C++ - 多线程之线程同步
一、线程为什么要同步
线程同步的目的是为了防止多个线程同时访问共享资源时出现数据竞争和不一致的情况。
线程间为什么需要同步?直接来看一个例子:
#include <iostream>
#include <time.h>
#include <thread>
using namespace std;
int a = 0;//全局共享变量
void foo()
{
for (int i = 0; i < 10000000; ++i)
{
a += 1;
}
}
int main()
{
clock_t start, end;
start = clock();
thread t1(foo);
thread t2(foo);
t1.join();
t2.join();
end = clock();
cout << a << endl;
cout << end - start << endl;
system("pause");
return 0;
}代码很简单,创建两个线程执行foo函数,foo函数的功能是对全局变量a进行自增,我们所预期的答案是20000000。但是实际运行结果却几乎不可能得到这个值,运行结果如下:
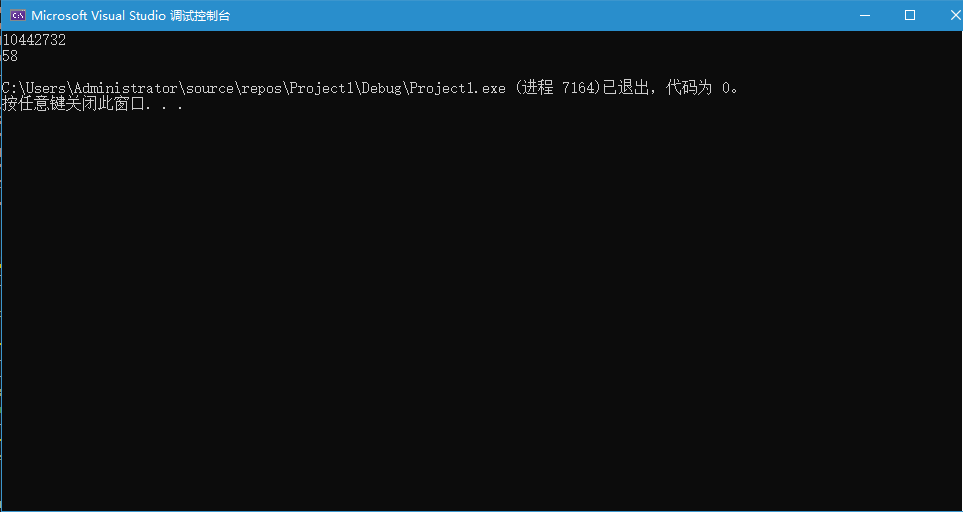
a的最终结果为10442732,共使用了58毫秒的时间。在两个线程对a进行自增的过程中可能会因为线程调度的问题使得最终结果并不正确。比如当前a的值为1,线程x现在将a的值读到寄存器中,而线程y也将a读到寄存器中,完成了自增并将新的值放入内存中,现在a的值为2,而线程x现在也对寄存器中的值进行自增,并将得到的结果放入内存中,a的值为2。可以看到两个线程都对a进行了自增,但是却得到的错误的结果。
这种情况便需要对线程间进行同步。
二、C++11线程同步方式
C++11引入了多线程支持,所以线程同步机制应该包括标准库中的一些工具。比如,互斥量、条件变量、future和promise,原子操作这些应该都是的。
1、std::mutex(互斥锁)
mutex _mutex;
_mutex.lock();//加锁
_mutex.unlock();//解锁
_mutex.try_lock();//尝试加锁,成功返回bool,失败返回false不阻塞包含mutex头文件后,就可以使用mutex类。相比起unix风格(接口名字复杂,且需要初始化互斥锁)要方便不少。
现在使用互斥锁来实现两个线程对同一变量自增的功能:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
int a = 0;
mutex _mutex;//互斥锁
void foo()
{
for (int i = 0; i < 10000000; ++i)
{
_mutex.lock();
a += 1;
_mutex.unlock();
}
}
int main()
{
clock_t start, end;
start = clock();
thread t1(foo);
thread t2(foo);
t1.join();
t2.join();
end = clock();
cout << a << endl;
cout << end - start << endl;
return 0;
}只有获得锁之后才能对数据a进行操作,运行结果如下:

2、std::recursive_mutex(递归锁)
class RecursiveCounter {
private:
std::recursive_mutex m_mutex;
int m_value = 0;
public:
void increment() {
std::lock_guard<std::recursive_mutex> lock(m_mutex);
m_value++;
}
// 同一个线程可以重复获取锁
void doubleIncrement() {
std::lock_guard<std::recursive_mutex> lock(m_mutex);
increment(); // 不会死锁!
m_value++;
}
};
3、std::timed_mutex(超时锁)
std::timed_mutex g_timed_mutex;
void tryLockWithTimeout() {
// 尝试获取锁,最多等待100ms
if (g_timed_mutex.try_lock_for(std::chrono::milliseconds(100))) {
std::lock_guard<std::timed_mutex> lock(g_timed_mutex, std::adopt_lock);
// 成功获取锁,执行临界区代码
std::cout << "Lock acquired successfully!\n";
} else {
// 超时,执行替代逻辑
std::cout << "Failed to acquire lock within timeout\n";
}
}
4、std::condition_variable(条件变量)
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
condition_variable cond;
mutex _mutex;
int a = 0;
void first() {
while (true)
{
unique_lock<mutex> lck(_mutex);
while (a % 3 != 0)
cond.wait(lck);
a++;
printf("%d\n", a % 3);
cond.notify_all();
lck.unlock();
}
}
void second() {
while (true) {
unique_lock<mutex> lck(_mutex);
while (a % 3 != 1)
cond.wait(lck);
a++;
printf("%d\n", a % 3);
cond.notify_all();
}
}
void third() {
while (a < 100) {
unique_lock<mutex> lck(_mutex);
while (a % 3 != 2)
cond.wait(lck);
a++;
printf("%d\n", a % 3);
cond.notify_all();
}
}
int main()
{
thread t1(first);
thread t2(second);
thread t3(third);
getchar();
return 0;
}运行结果如下:
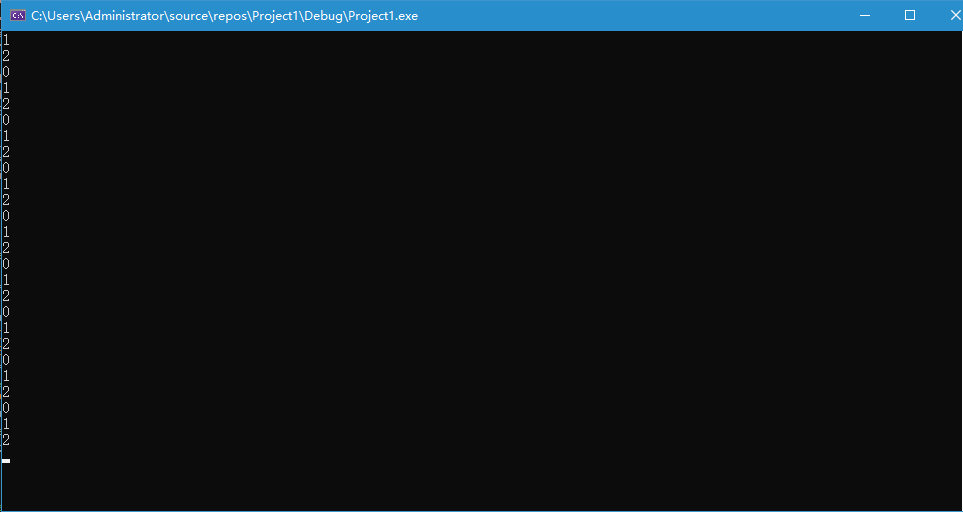
其中unique_lock是对mutex的一种RAII使用手法,来看看unique_lock的构造函数和析构函数:
explicit unique_lock(_Mutex& _Mtx)
: _Pmtx(_STD addressof(_Mtx)), _Owns(false)
{ // construct and lock
_Pmtx->lock();
_Owns = true;
}
~unique_lock() noexcept
{ // clean up
if (_Owns)
_Pmtx->unlock();
} 5、std::atomic (原子操作)
自旋锁是一种忙等形式的锁,会再用户态不同的询问锁是否可以获取,不会陷入到内核态中,所以更加高效。缺点是可能会对CPU资源造成浪费。但是在C++11中并没有直接提供自旋锁的实现。但是在C++11中提供了原子操作的实现,可以借助原子操作实现简单的自旋锁。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
atomic_flag flag;
int a = 0;
void foo()
{
for (int i = 0; i < 10000000; ++i)
{
while (flag.test_and_set())
{
}//加锁
a += 1;
flag.clear();//解锁
}
}
int main()
{
flag.clear();//初始化为clear状态
clock_t start, end;
start = clock();
thread t1(foo);
thread t2(foo);
t1.join();
t2.join();
end = clock();
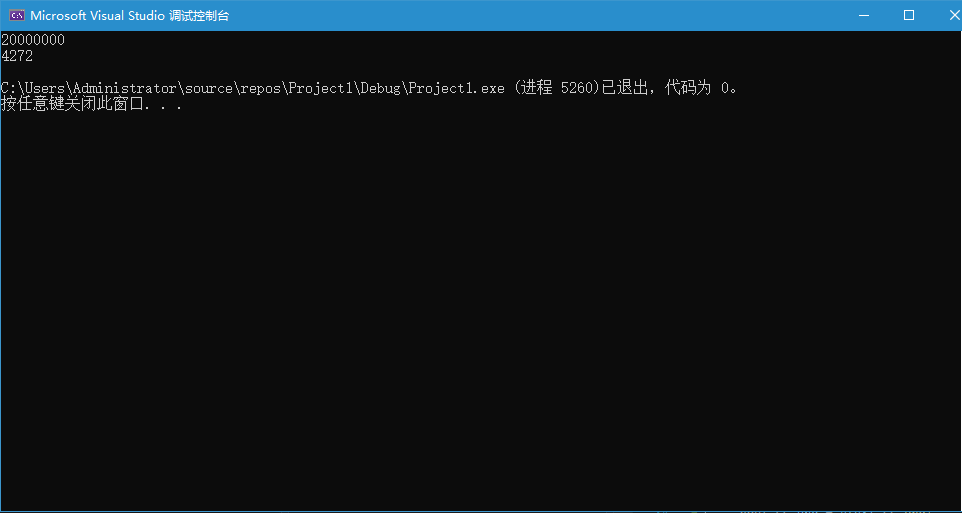
cout << a << endl;
cout << end - start << endl;
return 0;
}
- 互斥锁不会浪费CPU资源,在无法获得锁时使线程阻塞,将CPU让给其他线程使用。比如多个线程使用打印机等公共资源时,应该使用互斥锁,因为等待时间较长,不能让CPU长时间的浪费。
- 自旋锁效率更高,但是长时间的自旋可能会使CPU得不到充分的应用。在临界区代码较少,执行速度快的时候应该使用自旋锁。比如多线程使用malloc申请内存时,内部可能使用的是自旋锁,因为内存分配是一个很快速的过程。
三、总结
-
互斥量:适用于需要严格互斥访问的场景。
-
条件变量:适合线程间有条件等待的场景。
-
原子操作:轻量级同步,适合简单变量操作。
-
Future/Promise:用于异步任务的结果同步。
-
call_once:确保一次性初始化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号