

http常见7种请求
抛砖引玉,聊下概念性的东西先:
HTTP协议 (Hyper Text Transfer Protocol)
HTTP是一个基于TCP/IP通信协议来传递数据,包括html文件、图像、结果等,即是一个客户端和服务器端请求和应答的标准。
HTTP协议特点
1.http无连接:限制每次连接只处理一个请求,服务端完成客户端的请求后,即断开连接。(传输速度快,减少不必要的连接,但也意味着每一次访问都要建立一次连接,效率降低)
2.http无状态:对于事务处理没有记忆能力。每一次请求都是独立的,不记录客户端任何行为。(优点解放服务器,但可能每次请求会传输大量重复的内容信息)
3.客户端/服务端模型:客户端支持web浏览器或其他任何客户端,服务器通常是apache或者iis等
4.简单快速
5.灵活:可以传输任何类型的数据
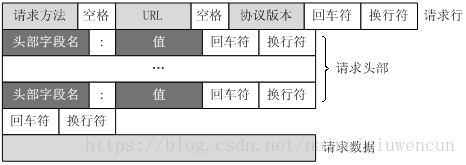
客户端请求消息
客户端发送一个请求到服务器的请求消息包括以下格式:
请求行,请求头部,空行,请求数据 (图片来自网络)
服务器响应消息
服务器响应包括如下格式:
状态行,消息报头,空行,响应正文

| 序号 | 方法 | 描述 |
| 1 | GET |
发送请求来获得服务器上的资源,请求体中不会包含请求数据,请求数据放在协议头中。另外get支持快取、缓存 、可保留书签等。幂等 |
| 2 | POST |
和get一样很常见,向服务器提交资源让服务器处理,比如提交表单、上传文件等,可能导致建立新的资源或者对 原有资源的修改。提交的资源放在请求体中。不支持快取。非幂等 |
| 3 | HEAD |
本质和get一样,但是响应中没有呈现数据,而是http的头信息,主要用来检查资源或超链接的有效性或是否可以可达、检 查网页是否被串改或更新,获取头信息等,特别适用在有限的速度和带宽下。 |
| 4 | PUT |
和post类似,html表单不支持,发送资源与服务器,并存储在服务器指定位置,要求客户端事先知 道该位置;比如post是在一个集合上(/province),而put是具体某一个资源上(/province/123)。所以put是安全的, 无论请求多少次,都是在123上更改,而post可能请求几次创建了几次资源。幂等 |
| 5 | DELETE | 请求服务器删除某资源。和put都具有破坏性,可能被防火墙拦截。如果是https协议,则无需担心。幂等 |
| 6 | CONNECT |
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。就是把服务器作为跳板,去访问其他网页 然后把数据返回回来,连接成功后,就可以正常的get、post了。 |
| 7 | OPTIONS | 获取http服务器支持的http请求方法,允许客户端查看服务器的性能,比如ajax跨域时的预检等。 |
| 8 | TRACE |
回显服务器收到的请求,主要用于测试或诊断。一般禁用,防止被恶意攻击或盗取信息。 |
GET 和 POST 比较
| GET | POST | |
| 点击返回/刷新按钮 | 没有影响 | 数据会重新提交 |
| 缓存/添加书签 | 可以 | 不可以 |
| 历史记录 | 有 | 没有 |
| 编码类型 | application/x-www-form-urlencoded |
application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用 多重编码 |
| 是否幂等 | 幂等 | 非幂等 |
| 长度限制 |
http协议没有限制,但是实际浏览器或服务 器有(最大2048) |
理论上没有,可能会收到服务器配置或内存限制 |
| 数据类型限制 | 只能ASCII,非ascii都要编码传输 | 没有限制,允许二进制数据 |
| 安全性 | 数据全部展示在url中,不安全 | 相比get,通过request body传递数据,比较安全 |
| 可见效 | 可见 | 不可见 |
注意:以上只是一种规范,如果非要给get加上request body,或者给post的url上带上参数,技术上没有任何问题。
另外曾经看到一篇文章听说『99% 的人都理解错了 HTTP 中 GET 与 POST 的区别』??说,get发送1个tcp包,而post发送两个tcp包,后来被验证这个说法是不正确的,其实get如果也发送body,则也会发送Expect:100
PATCH 和 PUT 比较
| PATCH | PUT | |
| 是否幂等 | 非幂等 | 幂等 |
| 粒度 | 局部,最小粒度,节约网络带宽 | 所有 |
注意:比如更新一个userinfo,包含name,age,sex等多个字段,如果只修改了age,如果用put来更新,则需要把其他没有变更的也要提交到服务器,但是使用patch,则只需要提交age到服务器即可。这都是协议层面来讨论的。
GET
请求示例

GET https://testrail-tools.trendmicro.com/portal/admin/getTimerInitStatus HTTP/1.1
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
Referer: https://testrail-tools.trendmicro.com/portal/admin/toLicenseTimerConfig?id=7
Accept-Language: zh-CN
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko
Host: testrail-tools.trendmicro.com
Connection: Keep-Alive
Cookie: _ga=GA1.2.1909963682.1524537669; _gid=GA1.2.563928490.1529501401
以上对应
第1行 请求行
请求方法(get)+空格+url(https://testrail-tools.trendmicro.com/portal/admin/getTimerInitStatus)+空格+协议版本(HTTP/1.1)
第2-10都是请求头部
Accept:表示客户端接受的内容类型,按照先后顺序表示客户端接收数据的先后次序
X-Requested-With:以x开头的是非http标准,一般是某种技术的出现而定义的;这里是用来判断是http请求还是ajax请求。
Referer:从这个页面访问请求行里的url
Accept-Language:客户端接受内容返回优先选择的语言
Accept-Encoding:客户端可以接受的服务器对返回内容进行编码压缩的格式。
User-Agent:客户端运行的浏览器类型信息。
Host:头域指定请求的服务器的地址和端口,HTTP/1.1必须包括Host,否则返回400
Connection:表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点, web服务器需要在返回给客户端HTTP头信息中发送一个Content-Length(返回信息正文的长度)头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然 后在正式写出内容之前计算它的大小。
Cookie:http请求时,会把保存的cookie也发送服务器。cookie是保存在客户端里的,分为内存cookie和硬盘cookie。前者随着浏览器关闭而消失,后者由过期时间或者用户手动清除。因为http请求是无状态的,所以服务器为了认证,会生成sessionid,让浏览器setcookie保存起来,每次请求携带上认证信息。这部份以后再聊吧。
响应示例
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Cache-Control: private
Expires: Wed, 31 Dec 1969 16:00:00 PST
X-Application-Context: application:prod
Content-Type: application/json;charset=UTF-8
Transfer-Encoding: chunked
Date: Wed, 20 Jun 2018 15:00:16 GMT
{"advancewarn":"1","userstatus":"1","ldap":"1","licensealarm":"1","deltempzipfile":"1","sctmlicense":"0","user":"1"}
第1行 状态行
第2-8 消息报头
Server:包含处理请求的服务器信息,包含多个产品注释和标识。
Cache-Control:告知缓存机制是否可以缓存和类型,private是只能当前用户,不能被共享。
Expires:响应过期时间
X-Application-Context:application配置,这里表示读取的是application-prod.properties
Content-Type:返回数据的类型和字符编码格式
Transfer-Encoding:告知接收端,报文采取了何种编码,chunked表示服务器无法确定消息大小,一般比如下载等,就采用chunked。
Date:返回消息的时间
第 9 行 空行
第 10 行 响应正文
消息报头指定了是返回json字符串。
POST
请求示例
POST https://testrail-tools.trendmicro.com/portal/admin/editTimer HTTP/1.1
Host: testrail-tools.trendmicro.com
Connection: keep-alive
Content-Length: 35
Accept: application/json, text/javascript, */*; q=0.01
Origin: https://testrail-tools.trendmicro.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: https://testrail-tools.trendmicro.com/portal/admin/toAdminTimerConfig?id=7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _ga=GA1.2.199305797.1501211992; _ga=GA1.1.199305797.1501211992; _gid=GA1.2.56449187.1529562439; _gat_gtag_UA_111346521_2=1
type=del&interval=1200&timelag=7200
第1行同 get
第2-13 行 请求头部
Content-Length:告知服务器,请求数据的大小
Origin:origin类似refered,但比refered更人性化,origin只出现在post中,而origin也不携带敏感信息和具体url路径。
Content-Type:http请求提交内容的编码类型,一般只有post需要设置。application/x-www-form-urlencoded(缺省)和multipart/form-data。
第14行 空行
第15行 请求数据
响应示例
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
X-Application-Context: application:prod
Content-Type: application/json;charset=UTF-8
Transfer-Encoding: chunked
Date: Thu, 21 Jun 2018 07:36:58 GMT
{"result":"edit timer success"}
其他这里就不累述了。
说了这么多,这么多请求方式都是http协议的标准,你完全可以随心所欲,全部用post或者全部用get,但是你要是开发的是商业产品,那你就要为你自己的随便买单咯。
好比删除一样东西,如果用get请求方式:http:/xxx/delete?id=1,那你很快就知道,这些标准也能让其他人一眼就能知道具体所要做的意思。
HTTP状态码
摘自HTTP状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols |
切换协议。服务器根据客户端的请求切换协议。只能切换到 更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information |
非授权信息。请求成功。但返回的meta信息不在原始的服务器 ,而是一个副本 |
| 204 | No Content |
无内容。服务器成功处理,但未返回内容。在未更新网页 的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content |
重置内容。服务器处理成功,用户终端(例如:浏览器)应重 置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices |
多种选择。请求的资源可包括多个位置,相应可返回一个 资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently |
永久移动。请求的资源已被永久的移动到新URI,返回信息 会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求 都应使用新的URI代替 |
| 302 | Found |
临时移动。与301类似。但资源只是临时被移动。客户端应继 使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified |
未修改。所请求的资源未修改,服务器返回此状态码时,不会 返回任何源。客户端通常会缓存访问过的资源,通过提供一个头 信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found |
服务器无法根据客户端的请求找到资源(网页)。通过此代 码,网站设计人员可设置"您所请求的资源无法找到"的个性 页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required |
请求要求代理的身份认证,与401类似,但请求者应当使用代 理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict |
服务器完成客户端的PUT请求是可能返回此代码,服务器处理 请求时发生了冲突 |
| 410 | Gone |
客户端请求的资源已经不存在。410不同于404,如果资源以前有 现在被永久删除了可使用410代码,网站设计人员可通过301代码 指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large |
由于请求的实体过大,服务器无法处理,因此拒绝请求。为防 止客户端的连续请求,服务器可能会关闭连接。如果只 是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求 |
| 503 | Service Unavailable |
由于超载或系统维护,服务器暂时的无法处理客户端的请求 。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
结束语:其实我们大部分情况下只用到了GET和POST。如果想设计一个符合RESTful规范的web应用程序,则这六种方法都会用到。不过即使暂时不想涉及REST,
了解这六种方法的本质仍然是很有作用的。大家将会发现,原来web也是很简洁明了的。下面再次依次说明这六种方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号