LLM入门
使用:
【基于词向量和神经网络,训练文本分类模型】实现英文新闻文本分类
https://www.bilibili.com/video/BV1DNxbepEpN/
【Transformer库和BERT模型快速入门,基于BERT实现中文新闻分类】实现中文新闻分类
https://www.bilibili.com/video/BV1KT421S7K4/
看到:
-
统计学习【特征分类和数据概率分布】
-
判别式模型(分类,回归)
- CV(图像分类和图像分割,目标检测)
- NLP(文本分类,关键信息提取)
-
生成式模型
-
CV(GAN,VAE)
-
NLP(问答系统)
-
-
CV图像分类:输入图像,输出类别
NLP文本分类:输入文本,输出类别(把文本进行分词【dataloder里】,把每个词转成高维向量【回调函数里】)
魔改:
简单模型确保输出,复杂网络优化准确率
解决问题的方式:
- 基于规则(谓词逻辑)
- 基于统计(蒙特卡洛搜索)
- 多层感知机(ResNet)
- 预训练模型(BERT)
- 预训练【无监督】 加 微调【先验知识】 加 后训练【强化学习】
题目(3种类型):
-
文本分类
- CCL2025-中文电子病历ICD诊断编码评测(https://tianchi.aliyun.com/competition/entrance/532302/information)
- CCL2025-中医辨证辨病及中药处方生成评测(https://tianchi.aliyun.com/competition/entrance/532301/information)
- 医疗诊疗对话意图识别挑战赛(https://tianchi.aliyun.com/competition/entrance/532044/information)
-
信息提取
-
问答系统
文本分类:
医疗诊疗对话意图识别挑战赛
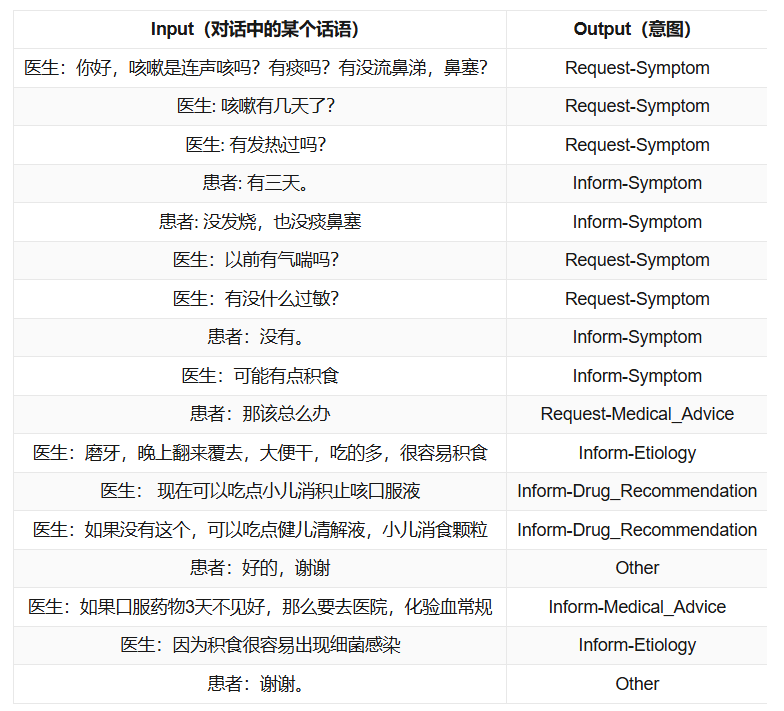
CCL2025-中文电子病历ICD诊断编码评测

CCL2025-中医辨证辨病及中药处方生成评测

策略:
-
对于单分类问题:直接套模型。
-
多分类问题
- 基于统计:由于单分类和多分类是一起输出的,所以如果只为了分数的话,可以统计每个单分类对应的多分类结果,取最高的前几个结果
- 基于多层感知机或者预训练模型(不会)
调参:
- 我们使用了两个模型,一个embedding + 线性分类层;一个BERT预训练模型 + 线性分类层。
- 在未调参的情况下
- GTX1650
- ”embedding + 线性分类层“模型,优化器lr为1e-3然后bs为32。在我的GTX1650上准确率很快收敛为1.0。在这三个任务上也分别实现了0.7273(306/337名),0.3536(56/65名),0.3458(58/77名)的成绩。可见,”embedding + 线性分类层“模型容量很小,所以在输入文本量大的时候表现很差。
- ”BERT预训练模型 + 线性分类层“模型,优化器lr为5e-5然后bs为6。跑第一个任务的时候准确率前三轮增大后几轮减小到0.3几,取准确率最大的第三轮模型得到0.7846(280/337名),后两个任务由于文本大小的增加(由一句话变成一段话)导致在我的电脑上batchsize由32减小到6才勉强训练动。
- GTX4090
- ”embedding + 线性分类层“模型容量很小,GTX1650上已经把潜能发掘到极致了。
- ”BERT预训练模型 + 线性分类层“模型,batchsize为6的时候跑这三个任务都没有太大进步(进步几名)。由于bs太小和lr太大导致模型震荡,无法发掘BERT的潜能。
- GTX1650
- 调参,bs调大lr调小
- GTX4090上,bs由6升为16,lr由5e-5降为2e-5,模型潜力得到发掘。三个任务分别实现了0.7956(271/337名),0.7125(14/65名,之前提交的时候是第9名现在被超了),0.4153(47/77名)的成绩。
- BERT模型潜力还未完全发掘,调参之路可以继续。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号