

liveTalking部署
1、环境要求
linux系统:建议ubuntu 20.04,
显卡驱动&CUDA Toolkit:v11.8
cuDNN:v8.9.5
2、软件安装
- 显卡驱动&CUDA Tookit安装
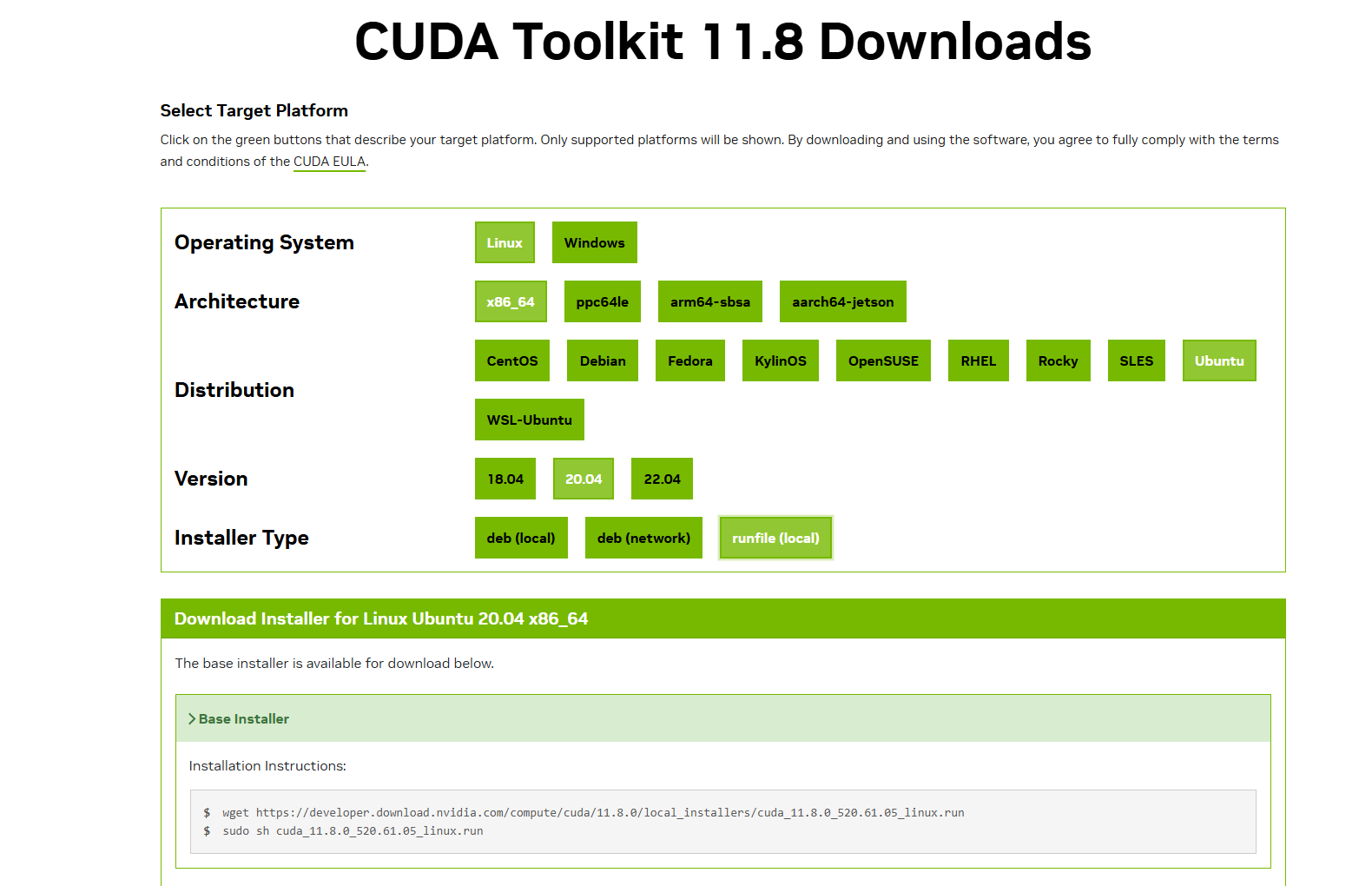
去官网下载CUDA安装包https://developer.nvidia.com/cuda-toolkit-archive,这里选择11.8版本
![]()
根据自己的系统选择,最终会生成安装命令,按照安装命令安装CUDA,安装的时候选择驱动和CUDA Toolkit安装,安装结束后查看下~/.bashrc环境变量是否有CUDA,如果没有,则在~/.bashrc文件末尾加上CUDA配置export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda说明:CUDA安装完成后会生成软链接目录CUDA,所以这里不需要指向到带版本的CUDA目录执行source ~/.bashrc使配置生效,最后执行nvcc -V和nvidia-smi查看驱动和toolkit是否都安装成功
- 安装cuDNN
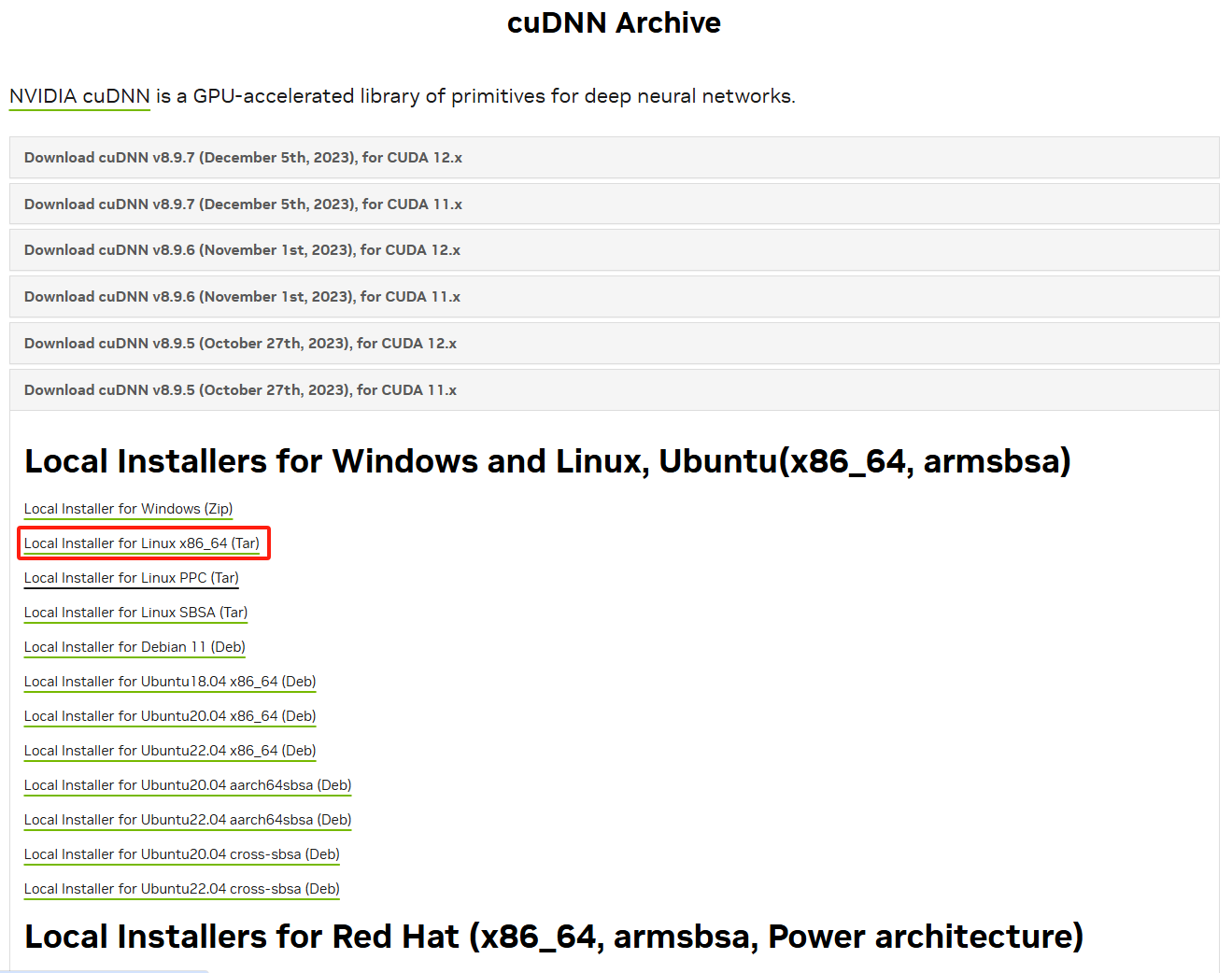
去官网下载和CUDA相匹配的版本https://developer.nvidia.com/rdp/cudnn-archive
![]()
下载完对文件cudnn-linux-x86_64-8.9.2.26_cuda11-archive.tar.xz进行解压缩
tar -xf cudnn-linux-x86_64-8.9.2.26_cuda11-archive.tar.xz
拷贝cuDNN目录下的文件到CUDAsudo cp include/cudnn* /usr/local/cuda/include sudo cp lib64/libcudnn* /usr/local/cuda/lib64 sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
#运行下面命令查看cuDNN是否安装成功
cat cudnn_version.h | grep CUDNN_MAJOR -A 2
- 安装conda
下载
wget https://repo.anaconda.com/archive/Anaconda3-2024.02-1-Linux-x86_64.sh
运行脚本
bash Anaconda3-2024.02-1-Linux-x86_64.sh
按照提示完成安装,如果环境变量文件没有则手动添加export PATH=/root/anaconda3/bin:$PATH,如果有则忽略
执行source ~/.bashrc使配置生效 - 安装docker
因为有两个服务需要使用到docker容器,所以我们需要安装docker
更新apt包
sudo apt update sudo apt upgrade -y
安装必要依赖
sudo apt install apt-transport-https ca-certificates curl software-properties-common
添加docker官方GPG秘钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
添加docker的APT源
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
更新APT包索引
sudo apt update安装docker社区版
sudo apt install docker-ce
验证docker安装
sudo systemctl status docker这里还需要安装nvidia-docker2,因为liveTalking需要使用显卡加速,否则容器启动不了
sudo apt install -y nvidia-docker2
3、部署软件
- 部署SRS服务
因为我们使用的是webrtc向srs推流模式,所以我们需要部署srs实时音视频推流服务器
export CANDIDATE='<服务器外网ip>' docker run --rm --env CANDIDATE=$CANDIDATE \ -p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp \ registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 \ objs/srs -c conf/rtc.conf
正式环境可以使用nohup命令后台运行
- 部署GPT-SoVITS
部署语音合成服务需要使用到conda创建虚拟环境
下载GPT-SoVITS项目源码https://github.com/RVC-Boss/GPT-SoVITS.git
安装依赖
conda create -n sovits python=3.9 conda activate sovits bash install.sh
下载模型文件,这里推荐先手动下载模型文件,如果通过项目启动下载可能会很慢
下载模型文件后放到GPT_SoVITS/GPT_SoVITS/pretrained_models下,大致如下
pretrained_models/ --chinese-hubert-base --chinese-roberta-wwm-ext-large --gsv-v2final-pretrained s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt s2D488k.pth s2G488k.pth启动服务
python api_v2.py
- 部署liveTalking
启动容器服务,第一次会有点慢,需要下载镜像
docker run --gpus all -it --network=host --rm registry.cn-beijing.aliyuncs.com/codewithgpu2/lipku-metahuman-stream:vjo1Y6NJ3N进入容器内部
docker exec -it <containerId> /bin/bash
在/root/metahuman-stream下,更新git,这里直接git pull拉取不了,最好外面从github上下载liveTalking源码拷贝到容器/root/metahuman-stream下
#拷贝外部文件到容器内部命令
docker cp <外部文件> <容器ID>:<容器内部路径> #然后合并文件夹 cp -r LiveTalking-main/* /root/metahuman-stream/启动服务
使用GPT-SoVITS服务的启动命令(注意:这边的REF_FILE是用来进行声音克隆的样本,存放地址如果是相对地址是相对GPT-SoVITS项目根目录的,REF_TEXT则是样本语音的文字) python app.py --transport rtcpush --push_url 'http://localhost:1985/rtc/v1/whip/?app=live&stream=livestream' --tts gpt-sovits --TTS_SERVER 'http://127.0.0.1:9880' --REF_FILE ref.wav --REF_TEXT '欢迎大家来体验达摩院推出的语音识别模型' 使用wav2lip模型 python app.py --transport rtcpush --push_url 'http://localhost:1985/rtc/v1/whip/?app=live&stream=livestream' --model wav2lip --avatar_id wav2lip_avatar2 --tts gpt-sovits --TTS_SERVER 'http://127.0.0.1:9880' --REF_FILE ref.wav --REF_TEXT '四川美食确实以辣闻名,但也有不辣的选择。比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。' 使用musetalk(三个模型对比下来这个效果最理想,支持自定义数字人形象)(推荐) python app.py --transport rtcpush --push_url 'http://localhost:1985/rtc/v1/whip/?app=live&stream=livestream' --model musetalk --avatar_id avator_4 --tts gpt-sovits --TTS_SERVER 'http://127.0.0.1:9880' --REF_FILE ref.wav --REF_TEXT '四川美食确实以辣闻名,但也有不辣的选择。比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。'
推荐使用musetalk模型。--REF_FILE:用于声音克隆的样例音频文件,--REF_TEXT:样例音频的文本信息,--push_url:srs推流服务地址
4、自定义数字人形象
以musetalk模型为例,因为该模型运行效果最好
- 首先下准备一个用于训练的视频文件,将其拷贝到liveTalking容器内部
- 进入musetalk目录
cd musetalk
- 使用样例视频训练
python simple_musetalk.py --avatar_id 4 --file <样例视频地址>
训练完后会在data目录下自动生成数字人模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号