hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处
一:说明
此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等。
当前使用的hadoop版本为2.6.4
此为mapreducer的第二章节
这一章节中有着 计算共同好友,推荐可能认识的人
一:说明 二:在开发工具在运行mapreducer 2.1:本地模式运行mapreducer 2.2:在开发工具中运行在yarn中 三:mapreduce实现join 3.1:sql数据库中的示例 3.2:mapreduce的实现思路 3.3:创建相应的javabean 3.4:创建mapper 3.5:创建reduce 3.6:完整代码 3.7:数据倾斜的问题 四:查找共同好友,计算可能认识的人 4.1:准备数据 4.2:计算指定用户是哪些人的好友 4.3:计算共同好友 五:使用GroupingComparator分组计算最大值 5.1:定义一个javabean 5.2:定义一个GroupingComparator 5.3:map代码 5.4:reduce的代码 5.5:启动类 六:自定义输出位置 6.1:自定义FileOutputFormat 七:自定义输入数据 八:全局计数器 九:多个job串联,定义执行顺序 十:mapreduce的参数优化 10.1:资源相关参数 10.2:容错相关参数 10.3:本地运行mapreduce作业 10.4:效率和稳定性相关参数
二:在开发工具在运行mapreducer
之前我们一直是在开发工具中写好了代码,然后打包成jar包在服务器中以hadoop jar的形式运行,当然这个极其麻烦,毕竟上传这个部署还是很麻烦的,其次就是每改一次代码,都需要重新打包到服务器中。还有一个最大的缺点就是没有办法打断点调试一些业务代码,这对于定位代码问题极其困难。这里也有两个办法。
2.1:本地模式运行mapreducer
何为本地模式,就是不是运行在yarn上面,仅仅是以运行在本地的一个模式。
首先既然是运行在本地,就需要有所有mapreducer的class文件,先在hadoop官网中下载hadoop的代码,然后编译成相应的操作系统版本,以笔者在windows中开发的环境,肯定是编译windows版本的,然后设置相应的环境变量
HADOOP_HOME=E:\software\hadoop-2.6.2
然后增加path
%HADOOP_HOME%\bin
然后看一下main方法,其实代码什么都不用改,conf的配置全部可以不写,直接运行就是本地模式,至于为什么在服务器根据hadoop jar运行时,会运行到jar中,因为hadoop jar命令加载了配置文件。
Configuration conf = new Configuration(); //这个默认值就是local,其实可以不写 conf.set("mapreduce.framework.name", "local"); //本地模式运行mr程序时,输入输出可以在本地,也可以在hdfs中,具体需要看如下的两行参数 //这个默认值 就是本地,其实可以不配 //conf.set("fs.defaultFS","file:///"); //conf.set("fs.defaultFS","hdfs://server1:9000/"); Job job = Job.getInstance(conf);
那实际上,需要使用本地模式的时候,这里面的配置可以什么都不写,因为默认的参数就是本地模式,所以这个时候直接运行就行了,当然,在后面我们接收了两个参数,分别是数据的的来源和存储位置,所以我们运行的时候的时候,直接提交参数就行了,以idea为例
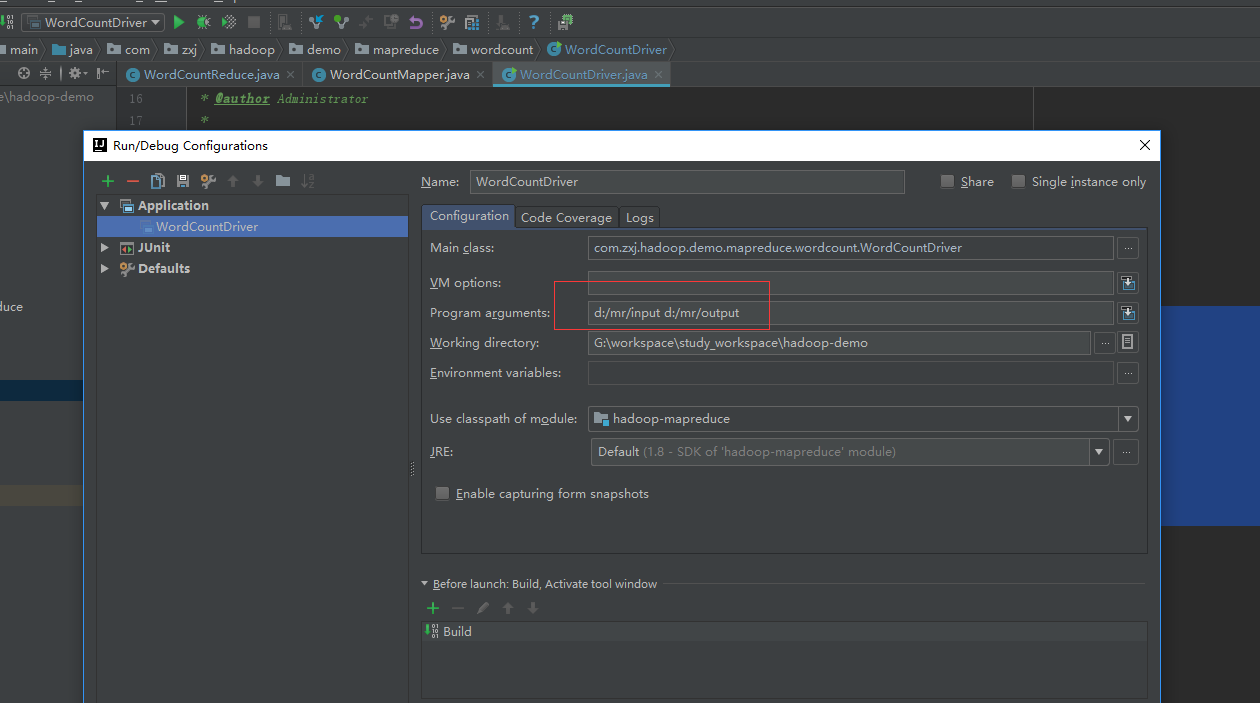
像在这里就传了两个参数,地址就在D盘中。
当然,其实也是支持挂在hdfs中的,如下配置
Configuration conf = new Configuration(); //这个默认值就是local,其实可以不写 conf.set("mapreduce.framework.name", "local"); //本地模式运行mr程序时,输入输出可以在本地,也可以在hdfs中,具体需要看如下的两行参数 //其实是可以本地模式也可以使用hdfs中的数据的 //conf.set("fs.defaultFS","file:///"); conf.set("fs.defaultFS","hdfs://server1:9000/");
也就是说,即使是本地模式,不仅仅可以使用在硬盘中,也可以使用在hdfs中
其实我们还需要加上一个日志文件,不然等下出错了,也看不到错误信息,仅仅是一片空白,那就尴尬了
在src/main/resource中添加一个log4j.properties文件,内容如下
log4j.rootLogger=info, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d [%t] %-5p %c - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
打印所有的info信息
2.2:在开发工具中运行在yarn中
上一部分中,我们是运行在本地模式,但是使用开发工具,可以更好的debug,这次我们在开发工具在,运行在服务器中的yarn上面。
想要运行在yarn上面,我们可以进行如下的配置
Configuration conf = new Configuration(); //运行在yarn的集群模式 conf.set("mapreduce.framework.name","yarn"); conf.set("yarn.resourcemanager.hostname","server1");//这行配置,使得该main方法会寻找该机器的mr环境 conf.set("fs.defaultFS","hdfs://server1:9000/");
通过之前的代码,我们知道我们要设置一个参数,使得mr环境能找到该代码的jar包,然后复制到所有的mr机器中去运行,但是我们这里要换一种方式,因为开发工具运行的时候,是直接运行class文件,而不是jar包
Job job = Job.getInstance(conf); //使得hadoop可以根据类包,找到jar包在哪里,如果是在开发工具中运行,那么则是找不到的 //job.setJarByClass(WordCountDriver.class); job.setJar("c:/xx.jar");
所以,如果我们要执行如下的代码,我们还需要先对程序进行打包才行。
仅仅修改完如上的一点代码,我们开始运行。
同样的,先配置启动参数,因为我们没改别的代码,mr的输入与输出都是从启动参数中读取的
然后执行main方法,如果server1有配置在hosts文中的话,那么见证奇迹.....哦,见证错误吧

在这里会看到一个错误,啥,没权限,对的,而且我们看到一个Administrator的用户,这个其实是我windows系统的用户,说明mapreduce运行的时候,拿的用户是当前登陆的用户,而在服务器中,如果看过之前的文章,我们给的目录权限是hadoop用户,所以我们要设置hadoop的用户。
我们要怎么做呢?还有要怎么设置用户为hadoop呢?我们来看一段hadoop的核心代码
if (!isSecurityEnabled() && (user == null)) { String envUser = System.getenv(HADOOP_USER_NAME); if (envUser == null) { envUser = System.getProperty(HADOOP_USER_NAME); } user = envUser == null ? null : new User(envUser); }
这段代码是获取用户的代码,这个时候我们就知道该怎么设置用户名了,常量名称为:HADOOP_USER_NAME
System.setProperty("HADOOP_USER_NAME","hadoop"); Configuration conf = new Configuration(); //运行在yarn的集群模式 conf.set("mapreduce.framework.name","yarn"); conf.set("yarn.resourcemanager.hostname","server1");//这行配置,使得该main方法会寻找该机器的mr环境 conf.set("fs.defaultFS","hdfs://server1:9000/");
可以看到红色区域,设置了hadoop的用户,此时,我们再运行一下代码,见证下一个错误,ps:一定要配置日志文件,不然看不到错误信息
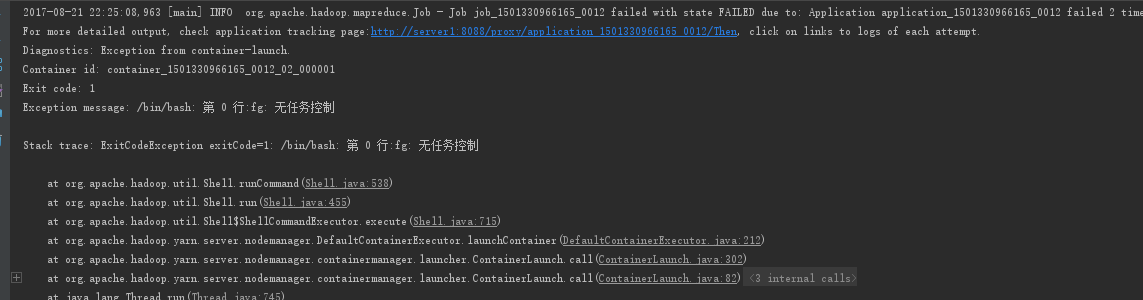
从完整的日志中,其实是可以看到,它是运行在yarn中了,不过出错了,图中是错误信息
有点让我吃惊的这竟然是中文的日志哈,如果是英文的日志,则是这样的
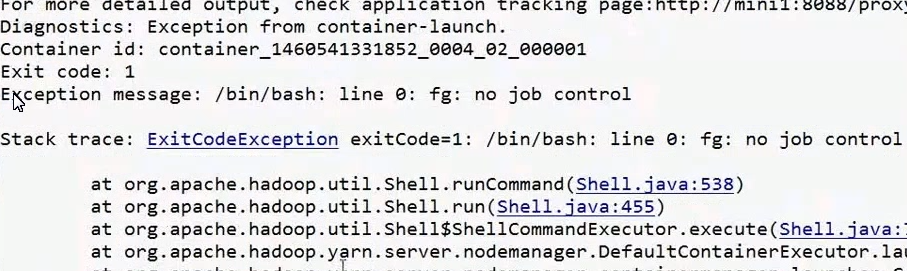
意思差不多哈,看到这个错误,我们要怎么解决呢?
这是hadoop的一个bug,新版本中已经解决,并且这个bug只会在windwos系统中出现,也就是意味着,如果你用的是linux的图形化界面,在这里面使用开发工具运行,也是不会有问题的。
先看一下问题是怎么产生的吧。先关联源码。
我们先找到org.apache.hadoop.mapred.YARNRunner这个类,并且在492行打上注释,可能位置会不一样,不过只需要找到environment变量即可,然后查看这个变量的名称
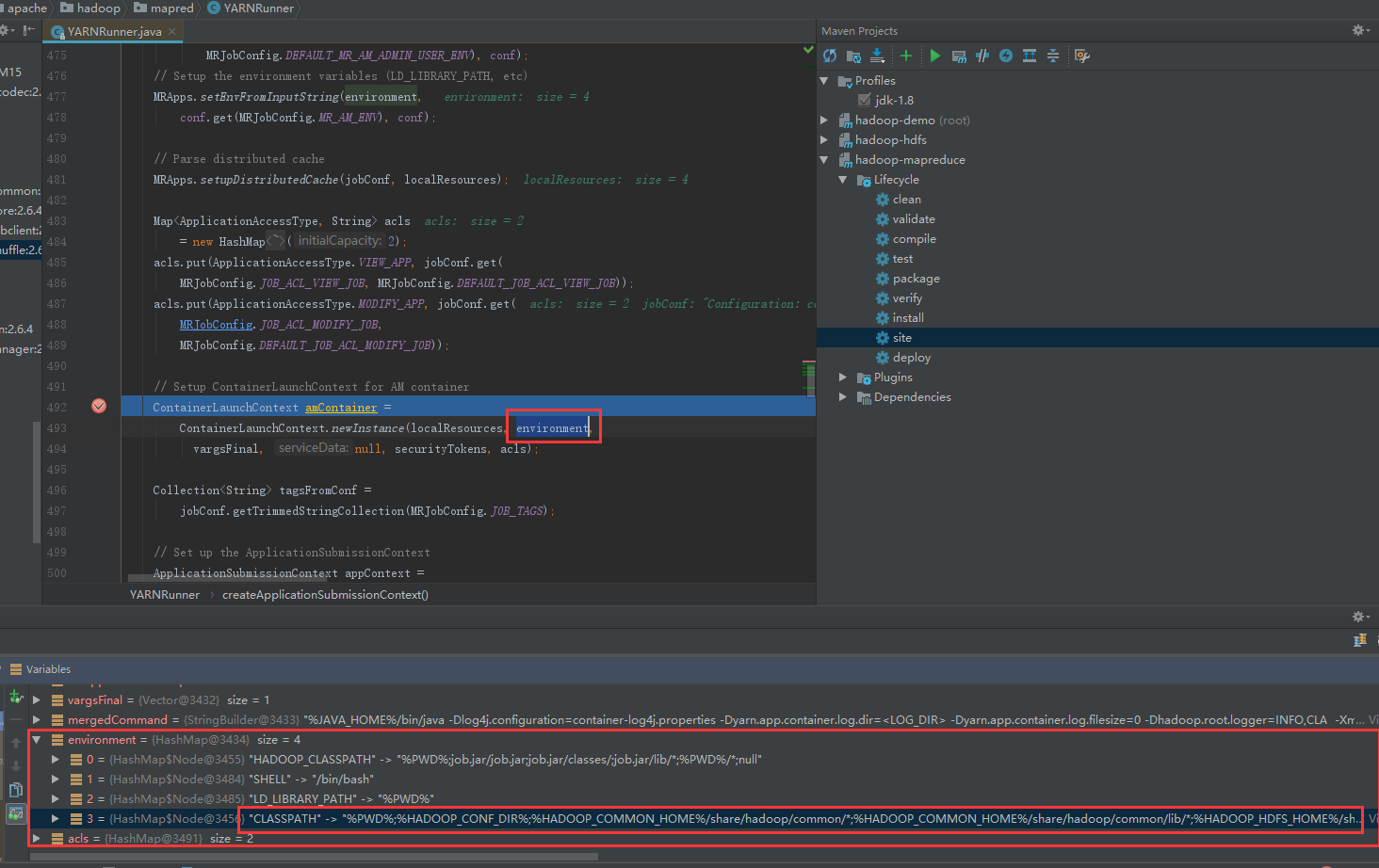
经过debug后,进入断点,查看environment变量,把内容最长的一段复制出来到记事本中查看。
很明显,最后的代码是执行在linux中的,但是这段环境却有问题。
首先就是%HADOOP_CONF_DIR%这种环境变量,对linux熟悉的可能知道,linux的环境变量是$JAVA_HOME$的这种形式,这是一个问题。
其次就是斜杠windows与linux也是不同的。
最后,环境变量的相隔,在linux中是冒号,而在windows中是分号。
这下应该知道问题了,不过我们要怎么改呢?只能改源代码了,千万不要对改源代码抱有害怕的心里,如果认真想想,这种类型的代码,就算是一个刚学会java基础的人也会修改,并没有什么可怕的。当然,等会也会贴出改完后的完整代码,不想改的同学直接复制就行了。
我们复制这样的一个类,包括代码,包名都要一样,直接建立在我们的工程中,java会优先读取本工程中的类
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.hadoop.mapred; import java.io.IOException; import java.nio.ByteBuffer; import java.util.ArrayList; import java.util.Collection; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Vector; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.classification.InterfaceAudience.Private; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileContext; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.UnsupportedFileSystemException; import org.apache.hadoop.io.DataOutputBuffer; import org.apache.hadoop.io.Text; import org.apache.hadoop.ipc.ProtocolSignature; import org.apache.hadoop.mapreduce.Cluster.JobTrackerStatus; import org.apache.hadoop.mapreduce.ClusterMetrics; import org.apache.hadoop.mapreduce.Counters; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.JobID; import org.apache.hadoop.mapreduce.JobStatus; import org.apache.hadoop.mapreduce.MRJobConfig; import org.apache.hadoop.mapreduce.QueueAclsInfo; import org.apache.hadoop.mapreduce.QueueInfo; import org.apache.hadoop.mapreduce.TaskAttemptID; import org.apache.hadoop.mapreduce.TaskCompletionEvent; import org.apache.hadoop.mapreduce.TaskReport; import org.apache.hadoop.mapreduce.TaskTrackerInfo; import org.apache.hadoop.mapreduce.TaskType; import org.apache.hadoop.mapreduce.TypeConverter; import org.apache.hadoop.mapreduce.protocol.ClientProtocol; import org.apache.hadoop.mapreduce.security.token.delegation.DelegationTokenIdentifier; import org.apache.hadoop.mapreduce.v2.LogParams; import org.apache.hadoop.mapreduce.v2.api.MRClientProtocol; import org.apache.hadoop.mapreduce.v2.api.protocolrecords.GetDelegationTokenRequest; import org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils; import org.apache.hadoop.mapreduce.v2.util.MRApps; import org.apache.hadoop.security.Credentials; import org.apache.hadoop.security.SecurityUtil; import org.apache.hadoop.security.UserGroupInformation; import org.apache.hadoop.security.authorize.AccessControlList; import org.apache.hadoop.security.token.Token; import org.apache.hadoop.yarn.api.ApplicationConstants; import org.apache.hadoop.yarn.api.ApplicationConstants.Environment; import org.apache.hadoop.yarn.api.records.ApplicationAccessType; import org.apache.hadoop.yarn.api.records.ApplicationId; import org.apache.hadoop.yarn.api.records.ApplicationReport; import org.apache.hadoop.yarn.api.records.ApplicationSubmissionContext; import org.apache.hadoop.yarn.api.records.ContainerLaunchContext; import org.apache.hadoop.yarn.api.records.LocalResource; import org.apache.hadoop.yarn.api.records.LocalResourceType; import org.apache.hadoop.yarn.api.records.LocalResourceVisibility; import org.apache.hadoop.yarn.api.records.ReservationId; import org.apache.hadoop.yarn.api.records.Resource; import org.apache.hadoop.yarn.api.records.URL; import org.apache.hadoop.yarn.api.records.YarnApplicationState; import org.apache.hadoop.yarn.conf.YarnConfiguration; import org.apache.hadoop.yarn.exceptions.YarnException; import org.apache.hadoop.yarn.factories.RecordFactory; import org.apache.hadoop.yarn.factory.providers.RecordFactoryProvider; import org.apache.hadoop.yarn.security.client.RMDelegationTokenSelector; import org.apache.hadoop.yarn.util.ConverterUtils; import com.google.common.annotations.VisibleForTesting; import com.google.common.base.CaseFormat; /** * This class enables the current JobClient (0.22 hadoop) to run on YARN. */ @SuppressWarnings("unchecked") public class YARNRunner implements ClientProtocol { private static final Log LOG = LogFactory.getLog(YARNRunner.class); private final RecordFactory recordFactory = RecordFactoryProvider.getRecordFactory(null); private ResourceMgrDelegate resMgrDelegate; private ClientCache clientCache; private Configuration conf; private final FileContext defaultFileContext; /** * Yarn runner incapsulates the client interface of yarn * * @param conf * the configuration object for the client */ public YARNRunner(Configuration conf) { this(conf, new ResourceMgrDelegate(new YarnConfiguration(conf))); } /** * Similar to {@link #YARNRunner(Configuration)} but allowing injecting * {@link ResourceMgrDelegate}. Enables mocking and testing. * * @param conf * the configuration object for the client * @param resMgrDelegate * the resourcemanager client handle. */ public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate) { this(conf, resMgrDelegate, new ClientCache(conf, resMgrDelegate)); } /** * Similar to * {@link YARNRunner#YARNRunner(Configuration, ResourceMgrDelegate)} but * allowing injecting {@link ClientCache}. Enable mocking and testing. * * @param conf * the configuration object * @param resMgrDelegate * the resource manager delegate * @param clientCache * the client cache object. */ public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate, ClientCache clientCache) { this.conf = conf; try { this.resMgrDelegate = resMgrDelegate; this.clientCache = clientCache; this.defaultFileContext = FileContext.getFileContext(this.conf); } catch (UnsupportedFileSystemException ufe) { throw new RuntimeException("Error in instantiating YarnClient", ufe); } } @Private /** * Used for testing mostly. * @param resMgrDelegate the resource manager delegate to set to. */ public void setResourceMgrDelegate(ResourceMgrDelegate resMgrDelegate) { this.resMgrDelegate = resMgrDelegate; } @Override public void cancelDelegationToken(Token<DelegationTokenIdentifier> arg0) throws IOException, InterruptedException { throw new UnsupportedOperationException("Use Token.renew instead"); } @Override public TaskTrackerInfo[] getActiveTrackers() throws IOException, InterruptedException { return resMgrDelegate.getActiveTrackers(); } @Override public JobStatus[] getAllJobs() throws IOException, InterruptedException { return resMgrDelegate.getAllJobs(); } @Override public TaskTrackerInfo[] getBlacklistedTrackers() throws IOException, InterruptedException { return resMgrDelegate.getBlacklistedTrackers(); } @Override public ClusterMetrics getClusterMetrics() throws IOException, InterruptedException { return resMgrDelegate.getClusterMetrics(); } @VisibleForTesting void addHistoryToken(Credentials ts) throws IOException, InterruptedException { /* check if we have a hsproxy, if not, no need */ MRClientProtocol hsProxy = clientCache.getInitializedHSProxy(); if (UserGroupInformation.isSecurityEnabled() && (hsProxy != null)) { /* * note that get delegation token was called. Again this is hack for * oozie to make sure we add history server delegation tokens to the * credentials */ RMDelegationTokenSelector tokenSelector = new RMDelegationTokenSelector(); Text service = resMgrDelegate.getRMDelegationTokenService(); if (tokenSelector.selectToken(service, ts.getAllTokens()) != null) { Text hsService = SecurityUtil.buildTokenService(hsProxy.getConnectAddress()); if (ts.getToken(hsService) == null) { ts.addToken(hsService, getDelegationTokenFromHS(hsProxy)); } } } } @VisibleForTesting Token<?> getDelegationTokenFromHS(MRClientProtocol hsProxy) throws IOException, InterruptedException { GetDelegationTokenRequest request = recordFactory.newRecordInstance(GetDelegationTokenRequest.class); request.setRenewer(Master.getMasterPrincipal(conf)); org.apache.hadoop.yarn.api.records.Token mrDelegationToken; mrDelegationToken = hsProxy.getDelegationToken(request).getDelegationToken(); return ConverterUtils.convertFromYarn(mrDelegationToken, hsProxy.getConnectAddress()); } @Override public Token<DelegationTokenIdentifier> getDelegationToken(Text renewer) throws IOException, InterruptedException { // The token is only used for serialization. So the type information // mismatch should be fine. return resMgrDelegate.getDelegationToken(renewer); } @Override public String getFilesystemName() throws IOException, InterruptedException { return resMgrDelegate.getFilesystemName(); } @Override public JobID getNewJobID() throws IOException, InterruptedException { return resMgrDelegate.getNewJobID(); } @Override public QueueInfo getQueue(String queueName) throws IOException, InterruptedException { return resMgrDelegate.getQueue(queueName); } @Override public QueueAclsInfo[] getQueueAclsForCurrentUser() throws IOException, InterruptedException { return resMgrDelegate.getQueueAclsForCurrentUser(); } @Override public QueueInfo[] getQueues() throws IOException, InterruptedException { return resMgrDelegate.getQueues(); } @Override public QueueInfo[] getRootQueues() throws IOException, InterruptedException { return resMgrDelegate.getRootQueues(); } @Override public QueueInfo[] getChildQueues(String parent) throws IOException, InterruptedException { return resMgrDelegate.getChildQueues(parent); } @Override public String getStagingAreaDir() throws IOException, InterruptedException { return resMgrDelegate.getStagingAreaDir(); } @Override public String getSystemDir() throws IOException, InterruptedException { return resMgrDelegate.getSystemDir(); } @Override public long getTaskTrackerExpiryInterval() throws IOException, InterruptedException { return resMgrDelegate.getTaskTrackerExpiryInterval(); } @Override public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts) throws IOException, InterruptedException { addHistoryToken(ts); // Construct necessary information to start the MR AM ApplicationSubmissionContext appContext = createApplicationSubmissionContext(conf, jobSubmitDir, ts); // Submit to ResourceManager try { ApplicationId applicationId = resMgrDelegate.submitApplication(appContext); ApplicationReport appMaster = resMgrDelegate.getApplicationReport(applicationId); String diagnostics = (appMaster == null ? "application report is null" : appMaster.getDiagnostics()); if (appMaster == null || appMaster.getYarnApplicationState() == YarnApplicationState.FAILED || appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) { throw new IOException("Failed to run job : " + diagnostics); } return clientCache.getClient(jobId).getJobStatus(jobId); } catch (YarnException e) { throw new IOException(e); } } private LocalResource createApplicationResource(FileContext fs, Path p, LocalResourceType type) throws IOException { LocalResource rsrc = recordFactory.newRecordInstance(LocalResource.class); FileStatus rsrcStat = fs.getFileStatus(p); rsrc.setResource(ConverterUtils.getYarnUrlFromPath(fs.getDefaultFileSystem().resolvePath(rsrcStat.getPath()))); rsrc.setSize(rsrcStat.getLen()); rsrc.setTimestamp(rsrcStat.getModificationTime()); rsrc.setType(type); rsrc.setVisibility(LocalResourceVisibility.APPLICATION); return rsrc; } public ApplicationSubmissionContext createApplicationSubmissionContext(Configuration jobConf, String jobSubmitDir, Credentials ts) throws IOException { ApplicationId applicationId = resMgrDelegate.getApplicationId(); // Setup resource requirements Resource capability = recordFactory.newRecordInstance(Resource.class); capability.setMemory(conf.getInt(MRJobConfig.MR_AM_VMEM_MB, MRJobConfig.DEFAULT_MR_AM_VMEM_MB)); capability.setVirtualCores(conf.getInt(MRJobConfig.MR_AM_CPU_VCORES, MRJobConfig.DEFAULT_MR_AM_CPU_VCORES)); LOG.debug("AppMaster capability = " + capability); // Setup LocalResources Map<String, LocalResource> localResources = new HashMap<String, LocalResource>(); Path jobConfPath = new Path(jobSubmitDir, MRJobConfig.JOB_CONF_FILE); URL yarnUrlForJobSubmitDir = ConverterUtils.getYarnUrlFromPath(defaultFileContext.getDefaultFileSystem().resolvePath(defaultFileContext.makeQualified(new Path(jobSubmitDir)))); LOG.debug("Creating setup context, jobSubmitDir url is " + yarnUrlForJobSubmitDir); localResources.put(MRJobConfig.JOB_CONF_FILE, createApplicationResource(defaultFileContext, jobConfPath, LocalResourceType.FILE)); if (jobConf.get(MRJobConfig.JAR) != null) { Path jobJarPath = new Path(jobConf.get(MRJobConfig.JAR)); LocalResource rc = createApplicationResource(FileContext.getFileContext(jobJarPath.toUri(), jobConf), jobJarPath, LocalResourceType.PATTERN); String pattern = conf.getPattern(JobContext.JAR_UNPACK_PATTERN, JobConf.UNPACK_JAR_PATTERN_DEFAULT).pattern(); rc.setPattern(pattern); localResources.put(MRJobConfig.JOB_JAR, rc); } else { // Job jar may be null. For e.g, for pipes, the job jar is the // hadoop // mapreduce jar itself which is already on the classpath. LOG.info("Job jar is not present. " + "Not adding any jar to the list of resources."); } // TODO gross hack for (String s : new String[] { MRJobConfig.JOB_SPLIT, MRJobConfig.JOB_SPLIT_METAINFO }) { localResources.put(MRJobConfig.JOB_SUBMIT_DIR + "/" + s, createApplicationResource(defaultFileContext, new Path(jobSubmitDir, s), LocalResourceType.FILE)); } // Setup security tokens DataOutputBuffer dob = new DataOutputBuffer(); ts.writeTokenStorageToStream(dob); ByteBuffer securityTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength()); // Setup the command to run the AM List<String> vargs = new ArrayList<String>(8); // vargs.add(MRApps.crossPlatformifyMREnv(jobConf, // Environment.JAVA_HOME) // + "/bin/java"); // TODO 此处为修改处 System.out.println(MRApps.crossPlatformifyMREnv(jobConf, Environment.JAVA_HOME) + "/bin/java"); vargs.add("$JAVA_HOME/bin/java"); // TODO: why do we use 'conf' some places and 'jobConf' others? long logSize = jobConf.getLong(MRJobConfig.MR_AM_LOG_KB, MRJobConfig.DEFAULT_MR_AM_LOG_KB) << 10; String logLevel = jobConf.get(MRJobConfig.MR_AM_LOG_LEVEL, MRJobConfig.DEFAULT_MR_AM_LOG_LEVEL); int numBackups = jobConf.getInt(MRJobConfig.MR_AM_LOG_BACKUPS, MRJobConfig.DEFAULT_MR_AM_LOG_BACKUPS); MRApps.addLog4jSystemProperties(logLevel, logSize, numBackups, vargs, conf); // Check for Java Lib Path usage in MAP and REDUCE configs warnForJavaLibPath(conf.get(MRJobConfig.MAP_JAVA_OPTS, ""), "map", MRJobConfig.MAP_JAVA_OPTS, MRJobConfig.MAP_ENV); warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, ""), "map", MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); warnForJavaLibPath(conf.get(MRJobConfig.REDUCE_JAVA_OPTS, ""), "reduce", MRJobConfig.REDUCE_JAVA_OPTS, MRJobConfig.REDUCE_ENV); warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, ""), "reduce", MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); // Add AM admin command opts before user command opts // so that it can be overridden by user String mrAppMasterAdminOptions = conf.get(MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.DEFAULT_MR_AM_ADMIN_COMMAND_OPTS); warnForJavaLibPath(mrAppMasterAdminOptions, "app master", MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.MR_AM_ADMIN_USER_ENV); vargs.add(mrAppMasterAdminOptions); // Add AM user command opts String mrAppMasterUserOptions = conf.get(MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.DEFAULT_MR_AM_COMMAND_OPTS); warnForJavaLibPath(mrAppMasterUserOptions, "app master", MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.MR_AM_ENV); vargs.add(mrAppMasterUserOptions); if (jobConf.getBoolean(MRJobConfig.MR_AM_PROFILE, MRJobConfig.DEFAULT_MR_AM_PROFILE)) { final String profileParams = jobConf.get(MRJobConfig.MR_AM_PROFILE_PARAMS, MRJobConfig.DEFAULT_TASK_PROFILE_PARAMS); if (profileParams != null) { vargs.add(String.format(profileParams, ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + TaskLog.LogName.PROFILE)); } } vargs.add(MRJobConfig.APPLICATION_MASTER_CLASS); vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDOUT); vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDERR); Vector<String> vargsFinal = new Vector<String>(8); // Final command StringBuilder mergedCommand = new StringBuilder(); for (CharSequence str : vargs) { mergedCommand.append(str).append(" "); } vargsFinal.add(mergedCommand.toString()); LOG.debug("Command to launch container for ApplicationMaster is : " + mergedCommand); // Setup the CLASSPATH in environment // i.e. add { Hadoop jars, job jar, CWD } to classpath. Map<String, String> environment = new HashMap<String, String>(); MRApps.setClasspath(environment, conf); // Shell environment.put(Environment.SHELL.name(), conf.get(MRJobConfig.MAPRED_ADMIN_USER_SHELL, MRJobConfig.DEFAULT_SHELL)); // Add the container working directory at the front of LD_LIBRARY_PATH MRApps.addToEnvironment(environment, Environment.LD_LIBRARY_PATH.name(), MRApps.crossPlatformifyMREnv(conf, Environment.PWD), conf); // Setup the environment variables for Admin first MRApps.setEnvFromInputString(environment, conf.get(MRJobConfig.MR_AM_ADMIN_USER_ENV), conf); // Setup the environment variables (LD_LIBRARY_PATH, etc) MRApps.setEnvFromInputString(environment, conf.get(MRJobConfig.MR_AM_ENV), conf); // Parse distributed cache MRApps.setupDistributedCache(jobConf, localResources); Map<ApplicationAccessType, String> acls = new HashMap<ApplicationAccessType, String>(2); acls.put(ApplicationAccessType.VIEW_APP, jobConf.get(MRJobConfig.JOB_ACL_VIEW_JOB, MRJobConfig.DEFAULT_JOB_ACL_VIEW_JOB)); acls.put(ApplicationAccessType.MODIFY_APP, jobConf.get(MRJobConfig.JOB_ACL_MODIFY_JOB, MRJobConfig.DEFAULT_JOB_ACL_MODIFY_JOB)); // TODO BY DHT for (String key : environment.keySet()) { String org = environment.get(key); String linux = getLinux(org); environment.put(key, linux); } // Setup ContainerLaunchContext for AM container ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(localResources, environment, vargsFinal, null, securityTokens, acls); Collection<String> tagsFromConf = jobConf.getTrimmedStringCollection(MRJobConfig.JOB_TAGS); // Set up the ApplicationSubmissionContext ApplicationSubmissionContext appContext = recordFactory.newRecordInstance(ApplicationSubmissionContext.class); appContext.setApplicationId(applicationId); // ApplicationId appContext.setQueue( // Queue name jobConf.get(JobContext.QUEUE_NAME, YarnConfiguration.DEFAULT_QUEUE_NAME)); // add reservationID if present ReservationId reservationID = null; try { reservationID = ReservationId.parseReservationId(jobConf.get(JobContext.RESERVATION_ID)); } catch (NumberFormatException e) { // throw exception as reservationid as is invalid String errMsg = "Invalid reservationId: " + jobConf.get(JobContext.RESERVATION_ID) + " specified for the app: " + applicationId; LOG.warn(errMsg); throw new IOException(errMsg); } if (reservationID != null) { appContext.setReservationID(reservationID); LOG.info("SUBMITTING ApplicationSubmissionContext app:" + applicationId + " to queue:" + appContext.getQueue() + " with reservationId:" + appContext.getReservationID()); } appContext.setApplicationName( // Job name jobConf.get(JobContext.JOB_NAME, YarnConfiguration.DEFAULT_APPLICATION_NAME)); appContext.setCancelTokensWhenComplete(conf.getBoolean(MRJobConfig.JOB_CANCEL_DELEGATION_TOKEN, true)); appContext.setAMContainerSpec(amContainer); // AM Container appContext.setMaxAppAttempts(conf.getInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, MRJobConfig.DEFAULT_MR_AM_MAX_ATTEMPTS)); appContext.setResource(capability); appContext.setApplicationType(MRJobConfig.MR_APPLICATION_TYPE); if (tagsFromConf != null && !tagsFromConf.isEmpty()) { appContext.setApplicationTags(new HashSet<String>(tagsFromConf)); } return appContext; } /** * 此处为修改处 * @param org * @return */ private String getLinux(String org) { StringBuilder sb = new StringBuilder(); int c = 0; for (int i = 0; i < org.length(); i++) { if (org.charAt(i) == '%') { c++; if (c % 2 == 1) { sb.append("$"); } } else { switch (org.charAt(i)) { case ';': sb.append(":"); break; case '\\': sb.append("/"); break; default: sb.append(org.charAt(i)); break; } } } return (sb.toString()); } @Override public void setJobPriority(JobID arg0, String arg1) throws IOException, InterruptedException { resMgrDelegate.setJobPriority(arg0, arg1); } @Override public long getProtocolVersion(String arg0, long arg1) throws IOException { return resMgrDelegate.getProtocolVersion(arg0, arg1); } @Override public long renewDelegationToken(Token<DelegationTokenIdentifier> arg0) throws IOException, InterruptedException { throw new UnsupportedOperationException("Use Token.renew instead"); } @Override public Counters getJobCounters(JobID arg0) throws IOException, InterruptedException { return clientCache.getClient(arg0).getJobCounters(arg0); } @Override public String getJobHistoryDir() throws IOException, InterruptedException { return JobHistoryUtils.getConfiguredHistoryServerDoneDirPrefix(conf); } @Override public JobStatus getJobStatus(JobID jobID) throws IOException, InterruptedException { JobStatus status = clientCache.getClient(jobID).getJobStatus(jobID); return status; } @Override public TaskCompletionEvent[] getTaskCompletionEvents(JobID arg0, int arg1, int arg2) throws IOException, InterruptedException { return clientCache.getClient(arg0).getTaskCompletionEvents(arg0, arg1, arg2); } @Override public String[] getTaskDiagnostics(TaskAttemptID arg0) throws IOException, InterruptedException { return clientCache.getClient(arg0.getJobID()).getTaskDiagnostics(arg0); } @Override public TaskReport[] getTaskReports(JobID jobID, TaskType taskType) throws IOException, InterruptedException { return clientCache.getClient(jobID).getTaskReports(jobID, taskType); } private void killUnFinishedApplication(ApplicationId appId) throws IOException { ApplicationReport application = null; try { application = resMgrDelegate.getApplicationReport(appId); } catch (YarnException e) { throw new IOException(e); } if (application.getYarnApplicationState() == YarnApplicationState.FINISHED || application.getYarnApplicationState() == YarnApplicationState.FAILED || application.getYarnApplicationState() == YarnApplicationState.KILLED) { return; } killApplication(appId); } private void killApplication(ApplicationId appId) throws IOException { try { resMgrDelegate.killApplication(appId); } catch (YarnException e) { throw new IOException(e); } } private boolean isJobInTerminalState(JobStatus status) { return status.getState() == JobStatus.State.KILLED || status.getState() == JobStatus.State.FAILED || status.getState() == JobStatus.State.SUCCEEDED; } @Override public void killJob(JobID arg0) throws IOException, InterruptedException { /* check if the status is not running, if not send kill to RM */ JobStatus status = clientCache.getClient(arg0).getJobStatus(arg0); ApplicationId appId = TypeConverter.toYarn(arg0).getAppId(); // get status from RM and return if (status == null) { killUnFinishedApplication(appId); return; } if (status.getState() != JobStatus.State.RUNNING) { killApplication(appId); return; } try { /* send a kill to the AM */ clientCache.getClient(arg0).killJob(arg0); long currentTimeMillis = System.currentTimeMillis(); long timeKillIssued = currentTimeMillis; while ((currentTimeMillis < timeKillIssued + 10000L) && !isJobInTerminalState(status)) { try { Thread.sleep(1000L); } catch (InterruptedException ie) { /** interrupted, just break */ break; } currentTimeMillis = System.currentTimeMillis(); status = clientCache.getClient(arg0).getJobStatus(arg0); if (status == null) { killUnFinishedApplication(appId); return; } } } catch (IOException io) { LOG.debug("Error when checking for application status", io); } if (status != null && !isJobInTerminalState(status)) { killApplication(appId); } } @Override public boolean killTask(TaskAttemptID arg0, boolean arg1) throws IOException, InterruptedException { return clientCache.getClient(arg0.getJobID()).killTask(arg0, arg1); } @Override public AccessControlList getQueueAdmins(String arg0) throws IOException { return new AccessControlList("*"); } @Override public JobTrackerStatus getJobTrackerStatus() throws IOException, InterruptedException { return JobTrackerStatus.RUNNING; } @Override public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, int clientMethodsHash) throws IOException { return ProtocolSignature.getProtocolSignature(this, protocol, clientVersion, clientMethodsHash); } @Override public LogParams getLogFileParams(JobID jobID, TaskAttemptID taskAttemptID) throws IOException { return clientCache.getClient(jobID).getLogFilePath(jobID, taskAttemptID); } private static void warnForJavaLibPath(String opts, String component, String javaConf, String envConf) { if (opts != null && opts.contains("-Djava.library.path")) { LOG.warn("Usage of -Djava.library.path in " + javaConf + " can cause " + "programs to no longer function if hadoop native libraries " + "are used. These values should be set as part of the " + "LD_LIBRARY_PATH in the " + component + " JVM env using " + envConf + " config settings."); } } }
代码就是这样子,重新运行main方法,就会发现,已经是运行成功了,第一次这样运行会有点慢,也不会太慢,第二次就正常了。
最后补充一些东西,其实conf的几行参数,也可以不写
conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname","server1");//这行配置,使得该main方法会寻找该机器的mr环境
conf.set("fs.defaultFS","hdfs://server1:9000/");
也就是这几行参数,其实是可以注释掉的。注释掉后会去读取配置文件,我们从服务器中把下面的几个配置文件下载下来

这里面的配置,是服务器中已经配置好的配置,再把它放到src/main/resource中,打包的时候,就会加载到classpath中,
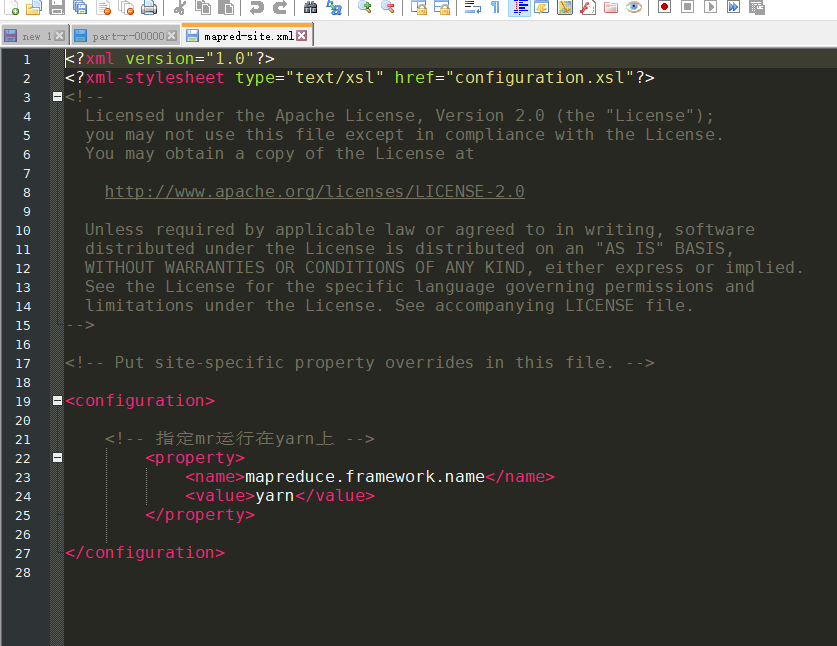
如图,配置文件中也有着这些配置,所以如果不写conf参数,把配置文件放进去,也是可以的
三:mapreduce实现join
3.1:sql数据库中的示例
先列举说明一下,以关系弄数据库来说明,假定我们现在有这样两个表,订单表和产品表。
订单表
订单Id,时间,产品编号,出售数量
1001,20170822,p1,3
1002,20170823,p2,9
1003,20170824,p3,11
产品表
#产品编号,产品名称,种类,单价 p1,防空火箭,1,20.2 p2,迫击炮,1,50 p3,法师塔,2,100
如果是用关系形数据库的SQL来表达,将会是如下的SQL
select * from 订单表 a left join 产品表 b on a.产品编号=b.产品编号
3.2:mapreduce的实现思路
首先找到链接的字符串,就是产品编号,可以看到,无论是订单表,还是产品表,都有个订单编号,sql中是根据这个关联,我们在mapreduce中也需要根据它来关联。
实现思路就是把产品编号,作为key当成reduce的输入。
这个时候,reduce中,全部是同一个产品的数据,其中有多个订单表的数据,这些订单是对应着同一个产品,也会有一条产品的表数据,然后把这些数据综合起来就行。
3.3:创建相应的javabean
以上是在sql数据库中的写法,假定我们有多个文件存在于hdfs中,我们要关联其中的数据,而数据格式就是这样的一个格式,我们要怎么处理呢?它就是mapreduce的一个join写法,我们这次使用本地模式运行。
首先在创建D:\mr\join\input目录,创建两个文件,分别为order_01.txt和product_01.txt里面分别把上面的订单数据和产品数据存放进去。
然后我们定义一个javabean,来存放这些信息,并且让其实现hadoop的序列化
/** * 这个类的信息,包含了两个表的信息记录 */ static class Info implements Writable,Cloneable{ /** * 订单号 */ private int orderId; /** * 时间 */ private String dateString; /** * 产品编号 */ private String pid; /** * 数量 */ private int amount; /** * 产品名称 */ private String pname; /** * 种类 */ private int categoryId; /** * 价格 */ private float price; /** * 这个字段需要理解<br> * 因为这个对象,包含了订单与产品的两个文件的内容,当我们加载一个文件的时候,肯定只能加载一部分的信息,另一部分是加载不到的,需要在join的时候,加进去,这个字段就代表着这个对象存的是哪些信息 * 如果为0 则是存了订单信息 * 如果为1 则是存了产品信息 */ private String flag; @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } @Override public void write(DataOutput out) throws IOException { out.writeInt(orderId); out.writeUTF(dateString); out.writeUTF(pid); out.writeInt(amount); out.writeUTF(pname); out.writeInt(categoryId); out.writeFloat(price); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { orderId = in.readInt(); dateString = in.readUTF(); pid = in.readUTF(); amount = in.readInt(); pname = in.readUTF(); categoryId = in.readInt(); price = in.readFloat(); flag = in.readUTF(); } public Info() { } public void set(int orderId, String dateString, String pid, int amount, String pname, int categoryId, float price,String flag) { this.orderId = orderId; this.dateString = dateString; this.pid = pid; this.amount = amount; this.pname = pname; this.categoryId = categoryId; this.price = price; this.flag = flag; } public int getOrderId() { return orderId; } public void setOrderId(int orderId) { this.orderId = orderId; } public String getDateString() { return dateString; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } public void setDateString(String dateString) { this.dateString = dateString; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public int getAmount() { return amount; } public void setAmount(int amount) { this.amount = amount; } public String getPname() { return pname; } public void setPname(String pname) { this.pname = pname; } public int getCategoryId() { return categoryId; } public void setCategoryId(int categoryId) { this.categoryId = categoryId; } public float getPrice() { return price; } public void setPrice(float price) { this.price = price; } @Override public String toString() { final StringBuilder sb = new StringBuilder("{"); sb.append("\"orderId\":") .append(orderId); sb.append(",\"dateString\":\"") .append(dateString).append('\"'); sb.append(",\"pid\":") .append(pid); sb.append(",\"amount\":") .append(amount); sb.append(",\"pname\":\"") .append(pname).append('\"'); sb.append(",\"categoryId\":") .append(categoryId); sb.append(",\"price\":") .append(price); sb.append(",\"flag\":\"") .append(flag).append('\"'); sb.append('}'); return sb.toString(); } }
3.4:创建mapper
mapper的代码可以直接看注释
static class JoinMapper extends Mapper<LongWritable,Text,Text,Info>{ private Info info = new Info(); private Text text = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); if(line.startsWith("#")){//跳转带#的注释 return; } //获取当前任务的输入切片,这个InputSplit是一个最上层抽象类,可以转换成FileSplit InputSplit inputSplit = context.getInputSplit(); FileSplit fileSplit = (FileSplit) inputSplit; String name = fileSplit.getPath().getName();//得到的是文件名,这里根据文件名来判断是哪一种类型的数据 //我们这里通过文件名判断是哪种数据 String pid = ""; String[] split = line.split(","); if(name.startsWith("order")){//加载订单内容,订单数据里面有 订单号,时间,产品ID,数量 //orderId,date,pid,amount pid = split[2]; info.set(Integer.parseInt(split[0]),split[1],pid,Integer.parseInt(split[3]),"",0,0,"0"); }else{//加载产品内容,产品数据有 产品编号,产品名称,种类,价格 //pid,pname,categoryId,price pid = split[0]; info.set(0,"",pid,0,split[1],Integer.parseInt(split[2]),Float.parseFloat(split[3]),"1"); } text.set(pid); context.write(text,info); } }
3.5:创建reduce
直接看注释即可
static class JoinReduce extends Reducer<Text,Info,Info,NullWritable>{ @Override protected void reduce(Text key, Iterable<Info> values, Context context) throws IOException, InterruptedException { Info product = new Info();//这个对象用来存放产品的数据,一个产品所以只有一个对象 List<Info> infos = new ArrayList<>();//这个list用来存放所有的订单数据,订单肯定是有多个的 for(Info info : values){ if("1".equals(info.getFlag())){ //产品表的数据 try { product = (Info) info.clone(); } catch (Exception e) { e.printStackTrace(); } }else{//代表着是订单表的数据 Info order = new Info(); try { order = (Info) info.clone(); } catch (Exception e) { e.printStackTrace(); } infos.add(order); } } //经过上面的操作,就把订单与产品完全分离出来了,订单在list集合中,产品在单独的一个对象中 //然后可以分别综合设置进去 for(Info tmp : infos){ tmp.setPname(product.getPname()); tmp.setCategoryId(product.getCategoryId()); tmp.setPrice(product.getPrice()); //最后进行输出,就会得到结果文件 context.write(tmp,NullWritable.get()); } } }
3.6:完整代码
上面贴了map与reduce,就差启动的main方法了,不过main方法是普通的main方法,和上一篇文中的启动方法一样,这里直接把join的所有代码全部贴了出来,包含main方法,全部写在一个文件里面
package com.zxj.hadoop.demo.mapreduce.join; import org.apache.commons.beanutils.BeanUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * @Author 朱小杰 * 时间 2017-08-22 .22:10 * 说明 ... */ public class MRJoin { /** * 这个类的信息,包含了两个表的信息记录 */ static class Info implements Writable,Cloneable{ /** * 订单号 */ private int orderId; /** * 时间 */ private String dateString; /** * 产品编号 */ private String pid; /** * 数量 */ private int amount; /** * 产品名称 */ private String pname; /** * 种类 */ private int categoryId; /** * 价格 */ private float price; /** * 这个字段需要理解<br> * 因为这个对象,包含了订单与产品的两个文件的内容,当我们加载一个文件的时候,肯定只能加载一部分的信息,另一部分是加载不到的,需要在join的时候,加进去,这个字段就代表着这个对象存的是哪些信息 * 如果为0 则是存了订单信息 * 如果为1 则是存了产品信息 */ private String flag; @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } @Override public void write(DataOutput out) throws IOException { out.writeInt(orderId); out.writeUTF(dateString); out.writeUTF(pid); out.writeInt(amount); out.writeUTF(pname); out.writeInt(categoryId); out.writeFloat(price); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { orderId = in.readInt(); dateString = in.readUTF(); pid = in.readUTF(); amount = in.readInt(); pname = in.readUTF(); categoryId = in.readInt(); price = in.readFloat(); flag = in.readUTF(); } public Info() { } public void set(int orderId, String dateString, String pid, int amount, String pname, int categoryId, float price,String flag) { this.orderId = orderId; this.dateString = dateString; this.pid = pid; this.amount = amount; this.pname = pname; this.categoryId = categoryId; this.price = price; this.flag = flag; } public int getOrderId() { return orderId; } public void setOrderId(int orderId) { this.orderId = orderId; } public String getDateString() { return dateString; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } public void setDateString(String dateString) { this.dateString = dateString; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public int getAmount() { return amount; } public void setAmount(int amount) { this.amount = amount; } public String getPname() { return pname; } public void setPname(String pname) { this.pname = pname; } public int getCategoryId() { return categoryId; } public void setCategoryId(int categoryId) { this.categoryId = categoryId; } public float getPrice() { return price; } public void setPrice(float price) { this.price = price; } @Override public String toString() { final StringBuilder sb = new StringBuilder("{"); sb.append("\"orderId\":") .append(orderId); sb.append(",\"dateString\":\"") .append(dateString).append('\"'); sb.append(",\"pid\":") .append(pid); sb.append(",\"amount\":") .append(amount); sb.append(",\"pname\":\"") .append(pname).append('\"'); sb.append(",\"categoryId\":") .append(categoryId); sb.append(",\"price\":") .append(price); sb.append(",\"flag\":\"") .append(flag).append('\"'); sb.append('}'); return sb.toString(); } } static class JoinMapper extends Mapper<LongWritable,Text,Text,Info>{ private Info info = new Info(); private Text text = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); if(line.startsWith("#")){//跳转带#的注释 return; } //获取当前任务的输入切片,这个InputSplit是一个最上层抽象类,可以转换成FileSplit InputSplit inputSplit = context.getInputSplit(); FileSplit fileSplit = (FileSplit) inputSplit; String name = fileSplit.getPath().getName();//得到的是文件名,这里根据文件名来判断是哪一种类型的数据 //我们这里通过文件名判断是哪种数据 String pid = ""; String[] split = line.split(","); if(name.startsWith("order")){//加载订单内容,订单数据里面有 订单号,时间,产品ID,数量 //orderId,date,pid,amount pid = split[2]; info.set(Integer.parseInt(split[0]),split[1],pid,Integer.parseInt(split[3]),"",0,0,"0"); }else{//加载产品内容,产品数据有 产品编号,产品名称,种类,价格 //pid,pname,categoryId,price pid = split[0]; info.set(0,"",pid,0,split[1],Integer.parseInt(split[2]),Float.parseFloat(split[3]),"1"); } text.set(pid); context.write(text,info); } } static class JoinReduce extends Reducer<Text,Info,Info,NullWritable>{ @Override protected void reduce(Text key, Iterable<Info> values, Context context) throws IOException, InterruptedException { Info product = new Info();//这个对象用来存放产品的数据,一个产品所以只有一个对象 List<Info> infos = new ArrayList<>();//这个list用来存放所有的订单数据,订单肯定是有多个的 for(Info info : values){ if("1".equals(info.getFlag())){ //产品表的数据 try { product = (Info) info.clone(); } catch (Exception e) { e.printStackTrace(); } }else{//代表着是订单表的数据 Info order = new Info(); try { order = (Info) info.clone(); } catch (Exception e) { e.printStackTrace(); } infos.add(order); } } //经过上面的操作,就把订单与产品完全分离出来了,订单在list集合中,产品在单独的一个对象中 //然后可以分别综合设置进去 for(Info tmp : infos){ tmp.setPname(product.getPname()); tmp.setCategoryId(product.getCategoryId()); tmp.setPrice(product.getPrice()); //最后进行输出,就会得到结果文件 context.write(tmp,NullWritable.get()); } } } static class JoinMain{ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(JoinMain.class); job.setMapperClass(JoinMapper.class); job.setReducerClass(JoinReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Info.class); job.setOutputKeyClass(Info.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean b = job.waitForCompletion(true); if(b){ System.out.println("OK"); } } } }
最后配置启动参数,以本地开发模式运行
运行成功后,得到如下结果

这就完成了
3.7:数据倾斜的问题
上面我们虽然解决了join的问题,但是也会陷入另一个问题,那就是数据倾斜。
假如果说a产品有10万张订单,b产品只有10个订单,那么就会导致每个reduce分配的数据不一致,个别速度很快,个别速度很慢,达不到快速的效果,性能低下。
解决这个问题,就是在map端实现数据的合并,在每个map中,单独加载产品表的信息,因为产品表的数据,肯定相对小一些,然后在map中实现数据的合并。
四:查找共同好友,计算可能认识的人
假定我们现在有一个社交软件,它的好友是单向好友,我们现在要计算用户之间的共同好友,然后向它推荐可能认识的人。
它需要经过两次mapreducer
4.1:准备数据
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
如上,冒号前面的是用户,冒号后面的是好友列表。
然后保存为文件,作为第一次mapreduce的输入
4.2:计算指定用户是哪些人的好友
package com.zxj.hadoop.demo.mapreduce.findfriend; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-08-24 .22:59 * 说明 先算出某个用户是哪些人的好友 */ public class Friend1 { static class FriendMapper1 extends Mapper<LongWritable, Text, Text, Text> { private Text k = new Text(); private Text v = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] personFriends = line.split(":"); String person = personFriends[0];//用户 String friends = personFriends[1];//好友 for (String friend : friends.split(",")) { //输出<好友,人> k.set(friend); v.set(person); context.write(k,v); } } } /** * 输入 好友,用户 */ static class FriendReduce1 extends Reducer<Text,Text,Text,Text>{ private Text k = new Text(); private Text v = new Text(); @Override protected void reduce(Text friend, Iterable<Text> persons, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for(Text person : persons){ sb.append(person).append(","); } k.set(friend); v.set(sb.toString()); context.write(k,v); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String input = "D:\\mr\\qq\\input"; String output = "D:\\mr\\qq\\out1"; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(Friend1.class); job.setMapperClass(FriendMapper1.class); job.setReducerClass(FriendReduce1.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path(input)); FileOutputFormat.setOutputPath(job,new Path(output)); boolean b = job.waitForCompletion(true); if(b){} } }
这里计算后的结果就是,某个用户分别是哪些人的好友,得到结果如下

4.3:计算共同好友
package com.zxj.hadoop.demo.mapreduce.findfriend; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; /** * @Author 朱小杰 * 时间 2017-08-24 .22:59 * 说明 继续第第二步操作 */ public class Friend2 { static class FriendMapper2 extends Mapper<LongWritable, Text, Text, Text> { /** * 这里拿到的是上一次计算的数据 A I,K,C,B,G,F,H,O,D, * A是哪些用户的好友 * @param key * @param value * @param context * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split("\t"); String friend = split[0]; String[] persions = split[1].split(","); Arrays.sort(persions); for(int i = 0 ; i < persions.length -2 ; i ++){ for(int j = i+1 ; j < persions.length -1 ; j ++){ //发送出 人-人 好友的数据,就是这两个人有哪个共同好友,会进入到同一个reducer中 context.write(new Text(persions[i] + "-" + persions[j]),new Text(friend)); } } } } /** * 输入 好友,用户 */ static class FriendReduce2 extends Reducer<Text,Text,Text,Text>{ private Text k = new Text(); private Text v = new Text(); @Override protected void reduce(Text person_person, Iterable<Text> friends, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for(Text f : friends){ sb.append(f.toString()).append(" "); } context.write(person_person,new Text(sb.toString())); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String input = "D:\\mr\\qq\\out1"; String output = "D:\\mr\\qq\\out2"; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(Friend2.class); job.setMapperClass(FriendMapper2.class); job.setReducerClass(FriendReduce2.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path(input)); FileOutputFormat.setOutputPath(job,new Path(output)); boolean b = job.waitForCompletion(true); if(b){} } }
经过这次计算,就能得到共同的好友了,因为是共同好友,所以他们也是有可能认识的人。
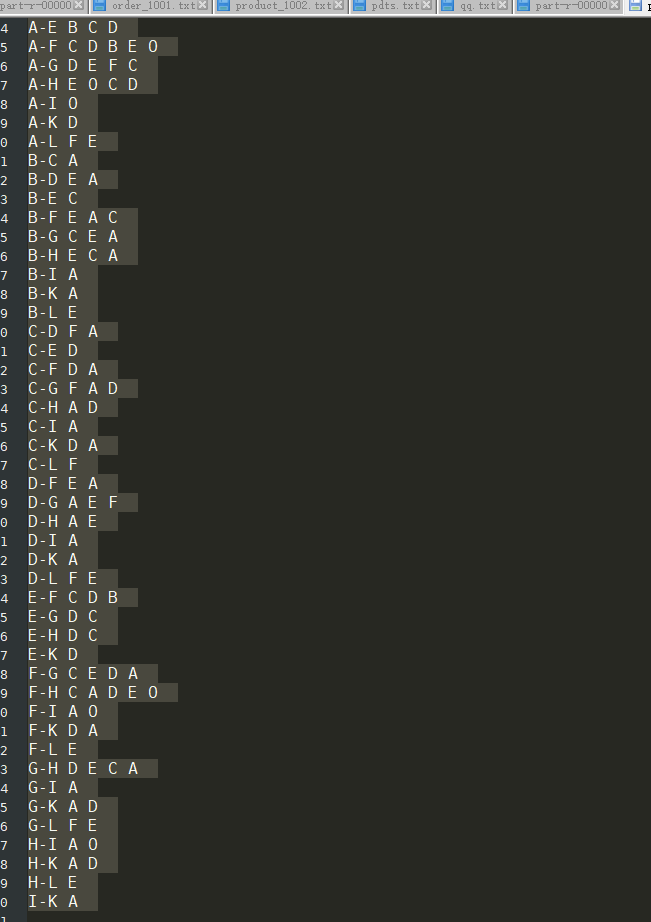
五:使用GroupingComparator分组计算最大值
我们准备一些订单数据
1号订单,200 1号订单,300 2号订单,1000 2号订单,300 2号订单,900 3号订单,9000 3号订单,200 3号订单,1000
这是每一号订单,分别售出多少钱,这里要求计算出每一号订单中的最大金额。
5.1:定义一个javabean
定义一个bean,并且实现序列化与排序比较接口
package com.zxj.hadoop.demo.mapreduce.groupingcomporator; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; /** * * */ public class OrderBean implements WritableComparable<OrderBean>{ private Text itemid; private DoubleWritable amount; public OrderBean() { } public OrderBean(Text itemid, DoubleWritable amount) { set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid; this.amount = amount; } public Text getItemid() { return itemid; } public DoubleWritable getAmount() { return amount; } @Override public int compareTo(OrderBean o) { int cmp = this.itemid.compareTo(o.getItemid()); if (cmp == 0) { cmp = -this.amount.compareTo(o.getAmount()); } return cmp; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(itemid.toString()); out.writeDouble(amount.get()); } @Override public void readFields(DataInput in) throws IOException { String readUTF = in.readUTF(); double readDouble = in.readDouble(); this.itemid = new Text(readUTF); this.amount= new DoubleWritable(readDouble); } @Override public String toString() { return itemid.toString() + "\t" + amount.get(); } }
5.2:定义一个GroupingComparator
我们都知道,reducer中,是把同一个key,以其所有的value放到了同一个reudce中计算,如果我们要把一个有着多属性的javabean当作key,那么同一个订单的bean就无法进入到同一个reduce中,我们需要通过这个分组,让所有同一个订单的bean全部进到同一个reduce中。
package com.zxj.hadoop.demo.mapreduce.groupingcomporator; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * @Author 朱小杰 * 时间 2017-08-26 .17:31 * 说明 利用reduce端的GroupingComparator来实现将一组bean看成相同的key * 用来分组 * @author */ public class ItemidGroupingComparator extends WritableComparator { /** * 这个类必须写,因为mapreduce需要知道反射成为哪个类 */ protected ItemidGroupingComparator() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean b1 = (OrderBean) a; OrderBean b2 = (OrderBean) b; //比较两个bean时,只比较这里面的一个字段,如果这里是相等的,那么mapreduce就会认为这两个对象是同一个key return b1.getItemid().compareTo(b2.getItemid()); } }
我们也知道,mapredce是根据key来进行排序的,所以我们可以想象,在把同一个订单的所有的bean当作一个key时,一个订单,只会有一个数据进入到reduce中,而因为我们实现的排序接口,数据最大的会最先进入到reduce中。
5.3:map代码
map的代码很简单
static class SecondarySortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{ OrderBean bean = new OrderBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, ","); bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[1]))); context.write(bean, NullWritable.get()); } }
这里很直接的把一个bean和一个null输出
5.4:reduce的代码
static class SecondarySortReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{ //到达reduce时,相同id的所有bean已经被看成一组,且金额最大的那个一排在第一位,所以后面的key也就不存在了 @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
因为前面有解释到,一个订单,只会有一个bean进来,并且进来的这个bean,肯定是最大值的一个金额,所以我们直接输出就行了
5.5:启动类
启动类和以往有点不同
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(SecondarySort.class); job.setMapperClass(SecondarySortMapper.class); job.setReducerClass(SecondarySortReducer.class); job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("D:\\mr\\groupcompatrator\\input")); FileOutputFormat.setOutputPath(job, new Path("D:\\mr\\groupcompatrator\\out1")); //在此设置自定义的Groupingcomparator类 job.setGroupingComparatorClass(ItemidGroupingComparator.class); job.waitForCompletion(true); }
运行之后查看效果如下

六:自定义输出位置
之前我们保存数据一直都是保存在文件系统中的,而且都是mapreduce代劳的,我们有没有可能把它输出到其它地方呢,比如关系型数据库,或者输出到缓存?hive等等这些地方?答案是可以的。
6.1:自定义FileOutputFormat
我们之前的启动类main方法中,一直有一行代码是这样子的
FileOutputFormat.setOutputPath(job, new Path("D:\\mr\\wordcount\\out1"));
这行代码是指定输出的位置,可以猜一下,我们使用的应该是FileOutputFormat或者是它的子类,答案是对的。所以我们来继承它,它是一个抽象类
package com.zxj.hadoop.demo.mapreduce.outputformat; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-08-26 .19:08 * 说明 mapreduce写数据时,会先调用这个类的getRecordWriter()方法,拿到一个RecordWriter对象,再调这个对象的写数据方法 */ public class MyOutputFormat<Text, LongWritable> extends FileOutputFormat<Text, LongWritable> { @Override public RecordWriter<Text, LongWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { return new MyRecordWriter<>(); } /** * 自定义的RecordWriter * * @param <Text> */ static class MyRecordWriter<Text, LongWritable> extends RecordWriter<Text, LongWritable> { private BufferedWriter writer; public MyRecordWriter() { try { writer = new BufferedWriter(new FileWriter("d:/myFileFormat")); } catch (Exception e) { e.printStackTrace(); } } @Override public void write(Text key, LongWritable value) throws IOException, InterruptedException { writer.write(key.toString() + " " + value.toString()); writer.newLine(); writer.flush(); } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { writer.close(); } } }
如上的代码中,我们自定义了一个OutputFormat,并且把文件输出到了D盘,可以想象,假如说我们要输出到一些关系型数据库,或者一些缓存,或者其它的存储位置,我们都可以灵活的去通过这个类去扩展它,而并不仅仅是受限于文件系统。
这个类配置使用的代码也只有一行
Job job = Job.getInstance(conf); //设置自定义的OutputFormat job.setOutputFormatClass(MyOutputFormat.class);
我们可以看到,这里我们设置了输出的Format。虽然我们在这个自定义的format中指定了输出的位置为D盘的根目录,但是输入和输出的两个参数还是要传的,也就是这两行代码
//指定输入文件的位置,这里为了灵活,接收外部参数 FileInputFormat.setInputPaths(job, new Path("D:\\mr\\wordcount\\input")); //指定输入文件的位置,这里接收启动参数 FileOutputFormat.setOutputPath(job, new Path("D:\\mr\\wordcount\\out1"));
或许有人会觉得,输入需要指定可以理解,输出为什么要指定呢?这是因为我们继承的是FileOutputFormat,所以我们就必须要有一个输出目录,这个目录也会输出文件,但是输出的不是数据文件,而是一个结果文件,代表着成功或者失败,而自定义中指定的format的位置,才是真正数据输出的位置
这里贴上完整的启动类的代码,自定义输出format不会影响到map与reduce,所以这里就不贴
public static void main(String[] args) throws IOException { Configuration conf = new Configuration(); //这个默认值就是local,其实可以不写 conf.set("mapreduce.framework.name", "local"); //本地模式运行mr程序时,输入输出可以在本地,也可以在hdfs中,具体需要看如下的两行参数 //这个默认值 就是本地,其实可以不配 //conf.set("fs.defaultFS","file:///"); //conf.set("fs.defaultFS","hdfs://server1:9000/"); Job job = Job.getInstance(conf); //使得hadoop可以根据类包,找到jar包在哪里 job.setJarByClass(Driver.class); //设置自定义的OutputFormat job.setOutputFormatClass(MyOutputFormat.class); //指定Mapper的类 job.setMapperClass(WordCountMapper.class); //指定reduce的类 job.setReducerClass(WordCountReduce.class); //设置Mapper输出的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置最终输出的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定输入文件的位置,这里为了灵活,接收外部参数 FileInputFormat.setInputPaths(job, new Path("D:\\mr\\wordcount\\input")); //指定输入文件的位置,这里接收启动参数 FileOutputFormat.setOutputPath(job, new Path("D:\\mr\\wordcount\\out1")); //将job中的参数,提交到yarn中运行 //job.submit(); try { job.waitForCompletion(true); //这里的为true,会打印执行结果 } catch (ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } }
影响到的位置也仅仅是红色代码区域。然后随便写一个wordcount的代码,执行结果如下,我们先看FileOutputFormat.setOutputPath()中参数目录的内容
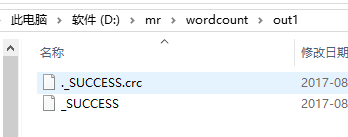
很明显,这是mapreduce运行完成后,代表运行结果的文件
我们再看D盘的目录
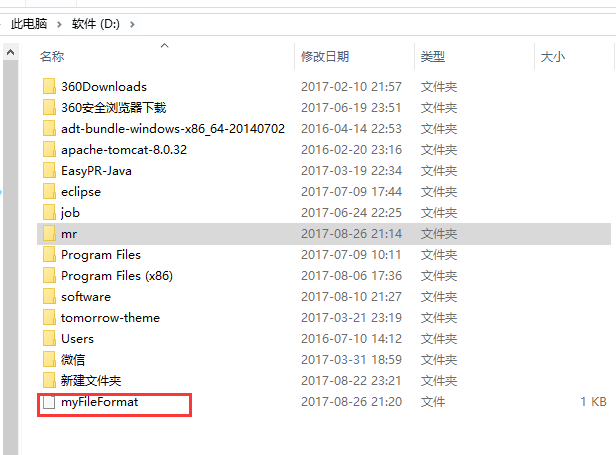
打开可以看到输出的最终结果

自定义输出就完了,利用这个类的实现,我们可以自由实现存储的位置
七:自定义输入数据
待补充...
八:全局计数器
在运行mapreduce中,我们可能会遇到计数器的需求,比如说我们要知道计算了多少条数据,剔除了多少条不合法的数据。
public class MultiOutputs { //通过枚举形式定义自定义计数器 enum MyCounter{MALFORORMED,NORMAL} static class CommaMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(","); for (String word : words) { context.write(new Text(word), new LongWritable(1)); } //对枚举定义的自定义计数器加1 context.getCounter(MyCounter.MALFORORMED).increment(1); //通过动态设置自定义计数器加1 context.getCounter("counterGroupa", "countera").increment(1); //直接设定数值 context.getCounter("","").setValue(10); } }
九:多个job串联,定义执行顺序
还记得之前我们写的mr程序中有计算qq好友,以及计算一本小说中,出现的哪个词最多的程序吗?我们分别是使用了两个mapreduce来计算这些数据,第二个mapreduce是基于第一个mapreduce的。
但是那个时候,我们是等待第一个程序执行完成后,手动执行第二个程序,其实这一步操作是可以自动的。我们可以把多个job关联起来
Job job1 = 创建第一个job; Job job2 = 创建第二个job; Job job3 = 创建第三个job; ControlledJob cJob1 = new ControlledJob(job1.getConfiguration()); ControlledJob cJob2 = new ControlledJob(job2.getConfiguration()); ControlledJob cJob3 = new ControlledJob(job3.getConfiguration()); cJob1.setJob(job1); cJob2.setJob(job2); cJob3.setJob(job3); // 设置作业依赖关系 cJob2.addDependingJob(cJob1);//第二个依赖于第一个 cJob3.addDependingJob(cJob2);//第三个依赖于第二个 JobControl jobControl = new JobControl("RecommendationJob"); jobControl.addJob(cJob1); jobControl.addJob(cJob2); jobControl.addJob(cJob3); // 新建一个线程来运行已加入JobControl中的作业,开始进程并等待结束 Thread jobControlThread = new Thread(jobControl); jobControlThread.start(); while (!jobControl.allFinished()) { Thread.sleep(500); } jobControl.stop();
十:mapreduce的参数优化
10.1:资源相关参数
//以下参数是在用户自己的mr应用程序中配置就可以生效 (1) mapreduce.map.memory.mb: 一个Map Task可使用的资源上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。 (2) mapreduce.reduce.memory.mb: 一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。 (3) mapreduce.map.java.opts: Map Task的JVM参数,你可以在此配置默认的java heap size等参数, e.g. “-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc” (@taskid@会被Hadoop框架自动换为相应的taskid), 默认值: “” (4) mapreduce.reduce.java.opts: Reduce Task的JVM参数,你可以在此配置默认的java heap size等参数, e.g. “-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc”, 默认值: “” (5) mapreduce.map.cpu.vcores: 每个Map task可使用的最多cpu core数目, 默认值: 1 (6) mapreduce.reduce.cpu.vcores: 每个Reduce task可使用的最多cpu core数目, 默认值: 1 //应该在yarn启动之前就配置在服务器的配置文件中才能生效 (7) yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存 (8) yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存 (9) yarn.scheduler.minimum-allocation-vcores 1 (10)yarn.scheduler.maximum-allocation-vcores 32 (11)yarn.nodemanager.resource.memory-mb 8192 //shuffle性能优化的关键参数,应在yarn启动之前就配置好 (12) mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m (13) mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
10.2:容错相关参数
(1) mapreduce.map.maxattempts: 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 (2) mapreduce.reduce.maxattempts: 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 (3) mapreduce.map.failures.maxpercent: 当失败的Map Task失败比例超过该值为,整个作业则失败,默认值为0. 如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业扔认为成功。 (4) mapreduce.reduce.failures.maxpercent: 当失败的Reduce Task失败比例超过该值为,整个作业则失败,默认值为0. (5) mapreduce.task.timeout: Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡主,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是300000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。
10.3:本地运行mapreduce作业
mapreduce.framework.name=local mapreduce.jobtracker.address=local fs.defaultFS=local
10.4:效率和稳定性相关参数
(1) mapreduce.map.speculative: 是否为Map Task打开推测执行机制,默认为false (2) mapreduce.reduce.speculative: 是否为Reduce Task打开推测执行机制,默认为false (3) mapreduce.job.user.classpath.first & mapreduce.task.classpath.user.precedence:当同一个class同时出现在用户jar包和hadoop jar中时,优先使用哪个jar包中的class,默认为false,表示优先使用hadoop jar中的class。 (4) mapreduce.input.fileinputformat.split.minsize: FileInputFormat做切片时的最小切片大小,
(5)mapreduce.input.fileinputformat.split.maxsize: FileInputFormat做切片时的最大切片大小(切片的默认大小就等于blocksize,即 134217728)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号