20183429实验四 Python综合实践
20183429 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1834
姓名: 张少旋
学号:20183429
实验教师:王志强
实验日期:2020年6月13日
必修/选修: 选修
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等,我在本次实验中用到了爬虫,数据处理,可视化等应用。运用这些来爬取
豆瓣电影top250,爬取内容包括"电影详情链接", "图片链接", "电影中文名", "电影外文名", "评分", "评价数", "描述", "相关信息"。并将这些信息在excel表格中显现。
2. 实验过程及结果
实验代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 13 16:50:03 2020
@author: 11319
"""
from bs4 import BeautifulSoup
import re
import sys
import urllib
import xlwt
import sqlite3
def main():
'''主程序'''
baseurl="https://movie.douban.com/top250?start="
datalist=getData(baseurl)
savepath='豆瓣电影top250.xls'
saveData(savepath,datalist)
def askURL(url):
'''访问URL'''
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
}
req=urllib.request.Request(url=url,headers=headers)
html=""
try:
response=urllib.request.urlopen(req)
html=response.read().decode("utf-8")
return html
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
def getData(baseurl):
'''获取数据'''
findLink=re.compile(r'<a href="(.*?)">')
findImg=re.compile(r'<img.*src="(.*?)"',re.S)
findTitle=re.compile(r'<span class="title">(.*)</span>')
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge=re.compile(r'<span>(\d*)人评价</span>')
findInq=re.compile((r'<span class="inq">(.*)</span>'))
findBd=re.compile(r'<p class="">(.*?)</p>',re.S)
datalist=[]
for i in range(0,11):
url=baseurl+str(i*25)
html=askURL(url)
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
movie_data=[]
item=str(item)
link=re.findall(findLink,item)[0]
movie_data.append(link)
img=re.findall(findImg, item)[0]
movie_data.append(img)
title=re.findall(findTitle,item)
if(len(title)==2):
ctitle=title[0]
movie_data.append(ctitle)
otitle=title[1].replace("/","")
movie_data.append(otitle)
else:
movie_data.append(title[0])
movie_data.append("")
rating=re.findall(findRating,item)[0]
movie_data.append(rating)
judge=re.findall(findJudge,item)[0]
movie_data.append(judge)
inq=re.findall(findInq,item)
if(len(inq)!=0):
inq=inq[0].replace("。","")
movie_data.append(inq)
else:
movie_data.append("")
bd=re.findall(findBd,item)[0]
bd=re.sub('<br(\s+)?/>(\s+)?',"",bd)
bd=re.sub("/","",bd)
movie_data.append(bd.strip())
datalist.append(movie_data)
#print(datalist)
return datalist
def saveData(savepath,datalist):
'''保存数据'''
workbook=xlwt.Workbook(encoding="utf-8",style_compression=0)
worksheet=workbook.add_sheet("豆瓣电影Top250",cell_overwrite_ok=True)
col=("电影详情链接","图片链接","电影中文名","电影外文名","评分","评价数","描述","相关信息")
for i in range(0,8):
worksheet.write(0,i,col[i])
for i in range(0,250):
#print("第%条" %(i+1))
data=datalist[i]
for j in range(0,8):
worksheet.write(i+1,j,data[j])
workbook.save('豆瓣电影top250.xls')
if __name__=='__main__':
'''程序入口'''
main()
结果:
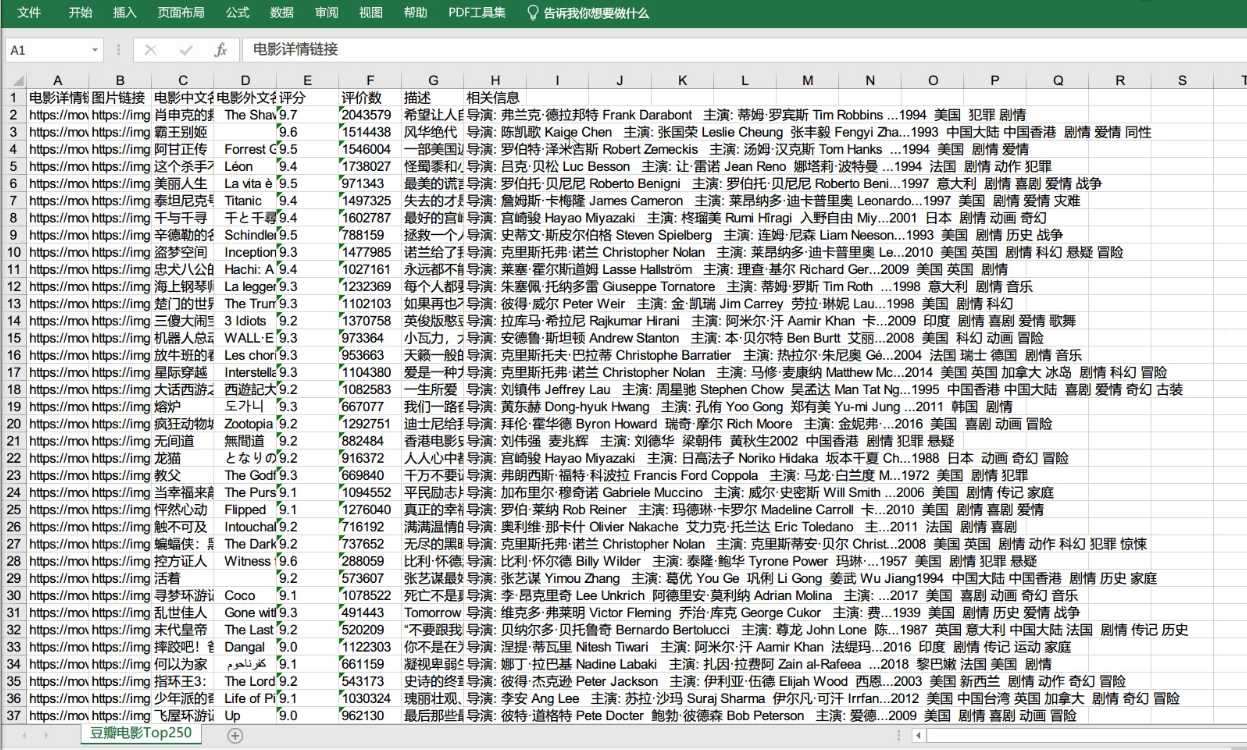
3. 实验过程中遇到的问题和解决过程
结课之后长时间未接触python,刚开始就很生疏,好多都已经遗忘,需要自己去查资料或者看视频才能解决。之后在实验过程中发现自己的开发环境
缺少很多模块,需要逐个下载安装。
其他(感悟、思考等)
学习了一学期的python,虽然学的并不是很好,很多情况下都需要求助同学才能解决一些问题。而通过网课的形式学习,自己学习效率,学习状态等
都有所影响,课上学习的并没有完全掌握,对部分知识了解不足。不过这课不像其他的课程,学完以后一直能用到,所以之后有空还能继续学习,学会
python能帮我们解决很多问题,所以python值得我们一直学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号