
K8s入门
中文社区文档: https://www.kubernetes.org.cn/doc-45
https://kuboard.cn/learning/
Ubuntu18.04安装k8s
作者:HoPGoldy 来源:简书 链接:https://www.jianshu.com/p/f2d4dd4d1fb1
版权声明:本文为CSDN博主「迷失0」的原创文章。 原文链接:https://blog.csdn.net/u010827484/article/details/83025404
前言
本文介绍如何在ubuntu上部署k8s集群,大致可以分为如下几个步骤:
- 修改
ubuntu配置 - 安装
docker - 安装
kubeadm、kubectl以及kubelet - 初始化
master节点 - 将
slave节点加入网络
如果你对上面的某些名字感到陌生,没关系,下文会一一进行讲解,如果你想先了解一下 docker 和 k8s,可以参考 10分钟看懂Docker和K8S。好了,在正式开始之前,首先看一下我们都有哪些服务器,如果你对如何组建如下虚拟机网络感兴趣的话,可以参考 virtualbox 虚拟机组网:
| 主机名 | 主机ip | 版本 | CPU | 内存 |
|---|---|---|---|---|
| master1 | 192.168.56.11 | Ubuntu server 18.04 | 2核 | 1G |
| worker1 | 192.168.56.21 | Ubuntu server 18.04 | 2核 | 1G |
因为k8s分为管理节点和工作节点,所以我们将要 在master1上部署管理节点,在worker1上部署工作节点。如果想了解如何创建这两个节点,可以参考 virtualbox 虚拟机组网 。服务器配置上,k8s 要求 CPU 最低为 2 核,不然在安装过程中会报错,虽然这个错误可以避免,但是为了稳定起见还是把虚拟机的配置成它想要的,至于内存 k8s 没有硬性要求,所以我就按我电脑的性能来分配了。
注意,本文的 docker、k8s 等软件安装均未指定具体版本,在本文完成时2019/6/27,下载到的版本如下,如有特殊版本需要请自行指定版本。
| 软件名 | 版本 |
|---|---|
| docker | 18.09.5 |
| kubectl | 1.15.0-00 amd64 |
| kubeadm | 1.15.0-00 amd64 |
| kubelet | 1.15.0-00 amd64 |
一. 修改 ubuntu 配置
首先,k8s 要求我们的 ubuntu 进行一些符合它要求的配置。很简单,包括以下两步:关闭 Swap 内存 以及 配置免密登录,这一步两台主机都需要进行配置。
关闭 swap 内存
这个swap其实可以类比成 windows 上的虚拟内存,它可以让服务器在内存吃满的情况下可以保持低效运行,而不是直接卡死。但是 k8s 的较新版本都要求关闭swap。所以咱们直接动手,修改/etc/fstab文件:
sudo vi /etc/fstab
你应该可以看到如下内容,把第二条用#注释掉就好了,注意第一条别注释了,不然重启之后系统有可能会报file system read-only错误。
UUID=e2048966-750b-4795-a9a2-7b477d6681bf / ext4 errors=remount-ro 0 1 # /dev/fd0 /media/floppy0 auto rw,user,noauto,exec,utf8 0 0
然后输入reboot重启即可,重启后使用top命令查看任务管理器,如果看到如下KiB Swap后均为 0 就说明关闭成功了。
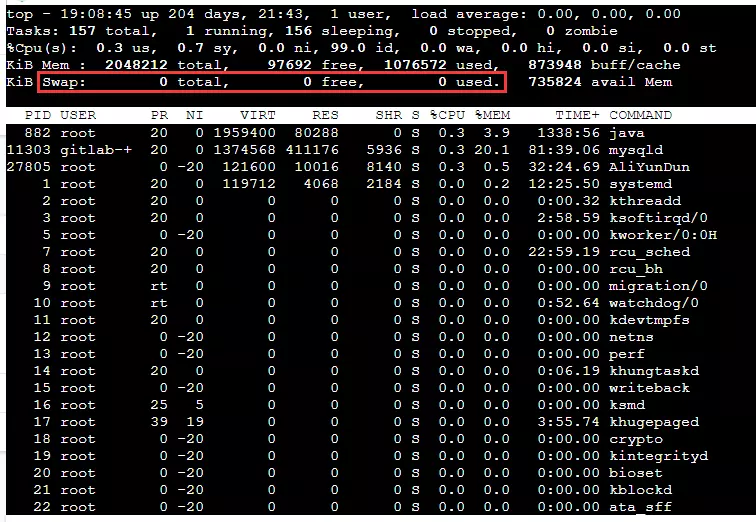
上面说的是永久关闭swap内存,其实也可以暂时关闭,使用swapoff -a命令即可,效果会在重启后消失。
配置免密登录
k8s 要求 管理节点可以直接免密登录工作节点 的原因是:在集群搭建完成后,管理节点的 kubelet 需要登陆工作节点进行操作。而至于怎么操作很简单,这里就不详提了,可以参见文章 virtualbox 虚拟机组网 的最后一个章节 免密钥登录 。
二. 安装 docker
docker 是 k8s 的基础,在安装完成之后也需要修改一些配置来适配 k8s ,所以本章分为 docker 的安装 与 docker 的配置 两部分。如果你已经安装并使用了一段时间的 docker 了话,建议使用docker -v查看已安装的 docker 版本,并在 k8s 官网上查询适合该版本的 k8s 进行安装。这一步两台主机都需要进行安装。
docker 的安装
docker 在 ubuntu 的安装上真是再简单不过了,执行如下命令即可,在安装之前请记得把镜像源切换到国内。
sudo apt install docker.io
等安装完成之后使用docker -v来验证 docker是否可用。
docker 的配置
安装完成之后需要进行一些配置,包括 切换docker下载源为国内镜像站 以及 修改cgroups。
这个cgroups是啥呢,你可以把它理解成一个进程隔离工具,docker就是用它来实现容器的隔离的。docker 默认使用的是cgroupfs,而 k8s 也用到了一个进程隔离工具systemd,如果使用两个隔离组的话可能会引起异常,所以我们要把 docker 的也改成systemd。
这两者都是在/etc/docker/daemon.json里修改的,所以我们一起配置了就好了,首先执行下述命令编辑daemon.json:
sudo vi /etc/docker/daemon.json
打开后输入以下内容:
{ "registry-mirrors": [ "https://dockerhub.azk8s.cn", "https://reg-mirror.qiniu.com", "https://quay-mirror.qiniu.com" ], "exec-opts": [ "native.cgroupdriver=systemd" ] }
然后:wq保存后重启 docker:
sudo systemctl daemon-reload sudo systemctl restart docker
然后就可以通过docker info | grep Cgroup来查看修改后的 docker cgroup 状态,发现变为systemd即为修改成功。
三. 安装 k8s
安装完了 docker 就可以下载 k8s 的三个主要组件kubelet、kubeadm以及kubectl了。这一步两台主机都需要进行安装。先来简单介绍一下这三者:
kubelet: k8s 的核心服务kubeadm: 这个是用于快速安装 k8s 的一个集成工具,我们在master1和worker1上的 k8s 部署都将使用它来完成。kubectl: k8s 的命令行工具,部署完成之后后续的操作都要用它来执行
其实这三个的下载很简单,直接用apt-get就好了,但是因为某些原因,它们的下载地址不存在了。所以我们需要用国内的镜像站来下载,也很简单,依次执行下面五条命令即可:
# 使得 apt 支持 ssl 传输 apt-get update && apt-get install -y apt-transport-https # 下载 gpg 密钥 curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - # 添加 k8s 镜像源 cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF # 更新源列表 apt-get update # 下载 kubectl,kubeadm以及 kubelet apt-get install -y kubelet=1.15.0-00 kubeadm=1.15.0-00 kubectl=1.15.0-00
直接在/etc/apt/sources.list里添加https://mirrors.aliyun.com/kubernetes/apt/是不行的,因为这个阿里镜像站使用的ssl进行传输的,所以要先安装apt-transport-https并下载镜像站的密钥才可以进行下载。
四. 安装 master 节点
下载完成后就要迎来重头戏了,初始化master节点,这一章节只需要在管理节点上配置即可,大致可以分为如下几步:
- 初始化
master节点 - 部署
flannel网络 - 配置
kubectl工具
初始化 master 节点
使用kubeadm的init命令就可以轻松的完成初始化,不过需要携带几个参数,如下。先不要直接复制执行,将赋值给--apiserver-advertise-address参数的 ip 地址修改为自己的master主机地址,然后再执行。
kubeadm init \ --apiserver-advertise-address=192.168.1.252 \ --kubernetes-version=v1.15.0 \ --image-repository registry.aliyuncs.com/google_containers \ --pod-network-cidr=10.10.0.0/16
这里介绍一下一些常用参数的含义:
--apiserver-advertise-address: k8s 中的主要服务apiserver的部署地址,填自己的管理节点 ip--image-repository: 拉取的 docker 镜像源,因为初始化的时候kubeadm会去拉 k8s 的很多组件来进行部署,所以需要指定国内镜像源,下不然会拉取不到镜像。--pod-network-cidr: 这个是 k8s 采用的节点网络,因为我们将要使用flannel作为 k8s 的网络,所以这里填10.244.0.0/16就好--kubernetes-version: 这个是用来指定你要部署的 k8s 版本的,一般不用填,不过如果初始化过程中出现了因为版本不对导致的安装错误的话,可以用这个参数手动指定。--ignore-preflight-errors: 忽略初始化时遇到的错误,比如说我想忽略 cpu 数量不够 2 核引起的错误,就可以用--ignore-preflight-errors=CpuNum。错误名称在初始化错误时会给出来。
当你看到如下字样是,就说明初始化成功了,请把最后那行以kubeadm join开头的命令复制下来,之后安装工作节点时要用到的,如果你不慎遗失了该命令,可以在master节点上使用kubeadm token create --print-join-command命令来重新生成一条。
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.56.11:6443 --token wbryr0.am1n476fgjsno6wa --discovery-token-ca-cert-hash sha256:7640582747efefe7c2d537655e428faa6275dbaff631de37822eb8fd4c054807
如果在初始化过程中出现了任何Error导致初始化终止了,使用kubeadm reset重置之后再重新进行初始化。
初始化节点方式二
建立配置文件
root@ubuntu:~# cat kubeadm.conf apiVersion: kubeadm.k8s.io/v1alpha2 kind: MasterConfiguration api: advertiseAddress: 0.0.0.0 networking: podSubnet: 10.244.0.0/16 etcd: image: registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64:3.2.24 kubernetesVersion: v1.12.1 imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
初始化master节点
kubeadm init --config kubeadm.conf
配置 kubectl 工具
这一步就比较简单了,直接执行如下命令即可:
mkdir -p /root/.kube && \ cp /etc/kubernetes/admin.conf /root/.kube/config
执行完成后并不会刷新出什么信息,可以通过下面两条命令测试 kubectl是否可用:
# 查看已加入的节点
kubectl get nodes
# 查看集群状态
kubectl get cs
部署 flannel 网络
flannel是什么?它是一个专门为 k8s 设置的网络规划服务,可以让集群中的不同节点主机创建的 docker 容器都具有全集群唯一的虚拟IP地址。想要部署flannel的话直接执行下述命令即可:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml
输出如下内容即为安装完成:
clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.extensions/kube-flannel-ds-amd64 created daemonset.extensions/kube-flannel-ds-arm64 created daemonset.extensions/kube-flannel-ds-arm created daemonset.extensions/kube-flannel-ds-ppc64le created daemonset.extensions/kube-flannel-ds-s390x created
至此,k8s 管理节点部署完成。
五. 将 slave 节点加入网络
首先需要重复步骤 1 ~ 3 来安装 docker 、k8s 以及修改服务器配置,之后执行从步骤 4 中保存的命令即可完成加入,注意,这条命令每个人的都不一样,不要直接复制执行:
kubeadm join 192.168.56.11:6443 --token wbryr0.am1n476fgjsno6wa --discovery-token-ca-cert-hash sha256:7640582747efefe7c2d537655e428faa6275dbaff631de37822eb8fd4c054807
待控制台中输出以下内容后即为加入成功:
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the master to see this node join the cluster.
随后登录master1查看已加入节点状态,可以看到worker1已加入,并且状态均为就绪。至此,k8s 搭建完成:
root@master1:~# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 145m v1.15.0 worker1 Ready <none> 87m v1.15.0
默认网卡问题修复
如果你是使用virtualBox部署的虚拟机,并且虚拟机直接无法使用网卡1的 ip 地址互相访问的话(例如组建双网卡,网卡1为 NAT 地址转换用来上网,网卡2为Host-only,用于虚拟机之间访问)。就需要执行本节的内容来修改 k8s 的默认网卡。不然会出现一些命令无法使用的问题。如果你的默认网卡可以进行虚拟机之间的相互访问,则没有该问题。
修改 kubelet 默认地址
访问kubelet配置文件:
sudo vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
在最后一行ExecStart 之前 添加如下内容:
Environment="KUBELET_EXTRA_ARGS=--node-ip=192.168.56.21"
重启kubelet:
systemctl stop kubelet.service && \ systemctl daemon-reload && \ systemctl start kubelet.service
至此修改完成,更多信息详见 kubectl logs、exec、port-forward 执行失败问题解决 。
修改 flannel 的默认网卡
编辑flannel配置文件
sudo kubectl edit daemonset kube-flannel-ds-amd64 -n kube-system
找到spec.template.spec.containers.args字段并添加--iface=网卡名,例如我的网卡是enp0s8:
- args: - --ip-masq - --kube-subnet-mgr # 添加到这里 - --iface=enp0s8
:wq保存修改后输入以下内容删除所有 flannel,k8s 会自动重建:
kubectl delete pod -n kube-system -l app=flannel
至此修改完成,更多内容请见 解决k8s无法通过svc访问其他节点pod的问题 。
K8s断电重启
一个节点显示NotReady
$ kubectl get nodes
重启kubelet
systemctl restart kubelet.service
Some users on RHEL/CentOS 7 have reported issues with traffic being routed incorrectly due to iptables being bypassed. You should ensure net.bridge.bridge-nf-call-iptables is set to 1 in your sysctl config, e.g.
root@ubuntu:~# sysctl net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-iptables = 1 root@ubuntu:~# sed -i "s,ExecStart=$,Environment=\"KUBELET_EXTRA_ARGS=--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.1\"\nExecStart=,g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf root@ubuntu:~# systemctl daemon-reload root@ubuntu:~# systemctl restart kubelet
查看当前kubeadm版本号和所需组件
root@ubuntu:~# kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"12", GitVersion:"v1.12.1", GitCommit:"4ed3216f3ec431b140b1d899130a69fc671678f4", GitTreeState:"clean", BuildDate:"2018-10-05T16:43:08Z", GoVersion:"go1.10.4", Compiler:"gc", Platform:"linux/amd64"} root@ubuntu:~# kubeadm config images list --kubernetes-version=v1.12.1 k8s.gcr.io/kube-apiserver:v1.12.1 k8s.gcr.io/kube-controller-manager:v1.12.1 k8s.gcr.io/kube-scheduler:v1.12.1 k8s.gcr.io/kube-proxy:v1.12.1 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.2.24 k8s.gcr.io/coredns:1.2.2
查看kubernetes pod
root@ubuntu:~# kubectl get pod --all-namespaces The connection to the server localhost:8080 was refused - did you specify the right host or port?
提示错误,是由于API认证失败导致,执行以下命令解决
root@ubuntu:~# mkdir -p $HOME/.kube root@ubuntu:~# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config root@ubuntu:~# sudo chown $(id -u):$(id -g) $HOME/.kube/config root@ubuntu:~# kubectl get pod --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-6c66ffc55b-55pd5 0/1 ContainerCreating 0 13m kube-system coredns-6c66ffc55b-bxwzn 0/1 ContainerCreating 0 13m kube-system etcd-ubuntu 1/1 Running 0 13m kube-system kube-apiserver-ubuntu 1/1 Running 0 13m kube-system kube-controller-manager-ubuntu 1/1 Running 0 13m kube-system kube-proxy-xpqdk 1/1 Running 0 13m kube-system kube-scheduler-ubuntu 1/1 Running 0 13m
"coredns-6c66ffc55b-55pd5”显示不是READY状态是因为网络插件没有加载
# kubectl describe pod coredns-6c66ffc55b-55pd5 -n kube-system ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 15m default-scheduler Successfully assigned kube-system/coredns-6c66ffc55b-55pd5 to ubuntu Warning NetworkNotReady 4s (x71 over 15m) kubelet, ubuntu network is not ready: [runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized]
master节点查看NODE状态
root@ubuntu:~# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE coredns-6c66ffc55b-l6782 1/1 Running 2 2m29s coredns-6c66ffc55b-vr7x6 1/1 Running 2 2m29s etcd-ubuntu 1/1 Running 0 105s kube-apiserver-ubuntu 1/1 Running 0 103s kube-controller-manager-ubuntu 1/1 Running 0 2m kube-proxy-jflpz 1/1 Running 0 2m29s kube-scheduler-ubuntu 1/1 Running 0 95s weave-net-sd2ld 2/2 Running 0 65s root@ubuntu:~# kubectl get nodes NAME STATUS ROLES AGE VERSION ubuntu Ready master 4m9s v1.12.1
master节点没有NODE加入的状态,而且master的系统组件也在不停的重建,查看kubelet系统(journalctl用于检索systemd日志)日志(journalctl -exu kubelet):
Oct 15 06:32:14 ubuntu kubelet[21032]: E1015 06:32:14.665343 21032 azure_dd.go:147] failed to get azure cloud in GetVolumeLimits, plugin.host: ubuntu Oct 15 06:32:14 ubuntu kubelet[21032]: W1015 06:32:14.675132 21032 kubelet.go:1622] Deleting mirror pod "etcd-ubuntu_kube-system(b88890b9-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:14 ubuntu kubelet[21032]: W1015 06:32:14.675908 21032 kubelet.go:1622] Deleting mirror pod "kube-apiserver-ubuntu_kube-system(b8a72b35-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:14 ubuntu kubelet[21032]: W1015 06:32:14.771417 21032 kubelet.go:1622] Deleting mirror pod "kube-controller-manager-ubuntu_kube-system(b906e6ad-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:15 ubuntu kubelet[21032]: W1015 06:32:15.682986 21032 kubelet.go:1622] Deleting mirror pod "kube-apiserver-ubuntu_kube-system(b9bde629-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:15 ubuntu kubelet[21032]: W1015 06:32:15.683031 21032 kubelet.go:1622] Deleting mirror pod "kube-controller-manager-ubuntu_kube-system(b906e6ad-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:15 ubuntu kubelet[21032]: W1015 06:32:15.683091 21032 kubelet.go:1622] Deleting mirror pod "kube-scheduler-ubuntu_kube-system(b9211840-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:15 ubuntu kubelet[21032]: W1015 06:32:15.683158 21032 kubelet.go:1622] Deleting mirror pod "etcd-ubuntu_kube-system(b9be1b4f-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:16 ubuntu kubelet[21032]: W1015 06:32:16.831308 21032 status_manager.go:501] Failed to update status for pod "kube-apiserver-ubuntu_kube-system(bacc5a0d-d07e-11e8-aa0c-000c29b23b73)": failed to patch status "{\"status\":{\"conditions\":[{\"lastProbeTime\":null,\"lastTransitionTime\":\"2018-10-15T13:29:34Z\",\"status\":\"True\",\"type\":\"Initialized\"},{\"lastProbeTime\":null,\"lastTransitionTime\":\"2018-10-15T13:29:36Z\",\"status\":\"True\",\"type\":\"Ready\"},{\"lastProbeTime\":null,\"lastTransitionTime\":\"2018-10-15T13:29:36Z\",\"status\":\"True\",\"type\":\"ContainersReady\"},{\"lastProbeTime\":null,\"lastTransitionTime\":\"2018-10-15T13:29:34Z\",\"status\":\"True\",\"type\":\"PodScheduled\"}],\"containerStatuses\":[{\"containerID\":\"docker://232c447bf98969bc21e01e41bcf2a3c70f96dbb12cd91beeb5e618b31eee46ff\",\"image\":\"k8s.gcr.io/kube-apiserver:v1.12.1\",\"imageID\":\"docker-pullable://registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver@sha256:0a45517b1eeab5bd036f9ecd24e33ccd1e62542d3899cea917ab55248dc2a7d6\",\"lastState\":{},\"name\":\"kube-apiserver\",\"ready\":true,\"restartCount\":0,\"state\":{\"running\":{\"startedAt\":\"2018-10-15T13:29:35Z\"}}}],\"hostIP\":\"192.168.52.135\",\"phase\":\"Running\",\"podIP\":\"192.168.52.134\",\"startTime\":\"2018-10-15T13:29:34Z\"}}" for pod "kube-system"/"kube-apiserver-ubuntu": pods "kube-apiserver-ubuntu" not found Oct 15 06:32:17 ubuntu kubelet[21032]: W1015 06:32:17.692972 21032 kubelet.go:1622] Deleting mirror pod "kube-controller-manager-ubuntu_kube-system(baadf46e-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:18 ubuntu kubelet[21032]: W1015 06:32:18.698033 21032 kubelet.go:1622] Deleting mirror pod "kube-scheduler-ubuntu_kube-system(bbfd837e-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:18 ubuntu kubelet[21032]: W1015 06:32:18.698169 21032 kubelet.go:1622] Deleting mirror pod "etcd-ubuntu_kube-system(bc1c04fa-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:18 ubuntu kubelet[21032]: W1015 06:32:18.698250 21032 kubelet.go:1622] Deleting mirror pod "kube-apiserver-ubuntu_kube-system(bbc082ee-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:20 ubuntu kubelet[21032]: W1015 06:32:20.008839 21032 kubelet.go:1622] Deleting mirror pod "kube-controller-manager-ubuntu_kube-system(bc961a05-d07e-11e8-aa0c-000c29b23b73)" because it is outdated Oct 15 06:32:20 ubuntu kubelet[21032]: W1015 06:32:20.737155 21032 kubelet.go:1622] Deleting mirror pod "etcd-ubuntu_kube-system(bc1c04fa-d07e-11e8-aa0c-000c29b23b73)" because it is outdated
发现kubelet的系统组件一直再重新创建,提示重建原因是组件过时。。。因为masterr和node节点的节点名字相同导致的问题,修改master节点主机名为master,node节点主机名为node-1解决:
/etc/hostname:修改主机名 /etc/hosts:修改主机命映射文件
修改完成后重新加入NODE节点到master节点,node和master都显示Ready表示成功
root@master:~# kubectl get pod --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE kube-system coredns-6c66ffc55b-6ljpk 1/1 Running 0 109s 10.32.0.4 master <none> kube-system coredns-6c66ffc55b-df85w 1/1 Running 0 2m3s 10.32.0.3 master <none> kube-system etcd-master 1/1 Running 0 3m22s 192.168.52.134 master <none> kube-system kube-apiserver-master 1/1 Running 0 3m49s 192.168.52.134 master <none> kube-system kube-controller-manager-master 1/1 Running 0 3m22s 192.168.52.134 master <none> kube-system kube-proxy-48wxn 1/1 Running 0 4m12s 192.168.52.134 master <none> kube-system kube-proxy-6g6m6 1/1 Running 0 77s 192.168.52.135 node-1 <none> kube-system kube-scheduler-master 1/1 Running 0 3m33s 192.168.52.134 master <none> kube-system weave-net-qfqdm 2/2 Running 1 77s 192.168.52.135 node-1 <none> kube-system weave-net-x9mxl 2/2 Running 0 4m5s 192.168.52.134 master <none> root@master:~# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready master 4m35s v1.12.1 node-1 Ready <none> 79s v1.12.1
kubelet启动失败
[root@develop ~]# systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: active (running) since Fri 2019-02-01 00:40:39 CST; 11s ago Docs: https://kubernetes.io/docs/ Main PID: 25128 (kubelet) Tasks: 59 CGroup: /system.slice/kubelet.service └─25128 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --cgroup-driver=sys... Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.063238 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.150205 25128 reflector.go:134] k8s.io/kubernetes/pkg/kubelet/kubelet.go:444: Failed to list *v1.Service: Get https://10.66.240....ction refused Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.163434 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.263638 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.363840 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.464061 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.551324 25128 reflector.go:134] k8s.io/kubernetes/pkg/kubelet/config/apiserver.go:47: Failed to list *v1.Pod: Get https://10.66....ction refused Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.564244 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.664408 25128 kubelet.go:2266] node "develop" not found Feb 01 00:40:51 develop kubelet[25128]: E0131 16:40:51.764609 25128 kubelet.go:2266] node "develop" not found Hint: Some lines were ellipsized, use -l to show in full.
提示develop没有找到,查看docker启动状态
[root@develop ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e91ac8b06cde b9027a78d94c "kube-controller-m..." About a minute ago Exited (1) 59 seconds ago k8s_kube-controller-manager_kube-controller-manager-develop_kube-system_450c90d90ecdd385f4dd73c165741a85_4 2b1278b4cb30 3cab8e1b9802 "etcd --advertise-..." About a minute ago Exited (1) About a minute ago k8s_etcd_etcd-develop_kube-system_cb6a672b3cc07b22cb17e78fcb4402f2_4 89911daa6631 177db4b8e93a "kube-apiserver --..." About a minute ago Exited (1) About a minute ago k8s_kube-apiserver_kube-apiserver-develop_kube-system_e3baede458ce45b952471adb98fe1a09_4 87e350205cce 3193be46e0b3 "kube-scheduler --..." 2 minutes ago Up 2 minutes k8s_kube-scheduler_kube-scheduler-develop_kube-system_15771bb86175c846e989776d98b76eb2_0 34719c83c53b registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 2 minutes ago Up 2 minutes k8s_POD_etcd-develop_kube-system_cb6a672b3cc07b22cb17e78fcb4402f2_0 f58abe8eb5f7 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-scheduler-develop_kube-system_15771bb86175c846e989776d98b76eb2_0 3e810e0b9d56 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-controller-manager-develop_kube-system_450c90d90ecdd385f4dd73c165741a85_0 157ca028b209 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-apiserver-develop_kube-system_e3baede458ce45b952471adb98fe1a09_0
有三个容器都没有启动,继续分析启动失败原因:
[root@develop ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 54fb1c4e2505 b9027a78d94c "kube-controller-m..." 38 seconds ago Exited (1) 36 seconds ago k8s_kube-controller-manager_kube-controller-manager-develop_kube-system_450c90d90ecdd385f4dd73c165741a85_5 954e5d43afe1 3cab8e1b9802 "etcd --advertise-..." About a minute ago Exited (1) About a minute ago k8s_etcd_etcd-develop_kube-system_cb6a672b3cc07b22cb17e78fcb4402f2_5 bb783d8d40f8 177db4b8e93a "kube-apiserver --..." About a minute ago Exited (1) About a minute ago k8s_kube-apiserver_kube-apiserver-develop_kube-system_e3baede458ce45b952471adb98fe1a09_5 87e350205cce 3193be46e0b3 "kube-scheduler --..." 3 minutes ago Up 3 minutes k8s_kube-scheduler_kube-scheduler-develop_kube-system_15771bb86175c846e989776d98b76eb2_0 34719c83c53b registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 3 minutes ago Up 3 minutes k8s_POD_etcd-develop_kube-system_cb6a672b3cc07b22cb17e78fcb4402f2_0 f58abe8eb5f7 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 3 minutes ago Up 3 minutes k8s_POD_kube-scheduler-develop_kube-system_15771bb86175c846e989776d98b76eb2_0 3e810e0b9d56 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 3 minutes ago Up 3 minutes k8s_POD_kube-controller-manager-develop_kube-system_450c90d90ecdd385f4dd73c165741a85_0 157ca028b209 registry.aliyuncs.com/google_containers/pause:3.1 "/pause" 3 minutes ago Up 3 minutes k8s_POD_kube-apiserver-develop_kube-system_e3baede458ce45b952471adb98fe1a09_0 [root@develop ~]# [root@develop ~]# docker logs 54fb1c4e2505 Flag --address has been deprecated, see --bind-address instead. I0131 16:43:57.905073 1 serving.go:318] Generated self-signed cert in-memory unable to load client CA file: unable to load client CA file: open /etc/kubernetes/pki/ca.crt: permission denied
都是因为/etc/kubernetes/pki/目录没有权限导致启动失败,查看很多资料。。。发现是因为selinux没有关闭导致的。。
[root@develop ~]# setenforce 0 //临时关闭 [root@develop ~]# getenforce Permissive [root@develop ~]# vim /etc/sysconfig/selinux //永久关闭 将SELINUX=enforcing 改为 SELINUX=disabled 。
踩雷区
安装赛程中出现ebtables or some similar executable not found
在执行kubeadm init中出现以下警告
[preflight] WARNING: ebtables not found in system path [preflight] WARNING: ethtool not found in system path
这可能是因为你的操作系统里没有安装ebtables, ethtool,可以执行以下命令安装
对于ubuntu/debian用户,执行apt install ebtables ethtool
对于centos/Fedora用户,执行yum install ebtables ethtool
执行kubeadm init时挂起waiting for the control plane to become ready
如题,在执行kubeadm init后,等到出现下面内容后命令一直挂起
[apiclient] Created API client, waiting for the control plane to become ready
这可能是由多种原因引起的,最为常见的如下:
网络连接问题.请排查网络连接是否正常.
kubelet 使用的默认的cgroup driver和docker使用的不一样,通过查看(/var/log/messages)或者执行journalctl -u kubelet看看是否有以下错误信息:
error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "systemd" is different from docker cgroup driver: "cgroupfs"
如果是这样,可以尝试重新安装docker来解决,也可以通过更改kubelet的默认配置来手动与docker匹配,详情参看这里
执行kubeadm reset时命令挂起Removing kubernetes-managed containers
sudo kubeadm reset [preflight] Running pre-flight checks [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" [reset] Removing kubernetes-managed containers (block)
这可能是由于docker中断引起的,可以通过journalctl -fu docker来查看docker的输出日志帮助排查问题.一般情况下可以尝试以下命令来解决问题
sudo systemctl restart docker.service sudo kubeadm reset
pod的状态是RunContainerError, CrashLoopBackOff 或 Error
刚刚执行过kubeadm init,不应该有pod的状态为以上中的状态之一(正常情况下都应该是Running)
如果执行kubeadm init后出现以上状态,请到官方仓库提出问题. coredns (或者kube-dns)在部署之前状态是Pending
如果在部署了网络组件(coredns或者kube-dns)之后仍然会出现以上状态,这很可能是你安装的网络组件的问题,你可以对它授予更高的RBAC权限或者安装更新的版本
解决主机重启后kubelet无法自动启动问题
问题描述

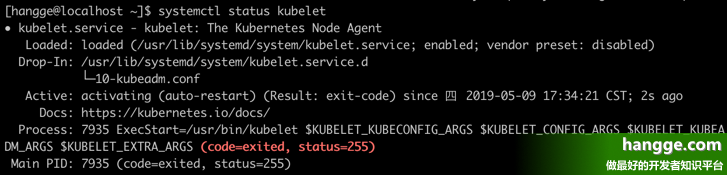
问题原因
解决办法
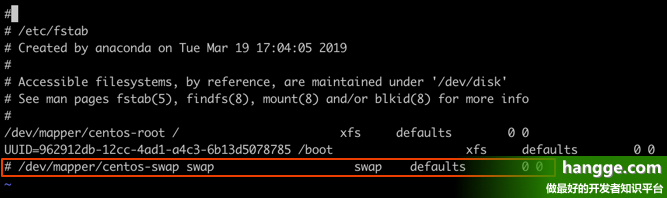
vi /etc/fstab
将 /dev/mapper/centos-swap swap swap default 0 0 这一行前面加个 # 号将其注释掉。
排错技巧
作者:索伦x 来源:简书
链接:https://www.jianshu.com/p/9d52a32f648d
- 查看日志 kubectl logs pod-name
- 查看事件 kubectl describe pod-name
- 查看docker日志
通过kubectl get pod -o wide找到容器运行的node节点
在node节点上通过docker ps -a找到出错的容器
docker logs container-id - 查看kubelet及其他组件日志:journalctl -u kubelet
参考:
- https://codyjava.iteye.com/blog/2435846
- http://dockone.io/question/1350
- kubeadm安装Kubernetes 1.14最佳实践
- Docker中的Cgroup Driver:Cgroupfs 与 Systemd
- Ubuntu16.04搭建Kubernetes
- Flannel介绍
- k8s 官方文档
- 让你的 k8s 使用更简单
- k8s 基本使用
- k8s 如何让你的应用活的更久

 浙公网安备 33010602011771号
浙公网安备 33010602011771号