


信创-TDSQL迁移GaussDB实战之数据迁移和表结构变换
在某公司的信创改造任务中,前期因为公司采购的TDSQL在实际的生产过程中存在一些性能问题,随着后期的采购转变为GaussDB(虽然非功能和性能问题也是有一些),因此在目前已经上线的项目中来对现有的TDSQL部分进行替代,在本次文章中介绍TDSQL迁移GaussDB的数据迁移和表结构变换部分。
GaussDB提供了ugo和drs两个工具,可以完成大部分的异构数据库之间的表结构变换和数据迁移任务,但是TDSQL这款封装了MySQL的产品因为其保护性目前暂不支持使用ugo和drs因此需要开发人员来采用其他方式完成任务。
下面部分将开始介绍TDSQL(MySQL)与GaussDB for PG的不同之处和数据迁移的方案。
1 数据类型
1.1 数值类型
1.1.1 整数类型
|
MySQL |
GaussDB PG |
||||||
|
名称 |
描述 |
存储空间 |
范围 |
名称 |
描述 |
存储空间 |
范围 |
|
BIT |
对于bit来说有bit(m),顾名思义m就是bit位数,当m为8的时候,就表示一个字节。不可以保存负数。 |
与m值有关 |
M指示每个值的位数,从1到64。默认为1,如果M被省略了。 |
|
|
|
|
|
BOOL |
对于Boolean来说,存储的值也就是0和1。在MySQL中已经将bool类型转换成了tinyint(1)。 |
1个字节 |
零的值被认为是假的。非零值被认为是真的。 |
|
|
|
|
|
TINYINT |
对于tinyint而言,在建表的时候如果使用tinyint(m)的格式,由于tinyint的大小为1字节们也就是m的最大值为255,如果超过255的话,则会报错Display width out of range for column `XXX` (max = 255)。
|
1个字节 |
对于无符号的数的存储范围是0~255,而对于有符号数的存储范围为-128~127。 |
TINYINT |
微整数,别名为 INT1。 |
1字节 |
0 ~ 255 |
|
SMALLINT |
Smallint可以存储2个字节,也就是16位的数据。 |
2个字节 |
对于无符号数的存储范围是0~65535,而对于有符号数的存储范围是-32768~32767。
|
SMALLINT |
小范围整数,别名为 INT2。 |
2字节 |
-32,768 ~ +32,767 |
|
MEDIUMINT |
Mediumint可以存储3个字节的数据,也就是24位的数据。 |
3个字节 |
可以存储无符号数的范围是0~16777216,而对于无符号数的存储范围是-8388608~8388607。 |
|
|
|
|
|
INT/INTEGER |
Int可以存储4个字节的数据,也就是32位数据. |
4个字节 |
可以存储无符号数据的范围为0~4294967295,而对无符号数的存储范围是-2147483648~2147483647。 |
INTEGER/BINARY_IN TEGER |
常用的整数,别名为 INT4。 |
4字节 |
-2,147,483,648 ~ +2,147,483,647 |
|
BIGINT |
Bigint可以存储8个字节的数据,也就是64位的数据。 |
8个字节 |
可以存储无符号数的范围是0~18446744073709551615,而对无符号数的存储范围是-9223372036854775808~9223372036854775807。已经很大了,在实际的工程应用中使用bigint的场景也是有很多。 |
BIGINT |
大范围的整数,别名 为INT8。 |
8字节 |
-9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 |
|
|
|
|
|
int16 |
十六字节的大范围整 数,目前不支持用户 用于建表等使用。 |
16字节 |
-170,141,183,460,469,231,731,68 7,303,715,884,105,728 ~ +170,141,183,460,469,231,731,68 7,303,715,884,105,727 |
1.1.2 任意精度类型
|
MySQL |
GaussDB PG |
||||||
|
名称 |
描述 |
存储空间 |
范围 |
名称 |
描述 |
存储空间 |
范围 |
|
DECIMAL、NUMERIC |
Decimal(M,D)大小不确定,M表示指定长度,就是小数位数(精度)的总数,D表示小数点(标度)后的位数。如果D是0,则设置没有小数点或分数部分。M最大65,D最大30。如果D被省略,默认是0。如果M被省略,默认是10。 |
|
标准SQL要求DECIMAL(5,2)可以用五位数和两个小数来存储任何值,因此可以将这些值存储在salary列范 围-999.99到999.99 |
NUMERIC[ (p[,s])], DECIMAL[( p[,s])] |
精度p取值范围为 [1,1000],标度s取 值范围为[0,p]。 说明 p为总位数,s为小 数位数。 |
用户声明精度。每四 位(十进制位)占用 两个字节,然后在整 个数据上加上八个字 节的额外开销。 |
未指定精度的情况下, 小数点前最大131,072 位,小数点后最大 16,383位。 |
|
|
|
|
|
NUMBER[( p[,s])] |
NUMERIC类型的 别名。 |
用户声明精度。每四 位(十进制位)占用 两个字节,然后在整 个数据上加上八个字 节的额外开销。 |
未指定精度的情况下, 小数点前最大131,072 位,小数点后最大 16,383位。 |
1.1.3 序列整型
|
MySQL |
GaussDB PG |
||||||
|
名称 |
描述 |
存储空间 |
范围 |
名称 |
描述 |
存储空间 |
范围 |
|
AUTO_INCREMENT |
MySQL本身没有内建的序列类型,但可以使用AUTO_INCREMENT属性来模拟序列的行为。 |
|
|
|
|
|
|
|
|
|
|
|
SMALLSERIAL |
二字节序列整型 |
2字节 |
-32,768 ~ +32,767 |
|
|
|
|
|
SERIAL |
四字节序列整型 |
4字节 |
-2,147,483,648 ~ +2,147,483,647 |
|
|
|
|
|
BIGSERIAL |
八字节序列整型 |
8字节 |
-9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 |
|
|
|
|
|
LARGESERIAL |
默认插入十六字节 序列整形,实际数 值类型和numeric 相同。 |
变长类 型,每四 位(十进 制位)占 用两个字 节,然后 在整个数 据上加上 八个字节 的额外开 销。 |
小数点前最大131,072位,小数 点后最大16,383位。 |
|
|
|
|
|
说明:SMALLSERIAL,SERIAL,BIGSERIAL和LARGESERIAL类型不是真正的类型,只是为在表中设置唯一标识做的概念上的便利。因此,创建一个整数字段,并且把它的缺省数值安排为从一个序列发生器读取。应用了一个NOT NULL约束以确保NULL不会被插入。在大多数情况下用户可能还希望附加一个UNIQUE或PRIMARY KEY约束避免意外地插入重复的数值,但这个不是自动的。最后,将序列发生器从属于那个字段,这样当该字段或表被删除的时候也一并删除它。目前只支持在创建表时候指定SERIAL列,不可以在已有的表中,增加SERIAL列。另外临时表也不支持创建SERIAL列。因为SERIAL不是真正的类型,也不可以将表中存在的列类型转化为SERIAL。 |
|||
1.1.4 浮点类型
|
MySQL |
GaussDB PG |
||||||
|
名称 |
描述 |
存储空间 |
范围 |
名称 |
描述 |
存储空间 |
范围 |
|
FLOAT |
|
Float为单精度4个字节 |
可以保证6位精度 |
|
|
|
|
|
DOUBLE |
|
Double为双精度8个字节 |
可以保证16位精度 |
|
|
|
|
|
DECIMAL |
Decimal(M,D)大小不确定,M表示指定长度,就是小数位数(精度)的总数,D表示小数点(标度)后的位数。如果D是0,则设置没有小数点或分数部分。M最大65,D最大30。如果D被省略,默认是0。如果M被省略,默认是10。 |
|
|
|
|
|
|
|
|
|
|
|
REAL, FLOAT4 |
单精度浮点数,不 精准。 |
4字节 |
-3.402E+38~3.402E +38,6位十进制数字精度。 |
|
|
|
|
|
DOUBLE PRECISION , FLOAT8 |
双精度浮点数,不 精准。 |
8字节 |
-1.79E+308~1.79E +308,15位十进制数字 精度。 |
|
|
|
|
|
FLOAT[(p)] |
浮点数,不精准。 精度p取值范围为 [1,53]。 说明 p为精度,表示二进 制总位数。 |
4字节或8字节 |
根据精度p不同选择 REAL或DOUBLE PRECISION作为内部表 示。如不指定精度,内 部用DOUBLE PRECISION表示。 |
|
|
|
|
|
BINARY_D OUBLE |
是DOUBLE PRECISION的别 名。 |
8字节 |
-1.79E+308~1.79E +308,15位十进制数字 精度。 |
|
|
|
|
|
DEC[(p[,s])] |
精度p取值范围为 [1,1000],标度s取 值范围为[0,p]。 说明 p为总位数,s为小 数位位数。 |
用户声明精度。每四 位(十进制位)占用 两个字节,然后在整 个数据上加上八个字 节的额外开销。 |
未指定精度的情况下, 小数点前最大131,072 位,小数点后最大 16,383位。 |
|
|
|
|
|
INTEGER[(p[,s])] |
精度p取值范围为 [1,1000],标度s取 值范围为[0,p]。 |
用户声明精度。每四 位(十进制位)占用 两个字节,然后在整 个数据上加上八个字 节的额外开销。 |
|
|
说明:同样的数据4.125,由于我们选择的是(5,2),就会导致出现float和double的结果是4.12,而decimal的结果是4.13,也就是说float和double与decimal之间所采用的数据截断和进位的方式不同。这是因为float和double使用的是四舍六入五成双。对于四舍六入五成双,就是5以下舍弃5以上进位,如果需要处理数据为5的时候,需要看5后面是否还有不为0的任何数字,如果有,则直接进位,如果没有,需要看5前面的数字,如果是奇数则进位,如果是偶数则将5舍掉,也就是4.125取两位小数在float和double取2位小数的情况下的结果为4.12,而decimal是4.13。 |
|
|
|
|
|||
1.2 字符类型
|
MySQL |
GaussDB PG |
||||
|
名称 |
描述 |
存储空间 |
名称 |
描述 |
存储空间 |
|
CHAR |
显示的是字符,固定长度字符串最长255字符。 |
|
CHAR(n) CHARACTER(n) NCHAR(n) |
定长字符串,不足补空 格。n是指字节长度,如 不带精度n,默认精度为 1。 |
最大为10MB。 |
|
VARCHAR |
显示的是字符,0~65535字节,可变长度字符串,最大65535字节。字符和字节有很大区别,对于字节而言,不同的编码方式字符占用的字节长度不同。Utf8编码最大21844字符,1~3个字节用于记录大小,对于utf8格式,3个字节表示1个字符,所以有(65535 - 3) / 3 = 21844。 |
|
VARCHAR(n) CHARACTER VARYING(n) |
变长字符串。PG兼容模式 下,n是字符长度。其他 兼容模式下,n是指字节 长度。 |
最大为10MB。 |
|
|
|
|
VARCHAR2(n) |
变长字符串。n是指字节长度。 是VARCHAR(n)类型的别名,为兼容Oracle类型特设。 存储类型VARCHAR。 |
最大为10MB。 |
|
|
|
|
NVARCHAR2(n) |
变长字符串。n是指字符 长度。 |
最大为10MB。 |
|
TINYBLOB |
在MySQL中,BLOB类型实际是个系统类型系列(TinyBlob、Blob、MediumBlob、LongBlob),除了在存储的最大信息量上不同外,他们是等同的。不过在MySQL中一般是不用Blob来存储大型对象的,可以使用MongoDB来进行代替。 |
最大255B |
|
|
|
|
BLOB |
|
最大65535B |
BLOB |
二进制大对象 目前BLOB支持的外部存取 接口仅为: DBE_LOB.GET_LENGTH DBE_LOB.READ DBE_LOB.WRITE DBE_LOB.WRITE_APPEND DBE_LOB.COPY DBE_LOB.ERASE 说明: 列存不支持BLOB类型 |
最大为32TB(即35184372088832字 节)。 |
|
MEDIUMBLOB |
|
最大 16777215B
|
|
|
|
|
LONGBLOB |
|
最大4294967295B |
|
|
|
|
TINYTEXT |
|
最大255B |
|
|
|
|
TEXT |
|
最大65535B |
TEXT |
变长字符串 |
最大为1GB-1,但还需要考虑到列描述头信息的大小,以及列所在元组的大小限制(也小于1GB-1),因此TEXT类型最大大小可能小于1GB-1 |
|
MEDIUMTEXT |
|
最大16777215B |
|
|
|
|
LONGTEXT |
|
最大4294967295B |
|
|
|
|
|
|
|
CLOB |
文本大对象。是TEXT类型 的别名。 |
最大为32TB-1,但还需要考虑到列描述头信息的大小,以及列所在元组的大小限制(也小于32TB-1),因此CLOB类型最大大小可能小于32TB-1。 |
|
|
|
|
RAW |
变长的十六进制类型。 说明: 列存不支持RAW类型, RAW(n),n是指字节长度建议值,不会用于校验输入raw类型的字节长度。 |
4字节加上实际的十六进制字符串。最 大为1GB-8203字节(即1073733621字 节)。 |
|
|
|
|
BYTEA |
变长的二进制字符串 |
4字节加上实际的二进制字符串。最大 为1GB-8203字节(即1073733621字 节)。 |
1.3 日期类型
|
MySQL |
GaussDB PG |
||||
|
名称 |
描述 |
存储空间 |
名称 |
描述 |
存储空间 |
|
DATE |
日期,yyyy-mm-dd |
|
DATE |
日期。 说明 A兼容性下,数据库将空字符串作为 NULL处理,数据类型DATE会被替换为 TIMESTAMP(0) WITHOUT TIME ZONE。 |
4字节(兼容模式A 下存储空间大小为8 字节) |
|
TIME |
时间,hh:mm:ss。
|
|
TIME [(p)] [WITHOUT TIME ZONE] |
只用于一日内时间。 p表示小数点后的精度,取值范围为 0~6。 |
8字节 |
|
|
|
|
TIME [(p)] [WITH TIME ZONE] |
只用于一日内时间,带时区。 p表示小数点后的精度,取值范围为 0~6。 |
12字节 |
|
DATETIME |
日期和时间的组合,yyyy-mm-dd hh:mm:ss。 |
8字节 |
|
|
|
|
|
|
|
SMALLDATETIME |
日期和时间,不带时区。 精确到分钟,秒位大于等于30秒进一 位。 |
8字节 |
|
TIMESTAMP |
Yyyymmddhhmmss。 |
4字节 |
TIMESTAMP[(p)] [WITHOUT TIME ZONE] |
日期和时间。 p表示小数点后的精度,取值范围为 0~6。 |
8字节 |
|
|
|
|
TIMESTAMP[(p)] [WITH TIME ZONE] |
日期和时间,带时区。TIMESTAMP 的别名为TIMESTAMPTZ。 p表示小数点后的精度,取值范围为 0~6。 |
8字节 |
|
|
|
|
INTERVAL DAY (l) TO SECOND (p) |
时间间隔,X天X小时X分X秒。 l:天数的精度,取值范围为 0~6。兼容性考虑,目前未实现具 体功能。 p:秒数的精度,取值范围为 0~6。小数末尾的零不显示。 |
16字节 |
|
|
|
|
INTERVAL [FIELDS] [ (p) ] |
时间间隔。 fields:可以是YEAR,MONTH, DAY,HOUR,MINUTE, SECOND,DAY TO HOUR,DAY TO MINUTE,DAY TO SECOND,HOUR TO MINUTE, HOUR TO SECOND,MINUTE TO SECOND。 p:秒数的精度,取值范围为 0~6,且fields为SECOND,DAY TO SECOND,HOUR TO SECOND或MINUTE TO SECOND 时,参数p才有效。小数末尾的零 不显示。 |
12字节 |
|
|
|
|
reltime |
相对时间间隔。格式为: X years X mons X days XX:XX:XX。 采用儒略历计时,规定一年为365.25 天,一个月为30天,计算输入值对应 的相对时间间隔。 |
4字节 |
|
|
|
|
abstime |
日期和时间。格式为: YYYY-MM-DD hh:mm:ss+timezone 取值范围为1901-12-13 20:45:53 GMT~2038-01-18 23:59:59 GMT, 精度为秒。 |
4字节 |
|
YEAR |
年份yyyy。 |
|
|
|
|
|
说明:Datatime用8个字节来保存数据,其取值范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。其跟时区无关。Timestamp用4个字节来保存数据,其取值范围为1970-01-01 00:00:00 UTC ~ 2038-01-19 03:14:07,timestamp和时区有关。优先推荐使用datatime类型保存日期和时间,可以保存的时间范围更大一些。注意事项:在给时间字段设置默认值时,建议不要设置成0000-00-00 00:00:00,不然查询表时可能会因为转换不了,而直接报错。 |
|
|
|||
2 数据库操作
2.1 DDL
2.1.1 建库建表
1)MySQL:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification[,create_specification]…]
create_specification:
1-1)CHARACTER_SET:
指定数据库采用的字符集,如果不能指定字符集,默认是utf8。
1-2)COLLATE:
指定数据库字符集的校对规则,常用的是utf8_bin(区分大小写)和utf8_general_ci(不区分大小写),注意默认使用的是utf8_general_ci。
虽然默认的是utf8,但是在实际的工程应用中都会建议使用utf8mb4。在所占字节数上utf8占3个字节,utf8mb4占4个字节。显然utf8mb4是要比utf8能存储更多的信息。
在MySQL中的utf8实际上不是真正的UTF-8。因为MySQL中的utf8编码只支持每个字符最多三个字节,而真正的UTF-8是每个字符最多四个字节。在MySQL的utf8编码中,中文是3个字节,其他数据、英文和符号占1个字节。
但是emoji符号占4个字节,一些较为复杂的文字、繁体字也是4个字节。所以会导致以上这些写入失败,因此需要改为utf8mb4。MySQL的utf8mb4才是真正的UTF-8。MySQL的utf8是一种专属的编码,它能够编码的Unicode字符并不多。
所有在使用utf8的MySQL和MariaDB用户都应该改用utf8mb4,不要再使用utf8。
1-3)创建数据表:
创建数据表的语句如下:
CREATE TABLE IF NOT EXISTS table_name( Filed1 datatype, Filed2 datatype, Filed3 datatype ) character set 字符集 collate 校对规则 engine 存储引擎
Filed:指定列名
Datatype:指定列类型(字段类型)
Character set:如不指定则为数据库字符集
Collate:如不指定则为所在数据库校对规则
Engine:存储引擎,前面大篇幅内容介绍过的,默认使用InnoDB,还可以选择MyISAM和Memory等等。
当然对于一个实际的建表任务而言,还会有AUTO_INCREMENT、ROW_FORMAT等参数来控制表的构建。
2)GaussDB PG:
建库:
CREATE DATABASE database_name
[ [ WITH ] { [ OWNER [=] user_name ] |
[ TEMPLATE [=] template ] |
[ ENCODING [=] encoding ] |
[ LC_COLLATE [=] lc_collate ] |
[ LC_CTYPE [=] lc_ctype ] |
[ DBCOMPATIBILITY [=] compatibilty_type ] |
[ TABLESPACE [=] tablespace_name ] |
[ CONNECTION LIMIT [=] connlimit ] |
[ DBTIMEZONE [=] time_zone ]}[...] ];
2-1)database_name:
数据库名称。
取值范围:字符串,要符合标识符的命名规范。
2-2)OWNER [ = ] user_name:
数据库所有者。缺省时,新数据库的所有者是当前用户。
取值范围:已存在的用户名。
2-3)TEMPLATE [ = ] template:
模板名。即从哪个模板创建新数据库。GaussDB采用从模板数据库复制的方式来
创建新的数据库。初始时,GaussDB包含两个模板数据库template0、
template1,以及一个默认的用户数据库postgres。
取值范围:仅template0。
2-4)ENCODING [ = ] encoding:
指定数据库使用的字符编码,可以是字符串(如'SQL_ASCII')、整数编号。
不指定时,默认使用模版数据库的编码。模板数据库template0和template1的编
码默认与操作系统环境相关。template1不允许修改字符编码,因此若要变更编
码,请使用template0创建数据库。
常用取值:GBK、UTF8、Latin1、GB18030等。
2-5)LC_COLLATE [ = ] lc_collate:
指定新数据库使用的字符集。例如,通过lc_collate = 'zh_CN.gbk'设定该参数。
该参数的使用会影响到对字符串的排序顺序(如使用ORDER BY执行,以及在文本
列上使用索引的顺序)。默认是使用模板数据库的排序顺序。
取值范围:操作系统支持的字符集。
注:
ENCODING、LC_COLLATE和LC_CTYPE可以根据如下命令查询:
select pg_encoding_to_char(collencoding) as encoding,collname,collcollate,collctype from pg_collation;
2-6)LC_CTYPE [ = ] lc_ctype:
指定新数据库使用的字符分类。例如,通过lc_ctype = 'zh_CN.gbk'设定该参数。
该参数的使用会影响到字符的分类,如大写、小写和数字。默认是使用模板数据
库的字符分类。
取值范围:操作系统支持的字符分类。
2-7)DBCOMPATIBILITY [ = ] compatibility_type:
指定兼容的数据库的类型,默认兼容O。
取值范围:A、B、C、PG。分别表示兼容O、MY、TD和POSTGRES。
A兼容性下,数据库将空字符串作为NULL处理,数据类型DATE会被替换为
TIMESTAMP(0) WITHOUT TIME ZONE。
将字符串转换成整数类型时,如果输入不合法,B兼容性会将输入转换为0,而其它兼
容性则会报错。
PG兼容性下,CHAR和VARCHAR以字符为计数单位,其它兼容性以字节为计数单位。
例如,对于UTF-8字符集,CHAR(3)在PG兼容性下能存放3个中文字符,而在其它兼容
性下只能存放1个中文字符。
2-8)TABLESPACE [ = ] tablespace_name:
指定数据库对应的表空间。
取值范围:已存在表空间名。
2-9)CONNECTION LIMIT [ = ] connlimit
数据库可以接受的并发连接数。
2-10)特别说明:
在GaussDB for PG中,Encoding 是编码规则,collate是基于这个编码规则中对于字符的排序,而 CTYPE 是什么,Ctype是针对字符的大小写比对起作用的配置。
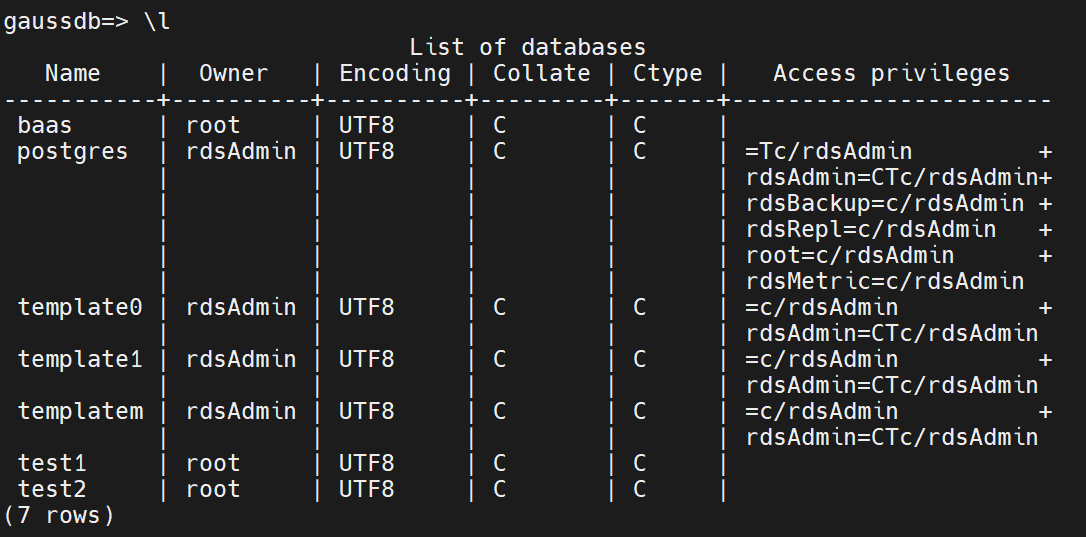
可以在设计索引的时候,指定不同的字符集。
在默认的情况下建表:
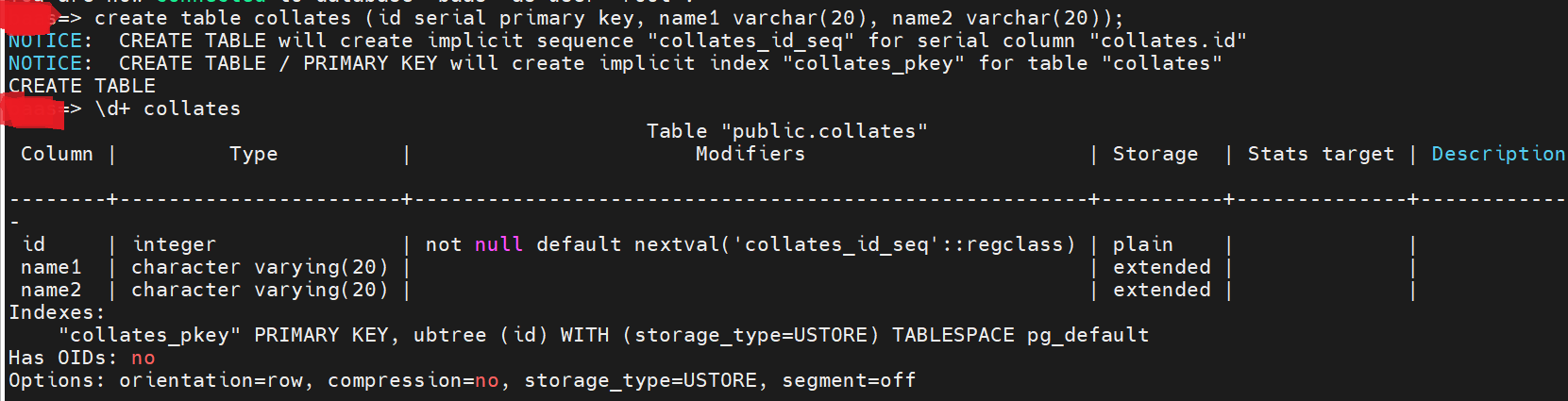
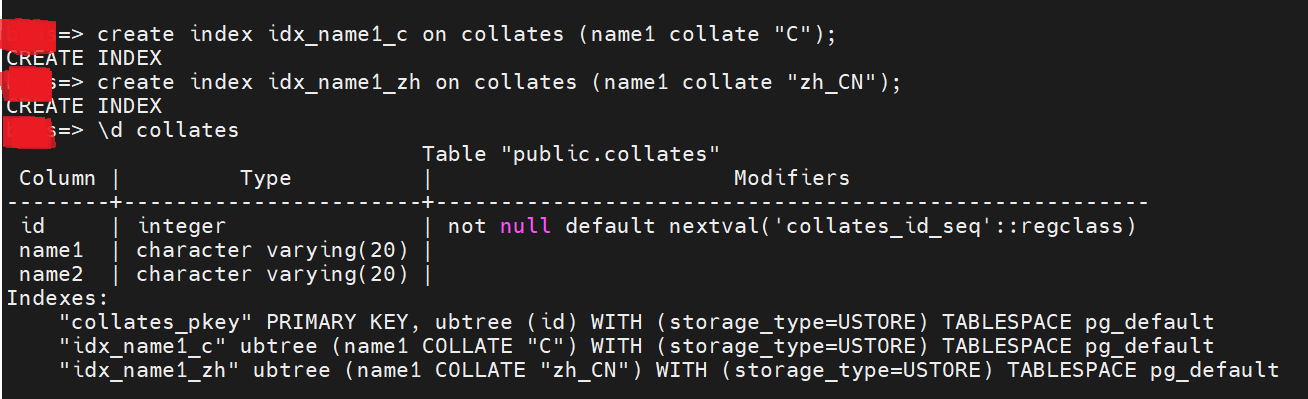
可以创建不同字符集的索引:
C.UTF-8 是一种语言环境设置,主要用于确保程序在处理文本时使用 UTF-8 编码。它与其他语言环境(如 en_US.UTF-8 和 zh_CN.UTF-8)有一些区别。
语言环境的区别:
C.UTF-8 是 POSIX 标准兼容的默认语言环境,严格支持 ASCII 字符,并扩展支持基本的 UTF-8。
en_US.UTF-8 是美式英语的 UTF-8 语言环境,支持英文及其他拉丁字母语种。
zh_CN.UTF-8 是中文的 UTF-8 语言环境,主要支持汉字、拼音、符号以及少量英文单词。
使用场景:
C.UTF-8 适用于需要严格遵循 POSIX 标准的场景,通常用于服务器端。
en_US.UTF-8 适用于以英语为主的应用程序和系统。
zh_CN.UTF-8 适用于中文应用程序和系统,显示中文更为兼容。
GaussDB数据库设计规范:
禁止使用postgres数据库,必须为业务创建Database。
创建Database必须设置字符集编码(ENCODING)、兼容性(DBCOMPATIBILITY)。
ENCODING:设置为UTF8;
DBCOMPATIBILITY:需配置为兼容Oracle语法,集中式版本需将参数配置为A,分布式版本需将参数配置为ORA,参考建库语句如下:
|
版本 |
参考建库语句 |
|
集中式 |
CREATE DATABASE test2 ENCODING='UTF8' lc_collate='C' lc_ctype='C' DBCOMPATIBILITY='A' TEMPLATE template0; |
|
分布式 |
CREATE DATABASE test2 ENCODING='UTF8' DBCOMPATIBILITY='ORA' TEMPLATE template0; |
建议一个数据库实例内应用自定义的Database数量不超过3个。
建议使用Schema进行业务隔离。
建表:
数据表设计规范
必须使用行存及ASTORE引擎;
建表语句参考:
CREATE TABLE tbl_name .... WITH (orientation=row,storage_type = astore);
必须定义Range分区表的上边界为Maxvalue。
删除、切割、合并、清空、交换分区的操作会使分区Global索引失效,建议申明UPDATE GLOBAL INDEX子句更新索引。
说明:UPDATE GLOBAL INDEX的更新策略为异步更新,可以避免在分区操作并UPDATE GLOBAL INDEX时,产生无法使用索引的问题。
对于ASTORE和USTORE:
Ustore 存储引擎,又名In-place Update存储引擎(原地更新),是openGauss 内核新增的一种存储模式。此前的版本使用的行存储引擎是Append (追加更新)模式。相比于Append Update(追加更新)行存储引擎,Ustore存储引擎可以提高数据页面内更新的HOT UPDATE的垃圾回收效率,有更新元组后存储空间占用的问题。Append Update和 In-place Update是两种不同的存储引擎策略,适用场景有所不同。
2.1.2 索引
1)MYSQL:
单张表的索引尽量控制在5个以内
单个索引的字段原则上不超过5个
表索引总长度不超过3072字节(系统限制)
组合索引的顺序要斟酌,以下需综合考虑
常用的筛选条件字段放在前面
选择性(基数)高的字段放在前面
尽可能地使用数据原生顺序从而避免额外的排序操作,需要经常排序的字段可加到索引中,字段顺序和最常用的排序一致
对于较长的字符串类型字段,建议使用前缀索引
合理合并索引,避免冗余,例如:
组合索引的最左前缀部分,不再创建相同的索引,比如(a,b)和(a),应该去掉(a)
主键字段(a),不再创建(a,b)这样的组合索引
创建索引:
索引的类型:
键索引:主键自动的为主索引(类型primary key)。
唯一索引:UNIQUE。
普通索引:INDEX。
全文索引:FULLTEXT,适用于MyISAM存储引擎。对于全文索引在实际开发中的考虑,要使用Solr或ElasticSearch。
添加索引:
CREATE [UNIQUE] INDEX index_name ON tbl_name (col_name[(length)][ASC|DESC],…);
或
ALTER TABLE tbl_name ADD INDEX [index_name] (index_col_name,…);
2)GaussDB:
合理设计组合索引,避免冗余。
禁止使用外键。
禁止索引总字符串长度超过200(单个索引、组合索引)。
关于NULL约束:
明确不存在NULL 值的字段必须添加NOT NULL 约束
用于WHERE 条件过滤和关联的字段都建议设置NOT NULL 约束
索引(包括单列索引和复合索引)字段建议添加NOT NULL约束
建议给数据表建立业务主键。
说明:使用DRS进行数据迁移或数据同步时,目标数据表上必须要有主键。
创建索引时,如果有联机事务,必须添加CONCURRENTLY参数。
说明:创建索引时,一般会阻塞其他DML对该索引所依赖表的访问,添加CONCURRENTLY参数将不阻塞其他DML操作。
在表上创建索引:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [schema_name.]index_name ] ON table_name
[ USING method ]
({ { column_name [ ( length ) ] | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ]
[ NULLS { FIRST | LAST } ] }[, ...] )
[ INCLUDE ( column_name [, ...] )]
[ WITH ( {storage_parameter = value} [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ];
在分区表上创建索引:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [schema_name.]index_name ] ON table_name
[ USING method ]
( {{ column_name [ ( length ) ] | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ]
[ NULLS LAST ] }[, ...] )
[ LOCAL [ ( { PARTITION index_partition_name | SUBPARTITION index_subpartition_name
[ TABLESPACE index_partition_tablespace ] } [, ...] ) ] | GLOBAL ]
[ INCLUDE ( column_name [, ...] )]
[ WITH ( { storage_parameter = value } [, ...] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ];
重点参数说明:
UNIQUE:
创建唯一性索引,每次添加数据时检测表中是否有重复值。如果插入或更新的值
会引起重复的记录时,将导致一个错误。
目前只有B-tree及UBtree索引支持唯一索引。
CONCURRENTLY:
以不阻塞DML的方式创建索引(加ShareUpdateExclusiveLock锁)。创建索引
时,一般会阻塞其他语句对该索引所依赖表的访问。指定此关键字,可以实现创
建过程中不阻塞DML。
此选项只能指定一个索引的名称。
普通CREATE INDEX命令可以在事务内执行,但是CREATE INDEX
CONCURRENTLY不可以在事务内执行。
列存表不支持CONCURRENTLY方式创建索引。对于临时表,支持使用
CONCURRENTLY关键字创建索引,但是实际创建过程中,采用的是阻塞式的
创建方式,因为没有其他会话会并发访问临时表,并且阻塞式创建成本更
低。
创建索引时指定此关键字,Astore需要执行先后两次对该表的全表扫描来完成build,
第一次扫描的时候创建索引,不阻塞读写操作;第二次扫描的时候合并更新第一次扫描
到目前为止发生的变更;Ustore只需全表扫描一次来完成索引创建。
2.1.3 分区
1)MySQL:
建议只使用RANGE、LIST和HASH最基本的分区方式;分区字段的类型请参照下面的介绍。分区表支持的分区类型:
1-1)RANGE
CREATE TABLE tbl_name .... PARTITION BY RANGE(column) ( PARTITION partition_name1 VALUES LESS THAN (value), …, PARTITION partition_nameN VALUES LESS THAN MAXVALUE)
语法说明:
支持指定一列的值进行RANGE分区。
分区键须为主键的一部分
建议分区键的类型为整型或时间类型
使用时间进行RANGE分区,均支持年、月、日函数。
注:若增加分区,需要人工干预。
实际操作:
创建分区表:
DROP TABLE if exists orders_1; CREATE TABLE orders_1 ( id INT PRIMARY KEY, order_date CHAR(4) , customer_id INT, product_name VARCHAR(255) ) PARTITION BY RANGE (order_date) ( PARTITION p1 VALUES LESS THAN (2021), PARTITION p2 VALUES LESS THAN (2022), PARTITION p3 VALUES LESS THAN (2023), PARTITION P4 VALUES LESS THAN(MAXVALUE));
查询分区信息:
select relname,parttype,parentid,boundaries from pg_partition where parentid in (SELECT parentid FROM pg_partition where relname='orders_1');
修改分区表:
ALTER TABLE orders_1 DROP PARTITION P4; ALTER TABLE orders_1 DROP PARTITION P5; ALTER TABLE orders_1 ADD PARTITION P4 VALUES LESS THAN (2024); ALTER TABLE orders_1 ADD PARTITION P6 VALUES LESS THAN (2025); ALTER TABLE orders_1 ADD PARTITION P4 VALUES LESS THAN (2024); ALTER TABLE orders_1 ADD PARTITION P6 VALUES LESS THAN (2025); ALTER TABLE orders_1 ADD PARTITION P10 VALUES LESS THAN (MAXVALUE); ALTER TABLE orders_1 RENAME PARTITION P10 TO P5;
注意:
GaussDB for PG中不存在类似MySQL的REORGANIZE PARTITION语法用于重新组织表的分区,需要先删除旧分区,然后添加一个新的分区,覆盖旧分区的范围。
1-2)LIST
CREATE TABLE tbl_name .... PARTITION BY LIST(column) ( PARTITION partition_name1 VALUES IN (value)或 PARTITION partition_name1 VALUES (value), …)
语法说明:
只支持按指定一列的值进行LIST分区。
分区键须为主键的一部分
建议分区键的类型为整型或时间类型
原因:MySQL、集中式TDSQL、分布式TDSQL单表如果采用PARTITION BY LIST,那么VALUES中的值只支持整型。如果希望支持字符类型,需要使用PARTITION BY LIST COLUMNS,而Oracle不兼容该语法,因此将该语法作为TDSQL独有语法,不建议使用。
采用LIST分区,程序需要保证不允许有LIST分区之外的值插入。
1-3)HASH
CREATE TABLE tbl_name .... PARTITION BY HASH(column) PARTITIONS num
语法说明:
只支持按指定一列的值进行HASH分区
分区键需要是主键的一部分
支持整型和时间类型(支持年、月、日函数)
分布式TDSQL中的分表不支持HASH二级分区
2)GaussDB:
GaussDB 分布式range、list分布表主键要求必须包含分布列。
当表中的数据量很大时,应当对表进行分区,一般需要遵循以下原则:
【建议】使用具有明显区间性的字段进行分区,比如日期、区域等字段上建立分区。
【建议】分区名称应当体现分区的数据特征。例如,关键字+区间特征。
【建议】将分区上边界的分区值定义为MAXVALUE,以防止可能出现的数据溢出。
|
分区方式 |
描述 |
|
Range |
表数据通过范围进行分区。 |
|
Interval |
表数据通过范围进行分区,超出范围的会自动根据间隔创建新的分区。 |
|
List |
表数据通过指定列按照具体值进行分区。 |
|
Hash |
表数据通过Hash散列方式进行分区。 |
典型的分区表定义如下:
创建Range分区表:
CREATE TABLE staffS_p1
(
staff_ID NUMBER(6) not null,
FIRST_NAME VARCHAR2(20),
LAST_NAME VARCHAR2(25),
EMAIL VARCHAR2(25),
PHONE_NUMBER VARCHAR2(20),
HIRE_DATE DATE,
employment_ID VARCHAR2(10),
SALARY NUMBER(8,2),
COMMISSION_PCT NUMBER(4,2),
MANAGER_ID NUMBER(6),
section_ID NUMBER(4)
)
PARTITION BY RANGE (HIRE_DATE)
(
PARTITION HIRE_19950501 VALUES LESS THAN ('1995-05-01 00:00:00'),
PARTITION HIRE_19950502 VALUES LESS THAN ('1995-05-02 00:00:00'),
PARTITION HIRE_maxvalue VALUES LESS THAN (MAXVALUE)
);
创建Interval分区表,初始两个分区,插入分区范围外的数据会自动新增分区:
CREATE TABLE sales
(prod_id NUMBER(6),
cust_id NUMBER,
time_id DATE,
channel_id CHAR(1),
promo_id NUMBER(6),
quantity_sold NUMBER(3),
amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
INTERVAL('1 day')
( PARTITION p1 VALUES LESS THAN ('2019-02-01 00:00:00'),
PARTITION p2 VALUES LESS THAN ('2019-02-02 00:00:00')
);
创建List分区表:
CREATE TABLE test_list (col1 int, col2 int) partition by list(col1) ( partition p1 values (2000), partition p2 values (3000), partition p3 values (4000), partition p4 values (5000) );
创建Hash分区表:
CREATE TABLE test_hash (col1 int, col2 int) partition by hash(col1) ( partition p1, partition p2 );
2.1.4 修改表
1)MySQL:
修改列的类型时优先使用MODIFY关键字,示例:
ALTER TABLE test_table MODIFY a VARCHAR (11);
TDSQL对表的修改绝大部分操作都会重构数据,可能对业务造成影响。为减少这种影响,必须把对表的多次ALTER操作合并为一次操作。
例如,要给表t增加一个字段b,同时给已有的字段aa建立索引, 通常的做法分为两步:
ALTER TABLE tt ADD COLUMN b VARCHAR(10); ALTER TABLE tt ADD INDEX idx_aa(aa);
正确的做法:
ALTER TABLE tt ADD COLUMN b VARCHAR(10),ADD INDEX idx_aa(aa);
2)Gauss DB:
修改表,包括修改表的定义、重命名表、重命名表中指定的列、重命名表的约束、设
置表的所属模式、添加/更新多个列、打开/关闭行访问控制开关。
修改表的定义:
ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name ) } action [, ... ];
其中具体表操作action可以是以下子句之一:
column_clause | ADD table_constraint [ NOT VALID ] | ADD table_constraint_using_index | VALIDATE CONSTRAINT constraint_name | DROP CONSTRAINT [ IF EXISTS ] constraint_name [ RESTRICT | CASCADE ] | CLUSTER ON index_name
等。
2.2 DML
2.2.1 SELECT
1)MySQL:
1. 查询非重复项使用DISTINCT,禁用QNIQUE
2. 尽量避免子查询
3. 聚合操作
1) 先缩小范围再做聚合等操作,以减少CPU和IO
2) 尽量避免使用类似COUNT(*)的全表扫描查询,从设计上考虑另外用一张表存这个计数值
4. 注意字段类型,避免类型转换,类型转换除了会增加CPU消耗,如果转换失败,还会导致索引失效
5. 尽量避免让数据库做算术运算,交给应用层来做,例如:
SELECT a FROM tbl WHERE id*10=100;
6. 尽量使用UNION ALL,而不是UNION,UNION会做去重和排序
7. WHERE子句使用的原则
1) 尽量使用索引,尤其是主键,尽量简单,尽量匹配到更少的行
2) 即使有索引,WHERE子句匹配的行数也不要超过表的30%,否则效率仍很低
3) 多使用等值操作符,少使用非等值操作符,非等值操作符通常会导致索引失效
8. OR条件大于3个:
1) 不同字段的,使用UNION ALL代替
2) 相同字段的,用IN代替
9. 尽量使用WHERE子句代替HAVING子句,例如:
SELECT id,COUNT(*) FROM tbl GROUP BY id HAVING age>=30;
应该替换为:
SELECT id,COUNT(*) FROM tbl WHERE age>30 GROUP BY id;
10. 一个表的ORDER BY和GROUP BY的组合都不应该超过3种,否则从业务逻辑考虑进行优化或者分成多张表
11. 表关联
1) 数据分库分表后尽量避免跨库表关联
2) 对于大表,建议不多于2张表做关联;对于小表(如配置信息类的)容许超过2张表以上的关联
3) 关联列上要求必须有索引
JOIN/LEFT JOIN/RIGHT JOIN,选择满足应用场景的关联类型
2)Gauss DB:
1.带有LIMIT的分页查询语句中必须带有ORDER BY 保证有序。
2.避免对大字段(如VARCHAR(2000))执行ORDER BY、DISTINCT、GROUP BY、UNION等会引起排序的操作。此类操作将消耗大量的CPU和内存资源,执行效率低下。
3.ORDER BY子句进行排序时,建议显式指定排序方式(ASC/DESC),NULL的排序方式(NULL FIRST/NULL LAST)。
4.禁止使用LOCK TABLE 语句加锁。
说明:LOCK TABLE提供多种锁级别,但如果对数据库原理和业务理解不足,误用表锁可能触发死锁,导致集群不可用。
5.不建议超过3张表或视图进行关联(特别是full join)。
6.建议使用连接操作符“||”替换concat函数进行字符串连接。
说明:concat函数的输出跟data type有关,生成执行计划时不能提前计算结果值,导致查询性能严重劣化。
7.建议使用CURRENT_DATE、CURRENT_TIME、CURRENT_TIMESTAMP(n)代替now函数获取当前时间。
说明:now函数生成的执行计划无法下推,导致查询性能严重劣化。
8.当in(val1, val2, val3…)表达式中字段较多时,建议使用in (values(va11), (val2),(val3)…)语句进行替换。
说明:优化器会自动把in约束转换为非关联子查询,从而提升查询性能。
9.若join列上的NULL值较多,则可以加上is not null过滤条件,以提前过滤数据,提高join效率。
10.多表关联查询时, 建议对表添加使用别名,保证语句逻辑清晰,便于维护。
11.子查询深度不建议超过2层。
2.2.2 INSERT
1)MySQL:
1. 多条INSERT语句要合并成一条批量提交,建议一次不要超过1000行数据
2. 禁止使用INSERT INTO tbl(),必须显示指明字段,示例:
INSERT INTO tbl_name(a,b,c) VALUES(1,2,3);
2)Gauss DB:
1.在批量数据入库之后,或者数据增量达到一定阈值后,建议对表进行analyze操作,防止统计信息不准确而导致的执行计划劣化。
2.INSERT ON DUPLICATE KEY UPDATE 不支持对主键或唯一约束的列上执行UPDATE。
说明:INSERT ON DUPLICATE KEY UPDATE的语义是对唯一约束冲突的行进行更新,这个过程中不应对约束的值进行更新。
3.不建议对存在多个唯一约束的表执行INSERT ON DUPLICATE KEY UPDATE。
说明:当存在多个唯一约束时,会默认检查所有的唯一约束条件,只要任何一个约束存在冲突,就会对冲突行进行更新,即可能更新多条记录,与业务预期不相符。业务应给予更加明确的插入更新条件。
4.对于批量插入的情况,建议使用executeBatch 执行INSERT INTO VALUES (?),执行效率将高于执行多条INSERT INTO VALUES(?)或INSERT INTO VALUES(?),...,(?)。
5.批量插入数据量不宜过大,建议单次批量数据条数不超过1000。
2.2.3 UPDATE
1)MySQL:
1. 必须带WHERE条件,最好使用主键
2. 控制一次性更新的数据记录,建议在1万条记录以内,以避免引起事务持有锁的时间过长,甚至可能因为单个事务的binlog太大导致强同步阻塞
3. 不使用不确定值的函数,比如RAND ()和NOW()
4. 禁止在UPDATE语句中,将“,”写成AND,例如:
UPDATE tbl SET fid=fid+1000, gid=gid+1000 WHERE id > 2;
如果写成
UPDATE tbl SET fid=fid+1000 AND gid=gid+1000 WHERE id > 2;
此时“fid+1000 AND gid=gid+1000”将作为值赋给fid,且没有Warning。
2)GaussDB:
1.不建议UPDATE 语句中直接使用LIMIT,应使用WHERE 条件明确需要更新的目标行。
2.禁止在UPDATE 更新多个列时,被更新列同样是更新源。
说明:同时更新多列,且更新源相同,在不同的数据库下行为不同,避免带来兼容性问题。
UPDATE table SET col1 = col2, col3 = col1 WHERE col1 = 1;
该语句在Oracle中,col3的值为原col1的值;而MySQL中,col3的值为col2的值(因为col2的值被赋予给了col1)。
3.UPDATE 语句中禁止使用ORDER BY、GROUP BY 子句,避免不必要的排序。
4.有主键/索引的表,更新时WHERE条件应结合主键/索引。
5.对于频繁更新的表,建议应用使用VACUUM进行清理。
2.2.4 DELETE
1)MySQL:
1. 必须带WHERE条件,最好使用主键
2. 控制一次性删除的数据记录,建议在1万条记录以内,以避免引起事务持有锁的时间过长,甚至可能因为单个事务的binlog太大导致强同步阻塞
3. 不使用不确定值的函数,比如RAND ()和NOW()
2)GaussDB:
1.不建议DELETE 语句中使用LIMIT。应使用WHERE条件明确需要删除的目标行。
2.DELETE 有主键或索引的表,WHERE 条件应结合主键或索引,提高执行效率。
3.DELETE语句中禁止使用ORDER BY、GROUP BY子句,避免不必要的排序。
2.2.5 WHERE
1)MySQL:
2)Gauss DB:
1.关于NULL
1)、查询条件中与NULL做比较时,必须使用IS NULL或IS NOT NULL
2)、在关联字段不存在NULL值的情况下,使用(not) exist代替(not) in
2.查询条件中不建议对索引字段使用“!= ”比较符,避免索引失效。
3.查询条件的索引字段上不建议NOT IN。
4.如果过滤条件只有OR表达式,建议将OR表达式转化为UNION ALL以提升性能。使用OR的SQL语句经常无法优化,导致执行速度慢。
5.exists/not exists子查询中含大表的查询条件时,建议增加/*+ no_expand*/提示
说明:优化器可能会自动将exists/not exists子查询展开,一旦子查询中含有大表,优化器则无法找到最优执行计划,从而变成慢SQL
6.禁止在SELECT 目标列中使用子查询,子查询作为过滤条件会使索引失效,从而导致全表扫描。
如:select (select ...),t2.c2 from t2 WHERE ...
3 其他注意点
3.1 MySQL和GaussDB不兼容语法处理建议
以下是在GaussDB PG和MySQL之间的一些主要的SQL语法不兼容性。这个列表包含了一些主要的不同之处,但并不是全部的不兼容性。在进行迁移之前,建议深入对比和测试以确保兼容性。
|
MySQL |
GaussDB |
备注 |
|
AUTO_INCREMENT |
SERIAL |
序列生成器 |
|
SHOW TABLES |
\dt |
查看所有表 |
|
SHOW DATABASES |
\l |
查看所有数据库 |
|
LIMIT n OFFSET m |
LIMIT n OFFSET m 或 FETCH FIRST n ROWS ONLY OFFSET m |
分页查询 |
|
DESCRIBE table or DESC table |
\d table |
描述表结构 |
|
CONCAT(str1, str2, ...) |
str1 || str2 |
拼接字符串 |
|
SUBSTRING(str, pos, len) |
SUBSTRING(str FROM pos FOR len) |
子字符串 |
|
LENGTH(str) |
LENGTH(str)或CHAR_LENGTH(str) |
字符串长度 |
|
CURDATE() |
CURRENT_DATE |
当前日期 |
|
NOW() |
CURRENT_TIMESTAMP |
当前事件 |
|
RAND() |
RANDOM() |
生成随机数 |
|
IFNULL(exp, replace_exp) |
COALESCE(exp, replace_exp) |
判断表达式是否为空 |
|
ISNULL(exp) |
exp IS NULL |
判断表达式是否为空 |
|
`作为标识符引用符 |
“作为标识符引用符 |
标识符引用符 |
|
存储过程使用BEGIN和END |
存储过程使用$$ |
存储过程定义 |
|
TRUNCATE TABLE不可在事务中 |
TRUNCATE TABLE可在事务中 |
清空表数据 |
|
REPALCE INTO |
INSERT ... ON CONFLICT DO UPDATE |
插入冲突更新 |
|
REGEXP |
~ |
正则表达式搜索 |
|
CREATE DATABASE 不支持所有者 |
CREATE TABLE支持所有者 |
创建数据库 |
|
ENUM类型 |
无对应,可用CHECK约束代替 |
类型不一致 |
|
SET类型 |
无对应,可用ARRAY类型代替 |
类型不一致 |
|
YEAR类型 |
无对应,可用INTERVAL YEAR或DATE类型代替 |
类型不一致 |
|
UNSIGNED类型 |
无对应,需注意数值范围 |
类型不一致 |
|
ZEROFILL类型 |
无对应,需在应用层处理 |
类型不一致 |
|
SHOW CREATE TABLE |
pg_dump -t table -s |
查看表创建语句 |
|
ENGINE = InnoDB |
无对应 |
存储引擎 |
|
CHARSET = utf8mb4 |
ENCODING = UTF8 |
字符集 |
|
COLLATE = utf8mb4_bin |
COLLATE “C” |
排序规则 |
|
分区表 |
分区表 |
分区定义语法不同 |
|
CREATE USER |
CREATE ROLE |
创建用户 |
|
REVOKE ALL PRIVILEGES |
REVOKE ALL |
撤销权限 |
|
GRANT SELECT ON *.* |
GRANT SELECT ON ALL TABLES IN SCHEMA |
授予权限 |
|
/*!50003 CREATE */ |
CREATE OR REPLACE |
创建或替换 |
|
LOCK TABLES |
LOCK TABLE |
锁表 |
|
UNLOCK TABLES |
COMMIT |
解锁 |
|
KILL QUERY |
CANCEL |
取消查询 |
|
SHOW PROCESSLIST |
SELECT * FROM pg_stat_activity |
查看进程列表 |
|
LOAD DATA INFILE |
COPY |
数据导入 |
|
SELECT INTO OUTFILE |
COPY TO |
数据导出 |
|
RENAME COLUMN |
ALTER COLUMN RENAME |
重命名列 |
|
RENAME INDEX |
ALTER INDEX RENAME |
重命名索引 |
|
RENAME DATABASE |
无对应 |
重命名数据库 |
|
ALTER DATABASE不支持修改所有者 |
ALTER DATABASE支持修改所有者 |
修改数据库所有者 |
|
ALTER DATABASE支持修改字符集和排序规则 |
ALTER DATABASE 不支持修改字符集和排序规则 |
修改数据库字符集和排序规则 |
|
ALTER TABLE支持一次修改多个列 |
ALTER TABLE一次只能修改一个列 |
修改表列 |
|
ALTER TABLE支持一次添加多个索引 |
ALTER TABLE一次只能添加一个索引 |
添加表索引 |
|
ALTER TABLE支持一次删除多个索引 |
ALTER TABLE一次只能删除一个索引 |
删除表索引 |
|
ALTER TABLE支持修改存储引擎 |
ALTER TABLE不支持修改存储引擎 |
修改表存储引擎 |
|
ALTER TABLE支持修改字符集和排序规则 |
ALTER TABLE不支持修改字符集和排序规则 |
修改表字符集和排序规则 |
|
ALTER TABLE支持修改自增值 |
ALTER TABLE不支持修改自增值 |
修改表自增值 |
3.2 语法差异
|
描述 |
MySQL |
GaussDB PG |
|
插入并存在时更新 |
REPLACE INTO或INSERT ... ON DUPLICATE KEY UPDATE ... |
INSERT...ON CONFLICT DO UPDATE... |
|
使用LIMIT进行分页查询 |
SELECT ... LIMIT offset,count |
SELECT ... LIMIT count OFFSET offset |
|
单行插入返回插入的ID |
INSERT INTO ...;SELECT LAST_INSERT_ID() |
INSERT INTO ... RETURNING id |
|
单行更新返回更新的行 |
UPDATE...;SELECT...; |
UPDATE ... RETURNING *; |
|
单行删除返回删除的行 |
DELETE...;SELECT...; |
DELETE...RETURNING*; |
|
随机获取一行记录 |
SELECT...ORDER BY RAND() LIMIT 1; |
SELECT...ORDER BY RANDOM() LIMIT 1; |
|
索引字段查询优化 |
SELECT * FROM table USE INDEX(index) WHERE column = value; |
SET enable_seqscan TO OFF;SELECT * FROM table WHERE column = value;SET enable_seqscan TO ON; |
|
使用全文索引搜索 |
MATCH(column) AGAINST(‘text’) |
to_tsvector(column) @@ to_tsquery(‘text’) |
|
查询特定范围的行 |
SELECT * FROM table LIMIT x,y |
SELECT * FROM table LIMIT y OFFSET x |
|
使用存储过程 |
CALL procedure_name() |
SELECT * FROM procedure_name() |
|
事务处理 |
START TRANSACTION; COMMIT; ROLLBACK; |
BEGIN; COMMIT; ROLLBACK; |
|
创建临时表 |
CREATE TEMPORARY TABLE table_name |
CREATE TEMP TABLE table_name |
|
MySQL使用反引号(``)引用表名和列名 |
SELECT column FROM table |
SELECT “column” FROM “table” |
|
时间和日期函数 |
DATE(),NOW(),YEAR(),MONTH(), DAY(),HOUR(),MINUTE(), SECOND() |
CURRENT_DATE, CURRENT_TIME, DATE_PART(‘year’, column), DATE_PAR column), DATE_PART(‘day’, column), DATE_PART(‘hour’, column), DATE_PART column), DATE_PART(‘second’, column) |
|
字符串连接函数 |
CONCAT(column1, column2) |
column1 || column2 |
|
对分组的限制 |
SELECT … FROM … GROUP BY … WITH ROLLUP |
SELECT … FROM … GROUP BY … ROLLUP(…) |
|
对NULL的处理 |
SELECT IFNULL(column, 0) FROM table |
SELECT COALESCE(column, 0) FROM table |
|
判断是否为空 |
SELECT column IS NULL FROM table |
SELECT column IS NULL FROM table |
|
日期加减操作 |
SELECT DATE_ADD(date, INTERVAL 1 DAY) FROM table |
SELECT date + INTERVAL ‘1 day’ FROM table |
|
创建自增主键 |
CREATE TABLE table(id INT AUTO_INCREMENT, PRIMARY KEY(id)) |
CREATE TABLE table(id SERIAL PRIMARY KEY) |
|
使用正则表达式匹配数据 |
SELECT column REGEXP ‘pattern’ FROM table |
SELECT column ~ ‘pattern’ FROM table |
|
计算平均值 |
SELECT AVG(column) FROM table |
SELECT AVG(column) FROM table |
|
计算最大值 |
SELECT MAX(column) FROM table |
SELECT MAX(column) FROM table |
|
计算最小值 |
SELECT MIN(column) FROM table |
SELECT MIN(column) FROM table |
|
计算总和 |
SELECT SUM(column) FROM table |
SELECT SUM(column) FROM table |
|
计算记录数 |
SELECT COUNT(column) FROM table |
SELECT COUNT(column) FROM table |
|
使用内置数学函数 |
SELECT ABS(column), CEIL(column), FLOOR(column), ROUND(column) FROM table |
SELECT ABS(column), CEILING(column), FLOOR(column), ROUND(column) FROM table |
|
使用内置字符串函数 |
SELECT CHAR_LENGTH(column), LOWER(column), UPPER(column), REVERSE(column) FROM table |
SELECT LENGTH(column), LOWER(column), UPPER(column), REVERSE(column) FROM table |
|
使用内置日期函数 |
SELECT CURRENT_DATE(), CURRENT_TIME(), DATE_FORMAT(date, ‘format’) FROM table |
SELECT CURRENT_DATE, CURRENT_TIME, TO_CHAR(date, ‘format’) FROM table |
|
使用内置转换函数 |
SELECT CAST(column AS type) FROM table |
SELECT CAST(column AS type) FROM table |
4 数据迁移案例
4.1 登陆GaussDB服务器
登陆服务器,在开发环境登陆XXX.XXX.XXX.XXX这个高斯节点。
例如使用MobaXterm。打开软件,连接该节点XXX.XXX.XXX.XXX。
输入密码进行登录。
然后,输入命令cd /opt/bin。
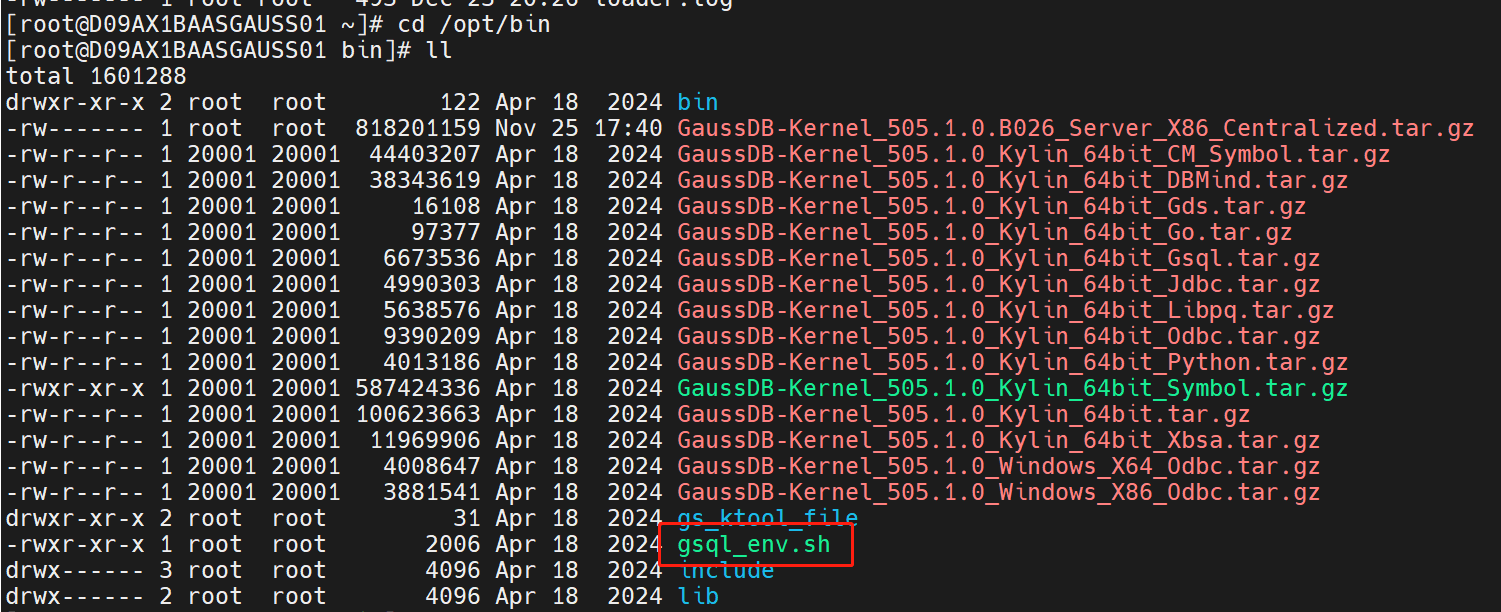
然后运行脚本,输入命令source gsql_env.sh。

然后登录数据库,输入命令gsql -h XXX.XXX.XXX.XXX -d postgres -U root -p 8000 -W password。就可以进行相关的操作了。
4.2 创建数据库
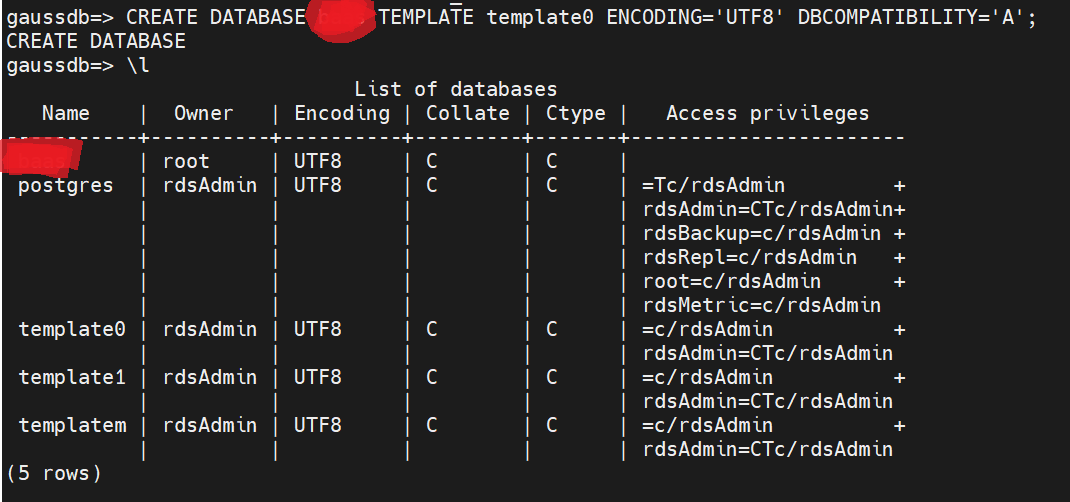
在gaussdb目录下执行CREATE DATABASE XXXX TEMPLATE template0 ENCODING='UTF8' DBCOMPATIBILITY='A';来创建XXXX数据库。
然后在gaussdb目录下执行\l,来查看建好的数据库信息。
4.3 建表
执行命令\c XXXX来选择使用XXXX库,输入密码可以登录。
然后进行建表操作,执行如下样例建表语句。
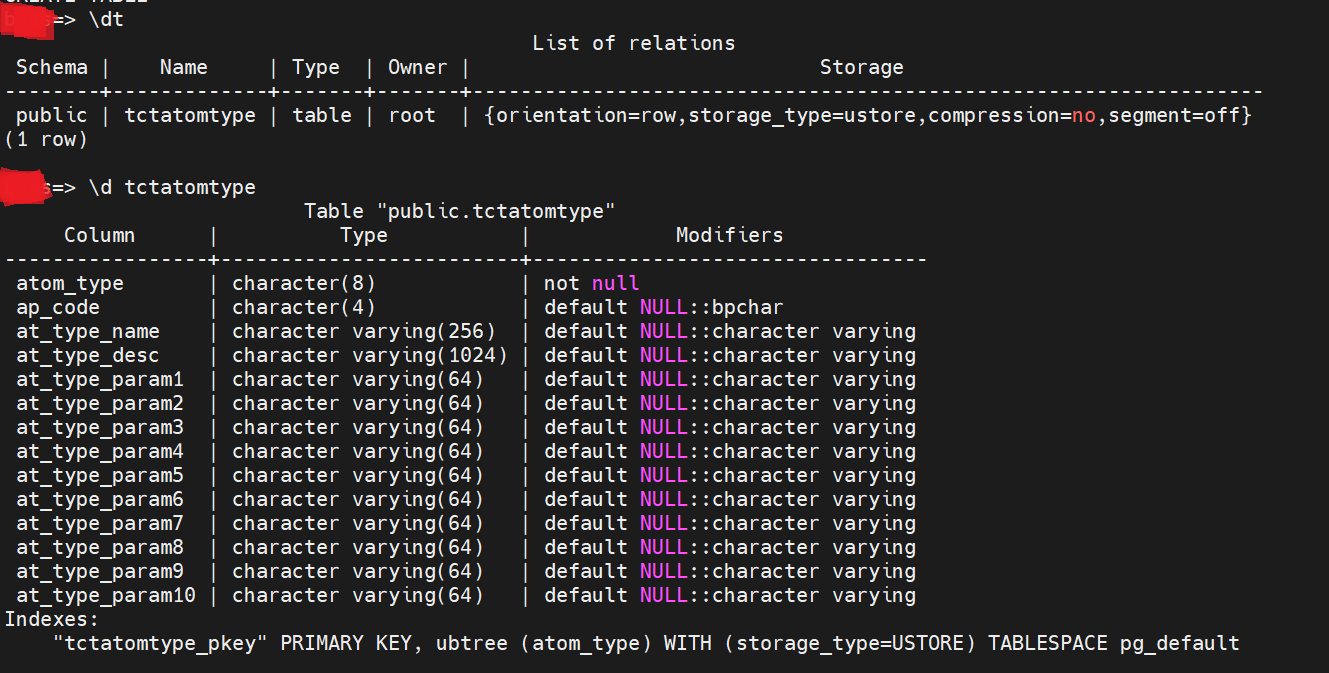
CREATE TABLE IF NOT EXISTS tctatomtype ( atom_type char(8) NOT NULL, ap_code char(4) DEFAULT NULL, at_type_name varchar(256) DEFAULT NULL, at_type_desc varchar(1024) DEFAULT NULL, at_type_param1 varchar(64) DEFAULT NULL, at_type_param2 varchar(64) DEFAULT NULL, at_type_param3 varchar(64) DEFAULT NULL, at_type_param4 varchar(64) DEFAULT NULL, at_type_param5 varchar(64) DEFAULT NULL, at_type_param6 varchar(64) DEFAULT NULL, at_type_param7 varchar(64) DEFAULT NULL, at_type_param8 varchar(64) DEFAULT NULL, at_type_param9 varchar(64) DEFAULT NULL, at_type_param10 varchar(64) DEFAULT NULL, PRIMARY KEY(atom_type) ) WITH (orientation=row,storage_type = USTORE);

建表完成之后,在XXXX目录下执行\dt 来查看数据库里的表信息。
还可以在XXXX目录下执行\d tctatomtype来查看tctatomtype的建表信息。
4.4 使用DataX进行迁移
4.4.1 安装DataX
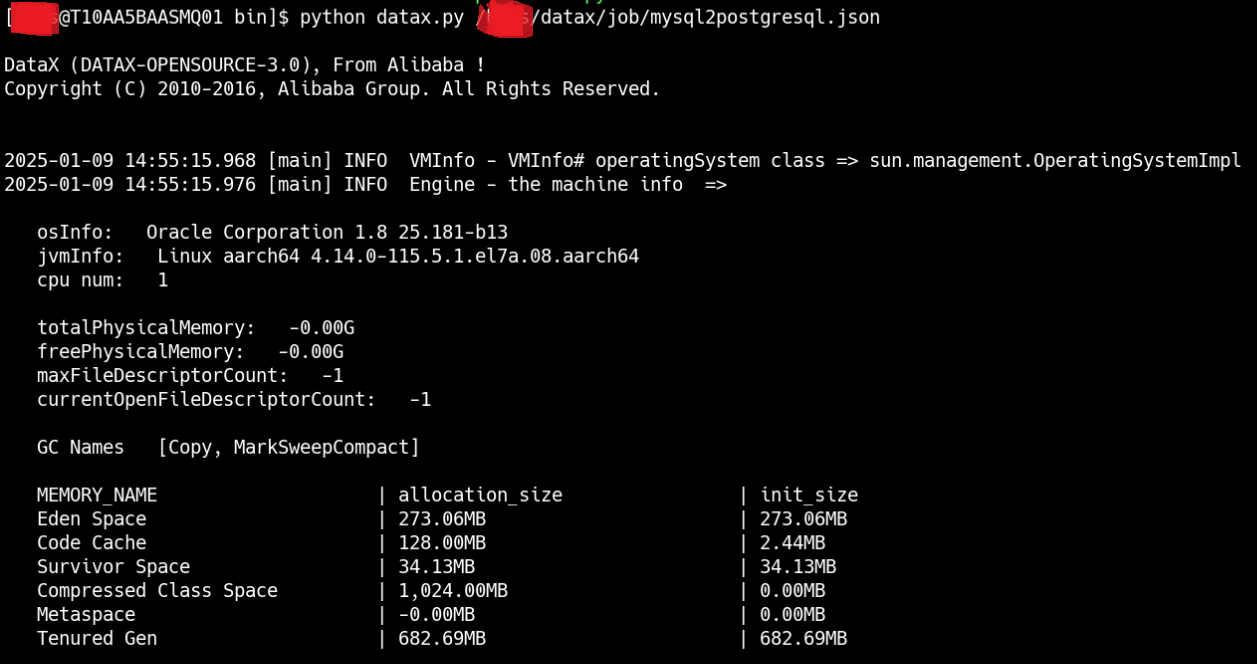
配置示例:从stream读取数据并打印到控制台
1)创建配置文件(json格式):
通过命令查看配置模板:python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
例如:python datax.py -r streamreader -w streamwriter
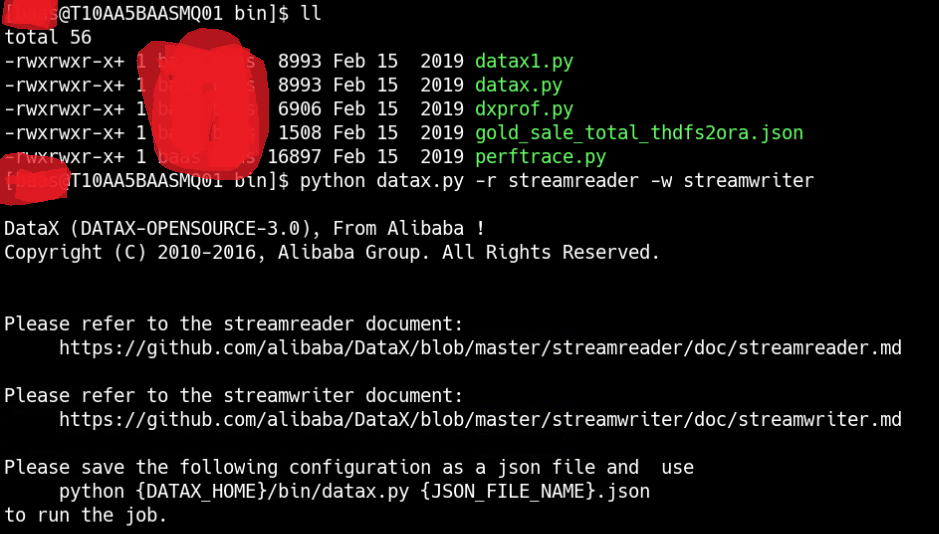
得到配置模板:
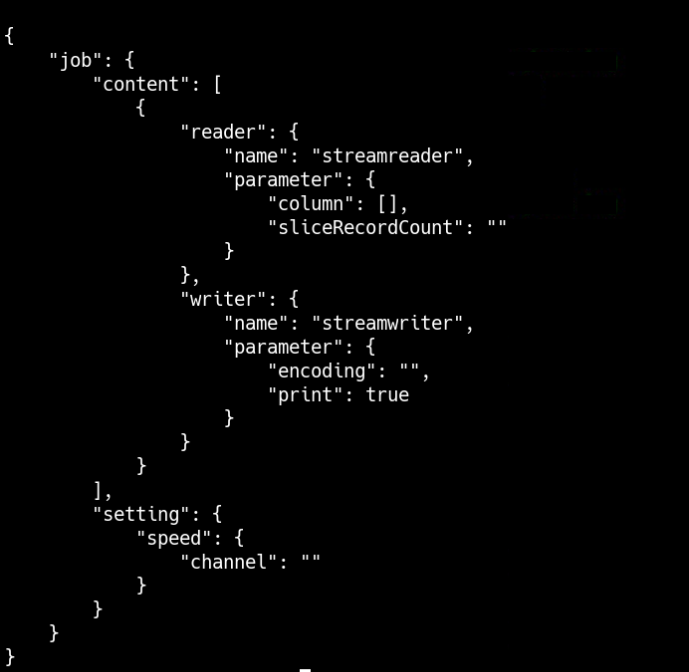
根据模板配置来配置脚本:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello, 你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
将该脚本上传至/XXXX/datax/job下,并执行chmod +x stream2stream.json,赋予执行权限。
2)启动DataX:
在/XXXX/datax/bin目录下来执行如下命令:
python datax.py /xxxx/datax/job/stream2stream.json
可以看到运行结果:
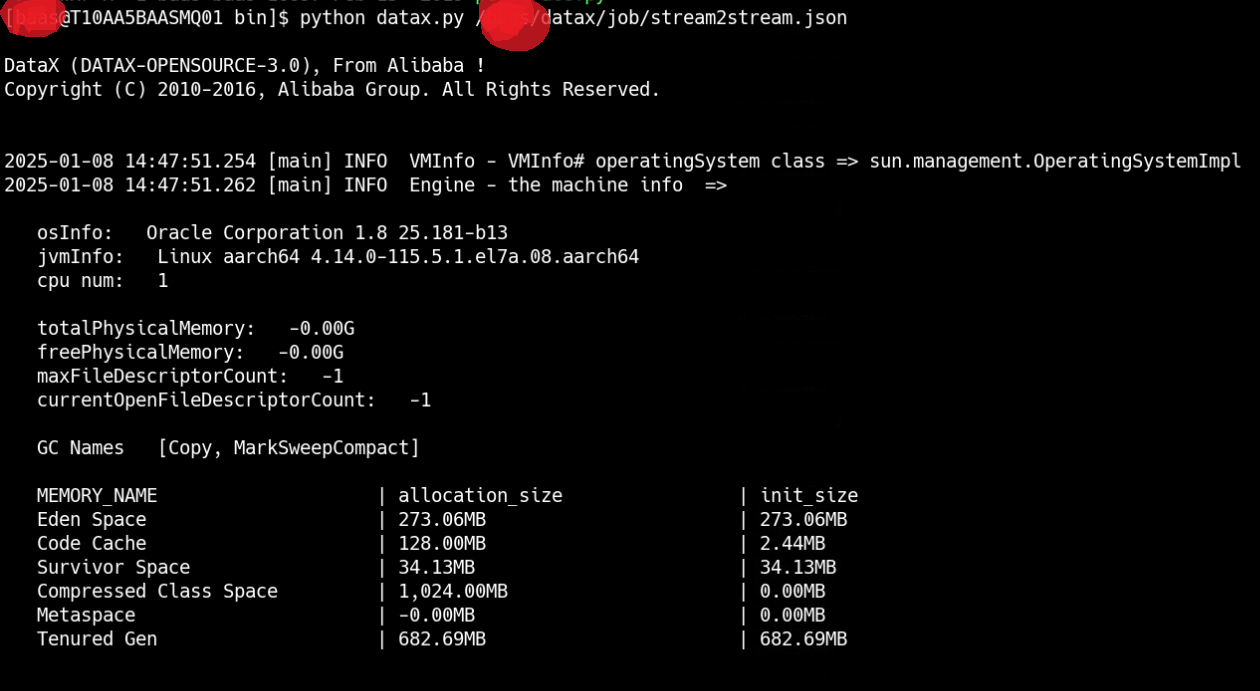
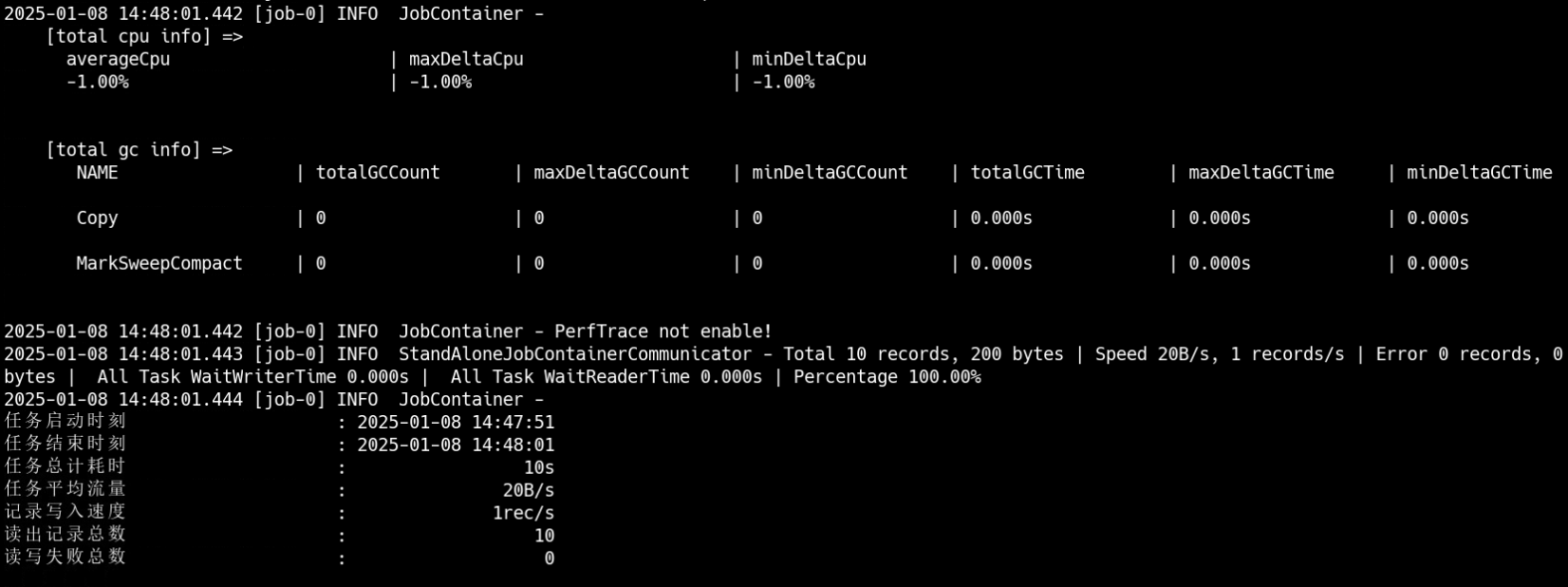
可以看到完成数据迁移。
4.4.2 DataX内部类型与MySQL和GaussDB的关系
|
DataX数据类型 |
MySQL表数据类型 |
GaussDB For PG表数据类型 |
|
long |
int,tinyint,smallint,mediumint,int,bigint,year |
bigint,bigserial,integer,smallint,serial |
|
double |
float,double,decimal |
double precision,money, numeric,real |
|
string |
nvarchar,char,tinytext,text,mediumtext,longtext |
nvarchar,char,text,bit,inet |
|
boolean |
bit,bool |
bool |
|
date |
Date,datetime,timestamp,time |
date,time,timestamp |
|
bytes |
tinyblob,mediumblob,blob,longblob,varbinary |
bytea |
4.4.3 创建校验数据表
创建一个check_data表来对数据量做校验来对迁移时间做记录。
CREATE TABLE IF NOT EXISTS check_data ( table_name VARCHAR(200) NOT NULL, mysql_num BIGINT DEFAULT NULL, pgsql_num BIGINT DEFAULT NULL, start_time TIMESTAMP DEFAULT NULL, end_time TIMESTAMP DEFAULT NULL, sql_state VARCHAR(4) DEFAULT NULL, PRIMARY KEY(table_name) ) WITH (orientation=row,storage_type = USTORE);
4.4.4 实际数据迁移测试
1)表结构信息:
选择XXXX里的某张配置表来进行数据迁移实验。选择控制交易类型的TCTATOMTYPE表来进行测试。
在TDSQL中,查看TCTATOMTYPE表的建表:
CREATE TABLE `tctatomtype` ( `atom_type` char(2) COLLATE utf8_bin NOT NULL, `ap_code` char(1) COLLATE utf8_bin DEFAULT NULL, `at_type_name` varchar(64) COLLATE utf8_bin DEFAULT NULL, `at_type_desc` varchar(256) COLLATE utf8_bin DEFAULT NULL, `at_type_param1` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param2` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param3` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param4` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param5` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param6` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param7` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param8` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param9` varchar(16) COLLATE utf8_bin DEFAULT NULL, `at_type_param10` varchar(16) COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`atom_type`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
对应的在GaussDB中的建表:
CREATE TABLE IF NOT EXISTS tctatomtype ( atom_type char(8) NOT NULL, ap_code char(4) DEFAULT NULL, at_type_name varchar(256) DEFAULT NULL, at_type_desc varchar(1024) DEFAULT NULL, at_type_param1 varchar(64) DEFAULT NULL, at_type_param2 varchar(64) DEFAULT NULL, at_type_param3 varchar(64) DEFAULT NULL, at_type_param4 varchar(64) DEFAULT NULL, at_type_param5 varchar(64) DEFAULT NULL, at_type_param6 varchar(64) DEFAULT NULL, at_type_param7 varchar(64) DEFAULT NULL, at_type_param8 varchar(64) DEFAULT NULL, at_type_param9 varchar(64) DEFAULT NULL, at_type_param10 varchar(64) DEFAULT NULL, PRIMARY KEY(atom_type) ) WITH (orientation=row,storage_type = USTORE);
共计14个字段。
2)迁移脚本准备:
在/XXXX/datax/bin目录下执行命令python datax.py -r mysqlreader -w postgresqlwriter。
得到TDSQL迁移GaussDB的模板。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"postSql": [],
"preSql": [],
"username": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
3)准备校验数据表:
在GaussDB中出创建一张表来记录数据迁移的信息和两个数据库的数据校验。
CREATE TABLE IF NOT EXISTS check_data ( table_name VARCHAR(200) NOT NULL, mysql_num BIGINT DEFAULT NULL, start_time TIMESTAMPTZ[6] DEFAULT NULL, end_time TIMESTAMPTZ[6] DEFAULT NULL, sql_state VARCHAR(4) DEFAULT NULL, PRIMARY KEY(table_name) ) WITH (orientation=row,storage_type = USTORE);
4)填写迁移脚本:
按照要迁移的数据库和数据表信息来完成迁移脚本的填写。
命名为mysql2postgresql.json。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["atom_type","ap_code","at_type_name","at_type_desc","at_type_param1",
"at_type_param2","at_type_param3","at_type_param4","at_type_param5",
"at_type_param6","at_type_param7","at_type_param8","at_type_param9",
"at_type_param10"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://XXXX/XXXX"],
"table": ["tctatomtype"]
}
],
"password": "XXXXXXXX",
"username": "XXXX"
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"column": ["atom_type","ap_code","at_type_name","at_type_desc","at_type_param1",
"at_type_param2","at_type_param3","at_type_param4","at_type_param5",
"at_type_param6","at_type_param7","at_type_param8","at_type_param9",
"at_type_param10"],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://XXXXX/XXXX",
"table": ["tctatomtype"]
}
],
"password": "XXXXX",
"postSql": ["update check_data set pgsql_num = (select count(1) from tctatomtype),end_time = current_timestamp,sql_state = '2' where table_name = 'tctatomtype'"],
"preSql": ["update check_data set start_time = current_timestamp,sql_state = '1' where table_name = 'tctatomtype'"],
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
然后上传至/XXXX/datax/job路径下。

5)执行迁移数据脚本:
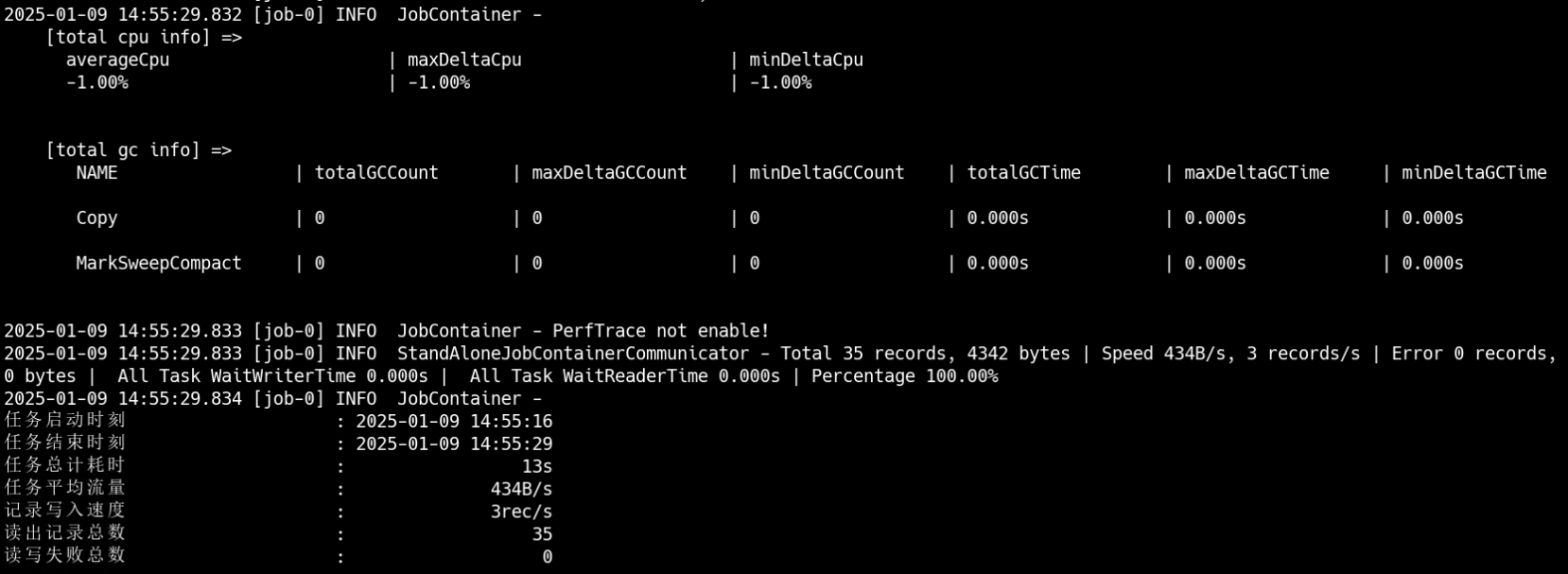
在/XXXX/datax/bin路径下执行命令:python datax.py /XXXX/datax/job/mysql2postgresql.json
但是可以看到会有报错,如下所示:
错误信息为:org.postgresql.util.PSQLException: The authentication type 10 is not supported. Check that you have configured the pg_hba.conf file to include the client's IP address or subnet, and that it is using an authentication scheme supported by the driver.]
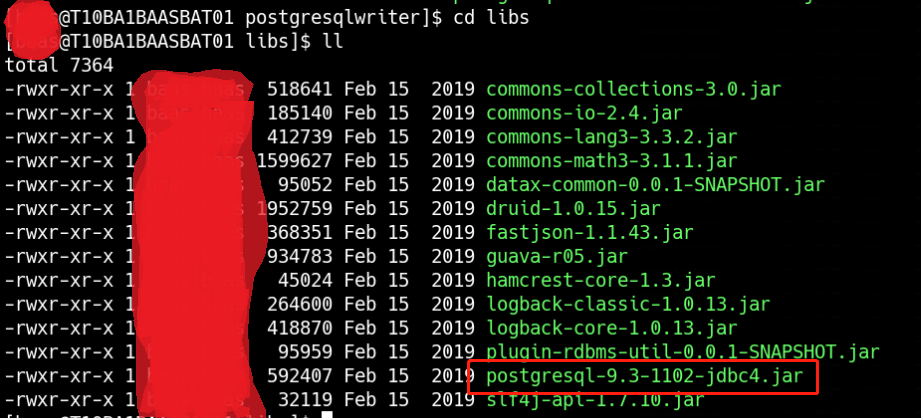
这个报错的原因是postgresql驱动版本低不匹配,需要更新驱动,但是由于是使用GaussDB,因此不能使用原生的postgresql驱动来进行替换升级。登陆GaussDB官网,下载dws_8.1.x_jdbc_driver.zip这个压缩包,解压后找到gsjdbc4.jar,来替换/baas/datax/plugin/writer/postgresqlwriter/libs中的postgresql-9.3-1102-jdbc4.jar。
最终结果如下:
替换前:
共计14个字段。
2)迁移脚本准备:
在/XXXX/datax/bin目录下执行命令python datax.py -r mysqlreader -w postgresqlwriter。
得到TDSQL迁移GaussDB的模板。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"postSql": [],
"preSql": [],
"username": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
3)准备校验数据表:
在GaussDB中出创建一张表来记录数据迁移的信息和两个数据库的数据校验。
CREATE TABLE IF NOT EXISTS check_data ( table_name VARCHAR(200) NOT NULL, mysql_num BIGINT DEFAULT NULL, start_time TIMESTAMPTZ[6] DEFAULT NULL, end_time TIMESTAMPTZ[6] DEFAULT NULL, sql_state VARCHAR(4) DEFAULT NULL, PRIMARY KEY(table_name) ) WITH (orientation=row,storage_type = USTORE);
4)填写迁移脚本:
按照要迁移的数据库和数据表信息来完成迁移脚本的填写。
命名为mysql2postgresql.json。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["atom_type","ap_code","at_type_name","at_type_desc","at_type_param1",
"at_type_param2","at_type_param3","at_type_param4","at_type_param5",
"at_type_param6","at_type_param7","at_type_param8","at_type_param9",
"at_type_param10"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://XXXX/XXXX"],
"table": ["tctatomtype"]
}
],
"password": "XXXX",
"username": "XXXX"
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"column": ["atom_type","ap_code","at_type_name","at_type_desc","at_type_param1",
"at_type_param2","at_type_param3","at_type_param4","at_type_param5",
"at_type_param6","at_type_param7","at_type_param8","at_type_param9",
"at_type_param10"],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://XXXX/XXXX",
"table": ["tctatomtype"]
}
],
"password": "XXXX",
"postSql": ["update check_data set pgsql_num = (select count(1) from tctatomtype),end_time = current_timestamp,sql_state = '2' where table_name = 'tctatomtype'"],
"preSql": ["update check_data set start_time = current_timestamp,sql_state = '1' where table_name = 'tctatomtype'"],
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
然后上传至/XXXX/datax/job路径下。

5)执行迁移数据脚本:
在/xxxx/datax/bin路径下执行命令:python datax.py /xxxx/datax/job/mysql2postgresql.json
但是可以看到会有报错,如下所示:
错误信息为:org.postgresql.util.PSQLException: The authentication type 10 is not supported. Check that you have configured the pg_hba.conf file to include the client's IP address or subnet, and that it is using an authentication scheme supported by the driver.]
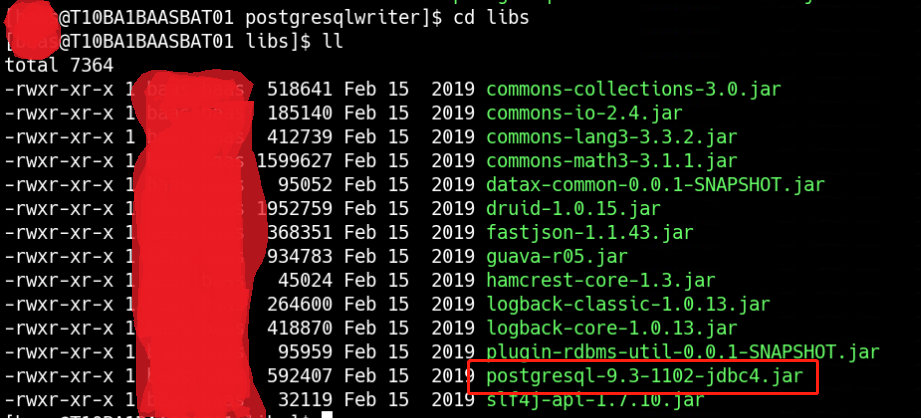
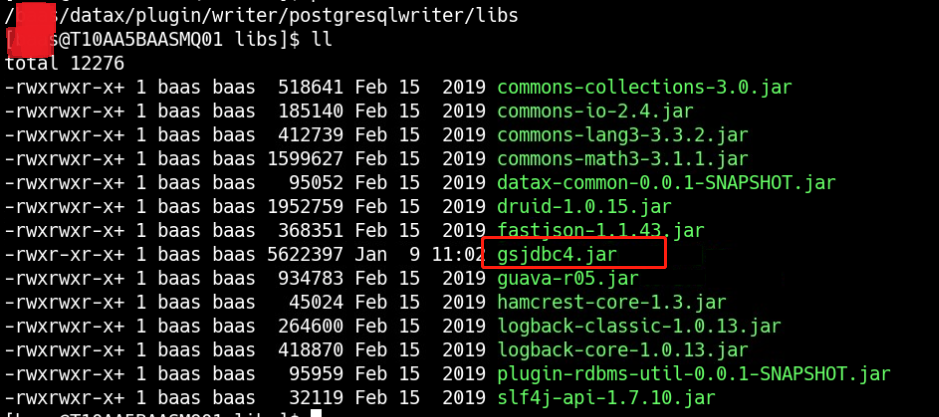
这个报错的原因是postgresql驱动版本低不匹配,需要更新驱动,但是由于是使用GaussDB,因此不能使用原生的postgresql驱动来进行替换升级。登陆GaussDB官网,下载dws_8.1.x_jdbc_driver.zip这个压缩包,解压后找到gsjdbc4.jar,来替换/baas/datax/plugin/writer/postgresqlwriter/libs中的postgresql-9.3-1102-jdbc4.jar。
最终结果如下:
替换前:
替换后:
然后再在/XXXX/datax/bin路径下执行命令:python datax.py /XXXX/datax/job/mysql2postgresql.json,可以看到数据完成迁移。
数据查看:
check_data表,TDSQL和GaussDB数据量一致:
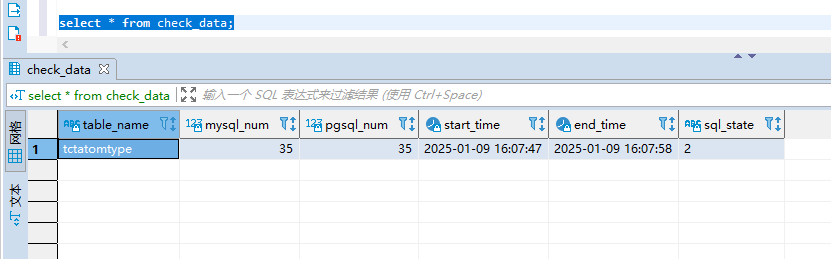
校对后迁移结果与在TDSQL上的表一致。
4.4.5数据迁移前准备
在check_data表中有table_name和mysql_num字段,需要在数据迁移之前来填充。
这块也使用DataX来完成,执行的脚本为check_data.json。
具体如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "baas",
"password": "XXXX",
"connection": [
{
"querySql": [
"select 'tctatomtype' as table_name,count(1) as mysql_num from tctatomtype"],
"jdbcUrl": [
"jdbc:mysql://XXXX/XXXX"
]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"column": ["table_name","mysql_num"],
"connection": [{
"jdbcUrl": "jdbc:postgresql://XXXX/XXXX",
"table": ["check_data"]
}],
"preSql":["delete from check_data"],
"password": "XXXX",
"username": "root"
}
}
}]
}
}
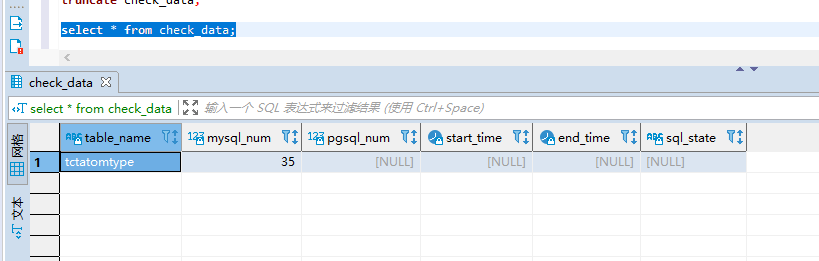
在/XXXX/datax/bin目录下执行python datax.py /XXXX/datax/job/check_data.json,迁移成功之后可以看到:
5 数据迁移实战
本次数据迁移工作是从TDSQL(MySQL)迁移到GaussDB for PG,总共704张表。
5.1 DDL
5.1.1字段
TDSQL中使用的字段和一些关键字与GaussDB for PG的对应关系:
|
序号 |
TDSQL字段或关键字 |
GaussDB for PG相应替代 |
备注 |
|
1 |
bigint |
bigint |
GaussDB for PG中bigint为有符号数,存储范围为-9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807。 TDSQL中bigint可以存储无符号数的范围是0~18446744073709551615,而对有符号数的存储范围是-9223372036854775808~9223372036854775807。 |
|
2 |
varchar |
varchar |
GaussDB for PG中varchar为字节,TDSQL中varchar为字符。 需要进行相应的换算。 |
|
3 |
timestamp |
timestamp |
GaussDB for PG中,timestamp类型用于存储带有日期和时间部分的值,其范围是公元0001年01月01日 00:00:00.000000至公元9999年12月31日 23:59:59.999999 TDSQL中timestamp存储时间范围为1970-01-01 00:00:00 UTC ~ 2038-01-19 03:14:07。 建议对TDSQL中的timestamp进行替换。 |
|
4 |
longblob |
blob |
GaussDB for PG中,blob最大为32TB(即35184372088832字节)。 TDSQL中,longblob最大4294967295B,约4GB。 GaussDB for PG的blob可以包含TDSQL的longblob。 |
|
5 |
tinyint |
tinyint |
GaussDB for PG中tinyint为无符号数,存储范围为0 ~ 255。 TDSQL中tinyint对于无符号的数的存储范围是0~255,而对于有符号数的存储范围为-128~127。 |
|
6 |
int |
integer |
GaussDB for PG中integer为有符号数,存储范围为-2,147,483,648 ~ +2,147,483,647。 TDSQL中tinyint可以存储无符号数据的范围为0~4294967295,而对无符号数的存储范围是-2147483648~2147483647。 需要判断GaussDB for PG中integer作为有符号数的存储范围是否够,如果不够需要换bigint。 |
|
7 |
datetime |
timestamp |
GaussDB for PG中timestamp类型用于存储带有日期和时间部分的值,其范围是公元0001年01月01日 00:00:00.000000至公元9999年12月31日 23:59:59.999999。 TDSQL中datetime取值范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。其跟时区无关。 |
|
8 |
double |
dec[(p[,s])]或double precision , float8 |
GaussDB for PG中DEC[(p[,s])]精度p取值范围为 [1,1000],标度s取值范围为[0,p]。说明:p为总位数,s为小数位位数。未指定精度的情况下, 小数点前最大131,072位,小数点后最大16,383位。 TDSQL中double为双精度8个字节,可以保证16位精度。Double类型不精确,double使用的是四舍六入五成双,可能会产生一些问题。 但是如果不确定使用DEC是否正确,使用DOUBLE PRECISION,FLOAT8,但是GaussDB for PG中 DOUBLE PRECISION,FLOAT8与TDSQL中的double不相同,不存在四舍六入五成双。 |
|
9 |
char |
char(n) |
GaussDB for PG中char(n)定长字符串,不足补空 格。n是指字节长度,如不带精度n,默认精度为 1。最大为10MB。 TDSQL中char显示的是字符,固定长度字符串最长255字符。 |
|
10 |
decimal |
numeric[(p[,s])], decimal[(p[,s])] |
GaussDB for PG中numeric精度p取值范围为 [1,1000],标度s取值范围为[0,p]。说明:p为总位数,s为小数位数。 TDSQL中decimal(M,D)大小不确定,M表示指定长度,就是小数位数(精度)的总数,D表示小数点(标度)后的位数。如果D是0,则设置没有小数点或分数部分。M最大65,D最大30。如果D被省略,默认是0。如果M被省略,默认是10。 |
|
11 |
blob |
blob |
GaussDB for PG中,blob最大为32TB(即35184372088832字节)。 TDSQL中,blob最大最大65535B。 |
|
12 |
mediumtext |
text |
GaussDB for PG中,text最大为1GB-1,但还需要考虑到列描述头信息的大小,以及列所在元组的大小限制(也小于1GB-1),因此TEXT类型最大大小可能小于1GB-1。 TDSQL中mediumtext最大65535B。 |
|
13 |
longtext |
clob |
GaussDB for PG中,clob最大为32TB-1,但还需要考虑到列描述头信息的大小,以及列所在元组的大小限制(也小于32TB-1),因此CLOB类型最大大小可能小于32TB-1。 TDSQL中longtext最大4294967295B。 |
|
14 |
date |
date或timestamp without time zone |
GaussDB for PG中,A兼容性下,数据库将空字符串作为NULL处理,数据类型DATE会被替换为 TIMESTAMP(0) WITHOUT TIME ZONE。 TDSQL中格式为日期,yyyy-mm-dd。 如果要将TDSQL中的date字段值插入到GaussDB For PG中,会存储为 yyyy-mm-dd 00:00:00的格式,在使用的时候,需要做substring(dt, 0, 11)截断处理。 |
|
15 |
text |
text |
GaussDB for PG中,text最大为1GB-1,但还需要考虑到列描述头信息的大小,以及列所在元组的大小限制(也小于1GB-1),因此TEXT类型最大大小可能小于1GB-1。 TDSQL中,text最大65535B。 |
|
16 |
smallint |
smallint |
GaussDB for PG中,smallint取值范围为-32,768 ~ +32,767。 TDSQL中,smallint对于无符号数的存储范围是0~65535,而对于有符号数的存储范围是-32768~32767。 需要判断GaussDB for PG中smallint作为有符号数的存储范围是否够,如果不够需要换integer。 |
|
17 |
int unsigned |
integer |
GaussDB for PG中integer为有符号数,存储范围为-2,147,483,648 ~ +2,147,483,647。 TDSQL中int可以存储无符号数据的范围为0~4294967295,而对无符号数的存储范围是-2147483648~2147483647。 需要判断GaussDB for PG中integer作为有符号数的存储范围是否够,如果不够需要换bigint。 |
|
18 |
bigint unsigned |
bigint |
GaussDB for PG中bigint为有符号数,存储范围为-9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807。 TDSQL中bigint可以存储无符号数的范围是0~18446744073709551615,而对有符号数的存储范围是-9223372036854775808~9223372036854775807。 |
5.1.2建表
其他关键字:
|
序号 |
TDSQL字段或关键字 |
GaussDB for PG相应替代 |
备注 |
|
1 |
not null |
not null |
无区别 |
|
2 |
comment 'column' |
comment on column table_name.column_name is 'column'; |
字段备注 GaussDB for PG中的comment使用在建表完成之后,用单独的语句来完成备注,并且一次只能完成一个字段的备注,多个字段需要分别执行来完成。 TDSQL中comment跟在建表中字段之后使用。 |
|
3 |
comment='table' |
comment on table table_name is 'table'; |
表备注 GaussDB for PG中的comment使用在建表完成之后,用单独的语句来完成备注。 TDSQL中comment跟在建表语句之后使用。 |
|
4 |
auto_increment |
serial |
GaussDB for PG中的serial不建议使用,需要使用uuid等来替换。 |
|
5 |
collate |
默认在建库时使用lc_collate='C' lc_ctype='C' |
GaussDB for PG中的排序是lc_collate和lc_ctype配合使用的。 |
|
6 |
default null |
default null |
无区别 |
|
7 |
primary key |
primary key |
GaussDB for PG中的primary key可以是如下格式: create table test3 (a text primary key); create table test4 (a text, primary key(a)); |
|
8 |
key |
无 |
通过在表定义之后使用 CREATE INDEX 语句来实现 -- 创建表 CREATE TABLE example_table ( id SERIAL PRIMARY KEY, name VARCHAR(100), age INT ); -- 创建索引 CREATE INDEX idx_example_table_name ON example_table(name); 在这个例子中,我们首先创建了一个名为 example_table 的表,其中包含一个 id 列(作为主键,自动递增),一个 name 列和一个 age 列。然后,我们为 name 列创建了一个索引,索引名为 idx_example_table_name。 虽然 PostgreSQL 不支持直接在 CREATE TABLE 语句中嵌入 CREATE INDEX 语句,但你可以使用事务或脚本将这两步操作组合在一起,以确保它们在逻辑上是一起的,但是这种方式是在公司不允许的。 |
|
9 |
engine |
无 |
GaussDB for PG不选择存储引擎。 |
|
10 |
default charset |
encoding |
GaussDB for PG中encoding='UTF8'替代TDSQL的DEFAULT CHARSET=utf8mb4 |
|
11 |
partition by range |
partition by range |
无区别 |
|
12 |
to_days() |
无 |
GaussDB for PG中不存在对应的函数,需要自建函数来实现,但是在实际的开发过程中不允许使用自建函数,因为不通用。 |
|
13 |
charset |
encoding |
GaussDB for PG中encoding='UTF8'替代TDSQL的charset=utf8mb4 |
注:构建按日分区的表的方式
常见的分区方案有范围分区(Range Partitioning)、间隔分区(Interval Partitioning)、哈希分区(Hash Partitioning)、列表分区(List Partitioning)、数值分区(Value Partition)等。目前行存表支持范围分区、间隔分区、哈希分区、列表分区,列存表仅支持范围分区。
范围分区策略:根据分区键值将记录映射到已创建的某个分区上,如果可以映射到已
创建的某一分区上,则把记录插入到对应的分区上,否则给出报错和提示信息。这是最常用的分区策略。
间隔分区是一种特殊的范围分区,相比范围分区,新增间隔值定义,当插入记录找不
到匹配的分区时,可以根据间隔值自动创建分区。
间隔分区只支持基于表的一列分区,并且该列只支持TIMESTAMP[(p)] [WITHOUT TIME ZONE]、TIMESTAMP[(p)] [WITH TIME ZONE]、DATE数据类型。
由于GaussDB for PG不存在TDSQL中的to_days函数,因此建立分区时可以采用如下格式:
drop table if exists sales;
create table if not exists sales (
sale_id SERIAL PRIMARY KEY,
sale_date DATE NOT NULL)
partition by range(sale_date)
(
partition p_20190201 VALUES LESS THAN ('2019-02-01'),
partition p_20190202 VALUES LESS THAN ('2019-02-02'),
partition p_20190203 VALUES LESS THAN ('2019-02-03'),
partition p_DEF values less than ('9999-12-31')
)
直接使用日期来进行日期划分。注意,对于用于需要进行分区的字段赋成Date或timestamp,同时在批量程序中也需要做相应的修改。
5.1.3表结构转换
由于TDSQL迁移GaussDB无法使用华为提供的表结构转换工具,因此需要自行编写程序来实现相应的功能,总体是实现5.1.1和5.1.2部分的相关内容。
表结构转换程序的输入是TDSQL环境下的建表DDL语句,输出是GaussDB for PG环境下的建表DDL语句。
POM配置:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>tdsql2guass</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.15</version>
</dependency>
</dependencies>
</project>
连接TDSQL数据库:
ConnectTdsql.java:
public class ConnectTdsql {
private static Connection conn = null;
private static Statement stsm = null;
// 注册驱动程序
static {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (Exception e) {
e.printStackTrace();
System.out.println("获取数据库连接对象出错");
}
}
// 获取连接对象,该方法返回一个连接
public static Connection getConnection(String url, String user, String password) {
// 创建连接对象
try {
conn = DriverManager.getConnection(url, user, password);
System.out.println("数据库已经连接好了!");
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
return conn;
}
// 释放资源,断开连接
public static void close(Connection conn, Statement stsm) {
if (null != stsm) {
try {
stsm.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if (null != conn) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
// 释放资源,断开连接,重载
public static void close(Connection conn, Statement stsm, ResultSet rs) {
if (null != rs) {
try {
rs.close();
} catch (SQLException e1) {
e1.printStackTrace();
throw new RuntimeException(e1);
}
}
if (null != stsm) {
try {
stsm.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if (null != conn) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
获取TDSQL中表的DDL:
public class GetTableNameAndDDL {
public static ArrayList getTableName(String url, String user, String password, Connection conn, Statement stsm, String dataBaseName) {
ArrayList<String> tableName = new ArrayList<>();
ResultSet rs = null;
int counter = 0;
try {
// 调用工具类连接对象
conn = ConnectTdsql.getConnection(url, user, password);
// 创建statement对象
stsm = conn.createStatement();
// 准备sql语句
String sql = "SELECT TABLE_NAME, TABLE_SCHEMA FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = '" + dataBaseName + "';";
// 执行sql语句,返回的是ResultSet对象
rs = stsm.executeQuery(sql);
// 遍历查询结果
while (rs.next()) {
StringBuilder sb = new StringBuilder();
// 根据表情况来定制
String table_name = rs.getString("TABLE_NAME");
String table_schema = rs.getString("TABLE_SCHEMA");
sb = sb.append(table_schema).append(".").append(table_name);
String table_all_name = sb.toString();
tableName.add(table_all_name);
++counter;
}
System.out.println("数据查询完毕!" + "共有 " + counter + " 张表");
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
// 调用工具类关闭连接
ConnectTdsql.close(conn, stsm, rs);
}
return tableName;
}
public static void getTableDDL(String url,
String user,
String password,
Connection conn,
Statement stsm,
String dataBaseName,
String folderPath) {
ResultSet rs = null;
try {
// 获取所有的表名
ArrayList<String> allTableName = getTableName(url, user, password, conn, stsm, dataBaseName);
// 获取建表信息
// 调用工具类连接对象
conn = ConnectTdsql.getConnection(url, user, password);
// 创建statement对象
stsm = conn.createStatement();
// 创建文件夹
makeFolder(folderPath);
// 准备sql语句
for (String tableName : allTableName) {
String sql = "SHOW CREATE TABLE " + tableName;
rs = stsm.executeQuery(sql);
if (null != rs) {
if (rs.next()) {
String table_ddl = rs.getString("Create Table");
stringToFile(folderPath, tableName, table_ddl);
}
}
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
// 调用工具类关闭连接
ConnectTdsql.close(conn, stsm, rs);
}
}
public static void stringToFile(String folderPath, String fileName, String tableDDLInfo) {
try {
String filePath = folderPath + fileName + ".sql";
// 创建一个File文件,表示要保存的文件
File file = new File(filePath);
// 创建一个BufferedWriter对象
BufferedWriter writer = new BufferedWriter(new FileWriter(file));
// 将String字符串写入文件
writer.write(tableDDLInfo);
// 关闭BufferedWriter对象
writer.close();
System.out.println("存放 " + fileName + " 建表信息的文件已经建好!");
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
public static void makeFolder(String folderPath) {
File folder = new File(folderPath);
if (!folder.exists()) {
folder.mkdirs();
}
System.out.println("存放建表信息的文件夹已经建好!");
}
}
TDSQL的DDL结构转为GaussDB的DDL结构:
public class GetDDLAndTransform {
public static void getAllFile(File fileInput, ArrayList<File> allFileList) {
// 获取文件列表
File[] fileList = fileInput.listFiles();
assert fileList != null;
for (File file : fileList) {
allFileList.add(file);
}
}
public static void getFileDDLInfoAndTransform(String folderPath) {
File dir = new File(folderPath);
ArrayList<File> allFileList = new ArrayList<>();
// 判断文件夹是否存在
if(!dir.exists()) {
System.out.println("需要查询文件的文件夹不存在!");
return;
}
getAllFile(dir, allFileList);
for (File file : allFileList) {
String ddlInfo = readFileByPath(file);
System.out.println(ddlInfo);
// 处理建表转换的主逻辑
/*
* 这里是实现本次任务的主要部分,执行tdsqlDDL2GaussDBDDL,然后输出到文件中
*/
System.out.println(tdsqlDDL2GaussDBDDL(file));
}
System.out.println("该文件夹下共有 " + allFileList.size() + " 个文件");
}
public static String readFileByPath(File fileName) {
StringBuilder result = new StringBuilder();
try {
FileInputStream fileInputStream = new FileInputStream(fileName);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while ((line = bufferedReader.readLine()) != null) {
result.append(line).append("\n");
}
bufferedReader.close();
} catch (Exception e) {
e.printStackTrace();
}
return result.toString();
}
/*
* 针对具体的TDSQL到GaussDB for PG的DDL转换任务,设计如下:
* 使用3个HashMap来存储相关信息,定义为HashMap<String, ArrayList<String>>
* 1)第1个HashMap存储字段信息,key为字段名,value为关于该字段的相关设定
* 2)第2个HashMap存储索引信息,key为索引名,value为关于该索引的相关类型
* 3)第3个HashMap存储分区信息,key为分区键信息,value为关于该分区的规则和数量信息
* 将TDSQL中相关表信息拆解到上述数据结构中,然后读取出来按照GaussDB for PG的相关规则进行DDL重构
*/
public static String tdsqlDDL2GaussDBDDL(File tdsqlFileName) {
// 存储GaussDB的建表信息
StringBuilder gaussDDL = new StringBuilder();
// 存储GaussDB的分区信息
StringBuilder gaussDDLPart = new StringBuilder();
// 存储GaussDB的索引信息
StringBuilder gaussDDLIndex = new StringBuilder();
// 存储表信息
LinkedHashMap<String, String> tableInfo = new LinkedHashMap<>();
// 存储列信息
LinkedHashMap<String, String> columnInfo = new LinkedHashMap<>();
// 存储索引信息
LinkedHashMap<String, String> indexInfo = new LinkedHashMap<>();
// 存储分区信息
LinkedHashMap<String, String> partitionInfo = new LinkedHashMap<>();
// 存储comment信息
ArrayList<String> commentInfo = new ArrayList<>();
try {
FileInputStream fileInputStream = new FileInputStream(tdsqlFileName);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
// 提取完毕之后使用Map里的数据来进行重构
while ((line = bufferedReader.readLine()) != null) {
// 获取表名
if (checkTableNameInfo(line)) {
tableInfo = getTableNameInfo(line);
// 获取列相关
// 重构GaussDB建表
// 1)首先获取表名
String gs_table_name = tableInfo.get("table_name");
String gs_create_table_name = "CREATE TABLE IF NOT EXISTS " + gs_table_name + " (";
gaussDDL.append(gs_create_table_name).append("\r\n");
} else if (checkColumnNameInfo(line)) {
columnInfo = getColumnNameInfo(line);
// 关于列信息的构建需要字段的规则映射
/*
* 需要补充映射规则
*/
// 列名之前需要缩进
gaussDDL.append("\t");
Iterator<Map.Entry<String, String>> iterator = columnInfo.entrySet().iterator();
String gs_column_name = null;
String gs_comment = null;
String gs_not_null = null;
String gs_default_null = null;
String gs_auto_increment = null;
String gs_column_type = null;
String tdsql_column_type = null;
// 遍历结果提取信息进行拼接
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
if ("column_name" == key) {
gs_column_name = entry.getValue();
} else if ("comment" == key) {
gs_comment = entry.getValue();
// comment信息存储起来
commentInfo.add(gs_comment);
} else if ("not_null" == key) {
gs_not_null = entry.getValue();
} else if ("default_null" == key) {
gs_default_null = entry.getValue();
} else if ("auto_increment" == key) {
gs_auto_increment = entry.getValue();
} else if ("column_type" == key) {
tdsql_column_type = entry.getValue();
}
}
// 列名
gaussDDL.append(gs_column_name.replace("`",""));
gaussDDL.append(" ");
// 判断是否为auto_increment,如果为auto_increment在Gauss中需要用uuid来替代,字段类型需要使用varchar,此时跳过字段类型的转换
if (gs_auto_increment == "1") {
gs_column_type = "varchar(256)";
gaussDDL.append(gs_column_type);
gaussDDL.append(" ");
} else {
// 字段类型,这里需要维护一个映射表,如果还涉及到char和varchar,需要将数字进行转换
if (null != tdsql_column_type) {
gs_column_type = tdsqlColumnConvert2Gauss(tdsql_column_type);
gaussDDL.append(gs_column_type);
gaussDDL.append(" ");
}
}
// 是否为not null
if (gs_not_null == "1") {
gaussDDL.append("NOT NULL");
gaussDDL.append(" ");
}
// 是否为default null
if (gs_default_null == "1") {
gaussDDL.append("DEFAULT NULL");
gaussDDL.append(" ");
}
gaussDDL.append(",").append("\r\n");
// 获取索引相关
} else if (checkIndexNameInfo(line)) {
indexInfo = getIndexNameInfo(line);
// 先添加主键,普通索引的添加方式不同于主键
if (indexInfo.containsKey("primary_key")) {
gaussDDL.append("\t");
gaussDDL.append("PRIMARY KEY(");
gaussDDL.append(indexInfo.get("primary_key").replace("`",""));
gaussDDL.append(")").append("\r\n");
}
if (!indexInfo.isEmpty()) {
Iterator<Map.Entry<String, String>> iterator = indexInfo.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
if ("primary_key" != key) {
gaussDDLIndex.append("CREATE INDEX IF NOT EXISTS ").append(entry.getKey().replace("`","")).append(" ON ").append(tableInfo.get("table_name")).append("(").append(entry.getValue().replace("`","")).append(");").append("\r\n");
}
}
}
// 到主键完成,高斯中的新表已经构建完成
// 获取分区相关
} else if (checkPartitionNameInfo(line)) {
partitionInfo = getPartitionNameInfo(line);
// 重构的时候需要注意,使用时期的字段需要时Date
if (!partitionInfo.isEmpty()) {
Iterator<Map.Entry<String, String>> iterator = partitionInfo.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
if ("PARTITION" == key) {
gaussDDLPart.append("PARTITION BY RANGE(").append(entry.getValue()).append(")").append("\r\n");
gaussDDLPart.append("(").append("\r\n");
} else if ("P_DEF".equals(key)) {
gaussDDLPart.append("\t").append("PARTITION ").append(key).append(" VALUES LESS THAN (").append(entry.getValue()).append(")").append("\r\n");
gaussDDLPart.append(");");
} else if (key != "PARTITION" && key != "P_DEF") {
gaussDDLPart.append("\t").append("PARTITION ").append(key).append(" VALUES LESS THAN (").append(entry.getValue()).append(")").append(",").append("\r\n");
}
}
}
}
// 还需要获取关于表的comment,这个就节后来做吧,tableInfo作为传入变量
}
gaussDDL.append(") WITH (orientation=row,storage_type = USTORE)").append("\r\n");
if (gaussDDLPart.toString().trim().length() == 0) {
gaussDDL.append(";").append("\r\n");
} else {
gaussDDL.append(gaussDDLPart.toString()).append("\r\n");
}
gaussDDL.append(gaussDDLIndex.toString()).append("\r\n");
} catch (Exception e) {
e.printStackTrace();
}
return gaussDDL.toString();
}
public static boolean checkTableNameInfo(String line) {
boolean result = false;
try {
String regex = "CREATE TABLE";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
System.out.println("表名信息匹配成功,开始获取表名!");
result = true;
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public static LinkedHashMap<String, String> getTableNameInfo(String line) {
LinkedHashMap<String, String> tableHashMap = new LinkedHashMap<>();
String tableName = null;
try {
String splitRole = "`";
String[] parts = line.split(splitRole);
int partsLength = parts.length;
if (partsLength >= 2) {
tableName = parts[partsLength - 2];
}
tableHashMap.put("table_name", tableName);
} catch (Exception e){
e.printStackTrace();
}
return tableHashMap;
}
public static boolean checkColumnNameInfo(String line) {
boolean result = false;
try {
String[] notColumnKeyWorlds = {"CREATE TABLE", "KEY", "ENGINE=InnoDB", "PARTITION"};
boolean auxiliary = true;
for (String keyworld : notColumnKeyWorlds) {
Pattern pattern = Pattern.compile(keyworld, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
// 如果匹配到关键字,则代表不属于列定义行,需要同时满足
auxiliary = auxiliary & (!matcher.find());
}
if (auxiliary == true) {
result = true;
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public static LinkedHashMap<String, String> getColumnNameInfo(String line) {
LinkedHashMap<String, String> columnHashMap = new LinkedHashMap<>();
String beforeKeyword = null;
String afterKeyword = null;
String modifiedString = null;
String columnName = null;
String columnType = null;
/*
* 1)key为‘column_name’,value为相应的字段名,如果没有为0
* 2)key为’column_type‘,value为该数据类型和数值,如果没有为0
* 3)key为关键字‘not null',value为1表示存在,value为0表示不存在
* 4)key为关键字’default null‘,value为1表示存在,value为0表示不存在
* 5)key为关键字’comment‘,value为具体的内容,如果没有的话为0
* 6)key为关键字’auto_increment',value为1表示存在,value为0表示不存在(这部分使用uuid来替代,在程序中来进行改造)
*/
try {
// 首先将输入的字符串都转换为小写
String input = line.toLowerCase().trim();
// 首先提取出comment前后的内容,防止comment中的内容对具体的拆分产生影响,如果comment中继续包含comment关键字需要更加细致的分析
String commentKeyWord = "comment";
int resultCommentKeyWord = -1;
resultCommentKeyWord = keywordOccurrence(input, commentKeyWord);
if (resultCommentKeyWord != -1) {
// 如果存在comment关键字
beforeKeyword = input.substring(0, resultCommentKeyWord);
int startIndexAfterKeyword = resultCommentKeyWord + commentKeyWord.length();
if (startIndexAfterKeyword <= input.length()) {
afterKeyword = input.substring(startIndexAfterKeyword);
if (afterKeyword.endsWith(",")) {
modifiedString = afterKeyword.substring(0, afterKeyword.length() - 1);
}
columnHashMap.put("comment", modifiedString);
}
// 后面的部分围绕beforeKeyword来开展
// 1)列名关键字:
columnName = extraceColumnName(beforeKeyword);
if (isNotBlank(columnName)) {
columnHashMap.put("column_name", columnName);
} else {
columnHashMap.put("column_name", "0");
}
// 2)not null关键字
int resultNotNullKeyWord = -1;
String notNullKeyWord = "not null";
resultNotNullKeyWord = keywordOccurrence(beforeKeyword, notNullKeyWord);
if (resultNotNullKeyWord != -1) {
columnHashMap.put("not_null", "1");
} else {
columnHashMap.put("not_null", "0");
}
// 3)default null关键字
int resultDefualtNullKeyWord = -1;
String defaultNullKeyWord = "default null";
resultDefualtNullKeyWord = keywordOccurrence(beforeKeyword, defaultNullKeyWord);
if (resultDefualtNullKeyWord != -1) {
columnHashMap.put("default_null", "1");
} else {
columnHashMap.put("default_null", "0");
}
// 4)auto_increment关键字
int resultAutoIncrementKeyWord = -1;
String autoIncrementKeyWord = "auto_increment";
resultAutoIncrementKeyWord = keywordOccurrence(beforeKeyword, autoIncrementKeyWord);
if (resultAutoIncrementKeyWord != -1) {
columnHashMap.put("auto_increment", "1");
} else {
columnHashMap.put("auto_increment", "0");
}
// 5)column_type关键字
// 导出的标准SQL,column_type会紧跟在columnName之后,处于第二的位置,将beforeKeyword拆分之后找到第二个位置就好
String regex = " ";
String[] types = beforeKeyword.trim().split(regex);
if (types.length >= 1) {
columnType = types[1];
columnHashMap.put("column_type", columnType);
} else {
columnHashMap.put("column_type", "0");
}
} else {
// 如果resultCommentKeyWord表示-1,则代表不存在comment关键字
columnHashMap.put("comment", "0");
// 后面的部分围绕beforeKeyword来开展
// 1)列名关键字:
columnName = extraceColumnName(input);
if (isNotBlank(columnName)) {
columnHashMap.put("column_name", columnName);
} else {
columnHashMap.put("column_name", "0");
}
// 2)not null关键字
int resultNotNullKeyWord = -1;
String notNullKeyWord = "not null";
resultNotNullKeyWord = keywordOccurrence(input, notNullKeyWord);
if (resultNotNullKeyWord != -1) {
columnHashMap.put("not_null", "1");
} else {
columnHashMap.put("not_null", "0");
}
// 3)default null关键字
int resultDefualtNullKeyWord = -1;
String defaultNullKeyWord = "default null";
resultDefualtNullKeyWord = keywordOccurrence(input, defaultNullKeyWord);
if (resultDefualtNullKeyWord != -1) {
columnHashMap.put("default_null", "1");
} else {
columnHashMap.put("default_null", "0");
}
// 4)auto_increment关键字
int resultAutoIncrementKeyWord = -1;
String autoIncrementKeyWord = "auto_increment";
resultAutoIncrementKeyWord = keywordOccurrence(input, autoIncrementKeyWord);
if (resultAutoIncrementKeyWord != -1) {
columnHashMap.put("auto_increment", "1");
} else {
columnHashMap.put("auto_increment", "0");
}
// 5)column_type关键字
// 导出的标准SQL,column_type会紧跟在columnName之后,处于第二的位置,将beforeKeyword拆分之后找到第二个位置就好
String regex = " ";
String[] types = input.trim().split(regex);
if (types.length >= 1) {
columnType = types[1];
columnHashMap.put("column_type", columnType);
} else {
columnHashMap.put("column_type", "0");
}
}
} catch (Exception e) {
e.printStackTrace();
}
return columnHashMap;
}
public static int keywordOccurrence(String input, String keyword) {
int firstOccurrentIndex = -1;
int count = 0;
int currentIndex = 0;
while ((currentIndex = input.indexOf(keyword.toLowerCase(), currentIndex)) != -1) {
count++;
if (firstOccurrentIndex == -1) {
firstOccurrentIndex = currentIndex;
}
currentIndex += keyword.length();
}
return firstOccurrentIndex;
}
public static String extraceColumnName(String input) {
String result = null;
String regex = "`([^`]*)`";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
result = matcher.group(0);
}
return result;
}
public static boolean isNotBlank(String s){
if(s != null && !s.isEmpty()){
return true;
}
return false;
}
public static boolean checkIndexNameInfo(String line) {
boolean result = false;
try {
String regex = "KEY";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
result = true;
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public static LinkedHashMap<String, String> getIndexNameInfo(String line) {
LinkedHashMap<String, String> indexHashMap = new LinkedHashMap<>();
try {
// 判断主键
String regex_prim_key = "PRIMARY KEY";
Pattern pattern = Pattern.compile(regex_prim_key, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
String regex = "\\(([^)]+)\\)";
Pattern pattern_prim_key = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher_prim_key = pattern_prim_key.matcher(line);
while (matcher_prim_key.find()) {
String prim_key_column = matcher_prim_key.group(1);
indexHashMap.put("primary_key", prim_key_column);
}
} else {
// 判断普通索引
String regex_key = "KEY";
Pattern pattern1 = Pattern.compile(regex_key, Pattern.CASE_INSENSITIVE);
Matcher matcher1 = pattern1.matcher(line);
if (matcher1.find()) {
String split_key = " ";
String[] indexs = line.trim().split(split_key);
String index_name = indexs[1];
String index_info = null;
String regex_index = "\\(([^)]+)\\)";
Pattern pattern_key = Pattern.compile(regex_index, Pattern.CASE_INSENSITIVE);
Matcher matcher_key = pattern_key.matcher(line);
while (matcher_key.find()) {
String index_column = matcher_key.group(1);
indexHashMap.put(index_name, index_column);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return indexHashMap;
}
public static boolean checkPartitionNameInfo(String line) {
boolean result = false;
try {
String regex = "PARTITION";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
result = true;
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
public static LinkedHashMap<String, String> getPartitionNameInfo(String line) {
StringBuilder sb = new StringBuilder();
LinkedHashMap<String, String> partitionHashMap = new LinkedHashMap<>();
String part_key_column = null;
String part_info = null;
String part_info_detail = null;
try {
// 判断分区键
String regex_part_key = "PARTITION BY RANGE";
Pattern pattern = Pattern.compile(regex_part_key, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
String regex = "to_days\\(([^)]+)\\)";
Pattern pattern_part_key = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher_part_key = pattern_part_key.matcher(line);
while (matcher_part_key.find()) {
part_key_column = matcher_part_key.group(1);
partitionHashMap.put("PARTITION", part_key_column);
}
} else {
// 判断分区信息
String regex_part_info = "VALUES LESS THAN";
Pattern pattern1 = Pattern.compile(regex_part_info, Pattern.CASE_INSENSITIVE);
Matcher matcher1 = pattern1.matcher(line);
if (matcher1.find()) {
String split_key = " ";
String[] indexs = line.trim().split(split_key);
part_info = indexs[1];
part_info_detail = convertDateFormat(part_info);
sb.append("'").append(part_info_detail).append("'");
partitionHashMap.put(part_info, sb.toString());
}
}
} catch (Exception e) {
e.printStackTrace();
}
return partitionHashMap;
}
public static String convertDateFormat(String input) {
String dataPart = input.replace("P_", "");
String result = null;
SimpleDateFormat inputFormat = new SimpleDateFormat("yyyyMMdd");
SimpleDateFormat outputFormat = new SimpleDateFormat("yyyy-MM-dd");
try {
if (isNumberic(dataPart)) {
Date date = inputFormat.parse(dataPart);
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
calendar.add(calendar.DAY_OF_MONTH, 1);
Date tomorrow = calendar.getTime();
result = outputFormat.format(tomorrow);
} else {
result = "9999-12-31";
}
} catch (ParseException e) {
e.printStackTrace();
return null;
}
return result;
}
public static boolean isNumberic(String str) {
return str != null && str.matches("\\d+");
}
public static String tdsqlColumnConvert2Gauss(String str) {
// 映射表,key为TDSQL字段类型,value为GaussDB字段类型
HashMap<String, String> columnMap = new HashMap<>();
// 向HashMap中添加一些键值对,用作后面column_info的转换
columnMap.put("bigint", "bigint");
columnMap.put("varchar", "varchar");
columnMap.put("timestamp", "timestamp");
columnMap.put("longblob", "blob");
columnMap.put("tinyint", "tinyint");
columnMap.put("int", "integer");
columnMap.put("datetime", "timestamp");
columnMap.put("double", "float8");
columnMap.put("char", "char");
columnMap.put("decimal", "decimal");
columnMap.put("blob", "blob");
columnMap.put("mediumtext", "text");
columnMap.put("longtext", "clob");
columnMap.put("date", "date");
columnMap.put("text", "text");
columnMap.put("smallint", "smallint");
columnMap.put("int unsigned", "integer");
columnMap.put("bigint unsigned", "bigint");
// 存储结果
StringBuilder result = new StringBuilder();
String column_digit = null;
String column_info = null;
String column_info_gs = null;
boolean isDecimal = false;
boolean isVar2char = false;
// 1)第一步:判断输入的字符串中是否含有数字,如果有就提取出来
boolean containsDigit = containsDigit(str);
if (containsDigit) {
// 这里主要是针对varchar、char和decimal的情况
// 如果包含数字且包含逗号","的情况
boolean containsComma = containsComma(str);
if (containsComma) {
column_info = extractNonBracketContent(str);
column_digit = extractContentInString(str);
isDecimal = true;
} else {
// 在这之前需要去掉字段里的括号
String input = str.replace("(","").replace(")","");
// 数字部分
column_digit = extractNumbers(input);
// 字段类型
column_info = extractNoDigitPart(input);
isVar2char = true;
}
} else {
column_info = str;
}
// 2)第二步:创建一个字段类型映射HashMap
if (columnMap.containsKey(column_info)) {
column_info_gs = columnMap.get(column_info);
}
// 3)第三步:拼接字段
if (null != column_digit) {
if (isDecimal) {
result = result.append(column_info_gs).append(column_digit);
} else if (isVar2char) {
int num = Integer.parseInt(column_digit);
if (column_info_gs == "varchar" || column_info_gs == "char") {
num = num * 4;
}
// num = num * 4;
String var2CharDigit = Integer.toString(num);
result = result.append(column_info_gs).append("(").append(var2CharDigit).append(")");
}
} else {
result = result.append(column_info_gs);
}
return result.toString();
}
public static boolean containsDigit(String input) {
Pattern pattern = Pattern.compile("\\d");
Matcher matcher = pattern.matcher(input);
return matcher.find();
}
public static boolean containsComma(String input) {
return input.contains(",");
}
public static String extractNumbers(String input) {
Pattern pattern = Pattern.compile("\\d+");
Matcher matcher = pattern.matcher(input);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
result.append(matcher.group()).append(" ");
}
if (result.length() > 0) {
result.setLength(result.length() - 1);
}
return result.toString();
}
public static String extractNoDigitPart(String str) {
return str.replaceAll("\\d", "");
}
public static String extractContentInString(String str) {
String result = null;
String pattern = "\\((.*?)\\)";
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(str);
if (m.find()) {
result = m.group(0);
}
return result;
}
public static String extractNonBracketContent(String str) {
String result = null;
String pattern = "^[^(]*";
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(str);
if (m.find()) {
result = m.group();
}
return result;
}
}
5.1.4 表结构转换结果
以有多字段、多索引和多分区的TDSQL表转换为例:
TDSQL的DDL结构:
CREATE TABLE `baas_mq_tran_monitor` ( `msg_id` varchar(40) COLLATE utf8mb4_bin NOT NULL COMMENT '消息ID', `global_serno` varchar(40) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '全局流水号', `credit_type` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '征信类型', `send_time` datetime NOT NULL COMMENT '发送时间', `receive_time` datetime DEFAULT NULL COMMENT '接收时间', PRIMARY KEY (`msg_id`,`send_time`), KEY `idx_global_serno_1` (`global_serno`), KEY `idx_sendTime_1` (`send_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='mq交易监控表' /*!50100 PARTITION BY RANGE (TO_DAYS(send_time)) (PARTITION P_20250121 VALUES LESS THAN (739638) ENGINE = InnoDB, PARTITION P_20250122 VALUES LESS THAN (739639) ENGINE = InnoDB, PARTITION P_20250123 VALUES LESS THAN (739640) ENGINE = InnoDB, PARTITION P_20250124 VALUES LESS THAN (739641) ENGINE = InnoDB, PARTITION P_20250125 VALUES LESS THAN (739642) ENGINE = InnoDB, PARTITION P_20250126 VALUES LESS THAN (739643) ENGINE = InnoDB, PARTITION P_20250127 VALUES LESS THAN (739644) ENGINE = InnoDB, PARTITION P_20250128 VALUES LESS THAN (739645) ENGINE = InnoDB, PARTITION P_20250129 VALUES LESS THAN (739646) ENGINE = InnoDB, PARTITION P_20250130 VALUES LESS THAN (739647) ENGINE = InnoDB, PARTITION P_20250131 VALUES LESS THAN (739648) ENGINE = InnoDB, PARTITION P_20250201 VALUES LESS THAN (739649) ENGINE = InnoDB, PARTITION P_20250202 VALUES LESS THAN (739650) ENGINE = InnoDB, PARTITION P_20250203 VALUES LESS THAN (739651) ENGINE = InnoDB, PARTITION P_20250204 VALUES LESS THAN (739652) ENGINE = InnoDB, PARTITION P_20250205 VALUES LESS THAN (739653) ENGINE = InnoDB, PARTITION P_20250206 VALUES LESS THAN (739654) ENGINE = InnoDB, PARTITION P_20250207 VALUES LESS THAN (739655) ENGINE = InnoDB, PARTITION P_DEF VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
转换为GaussDB的DDL结构:
CREATE TABLE IF NOT EXISTS baas_mq_tran_monitor (
msg_id varchar(160) NOT NULL ,
global_serno varchar(160) DEFAULT NULL ,
credit_type varchar(80) DEFAULT NULL ,
send_time timestamp NOT NULL ,
receive_time timestamp DEFAULT NULL ,
PRIMARY KEY(msg_id,send_time)
) WITH (orientation=row,storage_type = USTORE)
PARTITION BY RANGE(send_time)
(
PARTITION P_20250121 VALUES LESS THAN ('2025-01-22'),
PARTITION P_20250122 VALUES LESS THAN ('2025-01-23'),
PARTITION P_20250123 VALUES LESS THAN ('2025-01-24'),
PARTITION P_20250124 VALUES LESS THAN ('2025-01-25'),
PARTITION P_20250125 VALUES LESS THAN ('2025-01-26'),
PARTITION P_20250126 VALUES LESS THAN ('2025-01-27'),
PARTITION P_20250127 VALUES LESS THAN ('2025-01-28'),
PARTITION P_20250128 VALUES LESS THAN ('2025-01-29'),
PARTITION P_20250129 VALUES LESS THAN ('2025-01-30'),
PARTITION P_20250130 VALUES LESS THAN ('2025-01-31'),
PARTITION P_20250131 VALUES LESS THAN ('2025-02-01'),
PARTITION P_20250201 VALUES LESS THAN ('2025-02-02'),
PARTITION P_20250202 VALUES LESS THAN ('2025-02-03'),
PARTITION P_20250203 VALUES LESS THAN ('2025-02-04'),
PARTITION P_20250204 VALUES LESS THAN ('2025-02-05'),
PARTITION P_20250205 VALUES LESS THAN ('2025-02-06'),
PARTITION P_20250206 VALUES LESS THAN ('2025-02-07'),
PARTITION P_20250207 VALUES LESS THAN ('2025-02-08'),
PARTITION P_DEF VALUES LESS THAN ('9999-12-31')
);
CREATE INDEX IF NOT EXISTS idx_global_serno_1 ON baas_mq_tran_monitor(global_serno);
CREATE INDEX IF NOT EXISTS idx_sendTime_1 ON baas_mq_tran_monitor(send_time);
测试完毕无误。
欢迎大家讨论交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号