hadoop3入门
深入浅出 Hadoop YARN:https://zhuanlan.zhihu.com/p/54192454?utm_source=qq
常用命令
统计文件系统的可用空间信息
hadoop fs -df -h /
统计文件夹的大小信息
hadoop fs -du -s -h /aaa/*
统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
设置HDFS中文件的副本数量
hadoop fs -setrep 3 /aaa/a.txt
环境准备
克隆虚拟机
Vmware左侧选中要克隆的机器,这里对原有的hadoop-master机器进行克隆,虚拟机菜单中,选中管理菜单下的克隆命令。选择“创建完整克隆”,虚拟机名称为hadoop-slave2,选择虚拟机文件保存路径,进行克隆。再次克隆一个名为hadoop-slave2的虚拟机。
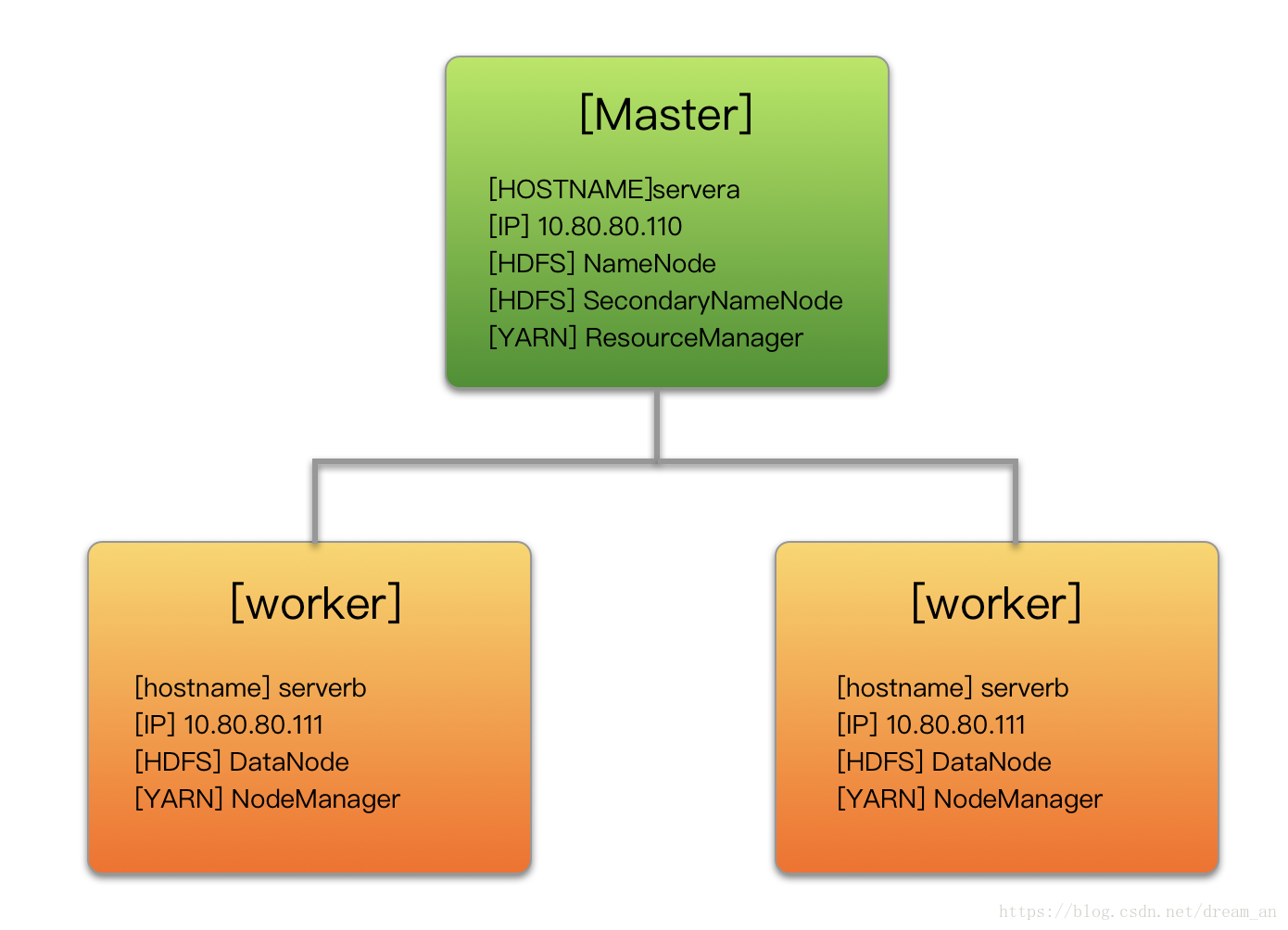
服务器功能规划
#部署完成后 root@servera:/opt/hadoop/hadoop-3.1.0# jps 14056 SecondaryNameNode 14633 Jps 13706 NameNode 14317 ResourceManager root@serverb:~# jps 5288 NodeManager 5162 DataNode 5421 Jps root@serverc:~# jps 4545 NodeManager 4371 DataNode 4678 Jps
JDK安装(每个节点同样操作)
- 下载JDK(可到甲骨文网站Oracle下载,我当时下载的是jdk-8u151-linux-x64.tar.gz(jdk8都行)
- 在jdk压缩包目录下(我的路径是/home/ubuntu/java/)解压:
tar –zxvf jdk-8u151-linux-x64.tar.gz - 配置jdk(关于Linux配置文件,可以参考:Linux配置文件说明),执行以下命令:
vim ~/.bashrc #在文件最后添加 export JAVA_HOME=/opt/jdk8 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$PATH source ~/.bashrc #刷新配置 java –version #验证,查看 java 版本
ssh免密码登录配置
2.2.1 网络环境配置
首先修改主机名和 IP 的映射关系,分别配置两台机器的hosts文件,在此之前先通过ip addr show或ifconfig命令查看两台机器(三个及三个以上节点只需添加即可)的IP地址,我的IP地址为:
2、host配置和主机名(四台)
修改四台服务器的hosts文件
vim /etc/hosts
192.168.0.71 hadoop-master 192.168.0.72 hadoop-slave1 192.168.0.73 hadoop-slave2
此时,两个节点间应该可以互相ping通
2.2.2 ssh免密登录(可以参考我之前博客)
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的
SSH是无密码登录的。
1、 在 hadoop01上生成公钥
ssh-keygen -t rsa
一路回车,都设置为默认值,然后再当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)。
2、 分发公钥
yum -y install openssh-server openssh-clients [hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop-master [hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop-slave1 [hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop-slave2
(3)master免密码登录worker,把各子节点的 id_rsa.pub 传到主节点
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-master ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-slave1 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-slave2
3、 设置hadoop-slave1、hadoop-slave2到其他机器的无密钥登录
同样的在hadoop-slave1、hadoop-slave2上生成公钥和私钥后,将公钥分发到三台机器上。
Hadoop的安装与配置
安装Hadoop
下载
(1)到Hadoop官网下载,我下载的是hadoop-3.0.0.tar.gz
(2)同jdk类似,在家目录下(/home/ubuntu/)创建文件夹hadoop:mkdir hadoop,然后解压:tar –zxvf hadoop-3.0.0.tar.gz
配置环境变量
执行如下命令:
vim ~/.bashrc //在文件最后添加 export HADOOP_HOME=/home/ubuntu/hadoop/hadoop-3.0.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source ~/.bashrc //刷新配置
创建文件目录
mkdir /home/ubuntu/hadoop/tmp mkdir /home/ubuntu/hadoop/dfs mkdir /home/ubuntu/hadoop/dfs/data mkdir /home/ubuntu/hadoop/dfs/name
配置Hadoop
进入hadoop-3.0.0的配置目录:cd /home/ubuntu/hadoop/hadoop-3.0.0/etc/hadoop,依次修改hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及workers文件。
配置 hadoop-env.sh
vim hadoop-env.sh
HADOOP_PID_DIR=/hadoop/pid # pid文件 HADOOP_LOG_DIR=/hadoop/logs # 日志文件 export JAVA_HOME=/opt/jdk #在hadoop-env.sh中找到 JAVA_HOME,配置成对应安装路径 export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"
配置 core-site.xml (根据自己节点进行简单修改即可)
vim core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-master:9000</value> <description>HDFS的URI,文件系统://namenode标识:端口号</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/ubuntu/hadoop/tmp</value> <description>namenode上本地的hadoop临时文件夹</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> <description>Size of read/write buffer used in SequenceFiles</description> </property> </configuration>
fs.default.name:指定NameNode的IP地址和端口号
hadoop.tmp.dir:指定hadoop数据存储的临时文件夹。
特别注意:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
配置 hdfs-site.xml
vim hdfs-site.xml
<configuration> <!-- Configurations for NameNode: --> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/ubuntu/hadoop/dfs/name</value> <description>namenode上存储hdfs名字空间元数据 </description> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count </name> <value>100</value> </property> <!-- Configurations for DataNode: --> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/ubuntu/hadoop/dfs/data</value> <description>datanode上数据块的物理存储位置</description> </property> <property> <name>dfs.replication</name> <value>2</value> <description>Hadoop的备份系数是指每个block在hadoop集群中有几份,系数越高,冗余性越好,占用存储也越多</description> </property> <!-- Configurations for namenode secondary --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop-master:50090</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> <description>dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true</description> </property> </configuration>
dfs.replication:指定HDFS的备份因子为3
dfs.name.dir:指定namenode节点的文件存储目录
dfs.data.dir:指定datanode节点的文件存储目录
配置 mapred-site.xml
vim mapred-site.xml注:之前版本需要cp mapred-site.xml.template mapred-site.xml,hadoop-3.0.0直接是mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.</description> <final>true</final> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>hadoop-master:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-master:19888</value> </property> <property> <name>mapred.job.tracker</name> <value>http://hadoop-master:9001</value> </property> </configuration>
配置 yarn-site.xml
vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> <description>The hostname of the RM.</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>hadoop-master:8032</value> <description>${yarn.resourcemanager.hostname}:8032</description> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop-master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop-master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoop-master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop-master:8088</value> </property> </configuration>
配置 workers 文件(之前版本是slaves,注意查看)
vi /opt/hadoop/etc/hadoop/workers ## 内容 hadoop-slave1 hadoop-slave2
分发Hadoop文件
1、 首先在其他两台机器上创建存放Hadoop的目录
[root@hadoop-slave1 ~]# mkdir /opt/hadoop [root@hadoop-slave2 ~]# mkdir /opt/hadoop
2、 通过Scp分发
Hadoop根目录下的share/doc目录是存放的hadoop的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。
doc目录大小有1.6G。
[root@hadoop-slave1 ]# scp -r /opt/hadoop/ hadoop-slave1:/opt/hadoop [root@hadoop-slave2 ]# scp -r /opt/hadoop/ hadoop-slave2:/opt/hadoop
五、格式NameNode
在NameNode机器上执行格式化:
[root@hadoop-master ]# /opt/hadoop/bin/hdfs namenode –format
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
<property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property>
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
链接:https://www.jianshu.com/p/230ddb791fda
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
六、启动集群
1、 启动HDFS
[root@hadoop-master]# /opt/hadoop/sbin/start-dfs.sh
enter image description here
2、 启动YARN
[root@hadoo-master]# /opt/hadoop/sbin/start-yarn.sh
在hadoop04上启动ResourceManager:
[root@hadoop-master]# sbin/yarn-daemon.sh start resourcemanager
3、 启动日志服务器
因为我们规划的是在hadoop04服务器上运行MapReduce日志服务,所以要在hadoop04上启动。
[root@hadoop-master ~]# /opt/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
[root@hadoop-master ~]# jps 3570 Jps 3537 JobHistoryServer 3310 SecondaryNameNode 3213 DataNode 3392 NodeManager
4、 查看HDFS Web页面
http://hadoop01.chybinmy.com:50070/
5、 查看YARN Web 页面
http://hadoop03:8088/cluster
七、测试Job
我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
1、 准备mapreduce输入文件wc.input
[root@hadoop-master ]# cat /opt/data/wc.input hadoop mapreduce hive hbase spark storm sqoop hadoop hive spark hadoop
2、 在HDFS创建输入目录input
[root@hadoop-master]# bin/hdfs dfs -mkdir /input
3、 将wc.input上传到HDFS
[root@hadoop-master]# bin/hdfs dfs -put /opt/data/wc.input /input/wc.input
4、 运行hadoop自带的mapreduce Demo
[root@hadoop-master]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output
5、 查看输出文件
[root@hadoop-master]# bin/hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 hadoop supergroup 0 2016-07-14 16:36 /output/_SUCCESS -rw-r--r-- 3 hadoop supergroup 60 2016-07-14 16:36 /output/part-r-00000
链接:https://www.jianshu.com/p/230ddb791fda
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
3、使用jps命令查看运行情况

4、命令查看Hadoop集群的状态
通过简单的jps命令虽然可以查看HDFS文件管理系统、MapReduce服务是否启动成功,但是无法查看到Hadoop整个集群的运行状态。我们可以通过hadoop dfsadmin -report进行查看。用该命令可以快速定位出哪些节点挂掉了,HDFS的容量以及使用了多少,以及每个节点的硬盘使用情况。
hadoop dfsadmin -report
输出结果:
Configured Capacity: 50108030976 (46.67 GB) Present Capacity: 41877471232 (39.00 GB) DFS Remaining: 41877385216 (39.00 GB) DFS Used: 86016 (84 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ......
5、hadoop 重启
sbin/stop-all.sh sbin/start-all.sh
查看集群是否成功启动
9870端口查看(这里是9870,不是50070了)
在浏览器输入10.10.10.12:9870,结果如下:

测试YARN
在浏览器输入10.10.10.12:8088,结果如下:

注:将绑定IP或mpi-1改为0.0.0.0,而不是本地回环IP,这样,就能够实现外网访问本机的8088端口了。比如这里需要将yarn-site.xml中的
<property> <name>yarn.resourcemanager.webapp.address</name> <value>mpi-1:8088</value> </property>
修改为:
<property> <name>yarn.resourcemanager.webapp.address</name> <value>0.0.0.0:8088</value> </property>
另外,可以直接参考Hadoop官网的默认配置文件进行修改,比如hdfs-site.xml文件,里面有详细的参数说明。另外可以使用hdfs dfs命令,比如hdfs dfs -ls /进行存储目录的查看。
问题汇总
xxx: Error: JAVA_HOME is not set and could not be found
这个错误意思没有找到jdk的环境变量,需要在hadoop-env.sh配置。
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
## 配置项
export JAVA_HOME=/usr/lib/jvm/jre-1.7.0-openjdk.x86_64
The authenticity of host ‘0.0.0.0 (0.0.0.0)’ can’t be established.
解决方案关闭SELINUX
-- 关闭SELINUX
# vim /etc/selinux/config
-- 注释掉
#SELINUX=enforcing
#SELINUXTYPE=targeted
— 添加
SELINUX=disabled
Datanode无法启动
多次执行./hadoop namenode -format命令,导致出错
删除hadoop-master , hadoop-slave1 , hadoop-slave2下/hadoop/文件下的所有文件,重新执行
/hadoop namenode -format
hadoop系统重启过后,namenode不能启动问题
参考地址:https://blog.csdn.net/whiteblacksheep/article/details/94722734
方案一:将namenode重新格式化(生产上不建议使用,因为此操作会把NameNode所有数据删除)
$ bin/hdfs namenode -format
方案二:修改配置文件core-site.xml,添加hadoop.tmp.dir属性:把存放目重新定定义到不会被删除的地方
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.7.7/data</value> </property> </configuration>
参考地址
- http://www.ityouknow.com/hadoop/2017/07/24/hadoop-cluster-setup.html
- https://www.jianshu.com/p/230ddb791fda
- 作者:威成天下 来源:CSDN
- 原文:https://blog.csdn.net/secyb/article/details/80170804
- 作者:王小雷-多面手 来源:CSDN
- 原文:https://blog.csdn.net/dream_an/article/details/80258283
- github配置文件源码地址: https://github.com/vbay/CSDN-CODE/tree/master/Hadoop-3.1.0-Fully-Distributed-Operation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号