
Flume入门
简介
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。 它具有基于流数据流的简单灵活的架构。 它具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错能力。 它使用简单的可扩展数据模型,允许在线分析应用程序。本文讲述如何使用Flume搜集Nginx的日志,并给出了几个使用示例
1.运行机制
Flume 的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。 Flume 分布式系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。flume 采集系统就是由一个个 agent 所连接起来形成。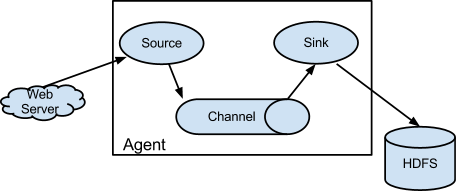
每一个 agent 相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据;
- Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据或者往最终存储系统传递数据;
- Channel:agent 内部的数据传输通道,用于从 source 将数据传递到 sink;在整个数据的传输的过程中,流动的是 event,它是 Flume 内部数据传输的最基本单元。event 将传输的数据进行封装。如果是文本文件,通常是一行记录,event 也是事务的基本单位。event 从 source,流向 channel,再到 sink,本身为一个字节数组,并可携带headers(头信息)信息。event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。 一个完整的 event 包括:event headers、event body、event 信息,其中event 信息就是 flume 收集到的日记记录。
Flume 安装部署
下载地址:https://flume.apache.org/download.html
部署Flume
安装jdk8
sudo apt-get update sudo apt-get install openjdk-8-jdk-headless
配置java环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 export JRE_HOME=$JAVA_HOME/jre export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
在Path后面加入解压后的路径
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /opt/
Kafka外网连接
0.8版本有两个配置参数需要修改:
advertised.host.name=192.168.1.13 #<==kafka开放到外网的IP(本地IP地址) advertised.port=9092 #<==9092映射到外网后的端口
最新版本0.10.x broker配置弃用了advertised.host.name 和 advertised.port 这两个个配置项,就配置advertised.listeners就可以了:
advertised.listeners=PLAINTEST://192.168.1.13:9092 # 本地IP地址:端口
需要知晓这些参数的同学可以参考:kafka配置文件详解
2.2.3.实例1:采集Nginx的日志在控制台显示
在根目录的conf下新建nginx-logger.conf文件,文件内容如下:
# 定义一个名为a1的agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置 source 组件:r1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/soft/nginx-1.14.0/logs/access.log # 描述和配置 sink 组件:k1 a1.sinks.k1.type = logger # 描述和配置 channel 组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置 source、channel、sink 之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
这里我们定义了一个source监听access.log文件的变化,并将采集到的日志文件打印在控制台
2.2.4.启动Flume
./bin/flume-ng agent -n a1 -c conf -f conf/nginx-logger.conf -Dflume.root.logger=INFO,console
-a a1 指定 agent 的名字
-c conf 指定配置文件目录
-f conf/nginx-logger.conf 指定配置文件
访问Nginx测试

2.2.4.实例2:采集到kafka
# 定义一个名为a1的agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置 source 组件:r1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/soft/nginx-1.14.0/logs/access.log # 描述和配置 sink 组件:k1 #设置Kafka接收器 a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink #设置Kafka的broker地址和端口号 a1.sinks.k1.brokerList=127.0.0.1:9092, 127.0.0.1:9092, 127.0.0.1:9092 #设置Kafka的Topic a1.sinks.k1.topic=App #设置序列化方式 a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder # 描述和配置 channel 组件:c1,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置 source、channel、sink 之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.2.5.实例3:采集到HDFS
切分日志脚本
# /bin/bash _prefix="/opt/soft/nginx-1.14.0" time=`date +%Y%m%d%H` mv ${_prefix}/logs/access.log ${_prefix}/logs/flume/access-${time}.log kill -USR1 `cat ${_prefix}/logs/nginx.pid`
定时切分日志,每个小时的59分切分日志
# 编辑crontab文件 vi /etc/crontab # 加入,每个小时的59分切分一次日志 59 * * * * root /opt/soft/nginx-1.14.0/log_spilt.sh # 重启cron服务 systemctl restart crond.service
nginx-hdfs.conf
# 定义这个 agent 中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置 source 组件:r1 ##注意:不能往监控目中重复丢同名文件 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /opt/soft/nginx-1.14.0/logs/flume a1.sources.r1.fileHeader = true # 描述和配置 channel 组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory # 默认该通道中最大的可以存储的 event 数量 a1.channels.c1.capacity = 1000 # 每次最大可以从 source 中拿到或者送到 sink 中的 event 数量 a1.channels.c1.transactionCapacity = 100 # 描述和配置 sink 组件:k1 a1.sinks.k1.channel = c1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://192.168.2.111:9000/business/%Y-%m-%d/%H-%M a1.sinks.k1.hdfs.filePrefix = logs a1.sinks.k1.hdfs.inUsePrefix = . # 默认值:30; hdfs sink 间隔多长将临时文件滚动成最终目标文件,单位:秒; 如果设置成 0,则表示不根据时间来滚动文件 a1.sinks.k1.hdfs.rollInterval = 0 # 默认值:1024; 当临时文件达到该大小(单位:bytes)时,滚动成目标文件; 如果设置成 0,则表示不根据临时文件大小来滚动文件 a1.sinks.k1.hdfs.rollSize = 16777216 # 默认值:10; 当 events 数据达到该数量时候,将临时文件滚动成目标文件; 如果设置成 0,则表示不根据 events 数据来滚动文件 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.batchSize = 1000 a1.sinks.k1.hdfs.writeFormat = text # 生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本 a1.sinks.k1.hdfs.fileType = DataStream # 操作 hdfs 超时时间 a1.sinks.k1.callTimeout =10000 a1.sinks.k1.hdfs.useLocalTimeStamp = true # 描述和配置 source channel sink 之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.2.6.实例4:flume-flume-kafka
flume1
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/soft/nginx-1.14.0/logs/access.log # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = 0.0.0.0 a1.sinks.k1.port = 41414 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
flume2
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port =41414 # Describe the sink #设置Kafka接收器 a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink #设置Kafka的broker地址和端口号 a1.sinks.k1.brokerList=127.0.0.1:9092, 127.0.0.1:9092, 127.0.0.1:9092 #设置Kafka的Topic a1.sinks.k1.topic=App #设置序列化方式 a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
作者:阿坤的博客
链接:https://www.jianshu.com/p/5c448388f48b
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号