


一种Hive性能调优方法(补充)
之前学习整理过一些Hive调优的方法,最近在学习参考书的时候看到作者提供了一个Hive调优的解决方案,在这里分享下。
案例所使用的数据来源于美国航班数据、机场数据和天气数据。用来查询要查找航班延误(时间超过15分钟)次数最多的5个机场,其出发机场的风速都超过1米/秒。

第一个调优方向:执行引擎
Hive目前支持3中执行引擎,每种引擎都有各自的优缺点。这里将比较一下MapReduce执行引擎和Tez执行引擎的性能。
1)MapReduce:
MapReduce支持引擎以传统的MapReduce作业方式来运行Hive查询。它是最初的执行引擎,如果你的查询不能用其他执行引擎来执行,它将是最安全的后备选项。通过将hive.execution.engine属性的值设置为mr,就可以选择该执行引擎。使用MapReduce执行查询花费了475.732s(在作者的实验设备环境下),并且在查询过程中将711MB的中间数据写入磁盘。

2)Tez
通过减少操作和限制写入磁盘的中间数据量,Apache Tez可以提供比MapReduce执行引擎更高效的处理。Tez避免来了不必要的HDFS写入操作。

通过将hive.execution.engine的值设置为tex,并且更改两个属性,hive.prewarm.enabled=true和hive.prewarm.numcontainers=10,结果如下。

仅仅更改执行引擎就可以是执行时间减少309秒,接近65%。
第二个调优方向:存储格式
有些文件格式专门针对Hive使用进行了优化,包括ORC文件和Parquet,这里来讲一下ORC文件。
ORC格式是一种基于列的存储格式,这意味着,它并不是按照单个数据行连续将全部数据存储在磁盘上,而是按每列连续存储数据。这样针对那些不包含某些列的查询,就可以避免不必要的磁盘访问,可以跳过那些在结果中不需要的大部分数据。ORC格式是一种可分割的文件格式,这意味着一个文件可以被分割成多个可并行处理的块。每个数据块被进一步细分为256MB的数据带,而这些数据带则用于将列数据存储在一起。任何不需要特定列值的查询都可以“跳过”这个数据带。

为了度量ORC的性能影响,需要首先创建原始表的两个副本,它们将以ORC格式存储。结果如下:
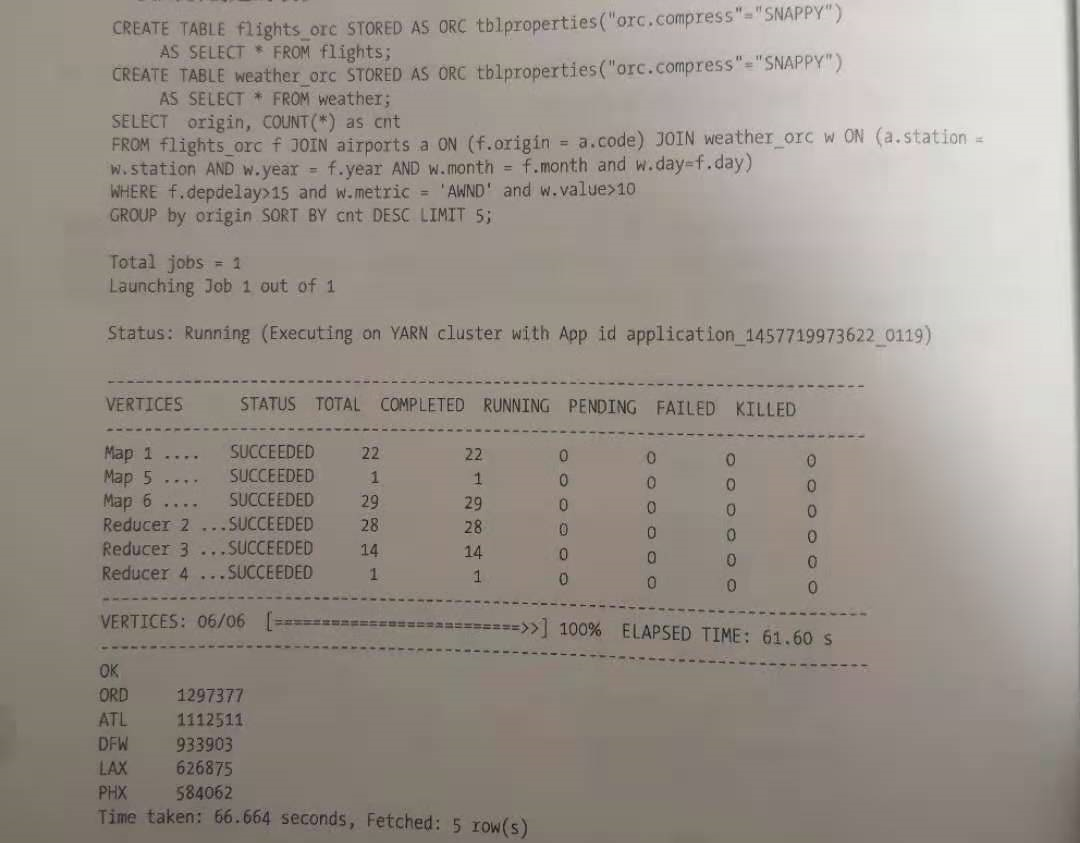
使用ORC合适存储导致执行时间减少了100秒,即减少了超过60%。
第三个调优方向:矢量化查询执行
Hive默认的查询执行引擎一次处理一行,因此在嵌套循环中需要有多层虚拟方法调用,从CPU的视角来看这是非常低效的。矢量化查询执行是一种Hive特性,其目的是按照每批1024行读取数据,并且一次性对整个记录集合(而不是对单条记录)应用操作,进而消除那些效率低下的问题。而要使用矢量化查询执行,就必须以ORC格式存储数据。
矢量化查询执行需要先将hive.vertorized.execution.enabled属性的值设置为true,并且针对有ORC支持的表运行查询。

相对于仅使用Tez和ORC来说,矢量化执行导致执行时间缩短了12秒。
第四个调优方向:查询执行计划
这里来讲讲基于代价的优化。
基于代价的优化(CBO)引擎利用了Hive Metastore的统计数据来产生最优的查询计划。用于优化的统计信息有两种类型:一种是表统计信息,包括表的未压缩大小、行数和用于存储数据的文件数;另一种是列统计信息,其中包括NDV(唯一值的个数)和最小值/最大值/计数值。
CBO进行了连续重排序,改进了针对星型连接模式和浓密连接模式的计划,并提供了基于样本查询的改进机会。
通过设置hive.stats.autogather为true,就可以进行自动化表统计信息的全局收集了。

一旦计算出统计信息,就可以通过在Hive内设置以下属性来启用CBO,这样我们运行的每个查询都可使用基于代价的优化引擎。

CBO引擎将执行时间进一步缩短了4秒,即7%,带来了最终优化结果。
此外,CBO还可以产生最佳的顺序,如下所示:

总体来说可以通过使用Tez、ORC存储格式、矢量化查询执行和CBO引擎等技术来减少涉及两个达标的单个查询的执行时间,可以从475秒缩短到49秒以下。最重要的是,只需少量工作就可以将大多数技术都应用到现有的大多数Hive表中。
本文的材料和语言来自于斯科特.肖的《Hive实战》,由唐富年老师翻译。
有兴趣的伙伴可以去翻看一下原文,自我感觉和《Hive编程指南》一块学习效果更好。
互勉~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号