


sqlalchemy 源码导读一
推荐:https://www.osgeo.cn/sqlalchemy/orm/mapped_attributes.html
Sqlalchemy工具包导读
langhelpers
PluginLoader : 插件载入器
加载模块的两种方式
方式一:
import sqlalchemy.dialects.postgresql module1 = sqlalchemy.dialects module2 = module1.postgresql
方式二
sqlalchemy = __import__("sqlalchemy.dialects.postgresql") module1 = sqlalchemy.dialects module2 = getattr(module1, "postgresql")
属性设置器
def attrsetter(attrname): code = \ "def set(obj, value):" \ " obj.%s = value" % attrname env = locals().copy() exec(code, env) return env['set'] class Obj(object): name = None tmp_obj = Obj() tmp_set = attrsetter('name') tmp_set(tmp_obj, '张三') print(tmp_obj.name)
预备知识
python--threading多线程总结:https://www.cnblogs.com/tkqasn/p/5700281.html
Threading.local: https://www.jianshu.com/p/92aac41d33ca
Python中的__all__
文章作者:Tyan
博客:noahsnail.com | CSDN | 简书
作用
__all__是一个字符串list,用来定义模块中对于from XXX import *时要对外导出的符号,即要暴露的借口,但它只对import *起作用,对from XXX import XXX不起作用。
测试
all.py文件时要导出的模块,内容如下:
__all__ = ['x', 'y', 'test'] x = 2 y = 3 z = 4 def test(): print('test')
- 测试文件一
from foo import * print('x: ', x) print('y: ', y) print('z: ', z) test()
- 运行结果:
x: 2 y: 3 Traceback (most recent call last): File "test.py", line 6, in <module> print('z: ', z) NameError: name 'z' is not defined
- 测试文件二
from foo import * from foo import z print('x: ', x) print('y: ', y) print('z: ', z) test()
- 运行结果
x: 2 y: 3 z: 4 test
python type
class X(object): a = 1 instance = type('X', (object,), dict(a=1)) # 产生一个新的类型 X print instance.a
collections
class KeyedTuple(tuple): _slots__ = () def __new__(cls, vals, labels=None): t = tuple.__new__(cls, vals) if labels: t.__dict__.update(zip(labels, vals)) else: labels = [] t.__dict__["_labels"] = labels return t def keys(self): return [l for l in self._labels if l is not None] def __setattr__(self, key, value): raise AttributeError("Can't set attribute: %s" % key) def _asdict(self): return {key: self.__dict__[key] for key in self.keys()} labels = ['a', 'b', 'c'] values = [1, 2, 3] keyed_tuple = KeyedTuple(values, labels) print keyed_tuple.keys() # a', 'b', 'c'] print keyed_tuple._asdict() # {'a': 1, 'c': 3, 'b': 2} print keyed_tuple.a # 1 print keyed_tuple.b # 2
decorator装饰器
from sqlalchemy.util.langhelpers import decorator
先引入一般装饰器
# coding=utf-8 from functools import update_wrapper def decorate(fn): def wrapper(self, *args, **kw): print("执行前操作") fn(self, *args, **kw) return update_wrapper(wrapper, fn) class Man(object): @decorate def say(self, msg, times=3): print("%s " % msg * 3) m = Man() m.say('hello')
再来看sqlalchemy中的装饰器,为了突出装饰器概念,将提取源码中的一部分来讲解
源码:from sqlalchemy.sql.base import _generative
@decorator # 让一个函数具有装饰器的功能 def _generative(fn, self, msg, times): # 类似于装饰器中的wrapper print("执行前操作") fn(self, msg, times) class Man(object): @_generative def say(self, msg, times=3): print("%s " % msg * 3) m = Man() m.say('hello')
decorator的作用:
- 让装饰器以函数的形式存在
- 自动进行函数签名匹配
函数签名匹配,个人理解:
原函数的self参数与装饰器函数的self进行匹配,原函数的msg参数与装饰器函数的msg进行匹配
def _generative(fn, self, msg, times):
def say(self, msg, times=3):
下面来看简化后的decorator,去除了函数签名自动适配的功能,只演示如何让一个函数成为装饰器:
在上面我们把_generative看作一般装饰器中的wrapper是为了方便理解,实际上真正的wrapper应该是下面的code字符串,python内置函数exec将通过code动态生成wrapper
from functools import update_wrapper def _exec_code_in_env(code, env, fn_name): exec (code, env) return env[fn_name] def decorator(target): """A signature-matching decorator factory.""" def decorate(fn): targ_name, fn_name = ('target', 'fn') metadata = dict(target=targ_name, fn=fn_name, name=fn.__name__) code = """\ def %(name)s(self, msg, times=3): return %(target)s(%(fn)s, self, msg, times=times) """ % metadata decorated = _exec_code_in_env(code, {targ_name: target, fn_name: fn}, fn.__name__) decorated.__defaults__ = fn.__defaults__ decorated.__wrapped__ = fn return update_wrapper(decorated, fn) return update_wrapper(decorate, target)
完整版代码:


# coding=utf-8 import inspect from functools import update_wrapper from inspect import getargspec as inspect_getfullargspec from sqlalchemy.util.langhelpers import format_argspec_plus def decorator(target): """A signature-matching decorator factory.""" def decorate(fn): if not inspect.isfunction(fn): raise Exception("not a decoratable function") spec = inspect_getfullargspec(fn) targ_name, fn_name = ('target', 'fn') args = inspect.formatargspec(*spec) if spec[0]: self_arg = spec[0][0] elif spec[1]: self_arg = '%s[0]' % spec[1] else: self_arg = None apply_pos = inspect.formatargspec(spec[0], spec[1], spec[2]) num_defaults = 0 if spec[3]: num_defaults += len(spec[3]) name_args = spec[0] if num_defaults: defaulted_vals = name_args[0 - num_defaults:] else: defaulted_vals = () apply_kw = inspect.formatargspec(name_args, spec[1], spec[2], defaulted_vals, formatvalue=lambda x: '=' + x) tmp_dict = dict(args=args[1:-1], self_arg=self_arg, apply_pos=apply_pos[1:-1], apply_kw=apply_kw[1:-1]) metadata = dict(target=targ_name, fn=fn_name) metadata.update(tmp_dict) metadata['name'] = fn.__name__ code = """\ def %(name)s(%(args)s): return %(target)s(%(fn)s, %(apply_kw)s) """ % metadata decorated = _exec_code_in_env(code, {targ_name: target, fn_name: fn}, fn.__name__) decorated.__defaults__ = getattr(fn, 'im_func', fn).__defaults__ decorated.__wrapped__ = fn return update_wrapper(decorated, fn) return update_wrapper(decorate, target) def _exec_code_in_env(code, env, fn_name): exec (code, env) return env[fn_name] @decorator def _generative(fn, self, msg, times): print("执行前操作") fn(self, msg, times) class Man(object): @_generative def say(self, msg, times=3): print("%s " % msg * 3) m = Man() m.say('hello')
inspect.getargspec(python2,python3中该函数已改变)
class Man(object): @_generative def say(self, msg, times=3): print("%s " % msg * 3) from inspect import getargspec arg_spec = getargspec(Man.say) print(arg_spec.args) # ['self', 'msg', 'times'] print(arg_spec.varargs) #None print(arg_spec.keywords) #None print(arg_spec.defaults) # (3,) print(inspect.formatargspec(arg_spec[0], arg_spec[1], arg_spec[2])) # (self, msg, times)
Select
参考文档:https://www.osgeo.cn/sqlalchemy/core/sqlelement.html
from sqlalchemy import Table, Column, Integer, String, MetaData, select from sqlalchemy import create_engine from sqlalchemy import asc # engine = create_engine('sqlite:///:memory:', echo=True) from sqlalchemy.sql import Select from sqlalchemy.util.langhelpers import public_factory metadata = MetaData() users = Table( 'users', metadata, Column('id', Integer, primary_key=True), Column('name', String), Column('fullname', String) ) # metadata.create_all(engine) stmt = Select([users]).order_by(users.c.name) print (stmt)
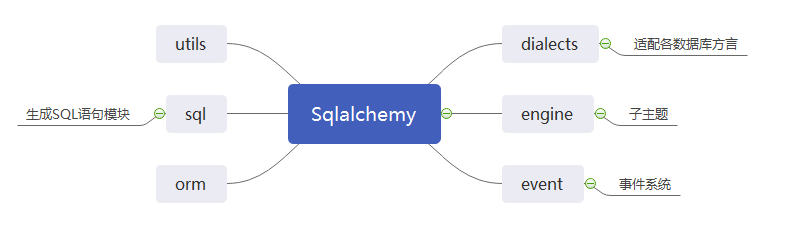
sqlalchemy模块构成
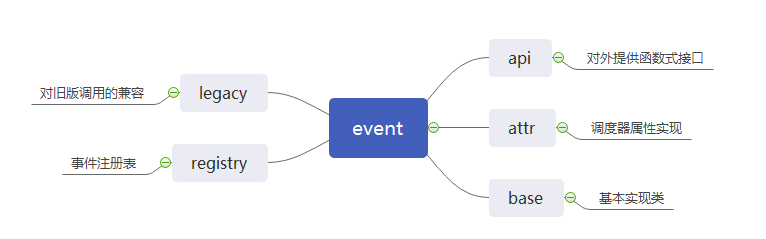
事件子系统
对事件系统化简示例,演示事件子系统基本调用流程
# coding=utf-8 import collections import weakref class _ClsLevelDispatch(object): """Class-level events on :class:`._Dispatch` classes.""" def __init__(self, parent_dispatch_cls, fn): self.name = fn.__name__ self._clslevel = weakref.WeakKeyDictionary() def append(self, event_key): target = event_key.dispatch_target assert isinstance(target, type), "Class-level Event targets must be classes." if target not in self._clslevel: self._clslevel[target] = collections.deque() self._clslevel[target].append(event_key.fn) def __call__(self, target, *args, **kwargs): listeners = self._clslevel[target.__class__] for listener in listeners: listener(*args, **kwargs) class _EventMeta(type): def __init__(cls, classname, bases, dict_): # 获取事件接口的事件名如:PoolEvents下的connect和first_connect event_names = [k for k in dict_ if not k.startswith('_') and k != 'dispatch'] dispatch_cls = type("%sDispatch" % classname, (object,), {}) dispatch_inst = dispatch_cls() for k in event_names: setattr(dispatch_inst, k, _ClsLevelDispatch(cls, dict_[k])) if getattr(cls, '_dispatch_target', None): # 为Pool配置调度器dispatch cls._dispatch_target.dispatch = dispatch_inst type.__init__(cls, classname, bases, dict_) class Pool(object): pass class PoolEvents(object): """连接池事件接口""" __metaclass__ = _EventMeta # 调度目标,元类会在该类加载的时候,在目标对象上配置调度器(dispatch)属性 _dispatch_target = Pool def connect(self, dbapi_connection, connection_record): """""" def first_connect(self, dbapi_connection, connection_record): """""" class _EventKey(object): def __init__(self, target, identifier, fn, dispatch_target): self.target = target self.identifier = identifier self.fn = fn self.fn_key = id(fn) self.dispatch_target = dispatch_target def base_listen(self): target, identifier, fn = self.dispatch_target, self.identifier, self.fn dispatch_collection = getattr(target.dispatch, identifier) dispatch_collection.append(self) def listen(target, identifier, fn): """Public API functions for the event system""" event_key = _EventKey(target, identifier, fn, target) event_key.base_listen() def on_connect_callback(*args, **kw): """事件触发后的回调函数""" print(args, kw) if __name__ == '__main__': my_pool = Pool() # 为目标对象(Pool)添加事件(connect)监听, listen(Pool, 'connect', on_connect_callback) # 触发事件(connect)所有监听函数 my_pool.dispatch.connect(my_pool, 'args1', 'args1', kw1="kw1")
引擎子系统
预备知识
正则:
正则表达式30分钟入门教程: https://deerchao.cn/tutorials/regex/regex.htm
(?: exp): 匹配exp,不捕获匹配的文本,也不给此分组分配组号
(?P<name> exp): 匹配exp,并捕获文本到名称为name的组里
示例:
(?P<name>[\w\+]+) # 捕获name分组(该分组对字母、数字、下划线和加号匹配一次或多次,如:123abc+++),\w: 字母、数字或下划线,\+:加号,+:表示一次或多次,[ab]:表示a或b
(?::(?P<password>.*))? # 非捕获分组内嵌一个捕获分组,后面的问号表示非贪婪匹配(最少匹配)
url模块
make_url函数,通过正则把数据库url地址转化为一个(URL)Python对象,本只演示正则部分。
def make_url(name_or_url): pattern = re.compile(r''' (?P<name>[\w\+]+):// (?: (?P<username>[^:/]*) (?::(?P<password>.*))? @)? # @符号不是正则关键字,为普通字符 (?: (?: \[(?P<ipv6host>[^/]+)\] | (?P<ipv4host>[^/:]+) )? (?::(?P<port>[^/]*))? )? (?:/(?P<database>.*))? ''', re.X) m = pattern.match(name_or_url) components = m.groupdict() return components # {'username': 'username', 'name': 'postgresql', 'database': 'database', 'ipv6host': None, # 'ipv4host': '127.0.0.1', 'password': 'password', 'port': '5432'} print(make_url("postgresql://username:password@127.0.0.1:5432/database"))
URL类
简单使用示例
from sqlalchemy.engine.url import make_url url = make_url("postgresql://username:password@127.0.0.1:5432/database") print(url.drivername) # postgresql print(url.username) # username print(url.password) # password print(url.host) # 127.0.0.1 print(url.get_dialect()) # <class 'sqlalchemy.dialects.postgresql.psycopg2.PGDialect_psycopg2'>
该类中比较难理解的一部分就是get_dialect函数,通过驱动名(postgresql)加载dialect类
if '+' not in self.drivername: name = self.drivername else: name = self.drivername.replace('+', '.') cls = registry.load(name) # 加载位置
本次只讲解关键代码,详细请看langhelpers章节
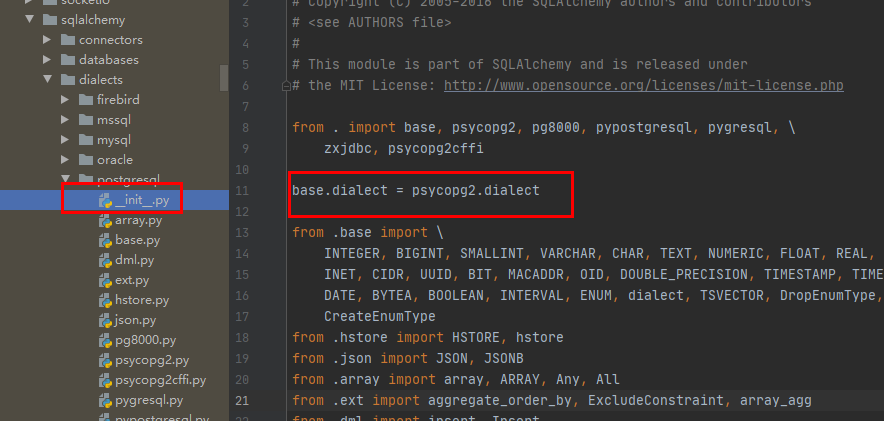
def load(dialect=None): driver = "base" sqlalchemy = __import__("sqlalchemy.dialects.%s" % dialect) postgresql_module = getattr(sqlalchemy.dialects, dialect) driver_module = getattr(postgresql_module, driver) cls = driver_module.dialect return cls dialect_cls = load("postgresql") print(dialect_cls)
直接导入是不可以的from sqlalchemy.dialects.postgresql.base import dialect,base.py下没有dialect
# coding=utf-8 class MemoizedSlots(object): """Apply memoized items to an object using a __getattr__ scheme. This allows the functionality of memoized_property and memoized_instancemethod to be available to a class using __slots__. """ __slots__ = () def _fallback_getattr(self, key): raise AttributeError(key) def __getattr__(self, key): if key.startswith("_memoized"): raise AttributeError(key) elif hasattr(self, "_memoized_attr_%s" % key): value = getattr(self, "_memoized_attr_%s" % key)() setattr(self, key, value) return value elif hasattr(self, "_memoized_method_%s" % key): fn = getattr(self, "_memoized_method_%s" % key) def oneshot(*args, **kw): result = fn(*args, **kw) def memo(*a, **kw): return result memo.__name__ = fn.__name__ memo.__doc__ = fn.__doc__ setattr(self, key, memo) return result oneshot.__doc__ = fn.__doc__ return oneshot else: return self._fallback_getattr(key) class Man(MemoizedSlots): def _memoized_attr_name(self): return u"张三" def _memoized_method_age(self): return 123 m = Man() name1 = m.name name2 = m.name age1 = m.age() age2 = m.age() print(age1, age2) print(name1, name2)
from sqlalchemy import Table, Column, Integer, String, MetaData, exc from sqlalchemy.sql.compiler import OPERATORS from sqlalchemy import Column, String from sqlalchemy.sql import Select def _compiler_dispatch(self, visitor, **kw): visit_attr = 'visit_%s' % self.__visit_name__ try: meth = getattr(visitor, visit_attr) except AttributeError: raise exc.UnsupportedCompilationError(visitor, self.__class__) else: return meth(self, **kw) class SQLCompiler(object): def __init__(self, statement): self.statement = statement self.string = statement._compiler_dispatch(self) def visit_select(self, select, **kwargs): froms = select._froms text = "SELECT " inner_columns = [] for name, column in select._columns_plus_names: column_name = column._compiler_dispatch(self) inner_columns.append(column_name) text = self._compose_select_body(text, select, inner_columns, froms, kwargs) return text def _compose_select_body(self, text, select, inner_columns, froms, kwargs): text += ", ".join(inner_columns) if froms: text += " \nFROM " text += ", ".join([table._compiler_dispatch(self) for table in froms]) if select._order_by_clause.clauses: text += self.order_by_clause(select, **kwargs) return text def visit_column(self, column): name = column.name tablename = column.table.name return tablename + "." + name def visit_table(self, table): return table.name def order_by_clause(self, select, **kw): """allow dialects to customize how ORDER BY is rendered.""" order_by = select._order_by_clause._compiler_dispatch(self, **kw) if order_by: return " ORDER BY " + order_by else: return "" def visit_clauselist(self, clauselist, **kw): sep = OPERATORS[clauselist.operator] ret = [] for c in clauselist.clauses: res = c._compiler_dispatch(self, **kw) ret.append(res) text = sep.join(ret) return text def __str__(self): return self.string """ stmt = Select([users]).order_by(users.c.name) dialect = StrCompileDialect() sql_compiler = SQLCompiler(dialect, stmt) """ if __name__ == '__main__': users = Table( 'users', MetaData(), Column('id', Integer, primary_key=True), Column('name', String), Column('fullname', String) ) stmt = Select([users]).order_by(users.c.name) stmt.__class__._compiler_dispatch = _compiler_dispatch sql_compiler = SQLCompiler(stmt) string = str(sql_compiler) print (string)
# coding=utf-8 from sqlalchemy import Table, Column, Integer, String, MetaData, exc, delete from sqlalchemy import Column, String from sqlalchemy.sql import Delete users = Table( 'users', MetaData(), Column('id', Integer, primary_key=True), Column('name', String), Column('first_name', String), Column('last_name', String) ) stmt = users.delete().where(users.c.name == '张三') print(stmt) stmt = Delete(users).where(users.c.name == '张三') print(stmt) stmt = users.insert().returning((users.c.first_name + " " + users.c.last_name).label('fullname')) print(stmt) stmt = users.update().where(users.c.name == '张三').values(name='X').returning(users.c.first_name, users.c.last_name) print(stmt) # for server_flag, updated_timestamp in connection.execute(stmt): # print(server_flag, updated_timestamp)
# coding=utf-8 import operator from sqlalchemy import String from sqlalchemy.sql.elements import BinaryExpression, BindParameter def _boolean_compare(expr, op, obj, negate=None, **kwargs): from sqlalchemy import Column real_expr = Column(expr.name, expr.type) obj = BindParameter(real_expr.key, obj, _compared_to_operator=op, _compared_to_type=real_expr.type, type_=None, unique=True) return BinaryExpression(real_expr, obj, op, type_=None, negate=negate, modifiers=kwargs) def like_op(a, b, escape=None): return a.like(b, escape=escape) def notlike_op(a, b, escape=None): return a.notlike(b, escape=escape) operator_lookup = { "eq": (_boolean_compare, operator.ne), "like_op": (_boolean_compare, notlike_op), } class ColumnOperators(object): def operate(self, op, *other, **kwargs): o = operator_lookup[op.__name__] return o[0](self, op, *(other + o[1:]), **kwargs) def __eq__(self, other): return self.operate(operator.eq, other) def like(self, other, escape=None): return self.operate(like_op, other, escape=escape) class Column(ColumnOperators): def __init__(self, name, _type): self.name = name self.type = _type if __name__ == '__main__': name = Column('name', String) address = Column('address', String) ret1 = name == "张三" ret2 = address == "花果山" ret3 = address.like("%果%") print(ret1, ret2, ret3) print(str(ret1), str(ret2), str(ret3))
engine/result.py
from sqlalchemy.cresultproxy import BaseRowProxy class RowProxy(BaseRowProxy): pass
出于性能优化的目的,BaseRowProxy由C代码实现,实际代码位置:site-pachages/sqlalchemy/cresultproxy.so
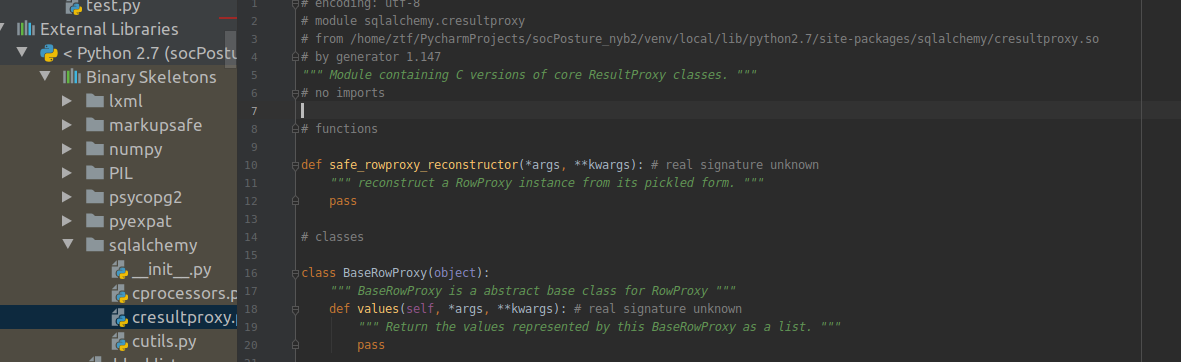
使用C/C++编写Python模块扩展:https://segmentfault.com/a/1190000011693325
result.py
import operator import re from sqlalchemy.sql import util as sql_util, sqltypes, expression from sqlalchemy import util, exc import psycopg2 def rowproxy_reconstructor(cls, state): obj = cls.__new__(cls) obj.__setstate__(state) return obj class ResultMetaData(object): """Handle cursor.description, applying additional info from an execution context.""" __slots__ = ( "_keymap", "case_sensitive", "matched_on_name", "_processors", "keys", "_orig_processors", ) def __init__(self, parent, cursor_description): self.case_sensitive = True self.matched_on_name = False self._orig_processors = None # merge cursor.description with the column info # present in the compiled structure, if any raw = self._merge_cursor_description(cursor_description) self._keymap = {} self._processors = [elem[3] for elem in raw] # keymap by primary string... by_key = dict([(elem[2], (elem[3], elem[4], elem[0])) for elem in raw]) # update keymap with primary string names taking # precedence self._keymap.update(by_key) def _merge_cursor_description(self, cursor_description): # no compiled SQL, just a raw string raw_iterator = self._merge_cols_by_none(cursor_description) ret = [] for (idx, colname, mapped_type, coltype, obj, untranslated) in raw_iterator: result_processor = None ret.append( (idx, colname, colname, result_processor, obj, untranslated) ) return ret def _colnames_from_description(self, cursor_description): untranslated = None self.keys = [] for idx, rec in enumerate(cursor_description): colname = rec[0] coltype = rec[1] colname = unicode(colname) self.keys.append(colname) yield idx, colname, untranslated, coltype def _merge_textual_cols_by_position(self, cursor_description, result_columns): num_ctx_cols = len(result_columns) if result_columns else None if num_ctx_cols > len(cursor_description): util.warn( "Number of columns in textual SQL (%d) is " "smaller than number of columns requested (%d)" % (num_ctx_cols, len(cursor_description)) ) seen = set() for (idx, colname, untranslated, coltype) in self._colnames_from_description(cursor_description): if idx < num_ctx_cols: ctx_rec = result_columns[idx] obj = ctx_rec[2] mapped_type = ctx_rec[3] if obj[0] in seen: raise exc.InvalidRequestError( "Duplicate column expression requested " "in textual SQL: %r" % obj[0] ) seen.add(obj[0]) else: mapped_type = sqltypes.NULLTYPE obj = None yield idx, colname, mapped_type, coltype, obj, untranslated def _merge_cols_by_name(self, cursor_description, result_columns): result_map = self._create_result_map(result_columns, self.case_sensitive) self.matched_on_name = True for ( idx, colname, untranslated, coltype, ) in self._colnames_from_description(cursor_description): try: ctx_rec = result_map[colname] except KeyError: mapped_type = sqltypes.NULLTYPE obj = None else: obj = ctx_rec[1] mapped_type = ctx_rec[2] yield idx, colname, mapped_type, coltype, obj, untranslated def _merge_cols_by_none(self, cursor_description): for (idx, colname, untranslated, coltype) in self._colnames_from_description(cursor_description): yield idx, colname, sqltypes.NULLTYPE, coltype, None, untranslated @classmethod def _create_result_map(cls, result_columns, case_sensitive=True): d = {} for elem in result_columns: key, rec = elem[0], elem[1:] if not case_sensitive: key = key.lower() if key in d: # conflicting keyname, just double up the list # of objects. this will cause an "ambiguous name" # error if an attempt is made by the result set to # access. e_name, e_obj, e_type = d[key] d[key] = e_name, e_obj + rec[1], e_type else: d[key] = rec return d def _key_fallback(self, key, err, raiseerr=True): map_ = self._keymap result = None if isinstance(key, util.string_types): result = map_.get(key if self.case_sensitive else key.lower()) # fallback for targeting a ColumnElement to a textual expression # this is a rare use case which only occurs when matching text() # or colummn('name') constructs to ColumnElements, or after a # pickle/unpickle roundtrip elif isinstance(key, expression.ColumnElement): if ( key._label and (key._label if self.case_sensitive else key._label.lower()) in map_ ): result = map_[ key._label if self.case_sensitive else key._label.lower() ] elif ( hasattr(key, "name") and (key.name if self.case_sensitive else key.name.lower()) in map_ ): # match is only on name. result = map_[ key.name if self.case_sensitive else key.name.lower() ] # search extra hard to make sure this # isn't a column/label name overlap. # this check isn't currently available if the row # was unpickled. if result is not None and result[1] is not None: for obj in result[1]: if key._compare_name_for_result(obj): break else: result = None if result is None: if raiseerr: util.raise_( exc.NoSuchColumnError( "Could not locate column in row for column '%s'" % expression._string_or_unprintable(key) ), replace_context=err, ) else: return None else: map_[key] = result return result def _has_key(self, key): if key in self._keymap: return True else: return self._key_fallback(key, None, False) is not None def _getter(self, key, raiseerr=True): if key in self._keymap: processor, obj, index = self._keymap[key] else: ret = self._key_fallback(key, None, raiseerr) if ret is None: return None processor, obj, index = ret if index is None: util.raise_( exc.InvalidRequestError( "Ambiguous column name '%s' in " "result set column descriptions" % obj ), from_=None, ) return operator.itemgetter(index) def __getstate__(self): return { "_pickled_keymap": dict( (key, index) for key, (processor, obj, index) in self._keymap.items() if isinstance(key, util.string_types + util.int_types) ), "keys": self.keys, "case_sensitive": self.case_sensitive, "matched_on_name": self.matched_on_name, } def __setstate__(self, state): # the row has been processed at pickling time so we don't need any # processor anymore self._processors = [None for _ in range(len(state["keys"]))] self._keymap = keymap = {} for key, index in state["_pickled_keymap"].items(): # not preserving "obj" here, unfortunately our # proxy comparison fails with the unpickle keymap[key] = (None, None, index) self.keys = state["keys"] self.case_sensitive = state["case_sensitive"] self.matched_on_name = state["matched_on_name"] class BaseRowProxy(object): __slots__ = ("_parent", "_row", "_processors", "_keymap") def __init__(self, parent, row, processors, keymap): self._parent = parent self._row = row self._processors = processors self._keymap = keymap def __reduce__(self): return ( rowproxy_reconstructor, (self.__class__, self.__getstate__()), ) def values(self): return list(self) def __iter__(self): for processor, value in zip(self._processors, self._row): if processor is None: yield value else: yield processor(value) def __len__(self): return len(self._row) def __getitem__(self, key): try: processor, obj, index = self._keymap[key] except KeyError as err: return self._row[key] def __getattr__(self, name): try: return self[name] except KeyError as e: util.raise_(AttributeError(e.args[0]), replace_context=e) class RowProxy(BaseRowProxy): __slots__ = () def __contains__(self, key): return self._parent._has_key(key) def __getstate__(self): return {"_parent": self._parent, "_row": tuple(self)} def __setstate__(self, state): self._parent = parent = state["_parent"] self._row = state["_row"] self._processors = parent._processors self._keymap = parent._keymap __hash__ = None def _op(self, other, op): return ( op(tuple(self), tuple(other)) if isinstance(other, RowProxy) else op(tuple(self), other) ) def __lt__(self, other): return self._op(other, operator.lt) def __le__(self, other): return self._op(other, operator.le) def __ge__(self, other): return self._op(other, operator.ge) def __gt__(self, other): return self._op(other, operator.gt) def __eq__(self, other): return self._op(other, operator.eq) def __ne__(self, other): return self._op(other, operator.ne) def __repr__(self): # return "repr(sql_util._repr_row(self))" return repr(sql_util._repr_row(self)) def has_key(self, key): return self._parent._has_key(key) def items(self): return [(key, self[key]) for key in self.keys()] def keys(self): return self._parent.keys def iterkeys(self): return iter(self._parent.keys) def itervalues(self): return iter(self) def values(self): return super(RowProxy, self).values() class ResultProxy(object): _process_row = RowProxy closed = False _metadata = None def __init__(self, cursor): self.cursor = self._saved_cursor = cursor self._init_metadata() def _getter(self, key, raiseerr=True): try: getter = self._metadata._getter except AttributeError as err: return None else: return getter(key, raiseerr) def _has_key(self, key): try: has_key = self._metadata._has_key except AttributeError as err: return None else: return has_key(key) def _init_metadata(self): cursor_description = self._cursor_description() self._metadata = ResultMetaData(self, cursor_description) def keys(self): if self._metadata: return self._metadata.keys else: return [] @property def lastrowid(self): return self._saved_cursor.lastrowid @property def returns_rows(self): return self._metadata is not None def _cursor_description(self): return self._saved_cursor.description def close(self): if not self.closed: self.closed = True def __iter__(self): while True: row = self.fetchone() if row is None: return else: yield row def __next__(self): row = self.fetchone() if row is None: raise StopIteration() else: return row next = __next__ def _fetchone_impl(self): try: return self.cursor.fetchone() except AttributeError as err: return None def _fetchmany_impl(self, size=None): try: if size is None: return self.cursor.fetchmany() else: return self.cursor.fetchmany(size) except AttributeError as err: return None def _fetchall_impl(self): try: return self.cursor.fetchall() except AttributeError as err: return None def process_rows(self, rows): process_row = self._process_row metadata = self._metadata keymap = metadata._keymap processors = metadata._processors return [ process_row(metadata, row, processors, keymap) for row in rows ] def fetchall(self): try: l = self.process_rows(self._fetchall_impl()) return l except BaseException as e: print(e) def fetchmany(self, size=None): try: l = self.process_rows(self._fetchmany_impl(size)) return l except BaseException as e: print(e) def fetchone(self): try: row = self._fetchone_impl() if row is not None: return self.process_rows([row])[0] return None except BaseException as e: print(e) def first(self): try: row = self._fetchone_impl() if row is not None: return self.process_rows([row])[0] return None except BaseException as e: print(e) finally: self.close() def scalar(self): row = self.first() if row is not None: return row[0] else: return None if __name__ == '__main__': conn = psycopg2.connect(database="postgres", host="localhost", password=u"postgres", port="5432", user="postgres") cursor = conn.cursor() cursor.execute("select version()") result = ResultProxy(cursor) row = result.scalar() m = re.match( r".*(?:PostgreSQL|EnterpriseDB) " r"(\d+)\.?(\d+)?(?:\.(\d+))?(?:\.\d+)?(?:devel|beta)?", row, ) ret = tuple([int(x) for x in m.group(1, 2, 3) if x is not None]) print(ret)
import psycopg2 import sqlalchemy.pool as pool from sqlalchemy.dialects.postgresql.psycopg2 import PGDialect_psycopg2 def getconn(): conn = psycopg2.connect(database="postgres", host="localhost", password=u"postgres", port="5432", user="postgres") # conn = psycopg2.connect(database="postgre", host="localhost", password=u"postgres", port="5432", user="postgres") return conn dialect = PGDialect_psycopg2() mypool = pool.QueuePool(getconn, max_overflow=10, pool_size=5, pre_ping=True, dialect=dialect) # get a connection conn = mypool.connect() conn.close() conn = mypool.connect() conn.close() # use it cursor = conn.cursor() cursor.execute("select 1") # "close" the connection. Returns # it to the pool. conn.close()
参考文档:
函数签名:https://developer.mozilla.org/zh-CN/docs/Glossary/Signature/Function
Python3 exec 函数:https://www.runoob.com/python3/python3-func-exec.html
__defaults__魔术方法简介:https://www.cnblogs.com/zhumengke/articles/12061000.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号