大型视觉语言模型使用_part2
AnomalyGPT
一种名为AnomalyGPT的工业异常检测方法,利用视觉大模型LVLM和提示工程零样本实现多种工业缺陷检测。
需要下载一个源码文件,四个权重文件。使用方式:直接运行./code/demo.py文件
- ImageBind 。每个输入模态都会生成一个嵌入向量,这些向量可以在同一嵌入空间中进行比较和计算。
- LLaMA+Vicuna。输入语言或者嵌入,输出语言。
- PandaGPT的Delta 权重,改Vicuna
- AnomalyGPT的Delta 权重 ,改PandaGPT
下载
源码下载链接:https://github.com/CASIA-IVA-Lab/AnomalyGPT
权重下载(README文件里有链接):下载完权重放进对应的文件夹里
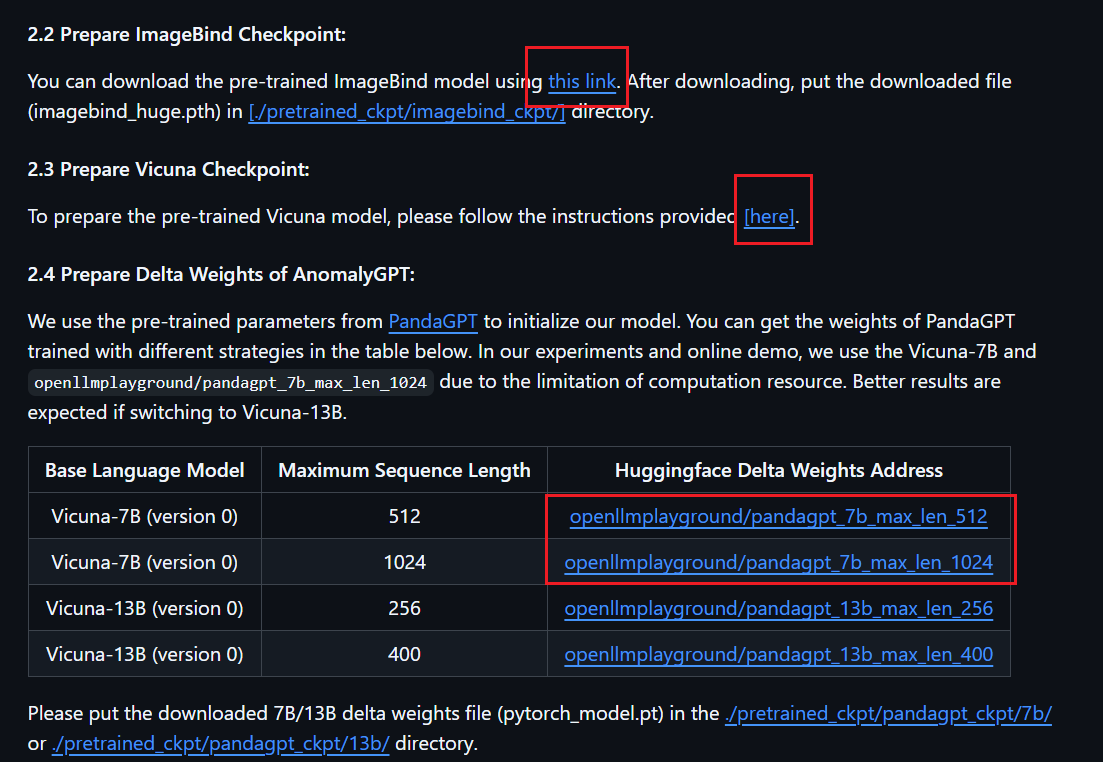
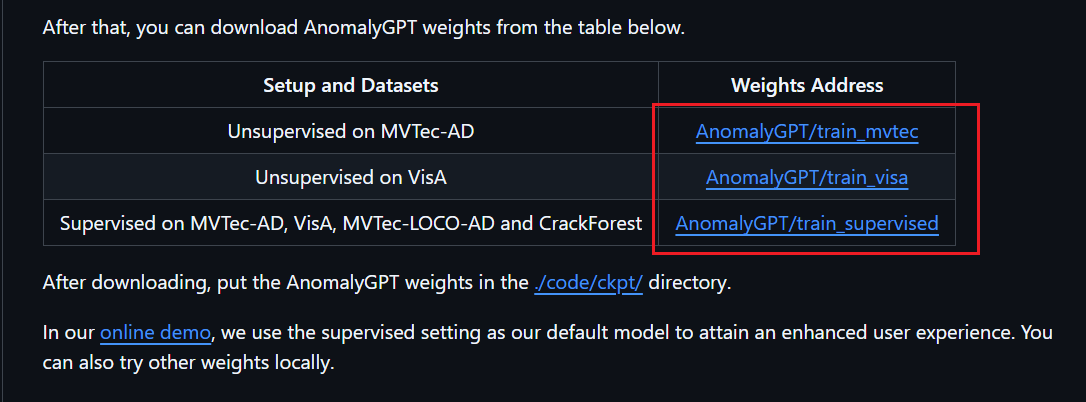
坑:
一、处理权重:LLaMA+Vicuna权重下载和合并权重
①分别下载权重(https://blog.csdn.net/lijjianqing/article/details/135408715)
他这里LLaMA权重和Vicuna权重在huggingface上有


这里说是选下面这个就能合并权重,但是实测选下面这个也合并不了
②下载总的权重(https://github.com/CASIA-IVA-Lab/AnomalyGPT/issues/111)

实测,使用这个是可以加载的。
3060爆内存了,在爆内存的同时显示“加载模型不成功”错误,不知道是不是内存足够的条件下便可以加载进去。
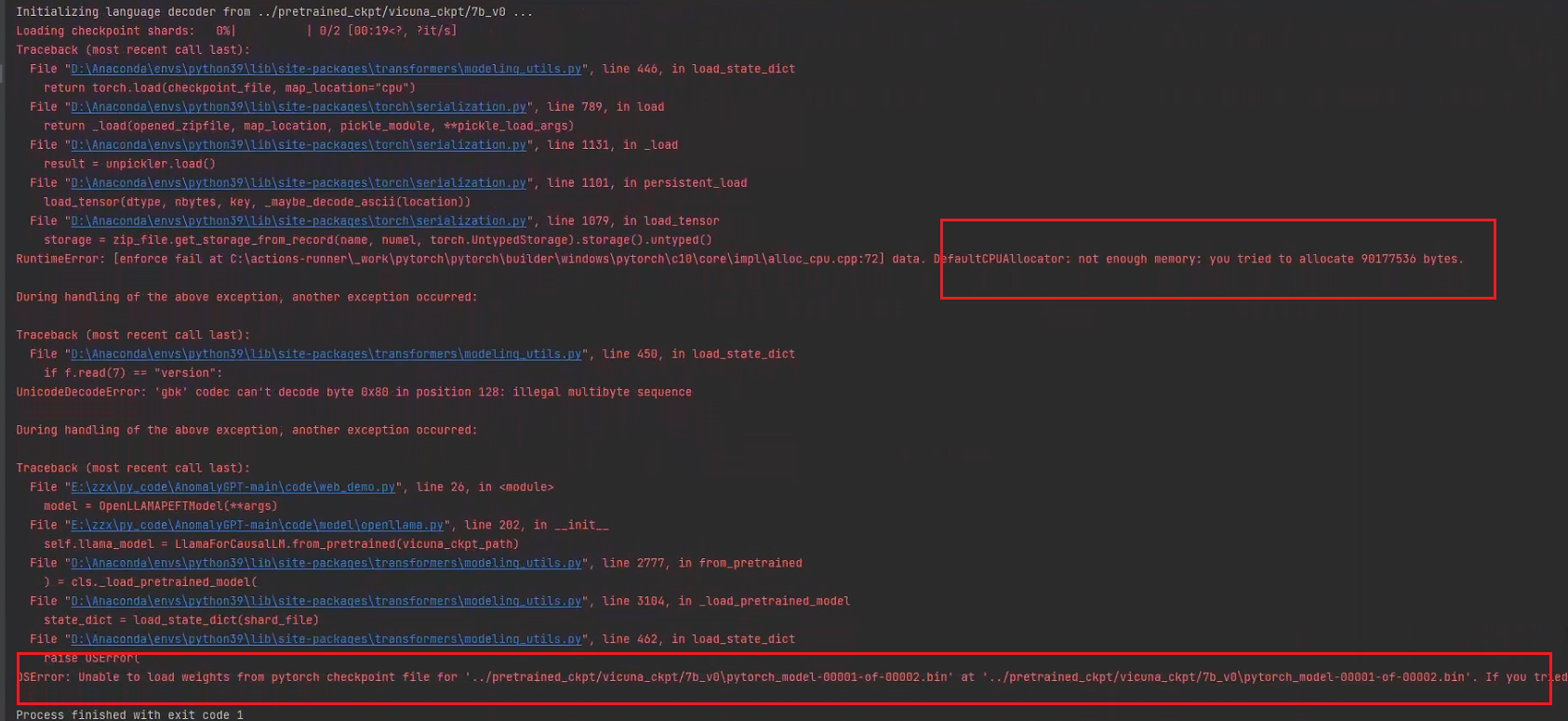
Loading checkpoint shards: 0%| | 0/2 [00:04<?, ?it/s]
Traceback (most recent call last):
File "D:\Anaconda\envs\python39\lib\site-packages\transformers\modeling_utils.py", line 446, in load_state_dict
return torch.load(checkpoint_file, map_location="cpu")
File "D:\Anaconda\envs\python39\lib\site-packages\torch\serialization.py", line 789, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "D:\Anaconda\envs\python39\lib\site-packages\torch\serialization.py", line 1131, in _load
result = unpickler.load()
File "D:\Anaconda\envs\python39\lib\site-packages\torch\serialization.py", line 1101, in persistent_load
load_tensor(dtype, nbytes, key, _maybe_decode_ascii(location))
File "D:\Anaconda\envs\python39\lib\site-packages\torch\serialization.py", line 1079, in load_tensor
storage = zip_file.get_storage_from_record(name, numel, torch.UntypedStorage).storage().untyped()
RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 90177536 bytes.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Anaconda\envs\python39\lib\site-packages\transformers\modeling_utils.py", line 450, in load_state_dict
if f.read(7) == "version":
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 128: illegal multibyte sequence
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\zzx\py_code\AnomalyGPT-main\code\web_demo.py", line 26, in <module>
model = OpenLLAMAPEFTModel(**args)
File "E:\zzx\py_code\AnomalyGPT-main\code\model\openllama.py", line 202, in __init__
self.llama_model = LlamaForCausalLM.from_pretrained(vicuna_ckpt_path)
File "D:\Anaconda\envs\python39\lib\site-packages\transformers\modeling_utils.py", line 2777, in from_pretrained
) = cls._load_pretrained_model(
File "D:\Anaconda\envs\python39\lib\site-packages\transformers\modeling_utils.py", line 3104, in _load_pretrained_model
state_dict = load_state_dict(shard_file)
File "D:\Anaconda\envs\python39\lib\site-packages\transformers\modeling_utils.py", line 462, in load_state_dict
raise OSError(
OSError: Unable to load weights from pytorch checkpoint file for '../pretrained_ckpt/vicuna_ckpt/7b_v0\pytorch_model-00001-of-00002.bin' at '../pretrained_ckpt/vicuna_ckpt/7b_v0\pytorch_model-00001-of-00002.bin'. If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
Process finished with exit code 1
kimi回答:
根据你的错误信息,问题出在加载预训练模型权重时,出现了内存不足和文件格式不匹配的问题。以下是详细的分析和解决方法:
### 问题分析
1. **内存不足**:
```
RuntimeError: [enforce fail at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 90177536 bytes.
```
这表明在加载模型权重时,系统内存不足,无法分配足够的内存来加载模型。
2. **文件格式问题**:
```
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 128: illegal multibyte sequence
```
这表明在加载模型权重文件时,文件编码格式不正确,导致解码失败。
3. **模型权重文件损坏或格式不正确**:
```
OSError: Unable to load weights from pytorch checkpoint file for '../pretrained_ckpt/vicuna_ckpt/7b_v0\pytorch_model-00001-of-00002.bin'
```
这表明模型权重文件可能损坏或格式不正确,无法正确加载。
### 解决方法
#### 方法 1:检查内存
确保你的系统有足够的内存来加载模型。如果你的系统内存不足,可以尝试以下方法:
- 关闭其他占用内存的应用程序。
- 使用具有更多内存的机器。
- 如果可能,尝试使用 GPU 加载模型,而不是仅使用 CPU。
#### 方法 2:检查文件编码
确保模型权重文件的编码格式正确。你可以尝试以下方法:
- 确保权重文件未被损坏,并且是正确的 PyTorch 格式。
- 如果权重文件是从其他地方下载的,请重新下载以确保文件完整性。
#### 方法 3:使用正确的加载方式
如果你尝试加载的是一个分片的权重文件(sharded checkpoint),确保使用正确的方式加载。例如:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"../pretrained_ckpt/vicuna_ckpt/7b_v0",
device_map="auto",
torch_dtype=torch.float16, # 或者使用 torch.bfloat16
)
```
如果权重文件是分片的,`transformers` 会自动处理分片加载。
#### 方法 4:检查模型文件路径
确保模型文件路径正确,并且权重文件未被损坏。你可以尝试以下方法:
- 确保路径中的文件名和路径分隔符正确(例如,使用正斜杠 `/` 而不是反斜杠 `\`)。
- 如果路径中有空格或特殊字符,尝试将路径放在引号中。
#### 方法 5:使用 `from_tf=True`
如果你尝试加载的是一个 TensorFlow 格式的权重文件,请确保设置 `from_tf=True`。例如:
```python
model = AutoModelForCausalLM.from_pretrained(
"../pretrained_ckpt/vicuna_ckpt/7b_v0",
from_tf=True,
device_map="auto",
torch_dtype=torch.float16,
)
```
这将确保正确加载 TensorFlow 格式的权重。
### 总结
- **检查内存**:确保系统有足够的内存来加载模型。
- **检查文件编码**:确保权重文件的编码格式正确。
- **使用正确的加载方式**:确保使用正确的方式加载分片权重文件。
- **检查模型文件路径**:确保模型文件路径正确,并且权重文件未被损坏。
- **使用 `from_tf=True`**:如果加载的是 TensorFlow 格式的权重文件,请设置 `from_tf=True`。
希望这些方法能帮助你解决问题!如果问题仍然存在,可以尝试重新下载权重文件或在新的环境中加载模型。
二、处理源码:下载python包的环境
一定要下载他requirement.txt给的pytorch版本。pytorch版本高了或者低了都会有和其他包不兼容或者和CUDA运行环境不兼容或者和代码里调用的函数不兼容。下载conda,在conda里面新建虚拟环境,每个虚拟环境相互独立(不同的项目要求的包的版本会有冲突)。pytorch下载带这种”cu121“标记的”pip install torch== 2.4.1 torchvision ==0.19.1 torchaudio == 2.4.1 --index-url https://download.pytorch.org/whl/cu121“,这种自带CUDA和CUDnn,不用担心系统CUDA版本太高。
pip install -r requirement.txt安装不了以下几个包:
实测,python3.8安装不了tokenizer这个包【tokenizers 包的某些依赖项(如 pyo3)使用了 abi3-py39 特性,这意味着它们需要 Python 3.9 或更高版本来编译】,python3.9则可以下载。
另外,tokenizer安装前需要安装rust【tokenizers 包的底层是用 Rust 编写的,需要 Rust 编译器来构建】,安装rust时windows系统需要c++环境支持。deepspeed包安装不了,但不影响使用。
fastchat包直接pip install安装不了,需要
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
git checkout v0.1.11(这里的fastchat版本不能为0.1.10,因为0.1.10没有--low-cpu-mem这个参数,无法在cpu内存小的设备上进行合并权重)
pip install -e ".[model_worker,webui]"
InternVL
InternVL 2.0 是一个多模态大型语言模型系列,具有各种大小的模型。InternVL2-8B是其中一种, 由 InternViT-300M-448px、一台 MLP 投影器(MLP projector 将 InternViT 提取的视觉特征投影到与语言模型 internlm2_5-7b-chat 相兼容的特征空间)和 internlm2_5-7b-chat组成。
模型:VIT+mlp+LLM
只需要分类的话,只需要下载这三个模型里的VIT。分类模型使用方式(红色框标注):
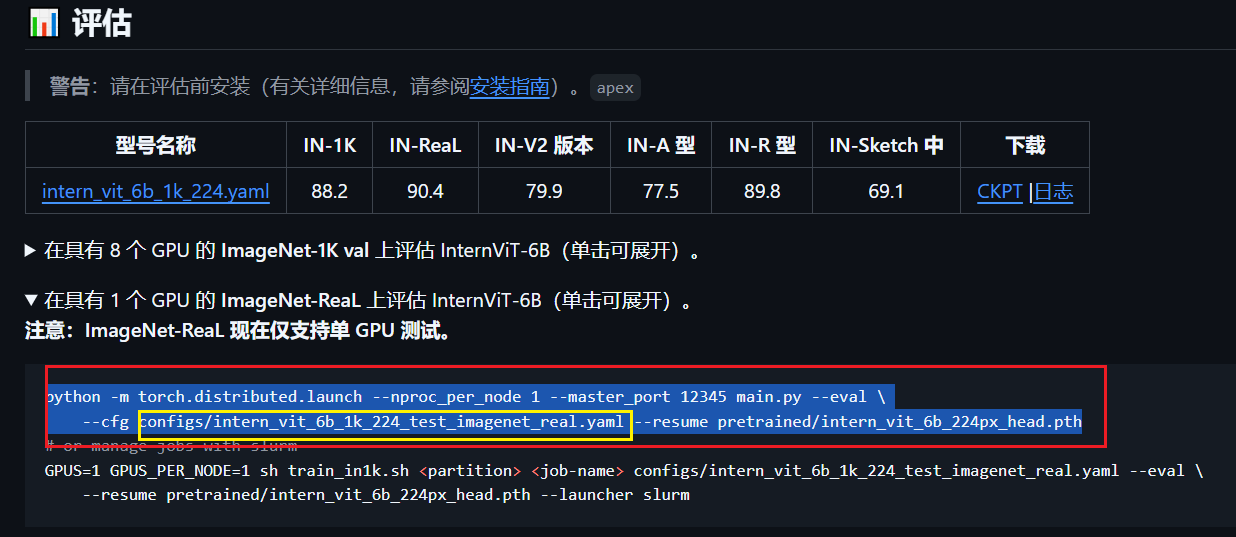
用不同的数据集,只需要改变黄色框标注的yml文件内容即可;没有web界面(可以下载openmmlab提供的网页版调用代码,调用了这种InternVL-8b或者-2b模型,然后下载”InternVL-8b“模型)
下载
源码下载链接:https://github.com/OpenGVLab/InternVL
只用到了这个文件夹
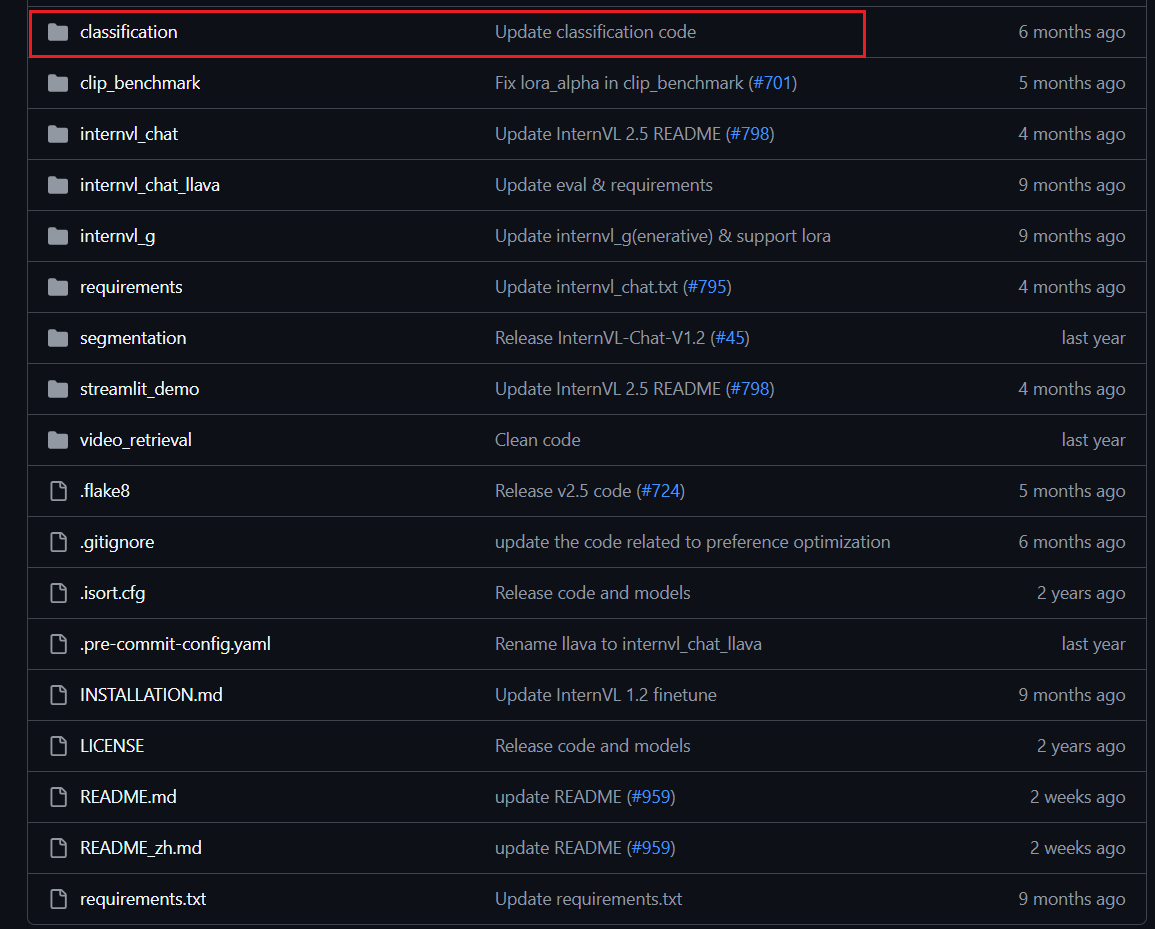
权重下载(在classification文件夹下的README.md文件里找):下载完权重放进对应的文件夹里
坑:
一、处理源码:下载python包
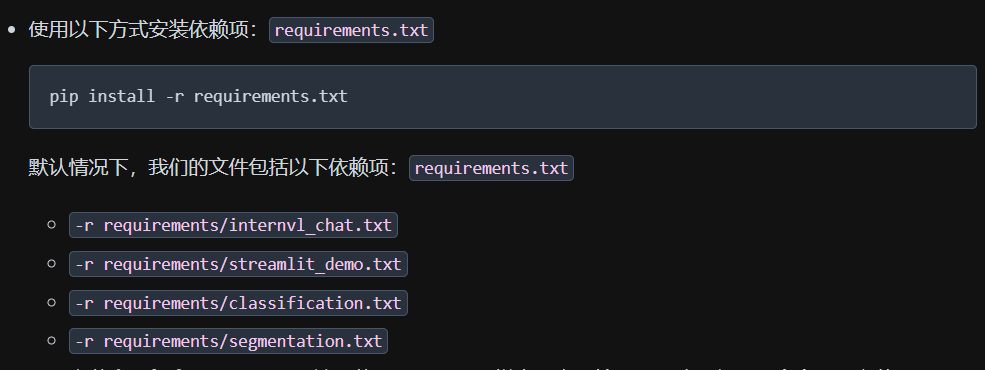
有几个包安装不了:
mmcv-full==1.6.2。环境中要求torch版本在2.0及以上,因为用到了torch2.0及以上才有的torch函数。而直接mim install mmcv-full ==1.6.2是安装不了的,需要进入mmcv官网下载(https://mmcv.readthedocs.io/zh-cn/v1.6.2/get_started/installation.html)。 mmcv1.X和mmcv2.X包的函数完全不一样,源码用的是mmcv1.X的函数,所以需要在mmcv1.X里找。mmcv1.X大多对应的pytorch1.X版本。发现适配pytorch2.0的mmcv最低版本是1.7(https://download.openmmlab.com/mmcv/dist/cu118/torch2.0/index.html)
mmcv1.X和mmcv2.X包的函数完全不一样,源码用的是mmcv1.X的函数,所以需要在mmcv1.X里找。mmcv1.X大多对应的pytorch1.X版本。发现适配pytorch2.0的mmcv最低版本是1.7(https://download.openmmlab.com/mmcv/dist/cu118/torch2.0/index.html)
flash-attn直接装装不了,后面需要加参数,“ pip install flash-attn --no-build-isolation”
二、使用main.py文件:分布式训练问题
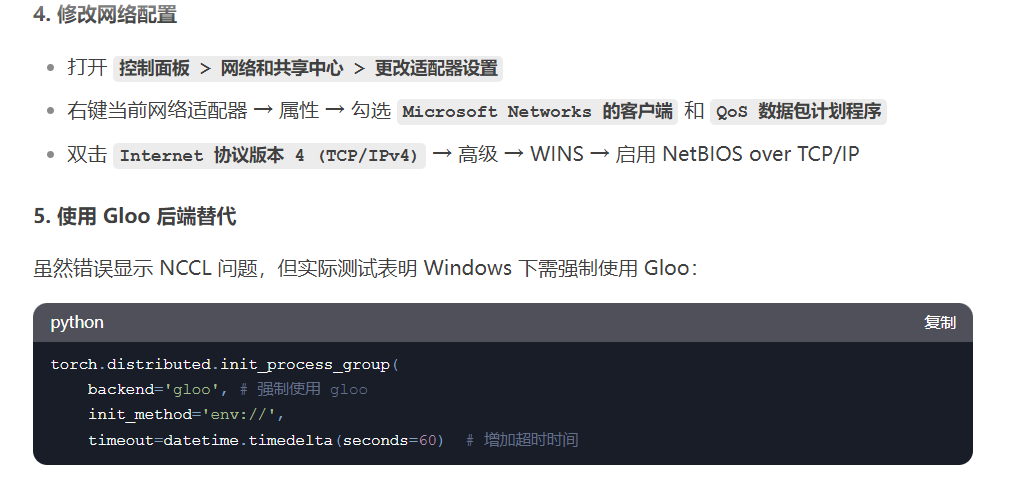
windows上需要更改网络配置和代码,否则报下面这个错误。(Linux系统不清楚)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号