

目标检测《四、 rv1109平台部署自己训练的yolov5 best.pt模型》
3. rv1109平台部署yolov5环境,官方onnx模型转换rknn模型验证
以上文章是从0到1,一点点记录部署全部过程,包括出现的错误以及解决过程。
第五篇是汇总前4篇,做一个归纳总理,顺序总结出部署过程,因为是后期总结,可能会导致哪里遗落,具体可以查看对应上面对应文章。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.在yolov5上将pt 转 onnx(window)
备注(目前这个章节使用的是yolov5 7.0版本)(后续经过验证,rv1109直接跑v7.0版本的yolov5最后在报段错误,跑V5.0就不会,可以直接参考第三点)
首先将之前训练好的best.pt放到yolov5目录下
python export.py --weights best.pt --img 640 --batch 1 --include onnx
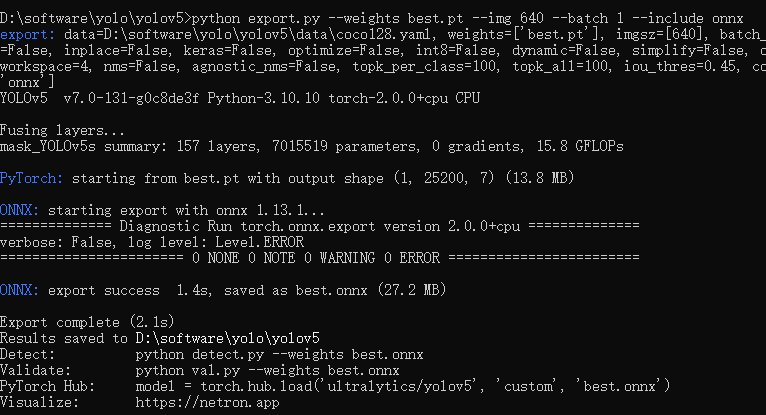
可以看到生成了best.onnx
2. 使用rknn toolkit将onnx转rknn(linux)
在rknn-toolkit工程文件夹中浏览至./examples/onnx/yolov5,将我们在2.2中转换得到的best.onnx复制到该文件夹下,修改该文件夹下的test.py中的内容为自己模型的名字,要修改的地方如下:

运行:
python test.py
提示报错:
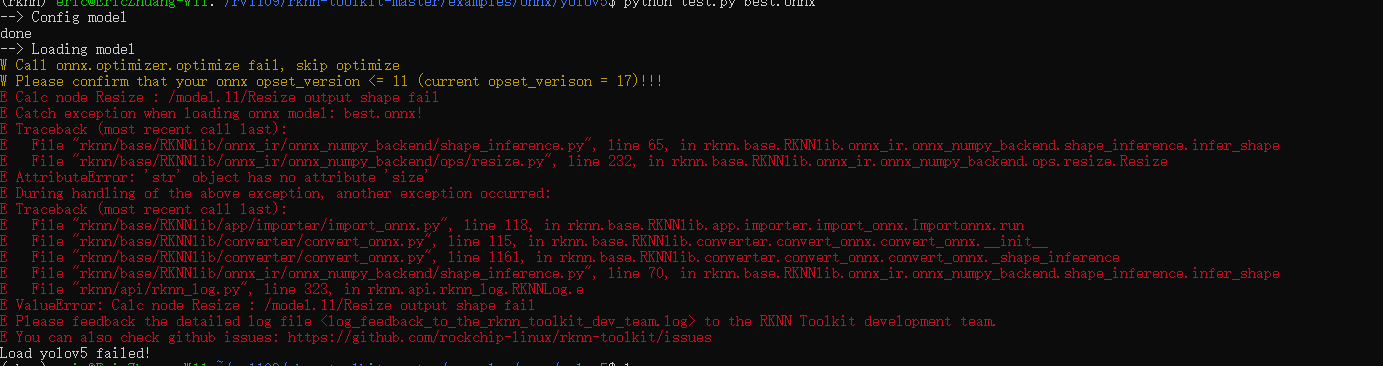
问题解决:
在通过yolov5 export出onnx的时候,修改export.py 把opset_version的值修改为12。

把转换出来的rknn放到rk1109平台运行:
报错:
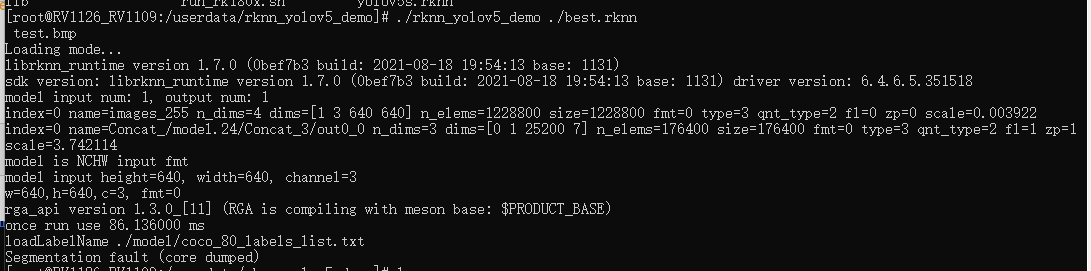
开始段错误了。好烦,不过我用的是yolov5 7.0版本。查询一下资料,好像rknn toolkit目前这1.7版本对应的是对应是yolov5 5.0。没办法,搞个5.0版本的。
3. rv1109 部署yolov5 5.0版本 pt -> onnx -> rknn
3.1 下载yolov5 5.0版本
yolov5不同版本训练得到的pt模型会决定rknn模型转换的成功与否。我之前使用yolov5 (v7.0)训练出来的pt转换rknn后,在板卡运行就一直报段错误,但是用yolov5(V5.0)就可以正常运行。
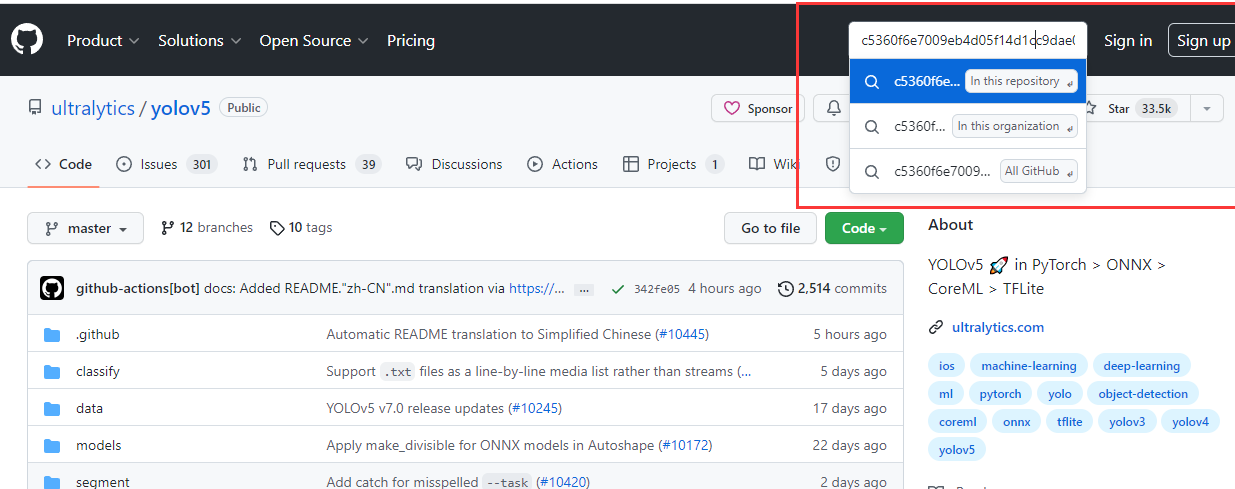
yolov5的节点id为:c5360f6e7009eb4d05f14d1cc9dae0963e949213
yolov5 git地址:https://github.com/ultralytics/yolov5
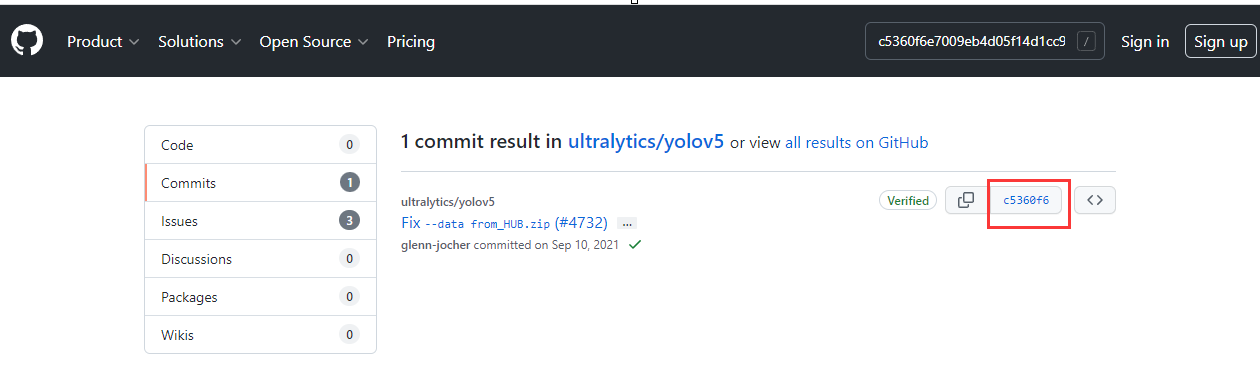
在右上角搜索这个commit id并进入“In this repository”,如图所示:
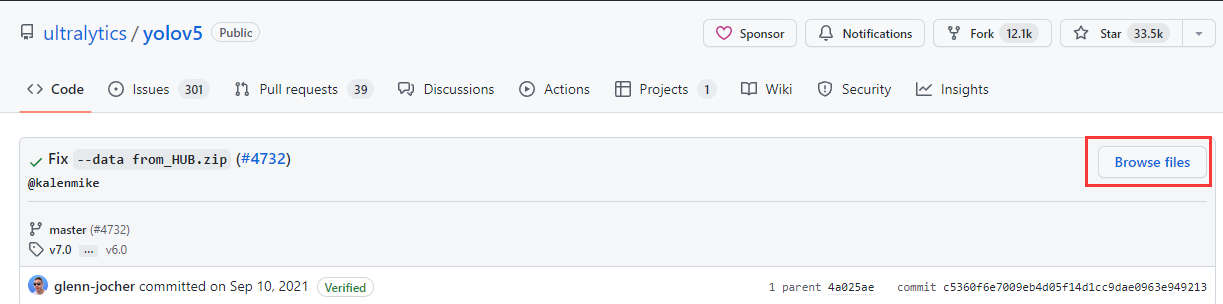
进入commits,点击右边的commit id,再次进入后点击Browse files,如下三图所示:
commit id:
Browse files:
对应版本的源码:

以上,yolov5的源码下载完成。
3.2 下载yolov5 5.0的模型
由于yolov5 (v5.0)源码中未包含预训练模型,因此需要自己下载
下载地址:https://github.com/ultralytics/yolov5/releases
找到V5.0,然后点击 v5.0 release


3.3 模型训练生成best.pt(这边请参考 yolov5训练自己的数据集)
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 1 --batch-size 4 --device cpu
其中epoch是训练的次数,我这边先设置为1,跑通一下流程,后续再加大一下训练次数。
报错:
yolov5 RuntimeError: result type Float can't be cast to the desired output type __int64
问题解决:
修改utils/loss.py文件中的两处内容:
for i in range(self.nl): anchors = self.anchors[i]
修改为:
for i in range(self.nl): anchors, shape = self.anchors[i], p[i].shape
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid
修改为:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
然后再训练就提示成功
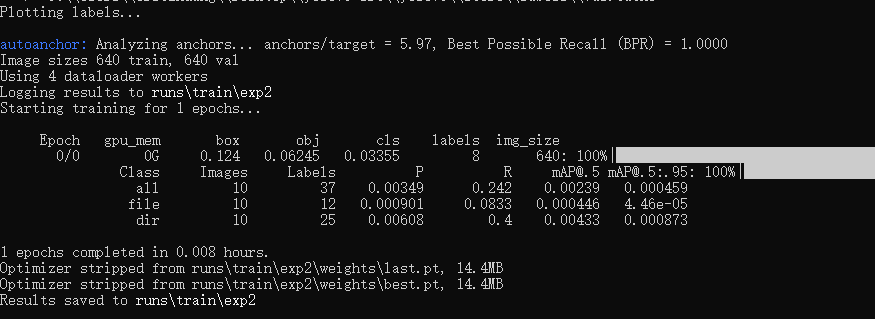
3.4 把best.pt转成best.onnx
注意:在训练时不要修改yolo.py的这段代码,训练完成后使用export.py进行模型导出转换时一定要进行修改,不然会导致后面的rknn模型转换失败!
并且如果export.py后,再次用train.py训练模型,要修改回来。不然训练模型会报错。
models/yolo.py文件的后处理部分,将class Detect(nn.Module) 类的子函数forward由
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
修改为:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x
把生成的best.pt放到yolov5目录下,执行:
python export.py --weights best.pt --img 640 --batch 1 --include onnx
报错:
--> Config model done --> Loading model W Call onnx.optimizer.optimize fail, skip optimize W Please confirm that your onnx opset_version <= 11 (current opset_verison = 13)!!! E Calc node Resize : /model.11/Resize output shape fail E Catch exception when loading onnx model: best.onnx! E Traceback (most recent call last): E File "rknn/base/RKNNlib/onnx_ir/onnx_numpy_backend/shape_inference.py", line 65, in rknn.base.RKNNlib.onnx_ir.onnx_numpy_backend.shape_inference.infer_shape E File "rknn/base/RKNNlib/onnx_ir/onnx_numpy_backend/ops/resize.py", line 232, in rknn.base.RKNNlib.onnx_ir.onnx_numpy_backend.ops.resize.Resize E AttributeError: 'str' object has no attribute 'size' E During handling of the above exception, another exception occurred: E Traceback (most recent call last): E File "rknn/base/RKNNlib/app/importer/import_onnx.py", line 118, in rknn.base.RKNNlib.app.importer.import_onnx.Importonnx.run E File "rknn/base/RKNNlib/converter/convert_onnx.py", line 115, in rknn.base.RKNNlib.converter.convert_onnx.convert_onnx.__init__ E File "rknn/base/RKNNlib/converter/convert_onnx.py", line 1161, in rknn.base.RKNNlib.converter.convert_onnx.convert_onnx._shape_inference E File "rknn/base/RKNNlib/onnx_ir/onnx_numpy_backend/shape_inference.py", line 70, in rknn.base.RKNNlib.onnx_ir.onnx_numpy_backend.shape_inference.infer_shape E File "rknn/api/rknn_log.py", line 323, in rknn.api.rknn_log.RKNNLog.e E ValueError: Calc node Resize : /model.11/Resize output shape fail E Please feedback the detailed log file <log_feedback_to_the_rknn_toolkit_dev_team.log> to the RKNN Toolkit development team. E You can also check github issues: https://github.com/rockchip-linux/rknn-toolkit/issues
问题解决:
修改export.py,把opset_version的值改为12:

再重复一下执行export.py,就可以了。
3.5 best.onnx转成best.rknn
首先需要在Linux中安装rknn toolokit,参考《Ubuntu 18.04安装rknn toolkit》
将生成的best.onnx放到toolkit的examples/onnx/yolov5目录下
修改test.py以下内容
以及
rknn.config(reorder_channel='0 1 2', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform =['rv1109'], output_optimize=1, quantize_input_node=QUANTIZE_ON)
把target_platform 修改为自己对应的平台。
以及将(备注:这边是因为我用的是RV1109,驱动只支持预编译,使能了预编译后,不能在模拟器上运行。其他平台或者设备根据自身看是否需要使能预编译。可以参考《在第二大点的第三小点》)
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
修改为:
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET, pre_compile=True)
修改dataset.txt,修改为自己要检测图片的名字。
执行:
python test.py
3.6 在rv1109设备上部署
在rv1109的SDK中rv1126_rv1109\external\rknpu\rknn\rknn_api\examples\rknn_yolov5_demo
修改include文件中的头文件postprocess.h
#define OBJ_CLASS_NUM 2 #这里的数字修改为数据集的类的个数
修改model目录下的coco_80_labels_list.txt文件, 改为自己的类并保存
file
dir
修改build.sh
GCC_COMPILER=自己设备的交叉编译器的路径/bin/arm-linux-gnueabihf
执行
./build.sh
执行成功会在当前目录生成install。
将install生成的文件放到设备中,然后将best.rknn以及需要检测图片放在一个目录中,执行
./rknn_yolov5_demo best.rknn test.bmp

执行成功,没有段错误了。但是检测不到,估摸是我训练的次数太少。后面加大训练次数,看一下效果。
把训练次数加大到100次,然后又验证了一次,
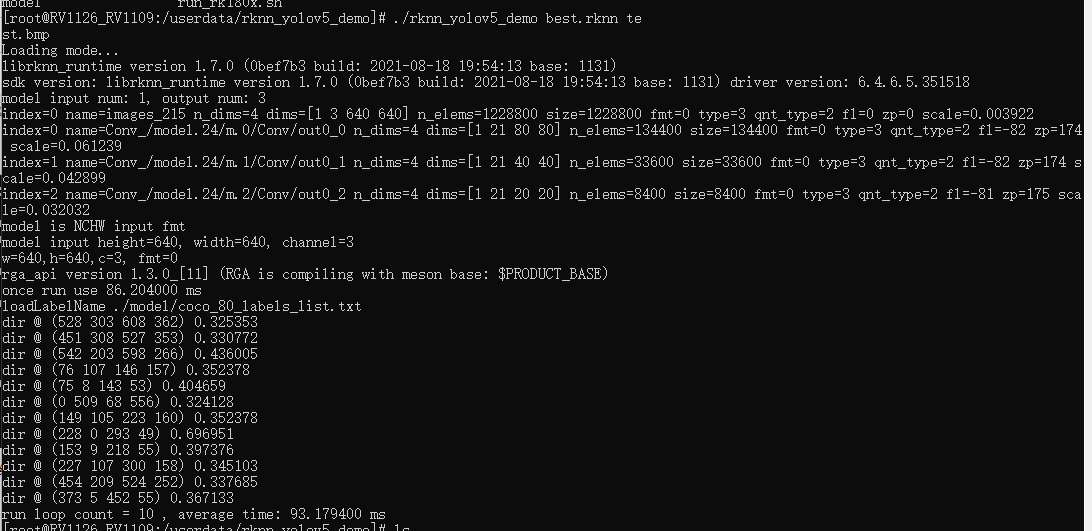
成功检测,不过只检测到dir,没检测到file。这个应该是yolov5模型训练得问题了。目前为止,流程是跑通了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号