
MIT_AI公开课p3p4学习笔记
03-推理目标树与基于规则的专家系统
1、问题引出
程序回答关于自身行为的问题。
例子:谁在谁之上,程序结构:
Put-On:
find space——调用getRidof"移开"
grasp——调用clear top——调用getRidof"移开"——调用Put-On
move
ungrasp
- 如何回答”为什么“?
返回上一层 - 如何回答“如何”?
往下一层
2、程序总结
- 这就是一颗目标树,由程序实现它每一步的目标而产生的踪迹生成。
- 所以,目标树就是能让程序回答关于自身的行为的问题。
- 西蒙的蚂蚁比喻——行为的复杂性=程序复杂性和环境复杂性中较大值【复杂行为,简单程序】
3、基于规则的专家系统
- 都可以用简单规则形式的知识表示出来;
- “专家”并不是有常识的,而是添加进去的规则;所以是基于规则的新手系统!
- 由已知事实向前推出结论,就是前向链系统。前向链系统实质上也是目标树,因为是目标为中心的程序,所以可以回答自身行为的问题 。
- 还可以从假设往回去找事实,这样的系统叫做后向链基于规则的专家系统。
- 专家系统的重要特征:演绎系统,是从事实推演出新事实
例子:购物袋内置物规则:大的放在下面,重物不超过三个……
知识工程的三条规则:
- 规则1:处理个案(比如:牛奶、薯片……)
- 规则2:看起来相同但实际上处理方式有所不同的东西(询问有什么不同,比如不同烹饪的豌豆)
- 规则3:建立一个系统然后看他何时出问题(做实验,看程序何时出错)
最后:故事就是由一系列受控的幻想来推进~
04-搜索:深度优先、爬山、束搜索
一、引入
例子: 从A到B地最优路径
题目: 根据图画出搜索树
惯例:
- 结点都需要按照字母顺序来;
- 不允许有路径绕回原来到过的地方
要点: 搜索≠图(地图Maps),搜索=选择
二、四种搜索算法
算法介绍
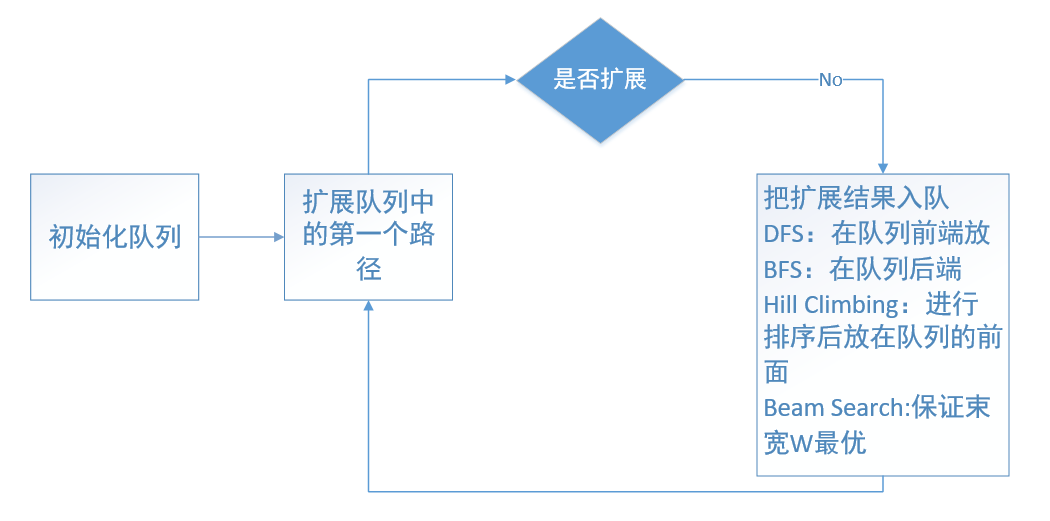
1、深度优先搜索(DFS)
- 遇到死胡同,“回溯”到上一次选择的地方,可以遍历所有节点,而不是只得到一条路
- 放在栈(Stack)中/队列中
- 把扩展的队列放在前端
- 生成两个路径的做法是:将队列前端的一个路径除去,发现这个路径没有到达目标后,对他进行扩展,然后把生成的路径放回队列
2、广度优先遍历(BFS)
- 一层层来遍历
- 放在队列(Queue)中
- 无法分辨自己是靠近还是远离目标
- 优化算法:已经扩展过的结点不再考虑(访问过的结点不再访问)
3、爬山算法(DFS的改良)
- 根据结点离目标近来选择而不是按照字母顺序(因为我们更倾向于选择离目标结点更近的结点)【这点优于DFS和BFS】
- 离目标的距离可以看做图中路径的权重
- 贪心算法,有可能陷入死路
4、束搜索(BFS的改良)
- 将每一层中考虑的路径数限制在一个较小的固定数字上
- 束宽:每次搜索考虑的路径长度
- 例如:束宽2,BDAC中考虑离目标最近的两个是BD,所以这一层只保留2个结点BD;
- 和BFS的区别:不会朝着离目标更远的方向走
程序流程图
算法比较
| 算法 | 是否回溯 | 是否使用入队列表 | 是否知情(使用启发性信息) |
|---|---|---|---|
| 深度优先 | √ | √ | × |
| 广度优先 | × | √ | × |
| 爬山算法 | √ | √ | √(路径权重) |
三、案例
1、爬山
-
原型: 在山上,判断四个方向中哪个方向让我们的海拔位置提高最高。
-
问题:
可能会卡在局部极大值处 -
失效: 电线杆问题:在一块平地上找方向是无效的。
-
比如:你处于一个山脊上,(下图是等高线)你向东西南北四个方向走都发现是在下山,所以推断出自己所处的地方是最高的,但是其实,最高处是最上面的等高线。
2、故事
- 使用的程序化英语是由Story Workbench程序提供给Genesis系统的
- 皮洛士式胜利(Pyrrhic victory):胜利刚开始看起来很棒,但其实不是那样。比如说:麦克白想当国王,之后他当上了国王,但是很不幸,他因此被人杀死。
- 程序回答常识问题是建立在目标树的基础上的;
- 程序回答反思层面,通过查找更高层的内容;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号