
Scrapy部署到线上服务器
1.服务器安装Ubuntu 20.01 64位,这个是LTS版本(不推荐用16.04,bug真多)

2.先在服务器上测试一下你的python环境,输入python3,再输入exit(),python版本是3.8.5(我用的阿里云镜像,室友用的腾讯云的镜像,但是他的python版本是3.8.2)。该Ubuntu 系统内置了python3, Ubuntu 16.04自带python2 和 python3两个版本。
3.安装pip,输入sudo apt-get install python3-pip,此时他会提示你没有这个包列表,输入sudo apt-get update ,sudo apt-get upgrade,安装过程大概5分钟。(这是因为你没有更新apt库,apt是一个应用管理工具,类似于你电脑上安装的360软件管家,apt是本地存了一份软件包信息的列表,比如软件大小,版本号,依赖等。你可以在断网的情况下,检索列表。目的是为了你在安装软件的时候快速检测依赖。并自动安装相关依赖。也就是说apt update是更新这个列表,如果不更新,可能你安装的软件的时候安装成了老版本。安装过程中出现任何弹窗均默认)
4.pip3 install scrapyd,pip3 install scrapy,pip3 install requests,pip3 install pymysql,pip3 install selenium(我记得可以pip一次性下载多个包)
5. vi /usr/local/lib/python3.8/dist-packages/scrapyd/default_scrapyd.conf,把文件里面的bind_address修改为自已的ip地址,如果修改为0.0.0.0,那么任何人都可以访问这个爬虫,如果只修改为自已的服务器ip地址的话,那么只有自已这台服务器才能访问,允许多个ip的话,那么中间加入空格即可 127.0.0.1 192.168.0.1。(我试了多次,貌似只能设置成0.0.0.0和127.0.0.0,其他ip会部署失败)
6.在本地上 pip3 install scrapyd-client(客户端的包),修改你系统环境的/Scripts,把scrapyd-deploy后面加上.py
7.修改你项目当中的scrapy.cfg,url那行注释关掉,localhost替换成你服务器的ip。
8.打开网址 https://curl.se/windows/ 下载你对应的版本的curl。
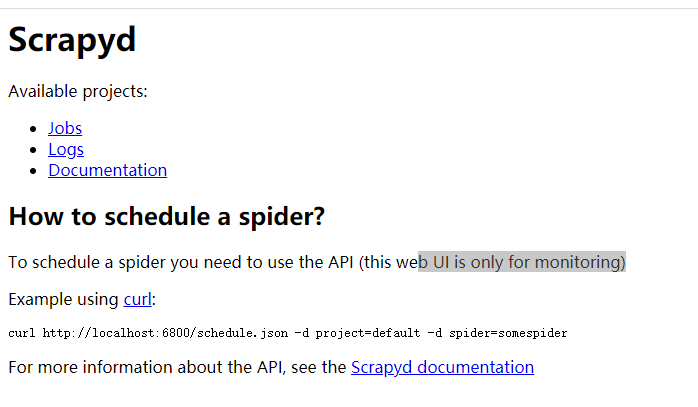
9.在你服务器开启scrapyd服务,输入scrapyd。在浏览器上输入ip:6800 即可看到如下图所示。

10.打开你要部署项目的目录,输入scrapyd-deploy,此时系统会提示你'scrapyd-deploy' 不是内部或外部命令,也不是可运行的程序
或批处理文件。此时你要修改两个配置文件,在D:\anaconda\Scripts下创建两个文件,scrapy.bat和scrapyd-deploy.bat,编辑两个文件scrapy.bat文件中输入以下内容 :
@echo off
D:\Python36\python D:\Python36\Scripts\scrapy %*
scrapyd-deploy.bat 文件中输入以下内容:
@echo off
D:\Python36\python D:\Python36\Scripts\scrapyd-deploy %*
在到你项目输入scrapyd-deploy,这就已经把你的项目部署到服务器了。如果你的服务器ip被添加你的ip地址的话,部署会失败的。
11.在cmd运行 curl http://ip:6800/schedule.json -d project=gsww -d spider=gsww_spider
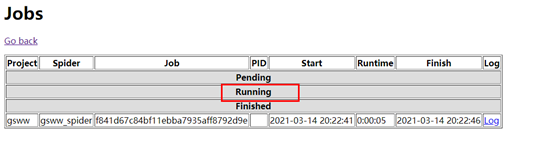
点击Log可以查看日记。
12.关闭爬虫,curl http://ip:6800/cancel.json -d project=gsww -d job=f841d67c84bf11ebba7935aff8792d9e
13.重启服务的话,直接输入scrapy就行。
14.官方部署文档说明 https://docs.scrapy.org/en/0.14/topics/scrapyd.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号