

Python 技术 -- Python Spider 深入
本部分是为 Python Spider 知识简谱的完整描述,若看不懂知识简谱可参阅此部分!-- CF.FC
Python Spider 扩展学习
学习是不断从模仿到创新,建议用"视频+书籍+网站+自我"的方式实现高效完美学习 -- CF.FC
一、URL、URN、URI
若学习的苦都吃不下来,那还有什么苦是能在以后承受的呢 -- CF.FC
1. URL、URN、URI 概念
- URN(Uniform Resource Name):统一资源名称
- URL(Uniform Resource Locator):统一资源定位符
- URI(Uniform Resource Identifier ):统一资源标识符,可把资源独一无二地标识出来
2. URL、URN、URI 关系
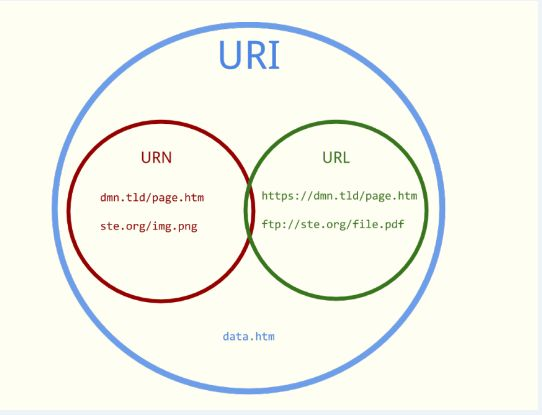
3. URL、URN、URI 概述
- URI 可分为 URL、URN 或同时具备 locators 和 names 特性
- 通常网络中的 URI 指 URL,URI 有 URL、URN 两种方式去访问其资源
- URN 的作用好似人的名字,URL 作用好似人的地址,即 URN 用于确定身份,URL 提供找寻方式
4. URL 格式组成

1. 协议:指定使用的传输协议,如:http、https、ftp、telnet、file 等
2. 登录信息:可选,指用户名和密码作为从服务器端获取资源时必要的登录信息(身份认证)
3. 服务器地址:可是域名,如:www.jianshu.com;也可是IP,如:192.168.1.10
4. 服务器端口:可选,指定服务器连接的网络端口,若省略则使用该协议的默认端口(http80、https443)
5. 文件路径:指定服务器上的路径来定位指定的资源
6. 参数:可选,用于给动态网页(如:CGI、ISAPI、PHP/JSP/ASP/ASP.NET等)传递参数,可有多个参数,用“&”符号隔开,每个参数的名和值用“=”符号隔开
7. 片段:可选,片段用于指定网络资源中的片断。html页面中片段则是描点,如:一个网页中有多个名词解释,可使用片段可直接定位到某一名词解释(描点的位置)
二、请求和响应
1. 请求
三、Python
学习和人生一样也需要大立大破 -- CF.FC
1. Python 概述
- Python 由创始人吉多·范·罗萨姆(Guido van Rossum)【龟叔】于 1989 年的圣诞节期间开发
- Python 是优雅而健壮的编程语言,有编译语言的强大性、通用性,有脚本语言、解释语言的易用性
- Python(蟒蛇)作为该编程语言的名字,是因为选取了其爱的 BBC 喜剧(Monty Python)的一词
- Python 第一个公开发行版发行于 1991 年,它是纯粹的自由软件,其源代码和解释器遵循 GPL 协议
Python 前身是 ABC 语言
GPL(GNU General Public License)协议
"龟叔"在荷兰阿姆斯特丹,为打发圣诞节的无趣开发出一个新的解释型脚本语言即 Python
2. Python 图标

3. Python 之父

4. Python 思想
Python 被设计成符合大脑思维习惯,采用极简主义的设计理念,加以统一规范的交互模式。使其易学、易理解、易记忆。Python 开发者的哲学是"用一种方法,最好是只有一种方法来做一件事"。
Python 是完全面向对象的编程语言,其函数、模块、数字、字符串等内置类型都是对象。它的类支持多态、操作符重载、多重继承等高级 OOP(面向对象)概念,且 Python 特有的简洁语法和类型使 OOP 十分易使用。当然 OOP 只是 Python 的一个选择而已,就像 C++ 一样,Python 既支持面向对象编程,也支持面向过程编程的模式。
Python 是一种解释型语言,目前 Python 的标准实现方式是将源代码的语句编译(转换)为字节码格式,然后通过解释器将字节码解释出来。Python 没有将代码编译成底层的二进制代码,所以相较于 C、C++ 等编译型语言,Python 执行速度会慢一些,但 Python 的解释型语言特性提高了开发速度,同时使它拥有解释型语言易于编写和调试等优点。
Python 本身被设计为可扩展的,并非所有的特性和功能都集成到语言核心。Python 提供了丰富的 API(应用程序编程接口) 和工具,以便程序员能轻松使用C、C++ 来编写扩充模块。Python 提供了非常完善的基础代码库,包括正则表达式、网络、多线程、GUI、数据库、等。除内置库外,Python 还有大量的第三方库以供使用。
Python 编译器本身也可被集成到其它需要脚本语言的程序内,因此很多人还把 Python 作为一种"胶水语言"(glue language)来使用,即用 Python 将其他语言程序进行集成和封装。2004 年,Python 已在 Google 内部使用。Google Engine 使用 C++ 编写性能要求极高的部分,然后用 Python 或者 Java、Go 调用相应模块。他们的目的是"Python where we can, C++ where we must",在操控硬件的场合使用 C++,在快速开发时候使用 Python。
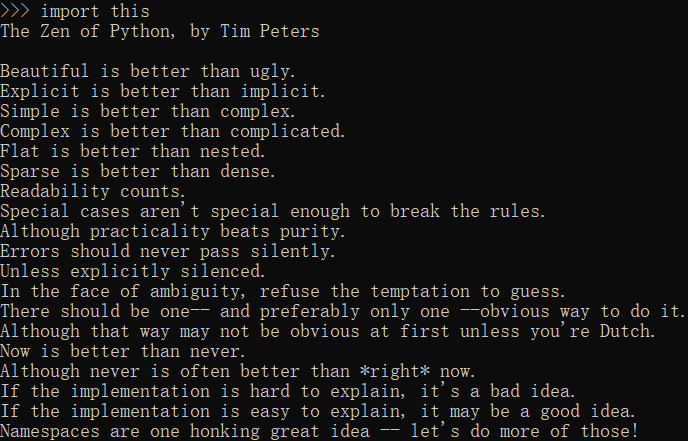
在任意一个 Python 的交互解释器中输入:import this 命令,就可看到 Python 的设计原则即 python 哲学理念(Explicit is better than implicit. 简称:EIBTI)"明了胜于晦涩",也被称为 Python 之禅,下图是 Python 之禅的内容:
3. Python 优点
- 1、软件质量高
Python 秉承了简洁、清晰的语法,以及高度一致的编程模式、始终如一的设计风格,可以保证开发出相当规范的代码。针对错误 Python 提供"安全合理"的退出机制。Python 支持异常处理,能有效捕获和处理程序运行时发生的错误,使你能够监控这些错误并进行处理。Python 代码能打包成模块和包方便管理和发布,很适合团队协同开发。
- 2、开发速度快
Python 致力于开发速度的最优化:简洁的语法、动态的类型、无需编译、丰富的库支持等特性使得程序员可快速进行项目开发。Python 往往只要几十行代码就可开发出需要几百行C代码的功能。Python 解析器能很方便地进行代码调试和测试,也可作为一个编程接口嵌入一个应用程序中,使得在开发过程中可直接进行调试,从而避免了耗时而又麻烦的编译过程,大大提高了开发速度和效率。在 Python 中,由于内存管理是由 Python 解释器负责,所以开发人员就可以从内存管理事务中解放出来,仅仅致力于开发计划中首要的应用程序设计,使得 Python 编写的程序错误更少、更加健壮、开发周期更短。
- 3、功能强大
Python 不仅功能强大本身也强壮,它还有许多面向其他系统的接口,所以完全可以使用 Python 开发整个系统的原型。为完成更多特定的任务,Python 内置了许多预编码的库工具,从正则表达式到网络编程,再到数据库编程都支持。在 web 领域、数据分析领域等,Python 还有强大的框架以便快速开发服务。例如:Django、TruboGears、Pylons 等。
- 4、易于扩展
Python 易于扩展(对于 CPython 可通过C、C++编写的模块进行功能扩展),使其能够成为一种灵活的黏合语言,可以脚本化处理其他系统和组件的行为。
- 5、跨平台
Python 是跨平台的,在各种不同的操作系统上(Linux、windows、MacOS、Unix 等)都可以看到 Python 的身影。因 Python 是用 C 写的又因其可移植性使得 Python 可以运行在任何带有 ANSI C 编译器的平台上。尽管有一些针对不同平台开发的特有模块,但是在任何一个平台上用 Python 开发的通用软件都可稍事修改或原封不动地在其他平台上运行。这种可移植性既适用于不同的架构,也适用于不同的操作系统。
4. Python 缺点
- 1、运行速度慢
Python 和 C、C++ 程序相比运行速度非常慢,因为 Python 是解释型语言即代码在执行时会一行一行地翻译成 CPU(中央处理器)能理解的机器码(机器指令),这个翻译过程非常耗时所以很慢。而 C 程序是运行前直接编译成 CPU 能执行的机器码,所以非常快。不过根据二八定律,大多数程序对速度要求不高。某些对运行速度要求很高的情况,Python 设计师倾向于用JIT(Just in time)即时编译技术,或用 C、C++ 改写这部分程序。而且你自己的时间是宝贵的资源,比 CPU 时间更珍贵。Python 开发速度带来的效益往往比执行速度带来的损失更为重要,尤其是在现代计算机高速的处理能力情况下。一些改进可能太难以实现,或者可能影响代码的可移植性或可维护性,并非所有的性能改进都值得付出努力。
- 2、代码不能加密
Python 发布程序时,实际上是发布源代码。这一点跟 C 语言不同,C 语言不用发布源代码,只需要把编译后的机器码发布出去。要从机器码完整反推出 C 代码是不可能的。
5. Python 方向
- Web 开发
Python 提供丰富的模块支持 sockets 编程、多线程编程,能方便快速地开发网络服务程序且支持最新的 XML 技术、json语言、数据库编程,同时 Python 的 ORM(Object-Relational-Mapping)对象关系映射框架,使得操作数据库非常方便。Python 还有优秀的 Django、Tornado、Flask 等 Web 框架,还有众多开源插件的支持,足以适用各种不同的 Web 开发需求。
- 自动化运维
Python 对操作系统服务的内置接口,使其成为编写可移植的维护操作系统的管理工具和部件的理想工具。Python 程序可以搜索文件和目录树、运行其他程序、使用进程和线程并行处理。
- 网络爬虫
在文本处理方面,python 提供的 re 模块能支持正则表达式,还提供 SGML(SGML(Standard Generalized Markup Language)标准通用标记语言、XML 分析模块,许多程序员利用 python 进行 XML 程序的开发。
- 图形处理
Python 有 PIL、Tkinter 等图形库支持能方便进行图形处理。在多媒体应用方面 Python 的 PyOpenGL 模块封装了"OpenGL应用程序编程接口",能进行二和三维图像处理,PyGame 模块可用于编写游戏。
- 人工智能
- 大数据分析
Python 大数据分析学习流程:数据获取->数据存储->数据预处理->数据分析->数据可视化。
- 机器人
6. Python 种类
- Cpython
Python 的官方版本,这是 Python 初始以及维护得最好的实现,使用 C 编写,新的语言特性一般会最先在这里出现。CPython 实现会将源代码文件(py文件)转换成字节码文件(pyc文件),然后运行在Python 虚拟机上,其执行过程为:程序--> C 解释器-->字节码-->机器码-->CPU。
- Jyhton
Python 的 Java 实现,此实现可用作 Java 应用程序的脚本语言,或可用于用 Java 类库创建应用程序,它也常用于为 Java 库创建测试。Jython 会将 Python 代码动态编译成 Java 字节码,然后在 JVM 上运行,其执行过程为:程序--> Java 解释器-->字节码-->机器码-->CPU。
- PyPy
完全用 Python 编写的 Python 实现。它支持在其他实现中没有找到的几个高级功能,如:stackless 支持和一个JIT(Just in Time)编译器,PyPy 将 Python 的源码翻编译成字节码再编译成机器码,其执行过程为:程序-->字节码-->机器码-->CPU。
- Python for .NET
一个可让 Python 程序员近乎无缝的集成 .NET 通用语言环境 CLR 和以及为 .NET 开发者提供一个强大的应用脚本工具。
- IronPython
一种在 .NET 和 Mono(Xamarin 公司开发的跨平台 .NET 运行环境)上实现的 Python 语言,由 Jim Hugunin(同时也是 Jython 创造者)所创造。Ironpython 是 .NET 在 Python 下的实现,而 CPython 是 C 在 Python 的实现,两者作用相同只是平台不同,所以装了 Ironpython 并不需要装 Python ,当然两者也可共存。
- RubyPython
RubyPython 是 Ruby 和 Python 解释器之间的桥梁。
- Brython
一种流行的 Python 解释器,可将 Python 转换为 JavaScript(JS) 代码。
7. Python 版本
- Python 2.X
Python 2.x的最后一个版本是 Python2.7(于2010年发布),官方将支持到2020年。
- Python 3
Python 3.X的第一个版本python 3.0(于2008年发布),Python 3.X 不兼容 Python 2.X 版本,官方也有发布 Python2.6 作为过渡到 Python 3.0 的版本,2.6之后版本都为过渡版本。为什么要开发 Python 3.X 版本呢?因为 Python 发展了 20 多年,里面有很多重复功能、重复模块,导致很多代码变得不那么简洁,所以 Guido 决定进行一次彻底的升级,原则是去繁从简,从而有了后续的 Python 3.X 版本。
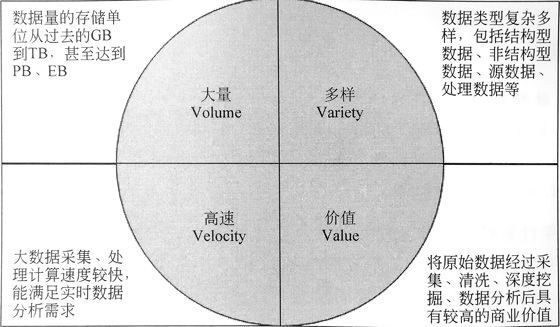
二、大数据的特征
1. Volume(大量)
大数据的特征首先是数据规模大。随着互联网、物联网、移动互联技术的发展,人和事物的所有轨迹都可以被记录下来,数据呈现出爆发性增长。数据相关计量单位的换算关系如下所示:
Byte 1Byte(B) = 8bit(b)
KB 1KB = 1024 B
MB 1MB = 1024KB
GB 1GB = 1024MB
TB 1TB = 1024GB
PB 1PB = 1024TB
EB 1EB = 1024PB
ZB 1ZB = 1024EB
YB 1YB = 1024ZB
BB 1BB = 1024YB
2. Variety(多样)
数据来源的广泛性,决定了数据形式的多样性。大数据可分为三类,一是结构化数据,如:财务系统数据、信息管理系统数据、医疗系统数据等,其特点是数据间因果关系强;一是非结构化的数据,如:视频、图片、音频等,其特点是数据间没有因果关系;三是半结构化数据,如:HTML文档、邮件、网页等,其特点是数据间的因果关系弱。有统计显示,目前结构化数据占据整个互联网数据量的75%以上,而产生价值的大数据,往往是这些非结构化数据。
3. Velocity(高速)
数据的增长速度和处理速度是大数据高速性的重要体现。与以往的报纸、书信等传统数据载体生产传播方式不同,在大数据时代,大数据的交换和传播主要是通过互联网和云计算等方式实现的,其生产和传播数据的速度是非常迅速的。另外,大数据还要求处理数据的响应速度要快,如:上亿条数据的分析必须在几秒内完成。数据的输人、处理、丢弃必须立刻见效,几乎无延迟。
4. Value(价值)
大数据的核心特征是价值。价值密度的高低和数据总量大小成反比,即数据价值密度越高数据总量越小,数据价值密度越低数据总量越大。任何有价值的信息的提取依托的就是海量的基础数据。当然目前大数据背景下有个未解决的问题,如:怎样通过强大的机器算法更迅速地在海量数据中完成数据的价值提纯。
5. 4V 的结构图
三、Python 常用库
1. 请求库(用于实现 HTTP 的请求)
- 1、urllib:用于操作 URL
- 2、aiohttp:基于 asyncio 实现的 HTTP 框架,使用异步库进行数据抓取可大大提高效率
- 3、selenium:自动化测试工具,通过此库你可直接调用浏览器完成某些操作,如:输入验证码
- 4、requests:基于 urllib 编写,阻塞式 HTTP 请求库,即发出请求直到服务器响应后程序才下一步
2. 解析库(用于从网页中提取信息)
- 1、lxml:支持 HTML 和 XML 的解析,支持 XPath 解析方式,而且解析效率非常高
- 2、tesserocr:一个 OCR 库,在遇到验证码(图形验证码为主)时,可直接用 OCR 识别
- 3、beautifulsoup:用于 html 和 XML 的解析,进而从网页中提取信息,拥有强大的 API
- 4、pyquery:jQuery 的 Python 实现,能以 jQuery 语法来操作解析 HTML 文档,易用、解析快
3. 存储库(Python与数据库的交互)
- 1、pymysql:一个纯 Python 实现的 MySQL 客户端操作库
- 2、pymongo:一个用于直接连接 mongodb 数据库进行查询操作的库
- 3、redisdump:一个用于 redis 数据导入/导出的工具基于 ruby 实现,使用前需先安装 Ruby
4. 爬虫框架(便于开发爬虫相关程序)
- 1、Portia:可视化爬取网页内容
- 2、newspaper:提取新闻、文章以及内容分析
- 3、python-goose:Java 编写的文章提取工具
- 4、cola:一个分布式爬虫框架,虽然项目整体设计有点糟但模块间耦合度较高
- 5、Scrapy:很强大的爬虫框架,适用于爬取简单的页面,但对稍复杂的页面则不适用
- 6、Crawley:高速爬取对应网站的内容,支持关系和非关系数据库,数据可导出为 JSON、XML 等
5. Web 框架库(便于开发 Web 服务程序)
- 1、flask:轻量级的 web 服务程序,简单、易用、灵活,主要用来做一些 API 服务
- 2、django:一个 web 服务器框架,提供了完整的后台管理,引擎、接口等,用它可制作完整网站
Python Spider 代码仓库
即使学习了很久也一无所有,但不乏重来的勇气和信心,而过程的精彩也是极其绚烂的 -- CF.FC
一、urllib 库
真理之海十分广阔,只有不断地学习并掌握知识,才有可能有朝一日窥见其神秘真面目 -- CF.FC
1.1 request 模块
requests_one.py、requests_two.py、requests_three.py、requests_four.py
1.1.1 request_one.py
"""
@date 2023/09/08
@author CF.FC(zhr)
@FileName:request_one.py
@description: urllib 库的 request 模块示例代码一
"""
# TODO 尝试用 from urllib import request as ure
import urllib.request # 导入 request 模块
# TODO 尝试用 https://fanyi.youdao.com/
url = 'http://fanyi.youdao.com/' # 定义 url 字符串
response = urllib.request.urlopen(url) # 构造 HTTP 请求,并将返回结果赋给 response
print('响应类型:', type(response)) # 输出响应类型
print('响应状态码:', response.getcode()) # 输出响应状态码
print('编码方式:', response.getheader('Content-Type')) # 输出编码方式
print('请求的URL:', response.geturl()) # 输出请求的 URL
# TODO 尝试用 response.read()
resp = response.read().decode('utf-8') # 读取网页内容并解码
print('网页内容:\n', resp) # 输出网页内容
# QA from urllib import request as ure 为什么和 import urllib.request 一致?因两种方式等价
# QA https://fanyi.youdao.com/ 为什么和 http://fanyi.youdao.com/ 一致?因 HTTP、HTTPS 都支持
# QA response.read() 为什么和 response.read().decode('utf-8') 不一致?因为 read() 默认为 Byte 类型,需用 decode() 解码成 str 类型显示
1.1.2 request_two.py
"""
@date 2023/09/08
@author CF.FC(zhr)
@FileName:request_two.py
@description: urllib 库的 request 模块示例代码二
"""
import urllib.request as ure
# TODO 尝试用 www.baidu.com
req = ure.urlopen('https://www.baidu.com/')
print("响应状态码:", req.getcode())
print("响应状态码:", req.status)
print("请求的地址:", req.geturl())
print("请求的地址:", req.url)
# TODO 尝试用 req.read().decode('UTF-8')
print("响应体内容:", req.read())
print("响应体内容:", req.readline())
print("响应头信息:", req.info())
print("响应头内容:", req.getheaders())
print("特定响应头:", req.getheader('Connection'))
# QA www.baidu.com 为什么不能用?因为没有 https:// 前缀导致 url 书写错误,必须加上前缀才为正确
# QA req.read().decode('UTF-8') 为什么可以变成字符串?因为 decode() 将返回的 Byte 类型 转成了 str 类型
1.1.3 request_three.py
"""
@date 2023/09/08
@author CF.FC(zhr)
@FileName:request_three.py
@description: urllib 库的 request 模块示例代码三
"""
import urllib.parse # 导入 parse 模块
# TODO from urllib import *
import urllib.request # 导入 request 模块
url = 'http://fanyi.youdao.com/translate?smartresult=dict&' \
'smartresult=rule' # 定义url字符串
data_value = {
'i': '苹果',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15924715113269',
'sign': '5c3a992ac57ed879b7678ff05bb3ec44',
'ts': '1592471511326',
'bv': 'c74c03c52496795b65595fdc27140f0f',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
} # 定义 data_value 参数
data_value = urllib.parse.urlencode(data_value).encode('utf-8') # 编码 data_value 参数
response = urllib.request.urlopen(url, data=data_value) # 构造HTTP请求,并将返回的结果赋值给response
resp = response.read().decode('utf-8') # 读取网页内容并解码
print(resp) # 输出网页内容
# QA 对象名的书写规范是什么?全部小写加下划线
# QA 为什么删掉原来 url 中的"_o"?因为它是反爬的设置
# QA 对象能否重新赋值?对象可以重新赋值,且会覆盖掉原来的值
# QA 路径书写中的 \ 代表什么意思?代表换行因为 PEP8 规范要求一行的字符不能超过120个
# QA 能否不写导入 pare 的模块语句?因 request 模块中包含 parse 模块,所以可以不写,但建议写上因为会产生警告
# QA 能否用 from urllib import * 替代 import urllib.parse 和 import urllib.request?不能,因为它导入的是所有函数,而没有模块文件
1.1.4 request_four.py
"""
@date 2023/09/08
@author CF.FC(zhr)
@FileName:request_four.py
@description: urllib 库的 request 模块示例代码四
"""
import urllib.request # 导入request模块
url = 'https://fanyi.youdao.com/' # 定义url字符串
headers_value = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; '
'Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/'
'83.0.4103.97 Safari/537.36'
} # 设置 headers_value 参数,伪装成浏览器
request = urllib.request.Request(url, headers=headers_value) # 创建Request对象,并将返回的结果赋值给request
response = urllib.request.urlopen(request).read().decode('utf-8') # 读取网页内容并解码
print(response) # 输出网页内容
# QA KHTML 是一个 Web(HTML) 渲染引擎
1.2 error 模块
error_one.py
1.2.1 error_one.py
"""
@date 2023/09/08
@author CF.FC(zhr)
@FileName:error_one.py
@description: urllib 库的 error 模块示例代码一
"""
import urllib.request # 导入request模块
import urllib.error # 导入error模块
try: # 处理异常
# TODO 尝试用 urllib.request.urlopen('https://www.zhr.com/')
response = urllib.request.urlopen('https://www.zhr.com/') # 构造HTTP请求,并将返回的结果赋值给 response
except urllib.error.HTTPError as e: # 捕获HTTP请求的异常
# 输出 HTTP 请求的异常原因、状态码和请求头
print('HTTP 异常原因:', e.reason)
print('响应状态码:', e.code)
print('请求头:\n', e.headers)
except urllib.error.URLError as e: # 捕获 URL 异常
print("URL 异常原因:", e.reason) # 输出 URL 异常原因
else:
# 如果没有异常则输出“Request Successfully”
print('Request Successfully')
# QA 异常处理机制的作用是什么?异常处理机制的作用是防止程序意外崩溃
# QA urllib.request.urlopen('https://www.zhr.com/') 和 response = urllib.request.urlopen('https://www.zhr.com/') 一致?因为后续的对象未被使用
1.3 parse 模块
parse_one.py
1.3.1 parse_one.py
"""
@date 2023/09/09
@author CF.FC(zhr)
@FileName:parse_one.py
@description: urllib 库的 parse 模块示例代码一
"""
import urllib.parse # 导入 parse 模块
url = 'https://f.youdao.com/?path=file&keyfrom=Nav-doc' # 定义 url 字符串
print(urllib.parse.urlparse(url)) # 拆分 url 并输出结果
print(urllib.parse.urljoin('https://f.youdao.com/', '?path=file&keyfrom=Nav-doc')) # 合并 url 并输出结果
params = {'path': 'file', 'keyfrom': 'Nav-doc'} # 定义 params 字符串
print('https://f.youdao.com/?' + urllib.parse.urlencode(params)) # 编码 params 参数,合并 url 并输出结果
query = 'path=file&keyfrom=Nav-doc' # 定义 query 字符串
print(urllib.parse.parse_qs(query)) # 将 query 字符串转换成字典
print(urllib.parse.parse_qsl(query)) # 将 query 字符串转换成列表
keyword = '网络爬虫' # 定义 keyword 中文字符串
url = 'https://f.youdao.com/?wd=' + urllib.parse.quote(keyword) # 将中文字符转换为 URL 编码,合并后赋值给 url
print(url) # 输出 URL 编码的 url
print(urllib.parse.unquote(url)) # 将 URL 编码转换为中文字符并输出结果
1.4 robotparser 模块
robotparser_one.py
1.4.1 robotparser_one.py
"""
@date 2023/09/09
@author CF.FC(zhr)
@FileName:robotparser_one.py
@description: urllib 库的 robotparser 模块示例代码一
"""
import urllib.robotparser # 导入 robotparser 模块
rp = urllib.robotparser.RobotFileParser() # 创建 RobotFileParser 类对象 rp
rp.set_url('https://fanyi.youdao.com/robots.txt') # 设置 robots.txt 文件的 URL
rp.read() # 读取 robots.txt 文件并进行分析
user_agent = 'Baiduspider' # 定义爬虫名称
# TODO 尝试用 http://fanyi.youdao.com/index.html
url = 'https://fanyi.youdao.com/web2/index.html' # 定义有道网页翻译的 url
print("是否允许爬取有道翻译的 index 默认页面:", rp.can_fetch(user_agent, url)) # 判断是否可以爬取有道网页翻译并输出判断结果
url = 'https://f.youdao.com/?path=fast&keyfrom=Nav-fast' # 定义有道人工翻译网页的 url
print("是否允许爬取有道翻译的人工翻译页面::", rp.can_fetch(user_agent, url)) # 判断是否可以爬取有道人工翻译网页并输出判断结果
# QA 为什么用 http://fanyi.youdao.com/index.html 而不用 http://fanyi.youdao.com/web2/index.html?因为有道翻译默认网页的网址发生了变化,之前的网址不适用了
二、requests 库
Talk is cheap. Show me the code -- Linus
2.1 请求方法
get_one.py、post_one.py、post_two.py
2.1.1 get_one.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_one.py
@description: requests 库的 get 函数示例代码一
"""
import requests as req
resp = req.get("https://www.muma.com/")
print("get 请求 url:", resp.url)
print("get 响应头:", resp.headers)
print("get 文本响应内容:", resp.text)
print("get 二进制响应内容:", resp.content)
# TODO 尝试用 print("get 返回 json 数据:", resp.json())
# print("get 返回 json 数据:", resp.json())
print("get 响应状态码:", resp.status_code)
print("get 请求头:", resp.request.headers)
print("get 猜测出的编码格式:", resp.encoding)
print("get 异常状态抛出", resp.raise_for_status())
print("get 分析出的编码格式:", resp.apparent_encoding)
# QA 用 print("get 返回 json 数据:", resp.json()) 为什么报 requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0) 错?因为没有 JSON 数据,删除它即可
2.1.2 post_one.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:post_one.py
@description: requests 库的 post 函数示例代码一
"""
import requests # 导入requests模块
data_value = {'name': '11111',
'password': '222222',
'remember': 'false'
} # 定义data_value参数
url = 'https://accounts.douban.com/j/mobile/login/basic' # 定义 url 字符串
r_post = requests.post(url, data=data_value) # 发送 HTTP 请求,并将返回结果赋值给 r
print("post 请求的URL:", r_post.url) # 输出请求的 URL
print("post 返回对象类型:", type(r_post)) # 输出返回对象类型
print("post 请求头:", r_post.request.headers) # 输出请求头
print("post 响应状态码:", r_post.status_code) # 输出返回状态码
while (True):
input_number = int(input("请输入数字选择不同的请求方式(0--退出、1--put、2--head、3--delete、4--options):"))
if input_number == 0:
print("退出程序")
break
elif input_number == 1:
# TODO requests.put('https://www.douban.com/') # PUT 请求
r_put = requests.put('https://www.douban.com/')
print("put 请求的 URL:", r_put.url)
print("put 请求头:", r_put.headers)
print("put 返回对象类型:", type(r_put))
print("put 响应状态码:", r_put.status_code)
elif input_number == 2:
# TODO requests.head('https://www.douban.com/') # head 请求
r_head = requests.head('https://www.douban.com/')
print("head 请求的URL:", r_head.url)
print("head 请求头:", r_head.headers)
print("head 返回对象类型:", type(r_head))
print("head 响应状态码:", r_head.status_code)
elif input_number == 3:
# TODO requests.delete('https://www.douban.com/') # DELETE 请求
r_delete = requests.delete('https://www.douban.com/')
print("delete 请求的URL:", r_delete.url)
print("delete 请求头:", r_delete.headers)
print("delete 返回对象类型:", type(r_delete))
print("delete 响应状态码:", r_delete.status_code)
elif input_number == 4:
# TODO requests.options('https://www.douban.com/') # OPTIONS请求
r_options = requests.options('https://www.douban.com/')
print("options 请求的URL:", r_options.url)
print("options 请求头:", r_options.headers)
print("options 返回对象类型:", type(r_options))
print("options 响应状态码:", r_options.status_code)
else:
print("数字输入有误,请重新输入")
2.1.3 post_two.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:post_two.py
@description: requests 库的 post 函数示例代码二
"""
import requests # 导入requests模块
r = requests.post('https://www.douban.com/') # 发送HTTP请求,并将返回结果赋值给r
print('响应类型:', type(r)) # 输出响应类型
print('请求的URL:', r.url) # 输出请求的URL
print('响应状态码:', r.status_code) # 输出响应状态码
print('请求头:', r.request.headers) # 输出请求头
2.2 传递 URL 参数
get_two.py
2.2.1 get_two.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_two.py
@description: requests 库的 get 函数示例代码二
"""
import requests # 导入 requests 库
params_value = {'q': 'Python'} # 定义字典形式的 params_value 参数值
r = requests.get('https://www.douban.com/search', params=params_value) # 将 params_value 作为参数增加到 url 中并发送请求,将返回结果赋值给 r
print(r.url) # 输出 url
2.3 定制请求头
get_three.py
2.3.1 get_three.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_three.py
@description: requests 库的 get 函数示例代码三
"""
import requests # 导入 requests 库
url = 'https://www.douban.com/' # 定义 url 字符串
headersvalue = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
} # 设置请求头的 User-Agent 信息
r = requests.get(url) # 不设置 headers,发送 HTTP 请求,并将返回结果赋值给r
print(r.status_code) # 输出返回状态
print(r.request.headers) # 输出请求头
r = requests.get(url, headers=headersvalue) # 设置 headers,发送 HTTP 请求,并将返回结果赋值给 r
print(r.status_code) # 输出返回状态
print(r.request.headers) # 输出请求头
# QA User-Agent 的作用是什么? User-Agent 的作用是将爬虫程序伪装成浏览器,防止浏览器的进行拦截
2.4 设置Cookie
get_four.py
2.4.1 get_four.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_four.py
@description: requests 库的 get 函数示例代码四
"""
import time
import requests # 导入requests模块
headersvalue = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Cookie': 'll="108288";bid=FU35Y0eS-KI;_vwo_uuid_v2=D18B3319C1E99BBB6569C2519D7E87F51|5e9046ac929cff3665e02f4d7f9f68d7;__yadk_uid=5fkfyCBRiZhR06ApyA4T6nfI7PZTE6nG;push_doumail_num=0;push_noty_num=0;__utmv=30149280.21804;gr_user_id=f6e3b102-811c-4a00-afc4-bbb5ee299526;viewed="35006240_34972174_34852472_30364330";douban-profile-remind=1;__gads=ID=26116add0658c95e-2222028b20c2008e:T=1592359146:RT=1592359146:S=ALNI_MYKBe2T1D1KdY6ogX7t81hsybGcgw;douban-fav-remind=1;_pk_ses.100001.8cb4=*;_pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1593565363%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DvSVBM9Y7T-Yy8vzFQq0LV5nGpKP5d6I3U243CpQX4pxJZH5ID5_PB9Wk-M164506%26wd%3D%26eqid%3Db5820ad1001638f7000000025efbe0b0%22%5D;__utma=30149280.1310555483.1590215237.1592894955.1593565364.25;__utmc=30149280;__utmz=30149280.1593565364.25.21.utmcsr=baidu|utmccn=(organic)|utmcmd=organic;__utmt=1;dbcl2="218046940:FNvUarDCBJw";ck=zTcB;_pk_id.100001.8cb4=02776c1057c8040d.1590215236.23.1593565372.1592894954.;ap_v=0,6.0;__utmb=30149280.3.10.1593565364'
} # 定义 headers 的 User-Agent 和 Cookie 信息
r = requests.get('https://www.douban.com/', headers=headersvalue) # 设置 headers,发送 HTTP 请求,并将返回结果赋值给 r
print(r.text) # 输出文本类型的返回内容
print("三秒后开始请求", "~~~" * 30)
time.sleep(3)
# TODO 尝试用 requests.get('https://www.douban.com/', cookies=r.cookies)
resp = requests.get('https://www.douban.com/', cookies=r.cookies)
print(resp.content)
print("请求正常的结束", "~~~" * 30)
2.5 设置超时
get_five.py
2.5.1 get_five.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_five.py
@description: requests 库的 get 函数示例代码五
"""
import requests # 导入 requests 库
# 异常处理
try:
r = requests.get('https://www.douban.com/', timeout=0.001) # 设置 timeout 参数,发送 HTTP 请求,并将返回结果赋值给 r
# TODO resp = requests.get('https://www.douban.com/', timeout=1)
resp = requests.get('https://www.douban.com/', timeout=1)
except requests.Timeout: # 捕获 Timeout 异常
print('Timeout!') # 输出 Timeout!
else:
print(r.status_code) # 输出响应状态码
print(resp.status_code) # 输出响应状态码
# QA 异常处理机制是什么样的?异常处理机制在异常被捕获到的时候,就会马上停止程序运行且输出异常,如上述代码所示
2.6 获取二级制文件
get_six.py
2.6.1 get_six.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:get_six.py
@description: requests 库的 get 函数示例代码六
"""
import requests # 导入 requests 库
r = requests.get('https://img9.doubanio.com/view/subject/s/public/s33643895.jpg') # 发送 HTTP 请求,并将返回结果赋值给 r
print(r.content) # 输出二进制类型返回内容
print(r.text) # 输出文本类型返回内容
with open('on the rode.jpg', 'wb') as f: # 保存二进制类型返回内容为 jpg 文件
f.write(r.content)
# QA 为什么 text 属性返回的内容是乱码?因为图片是二进制数据,不能直接将其转化为字符串,通过文件的写入二进制数据操作可将其变为对应的图片
2.7 字符编码
detect_one.py、detect_two.py、detect_three.py
2.7.1 detect_one.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:detect_one.py
@description: chardet 库的 detect 函数示例代码一
"""
import chardet # 导入 chardet 库
str2byte = '网络爬虫'.encode('utf-8') # UTF-8 编码
print("原始字符串:", str2byte) # 输出编码字符串
print("字符串类型", type(str2byte)) # 输出编码字符串类型
print("编码类型:", chardet.detect(str2byte)) # 检测编码类型
byte2str = str2byte.decode('utf-8') # 解码
print("解码内容:", byte2str) # 输出解码字符串
print("解码类型:", type(byte2str)) # 输出解码字符串类型
# QA 为什么 Unicode 不能通过 decode() 方法再次进行解码,已编码内容也不能通过 encode()再次编码?因为已有成品
2.7.2 detect_two.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:detect_two.py
@description: chardet 库的 detect 函数示例代码二
"""
import chardet # 导入 chardet 库
import requests # 导入 requests 库
r = requests.get('https://www.sina.com.cn/') # 发送请求,并将返回结果赋值给 r
print("编码类型:", r.encoding) # 输出返回编码类型
print("编码类型:", chardet.detect(r.content)) # 检测返回内容编码类型
code_type = chardet.detect(r.content)['encoding'] # 将检测到的编码类型赋值给 code_type
# TODO 尝试用 print(r.content.decode()) # 输出解码后的网页内容
print(r.content.decode(code_type)) # 输出解码后的网页内容
# QA 为什么 print(r.content.decode()) 和 r.content.decode(code_type) 都没中文乱码?因为网页原始编码为 UTF-8
# QA r.encoding 和 chardet.detect() 的区别是什么?r.encoding 只根据文件头判断,若网页写得不规范返回 ISO-8859; chardet.detect() 会根据返回的二进制数据判断编码,然后再用 decode() 解码,应根据实际情况选择
2.7.3 detect_three.py
"""
@date 2023/09/15
@author CF.FC(zhr)
@FileName:detect_three.py
@description: chardet 库的 detect 函数示例代码三
"""
import chardet
import requests
base_url = 'https://movie.douban.com/top250' # 定义 base_url 字符串
headers_value = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
} # 设置请求头User-Agent参数
for i in range(0, 10): # 循环翻页
params_value = {'star': str(i * 25), 'filter': ''}
try:
r = requests.get(base_url, params=params_value, headers=headers_value, timeout=1) # 发送请求,并将返回结果赋值给r
except requests.Timeout:
print('Timeout!')
else:
print("响应状态码:", r.status_code) # 输出
print("URL:", r.url) # 输出
code_type = chardet.detect(r.content)['encoding'] # 检测返回内容编码类型
with open('movie.txt', 'a+', encoding='utf-8') as f: # 将爬取到的网页内容保存至 txt 文件中
f.write(r.content.decode(code_type))
# QA Python 文件的 a+ 操作指什么?a+ 表示追加文本
三、lxml 库
既要有深入下去的细心和恒心,也要有统揽全局的决心和信心 -- CF.FC
3.1 lxml XPath 通过路径选择节点
etree_one.py、etree_two.py
3.1.1 etree_one.py
"""
@date 2023/09/17
@author CF.FC(zhr)
@FileName:etree_one.py
@description: lxml 库的 etree 模块示例代码一
"""
import requests # 导入 requests 库
import urllib.parse # 导入 parse 模块
from lxml import etree # 导入 etree 模块
from urllib.robotparser import RobotFileParser # 导入 RobotFileParser 类
# TODO 尝试用 robot_file_parser = RobotFileParser
robot_file_parser = RobotFileParser() # 创建RobotFileParser对象
# TODO 尝试用 robot_file_parser.set_url(url='https://www.17k.com/robot.txt')
robot_file_parser.set_url(url='https://www.17k.com/robots.txt') # 设定 17k(URL) 的 robots 协议
print("17k网站的 robots 协议:", robot_file_parser.read())
novel_base_url = 'https://www.17k.com' # 定义字符串 novel_base_url
# TODO 尝试用 novel_url = urllib.parse.urljoin(novel_base_url, '/list/3328785.html/')
novel_url = urllib.parse.urljoin(novel_base_url, '/list/3328785.html') # 将合并的 url 赋值给 novel_url
resp = requests.get(novel_url) # 发送请求,并将返回结果赋值给 r
print("响应状态码:", resp.status_code)
html = etree.HTML(resp.text) # 创建 HTML 对象 html
print("以下为 XPath 正常执行后产生的内容:") # 打印输出Xpath正常执行后的输出内容
hrefs = html.xpath('//div/dl/dd/a/@href') # 选择节点并提取 href 属性值
for href in hrefs:
chapter_url = urllib.parse.urljoin(novel_base_url, href) # 将 novel_base_url 和提取的属性值合并成章节链接
print(chapter_url) # 输出每个章节链接
# QA 为什么 robot_file_parser = RobotFileParser 会导致后续的对象使用出错?因为实例化对象的格式写错了,但注意在 Pycharm 中却没有错误提示
# QA 为什么 novel_url = urllib.parse.urljoin(novel_base_url, '/list/3328785.html/') 会报 404?因为具体文件的页面后不能加 / ,只能在网址后加 / 以加速请求
# QA 为什么 robot_file_parser.set_url(url='https://www.17k.com/robot.txt') 可以用?因为 RobotFileParser 类可识别 robot.txt 和 robots.txt,但浏览器的地址栏不能识别 robot.txt 只能用 robots.txt
# QA 为什么出现 requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))错误?因为网站关闭导致请求失败
3.1.2 etree_two.py
"""
@date 2023/09/17
@author CF.FC(zhr)
@FileName:etree_two.py
@description: lxml 库的 etree 模块示例代码二
"""
import requests # 导入 requests 库
from lxml import etree # 导入 etree 模块
url = 'https://www.17k.com/list/3328785.html' # 定义 url 字符串
r = requests.get(url) # 发送请求,并将返回结果赋值给r
html = etree.HTML(r.text) # 创建 HTML 对象 html
print('HTML对象类型:', type(html)) # 输出 html 的类型
print('body节点下的所有div子节点:', html.xpath('/html/body/div')) # 输出 body 节点下的所有 div 子节点
print('body节点下的所有div子孙节点:', html.xpath('body//div')) # 输出 body 节点下的所有 div 子孙节点
print('body节点下的所有子节点:', html.xpath('body/*')) # 输出 body 节点下的所有子节点
print('当前body节点:', html.xpath('body/.')) # 输出当前 body 节点
print('当前body节点的父节点:', html.xpath('body/..')) # 输出当前 body 节点的父节点
3.2 lxml XPath 通过属性选择节点
etree_three.py
3.2.1 etree_three.py
"""
@date 2023/09/17
@author CF.FC(zhr)
@FileName:etree_three.py
@description: lxml 库的 etree 模块示例代码三
"""
import requests # 导入 requests 库
from lxml import etree # 导入 etree 模块
url = 'https://www.17k.com/list/3328785.html' # 定义 url 字符串
r = requests.get(url) # 发送请求,并将返回结果赋值给 r
html = etree.HTML(r.text) # 创建 HTML 对象 html
print('class属性值为“content”的div节点:', html.xpath('//div[@class="content"]')) # 输出 class 属性值为 "content" 的 div 节点
print('id属性值以“con”开头的div节点:', html.xpath('//div[starts-with(@id,"con")]')) # 输出 id 属性值以 "con" 开头的 div 节点
print('id属性值包含“tent”的div节点:', html.xpath('//div[contains(@id,"tent")]')) # 输出 id 属性值包含 "tent" 的 div 节点
print('id属性值为“content”和class属性值为“showtxt”的div节点:', html.xpath('//div[@id="content" and @class="showtxt"]')) # 输出 id 属性值为 "content" 和 class 属性值为 "showtxt" 的 div 节点
print('id属性值为“content”的div节点的class属性值:', html.xpath('//div[@id="content"]/@class')) # 输出 id 属性值为 "content" 的 div 节点的 class 属性值
3.3 lxml XPath 通过内置函数选择
etree_four.py、etree_five.py
3.3.1 etree_four.py
"""
@date 2023/09/17
@author CF.FC(zhr)
@FileName:etree_four.py
@description: lxml 库的 etree 模块示例代码四
"""
import requests # 导入 requests 库
from lxml import etree # 导入 etree 模块
chapter_url = 'https://www.17k.com/chapter/3328785/44207503.html' # 定义字符串 chapter_url
r = requests.get(chapter_url) # 发送请求,并将返回结果赋值给r
print("请求地址:", r.url) # 打印输出请求的地址
print("响应状态码:", r.status_code) # 打印输出响应状态码
code_type = r.apparent_encoding # 获取返回内容编码类型
print("编码类型:", code_type) # 打印输出编码类型
if code_type == 'Windows-1254': # 判编码类型是否是 Windows-1254,若是改变编码类型为 UTF-8
code_type = 'UTF-8'
r.encoding = code_type # 重定义返回内容编码类型
html = etree.HTML(r.text) # 创建 HTML 对象 html
title = html.xpath('//h1/text()')[0] # 选择 h1 节点并提取文本,将返回的列表第一项赋值给 title
print() # 换行
print(title) # 输出第一章节的标题
# TODO 尝试用 contents = html.xpath('//div[@class="p"]/text()')
contents = html.xpath('//div[@class="p"]//text()') # 选择 class 属性值为 "p" 的 div 节点并提取文本
for i in contents: # 遍历列表
content = i.strip() # 移除字符串头尾的空格,并赋值给 content
print(content) # 输出第一章节的正文
# QA 为什么用 GBK 替换掉 GB2312?因为 GB2312 编码支持的汉字较少,可能导致中文内容出现小部分乱码,而 GBK 编码向下兼容 GB2312,若编码类型是 GB2312 可直接将编码类型改为 GBK,已解决乱码问题
# QA 为什么用 contents = html.xpath('//div[@class="p"]/text()') 代码正常运行但无内容产生?因为找寻的节点不对所以输出内容为空,应该用 contents = html.xpath('//div[@class="p"]//text()')
3.3.2 etree_five.py
"""
@date 2023/09/19
@author CF.FC(zhr)
@FileName:etree_five.py
@description: lxml 库的 etree 模块示例代码五
"""
import time
import requests
from lxml import etree
url = 'https://www.biquge365.net/newbook/33411/'
head = {
'Referer': 'https://www.biquge365.net/book/33411/',
'users-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39'
}
response = requests.get(url, headers=head, verify=False)
html = etree.HTML(response.text)
novel_name = html.xpath('/html/body/div[1]/div[3]/div[1]/h1/text()')[0]
novel_directory = html.xpath('/html/body/div[1]/div[4]/ul/li[*]/a/@href')
time.sleep(5)
for i in novel_directory:
com_url = 'https://www.biquge365.net'+i
print(com_url)
response2 = requests.get(com_url,headers=head)
html2 = etree.HTML(response2.text)
novel_chapter = html2.xpath('//*[@id="neirong"]/h1/text()')[0]
print(novel_chapter)
novel_content = '\n'.join(html2.xpath('//*[@id="txt"]/text()'))
print(novel_content)
with open('D:\\'+novel_chapter+'.txt','w',encoding='utf-8') as file:
file.write(novel_chapter+'\n'+novel_content+'\n')
file.close()
print("下载成功"+novel_chapter)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号