

ElasticSearch源码之——Gateway
版本:es6.3.2
es数据存储
数据存储配置

es集群状态数据查看:

目录文件
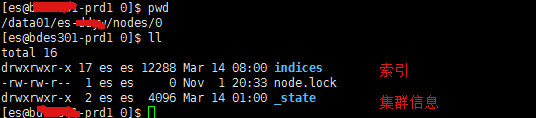
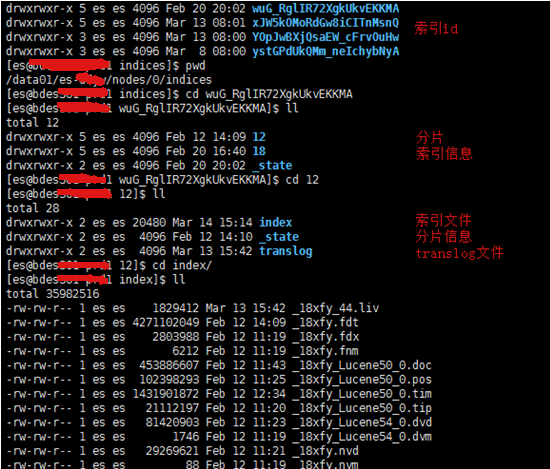
集群重启后元数据如何恢复?
gateway模块
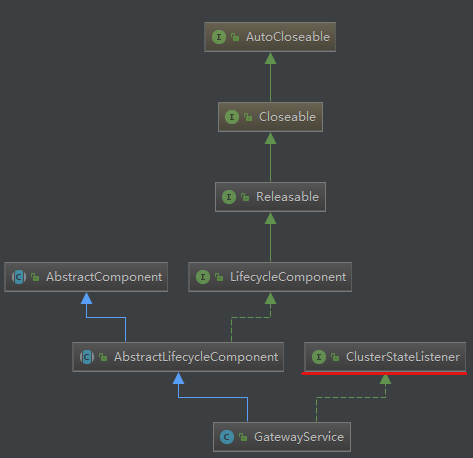
1.启动
injector.getInstance(GatewayService.class).start();//节点启动时启动
@Override protected void doStart() { // use post applied so that the state will be visible to the background recovery thread we spawn in performStateRecovery clusterService.addListener(this);//实现了ClusterStateListener,启动时监听集群状态发生变化 }
2.配置文件elasticsearch.yml中的gateway相关配置,判断是否满足集群recovery的条件,满足条件后执行恢复操作
gateway.expected_nodes: 10
gateway.expected_master_nodes: 3
gateway.expected_data_nodes: 10
gateway.recover_after_time: 5m
gateway.recover_after_nodes: 9
gateway.recover_after_master_nodes: 2
gateway.recover_after_data_nodes: 9
3.集群状态发生变化后做如下事情:
callClusterStateAppliers(clusterChangedEvent);//1.应用集群状态
callClusterStateListeners(clusterChangedEvent);//2.状态更新后的操作
task.listener.clusterStateProcessed(task.source, previousClusterState, newClusterState);//更新本节点存储的集群状态
private void callClusterStateListeners(ClusterChangedEvent clusterChangedEvent) { Stream.concat(clusterStateListeners.stream(), timeoutClusterStateListeners.stream()).forEach(listener -> {//执行每个监听器的clusterChanged方法 try { logger.trace("calling [{}] with change to version [{}]", listener, clusterChangedEvent.state().version()); listener.clusterChanged(clusterChangedEvent); } catch (Exception ex) { logger.warn("failed to notify ClusterStateListener", ex); } }); }
ClusterStateListener监听到集群状态发生改变执行
GatewayService.clusterChanged
performStateRecovery(enforceRecoverAfterTime, reason);//恢复操作具体执行过程
DiscoveryNodes nodes = state.nodes();//获取集群中的节点
if (state.nodes().isLocalNodeElectedMaster() == false) {//如果本节点不是master节点,则不进行元数据恢复工作
// not our job to recover
return;
}
if (state.nodes().getMasterNodeId() == null) {//元数据恢复,需要满足的条件
logger.debug("not recovering from gateway, no master elected yet");//要求master选举成功
} else if (recoverAfterNodes != -1 && (nodes.getMasterAndDataNodes().size()) < recoverAfterNodes) {
logger.debug("not recovering from gateway, nodes_size (data+master) [{}] < recover_after_nodes [{}]",//满足配置文件中给出的条件
nodes.getMasterAndDataNodes().size(), recoverAfterNodes);
}
....
performStateRecovery(enforceRecoverAfterTime, reason);//集群状态恢复
threadPool.schedule(recoverAfterTime, ThreadPool.Names.GENERIC, () -> {
if (recovered.compareAndSet(false, true)) {
logger.info("recover_after_time [{}] elapsed. performing state recovery...", recoverAfterTime);
gateway.performStateRecovery(recoveryListener);//具体执行恢复的方法,并传入一个listener,等待完成后执行后续过程
}
});
元数据恢复过程:
- 首先进行两种元数据的恢复:集群级和索引级
- 然后进行分片元数据恢复以及分片分配
1)获取集群中的master候选节点
String[] nodesIds = clusterService.state().nodes().getMasterNodes().keys().toArray(String.class);
2)从上述节点中获取所有的metadata信息
TransportNodesListGatewayMetaState.NodesGatewayMetaState nodesState = listGatewayMetaState.list(nodesIds, null).actionGet();
3)根据版本号从各个节点中获取最新的metadata作为最新的metadata,每有一次元数据的更新,版本号会加1
if (electedGlobalState == null) { electedGlobalState = nodeState.metaData(); } else if (nodeState.metaData().version() > electedGlobalState.version()) { electedGlobalState = nodeState.metaData(); }
4)同时,从各个metadata中的所有索引信息取出来放入一个Map中,供后续metadata中indicies的恢复使用
for (ObjectCursor<IndexMetaData> cursor : nodeState.metaData().indices().values()) { indices.addTo(cursor.value.getIndex(), 1); }
5)构建一份最新的元数据metadata表,并去掉其中的indices信息,在下一阶段选举
// update the global state, and clean the indices, we elect them in the next phase MetaData.Builder metaDataBuilder = MetaData.builder(electedGlobalState).removeAllIndices();
6)对找到的索引获取最新的版本并进行一些校验后,加入metadata中。如索引是否可用,如果打开不可用,会将该索引的状态设为关闭。
7)构建clusterstate,并执行监听器成功方法,在该方法中提交集群状态,进行路由表routingtable的构建。
将索引信息添加到路由表中,此时分片状态全部为unassigned,哪些分片分配在哪些节点的信息还没有确定。
// initialize all index routing tables as empty RoutingTable.Builder routingTableBuilder = RoutingTable.builder(updatedState.routingTable()); for (ObjectCursor<IndexMetaData> cursor : updatedState.metaData().indices().values()) { routingTableBuilder.addAsRecovery(cursor.value); } // start with 0 based versions for routing table routingTableBuilder.version(0); // now, reroute updatedState = ClusterState.builder(updatedState).routingTable(routingTableBuilder.build()).build(); return allocationService.reroute(updatedState, "state recovered");
shard重新分配过程:
分片分配的两个内容:
- 分片分配给哪个节点
- 决定哪个分片作为主分片,哪些作为副本
es提供两个组件完成分片的分配:allocators(寻找目前集群情况的最优节点)和deciders(决定是否执行在该节点上的分配)
新建索引的分配策略:allocators找出节点按分片数升序排序(尽可能均衡地分配分片),deciders遍历allocators给出的节点,并决定是否分配在上面。
已有索引的分配策略:对于主分片,allocators将主分片分配在拥有该分片完整数据的节点上;对于副本,allocators找出拥有该分片副本的节点(即使没有完整数据),如果找到这样的节点,从主分片同步数据,如果没 有这样的节点,则从主分片拷贝数据。
我们现在gateway模块进行的是已有索引的分片分配策略
// now, reroute updatedState = ClusterState.builder(updatedState).routingTable(routingTableBuilder.build()).build(); return allocationService.reroute(updatedState, "state recovered");
1)分片分配决策器
ClusterModule初始化时,创建分片分配决策器 allocationDeciders
this.deciderList = createAllocationDeciders(settings, clusterService.getClusterSettings(), clusterPlugins); this.allocationDeciders = new AllocationDeciders(settings, deciderList);
2)allocationService进行分片分配
RoutingAllocation allocation = new RoutingAllocation(allocationDeciders, routingNodes, clusterState, clusterInfoService.getClusterInfo(), currentNanoTime());
reroute(allocation);
gatewayAllocator.allocateUnassigned(allocation);
primaryShardAllocator.allocateUnassigned(allocation);//分配主分片
replicaShardAllocator.processExistingRecoveries(allocation);
replicaShardAllocator.allocateUnassigned(allocation);//分片副本
shardsAllocator.allocate(allocation);//分片均衡
分片分配的过程中会遍历所有未分配分配,根据决策决定是否进行分片初始化
数据recovery
shards元信息恢复后,会提交集群状态改变的任务
clusterService.submitStateUpdateTask
当节点收到来自Master的广播后,开始应用新的clusterState
public synchronized void applyClusterState(final ClusterChangedEvent event){
createOrUpdateShards(state);//
}
indexShard.startRecovery(recoveryState, recoveryTargetService, recoveryListener, repositoriesService,//开始恢复分片 (type, mapping) -> { assert recoveryState.getRecoverySource().getType() == RecoverySource.Type.LOCAL_SHARDS: "mapping update consumer only required by local shards recovery"; try { client.admin().indices().preparePutMapping() .setConcreteIndex(shardRouting.index()) // concrete index - no name ***, it uses uuid .setType(type) .setSource(mapping.source().string(), XContentType.JSON) .get(); } catch (IOException ex) { throw new ElasticsearchException("failed to stringify mapping source", ex); } }, this); return indexShard;
分片恢复后,启动分片,提供分片读写功能
@Override public void onRecoveryDone(RecoveryState state) { shardStateAction.shardStarted(shardRouting, "after " + state.getRecoverySource(), SHARD_STATE_ACTION_LISTENER); }
致此,ES集群重启后数据恢复完成。
一个集群可能有成千上万个分片,分片恢复的过程是异步执行,gateway模块在集群级、索引级元数据恢复后完成(onSuccess)。
参考文章:https://blog.csdn.net/thomas0yang/article/details/52535604
https://blog.csdn.net/codingapple/article/details/17308433
https://www.easyice.cn/archives/226
https://www.easyice.cn/archives/248 比较全面的gateway+allocation流程分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号