

读《Java并发编程的艺术》(二)
上篇博客开始,我们接触了一些有关Java多线程的基本概念。这篇博客开始,我们就正式的进入了Java多线程的实战演练了。实战演练不仅仅是贴代码,也会涉及到相关概念和术语的讲解。
线程的状态
程的状态分为:新生,可运行,运行,阻塞,死亡5个状态。如下图:
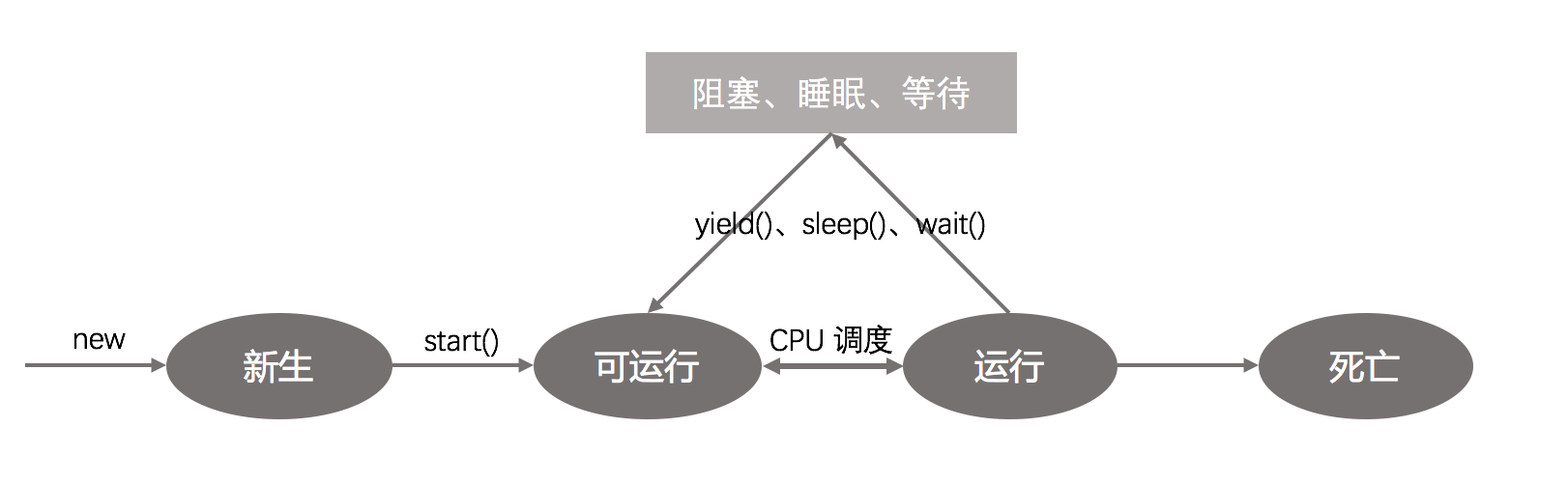
状态说明:
- 新生(new):线程对象刚创建,但尚未启动。
- 可运行(Runnable):线程创建完毕,并调用了start()方法,虽然调用了start(),但是并不一定意味着线程会立即执行,还需要CPU的时间调度。线程此时的状态就是可运行状态。
- 运行:线程等到了CPU的时间调度,此时线程状态转为运行状态。
- 阻塞(Blocked):线程由于某种原因被阻碍了,但是此时线程还处于可运行状态。调度机制可以简单的跳过它,不给它分配任何CPU时间。
其他状态比较简单,阻塞状态是其中比较有意思的。造成线程阻塞的原因有:
- 调用sleep(毫秒数),使线程进入"睡眠"状态。在规定的毫秒数内,线程不会被执行,使用sleep()使线程进入睡眠状态,但是此时并不会放弃所持有的锁,其他线程此时并不能访问被锁住的对象。sleep()可使优先级低的线程得到执行的机会,当然也可以让同优先级和高优先级的线程有执行的机会。
- 调用suspend()暂停线程的执行,除非收到resume()消息,否则不会返回"可运行"状态。强烈建议不要使用这种方式。
- 用wait()暂停了线程的执行,除非线程收到notify()或者notifyAll()消息,否则不会变成"可运行"状态。这个方法是Object类中的方法。使用wait()方法,不仅让线程休眠,同时还暂时放弃了其所持有的锁,如果需要使线程暂停休眠,可使用interrupt()方法。虽说wait()放弃了锁,但是在恢复的时候,还得把锁还回来。如何还?
- 在wait()中设置参数,比如wait(1000),以毫秒为单位,就表明只借出去1秒中,一秒钟之后,自动收回。
- 让借用的线程通知该线程,用完就还。这时,该线程马上就收锁。比如:我设了1小时之后收回,其他线程只用了半小时就完了,那怎么办呢?当然用完了就收回了,不用管我设的是多长时间。别的线程如何通知?就是上面说的使用notify()或者notifyAll()。
- 调用yield()方法(Thread类中的方法)自动放弃CPU,让给其他线程。值得注意的是,该方法虽然放弃了CPU,但是还会有机会得到执行,甚至马上。yield()只能使同优先级的线程有执行的机会。
- 线程正在等候一些IO操作。
- 线程试图调用另一个对象的"同步"方法,但那个对象处于锁定状态,暂时无法使用。
下面是一个关于使用Object类中wait()和notify()方法的例子:
1 /** 2 * @author zhouxuanyu 3 * @date 2017/05/17 4 */ 5 public class ThreadStatus { 6 7 private String flag[] = { "true" }; 8 9 public static void main(String[] args) { 10 System.out.println("main thread start..."); 11 ThreadStatus threadStatus = new ThreadStatus(); 12 WaitThread waitThread = threadStatus.new WaitThread(); 13 NotifyThread notifyThread = threadStatus.new NotifyThread(); 14 waitThread.start(); 15 notifyThread.start(); 16 } 17 18 class NotifyThread extends Thread { 19 20 @Override 21 public void run() { 22 synchronized (flag) { 23 for (int i = 0; i < 5; i++) { 24 try { 25 sleep(1000); 26 } catch (InterruptedException e) { 27 e.printStackTrace(); 28 } 29 System.out.println("NotifyThread.run()---" + i); 30 } 31 flag[0] = "false"; 32 flag.notify(); 33 } 34 } 35 } 36 37 class WaitThread extends Thread { 38 39 @Override 40 public void run() { 41 //使用flag使得线程获得锁 42 synchronized (flag) { 43 while (flag[0] != "false") { 44 System.out.println("WaitThread.run....."); 45 try { 46 flag.wait(); 47 } catch (InterruptedException e) { 48 e.printStackTrace(); 49 } 50 } 51 System.out.println("wait() end..."); 52 } 53 } 54 } 55 }
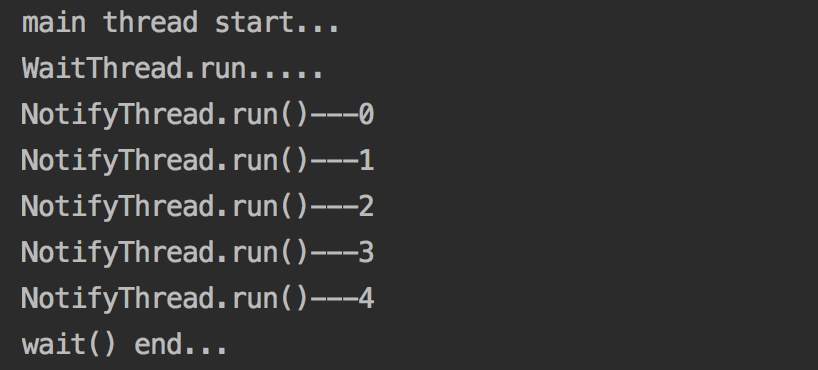
上面的代码演示了如何使用wait()和notify()方法,代码释义:主线程执行,打印出main thread start.....语句当在main()中调用waitThread.start()之后,线程启动,执行run方法并获得flag的锁,并开始执行同步代码块中的代码,接下来调用wait()方法后,waitThead阻塞并让出flag锁,此时notifyThread获得flag锁,开始执行,每隔1s打印出对应的语句,循环结束后,将flag中的标志置为false并使用notify()唤醒waitThread线程,使得waitThread线程继续执行,打印出wait() end...此时程序结束。控制台打印结果如下:
线程优先级
每个线程都有一个优先级,在线程大量被阻塞时,程序会优先选择优先级较高的线程执行。但是不代表优先级低的线程不被执行,只是机会相对较小罢。getPriority()获取线程的优先级,setPriority()设置线程的优先级。线程默认的优先级为5。
并发容器和框架
hashmap原理
都知道hashmap是线程不安全的。为什么不安全?先看下hashmap的数据结构:
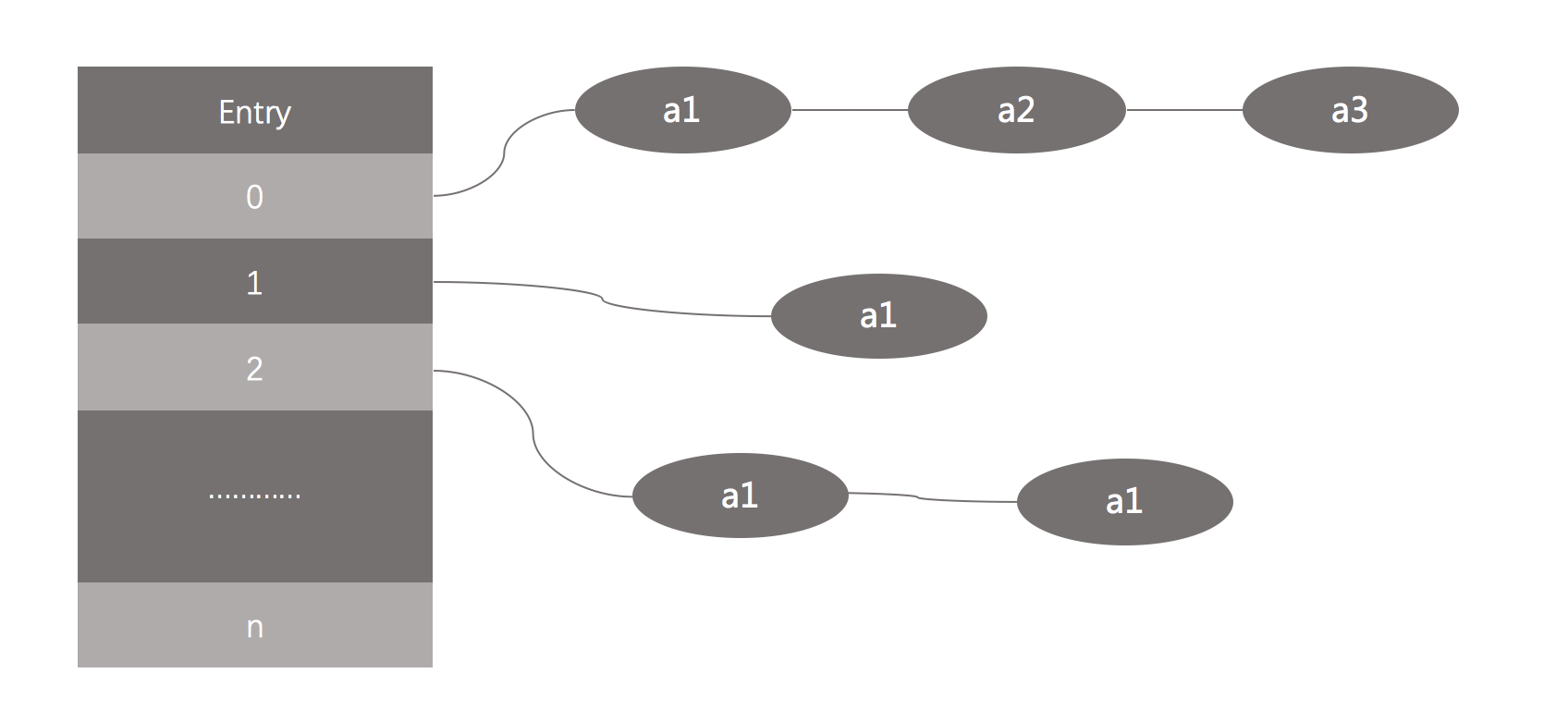
在JDK1.8之前,hashmap采用数组+链表的数据结构,如上图;而在JDK1.8时,其数据结构变为了数据+链表+红黑树。当链表长度超过8时,会自动转换为红黑树(抽时间复习红黑树,快忘记了!),提高了查找效率。当向hashmap中添加元素时,hashmap内部实现会根据key值计算其hashcode,如果hashcode值没有重复,则直接添加到下一个节点。如果hashcode重复了,则会在重复的位置,以链表的方式存储该元素。JDK1.8源码分析:
1 /** 2 * Associates the specified value with the specified key in thismap. 3 * If the map previously contained a mapping for the key, the old 4 * value is replaced. 5 * 6 */ 7 public V put(K key, V value) { 8 return putVal(hash(key), key, value, false, true); 9 } 10 static final int hash(Object key) { 11 int h; 12 //key的值为null时,hash值返回0,对应的table数组中的位置是0 13 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 14 } 15 16 /** 17 * Implements Map.put and related methods 18 * 19 * @param hash hash for key 20 * @param key the key 21 * @param value the value to put 22 * @param onlyIfAbsent if true, don't change existing value 23 * @param evict if false, the table is in creation mode. 24 * @return previous value, or null if none 25 */ 26 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 27 boolean evict) { 28 Node<K,V>[] tab; Node<K,V> p; int n, i; 29 //先将table赋给tab,判断table是否为null或大小为0,若为真,就调用resize()初始化 30 if ((tab = table) == null || (n = tab.length) == 0) 31 n = (tab = resize()).length; 32 //通过i = (n - 1) & hash得到table中的index值,若为null,则直接添加一个newNode 33 if ((p = tab[i = (n - 1) & hash]) == null) 34 tab[i] = newNode(hash, key, value, null); 35 else { 36 //执行到这里,说明发生碰撞,即tab[i]不为空,需要组成单链表或红黑树 37 Node<K,V> e; K k; 38 if (p.hash == hash && 39 ((k = p.key) == key || (key != null && key.equals(k)))) 40 //此时p指的是table[i]中存储的那个Node,如果待插入的节点中hash值和key值在p中已经存在,则将p赋给e 41 e = p; 42 //如果table数组中node类的hash、key的值与将要插入的Node的hash、key不吻合,就需要在这个node节点链表或者树节点中查找。 43 else if (p instanceof TreeNode) 44 //当p属于红黑树结构时,则按照红黑树方式插入 45 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 46 else { 47 //到这里说明碰撞的节点以单链表形式存储,for循环用来使单链表依次向后查找 48 for (int binCount = 0; ; ++binCount) { 49 //将p的下一个节点赋给e,如果为null,创建一个新节点赋给p的下一个节点 50 if ((e = p.next) == null) { 51 p.next = newNode(hash, key, value, null); 52 //如果冲突节点达到8个,调用treeifyBin(tab, hash),这个treeifyBin首先回去判断当前hash表的长度,如果不足64的话,实际上就只进行resize,扩容table,如果已经达到64,那么才会将冲突项存储结构改为红黑树。 53 54 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 55 treeifyBin(tab, hash); 56 break; 57 } 58 //如果有相同的hash和key,则退出循环 59 if (e.hash == hash && 60 ((k = e.key) == key || (key != null && key.equals(k)))) 61 break; 62 p = e;//将p调整为下一个节点 63 } 64 } 65 //若e不为null,表示已经存在与待插入节点hash、key相同的节点,hashmap后插入的key值对应的value会覆盖以前相同key值对应的value值,就是下面这块代码实现的 66 if (e != null) { // existing mapping for key 67 V oldValue = e.value; 68 //判断是否修改已插入节点的value 69 if (!onlyIfAbsent || oldValue == null) 70 e.value = value; 71 afterNodeAccess(e); 72 return oldValue; 73 } 74 } 75 ++modCount;//插入新节点后,hashmap的结构调整次数+1 76 if (++size > threshold) 77 resize();//HashMap中节点数+1,如果大于threshold,那么要进行一次扩容 78 afterNodeInsertion(evict); 79 return null; 80 }
hashmap不安全的原因:上面分析了JDK源码,知道了put方法不是同步的,如果多个线程,在某一时刻同时操作HashMap并执行put操作,而有大于两个key的hash值相同,这个时候需要解决碰撞冲突,而解决冲突的办法采用拉链法解决碰撞冲突,对于链表的结构在这里不再赘述,暂且不讨论是从链表头部插入还是从尾部插入,这个时候两个线程如果恰好都取到了对应位置的头结点e1,而最终的结果可想而知,这两个数据中势必会有一个会丢失。同理,hashmap扩容的方法也如此,当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
hashtable原理
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap登场
ConcurrentHashMap锁分段技术:HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。以下是ConcurrentHashMap的数据结构:
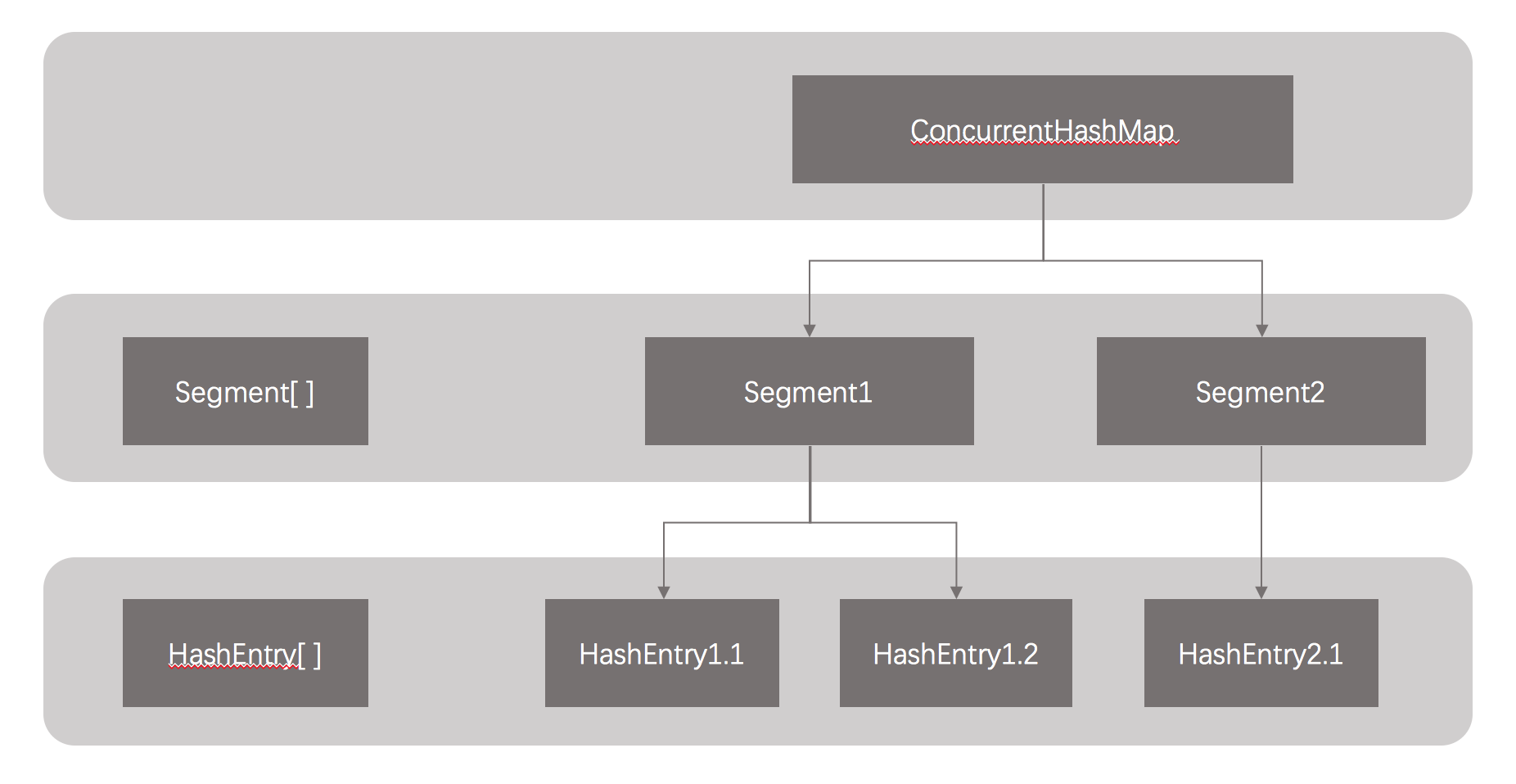
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素每Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
Fork/Join框架
什么是Fork/Join框架?
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是**一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。**Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+…+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。如图:
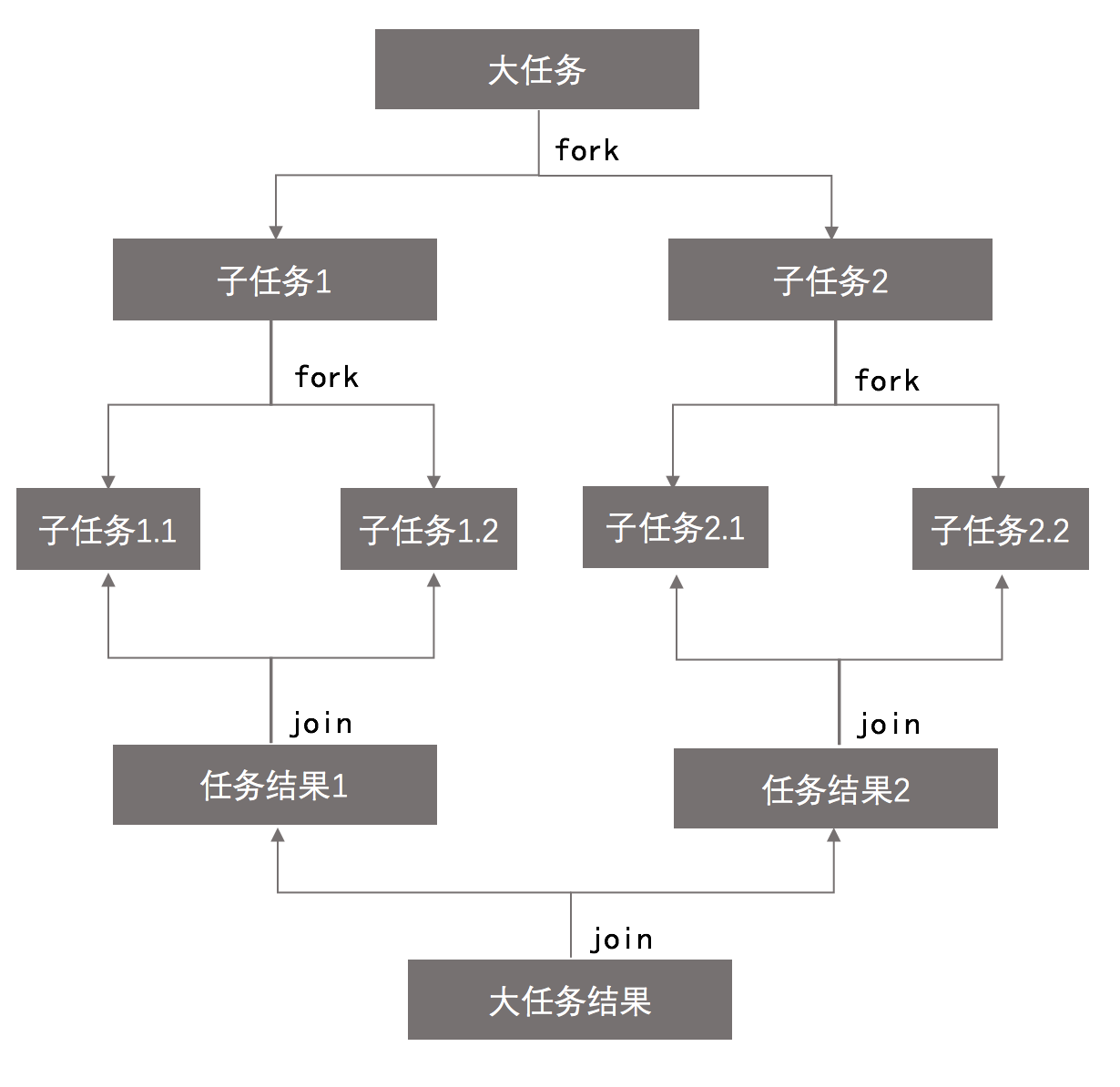
工作窃取算法
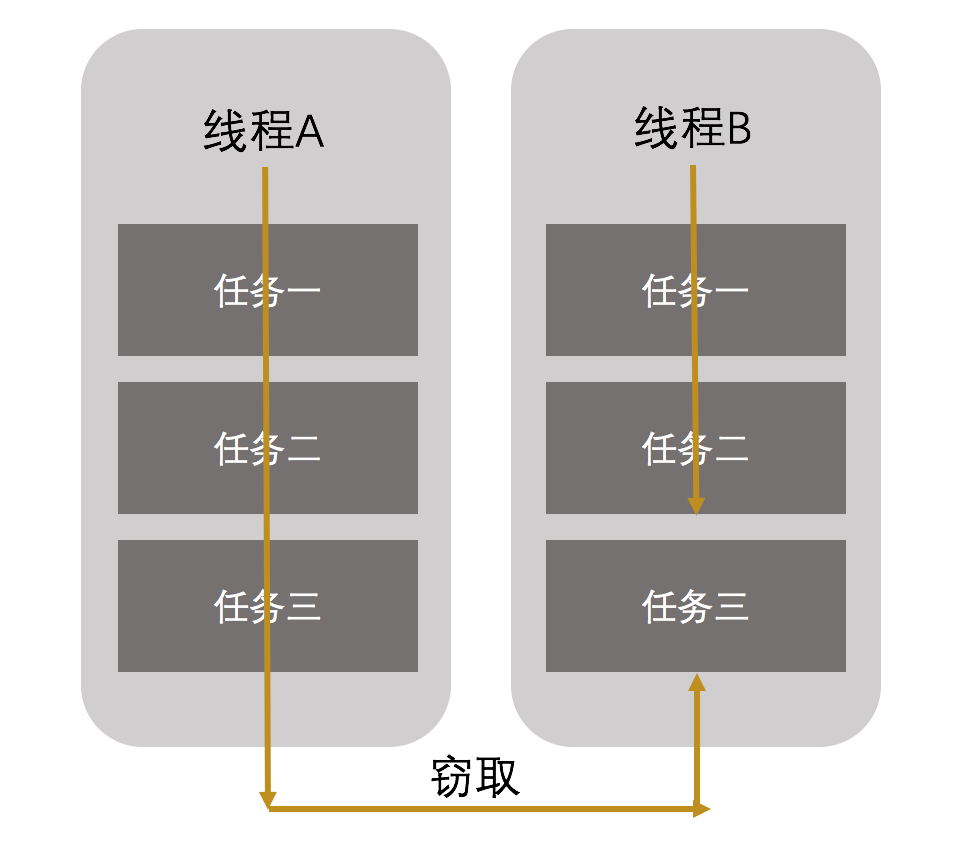
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如A线程负责处理A队列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。如下图:
该篇文章主要记录一些关于线程中锁机制的基础,以及简单分析了一下HashMap,HashTable以及ConcurrentHashMap的相关原理,文章最后简单的涉及了一下Fork-Join框架,由于本周比较忙,所以还未深入学习,下篇博客将会使用Fork-Join框架写一些demo帮助理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号