


我也是刚刚开始学习爬虫,写博客的意思就是在学习中记下笔记,以及遇到的坑,尽量让能读到文章的人跳过这些坑!!
网络爬虫类型:

1,通用性爬虫(百度,啥搜索引擎使用的。返回一堆不相关的网页;他的目标就是尽可能增大网络覆盖率,基于关键字搜索)
2,聚焦网络爬虫
3,增量式网络爬虫
4,深层网络爬虫
举个栗子:
如上图:宅男们寻求片的地址,找bt资源之类的地方
比如爬虫下来百度网盘资源共享的
学爬虫大杀器就是scrapy,今天先看下安装,真的他妈的好坑爹啊
Windows安装:
1、pip3 install wheel
2、pip3 install lxml
3、pip3 install pyopenssl
4、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
5、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted(cp代表python的版本)
6、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
7、pip3 install scrapy
其他:
pip3 install scrapy
因为本人有些强迫症,所以我必须把东西给弄全了
安装scrapy-splash
这个东西是一个scrapy支持JavaScript渲染的工具
安装氛围两部分:
1,在docker的安装,安装之后启动sqlash的服务,就可以通过他的接口实现JS页面的加载。另外一个就是scrapy-splash的python库的安装,安装之后即可在scrapy中使用sqlash的服务。
还是那句话,要学就学好了。
安装scrapy-redis模块,以方便后期分布式爬虫的搭建。
如果想要大规模的抓取数据的话,一定会用到分布式爬虫,对于分步实施爬虫来讲,我们需要多台主机,每台主机有多个爬虫的任务。但是源代码只有一份,那么此时就需要我们将源码部署到多台主机上面协同运行。
咋部署?
………………………………………………………………………………………………………………………………………………………………………………………………………………
1,scrapy有一个扩展的组件,叫做scrapyd,我们只需安装该扩展组件,即可远程管理scrapy任务。包括部署源码、启动任务、监听任务等等。另外呢,还有scrapyd-Client和Scrapy API来帮助我们更加方便的完成部署和监听操作。
, 2,通过Docker集群部署,我们只需要将爬虫制作为Docker镜像,只需要主机安装了Docker,就可以直接运行爬虫,无需担心环境配置和版本等一系列的问题。(推荐!)
###补充说明###
Docker是一种容器技术,可以将应用和环境进行打包,形成一个独立的,类似于APP形式的应用。,这个应用可以直接被分发到任一个支持Docker'的环境当中,通过简单的命令就可以启动运行。
Docker是当前最为流行的容器化实施方案。和虚拟机的技术类似,但是又与之不同
Docker相比虚拟技术,更轻量实现了应用服务的打包。使用Docker可以让每一个应用之间相互隔离。可以在一台机器上同时运行多个应用,不过他们一起共享一个操作系统。
Docker的优势在于,他可以在更加细的粒度上进行资源管理。也比虚拟化技术更加节省资源。
对于爬虫来讲:需要大规模进行部署爬虫系统的话一定要使用Docker,所谓工欲善其事,必先利其器!
Windows安装:https://docs.docker.com/toolbox/toolbox_install_windows/(推荐是win10)
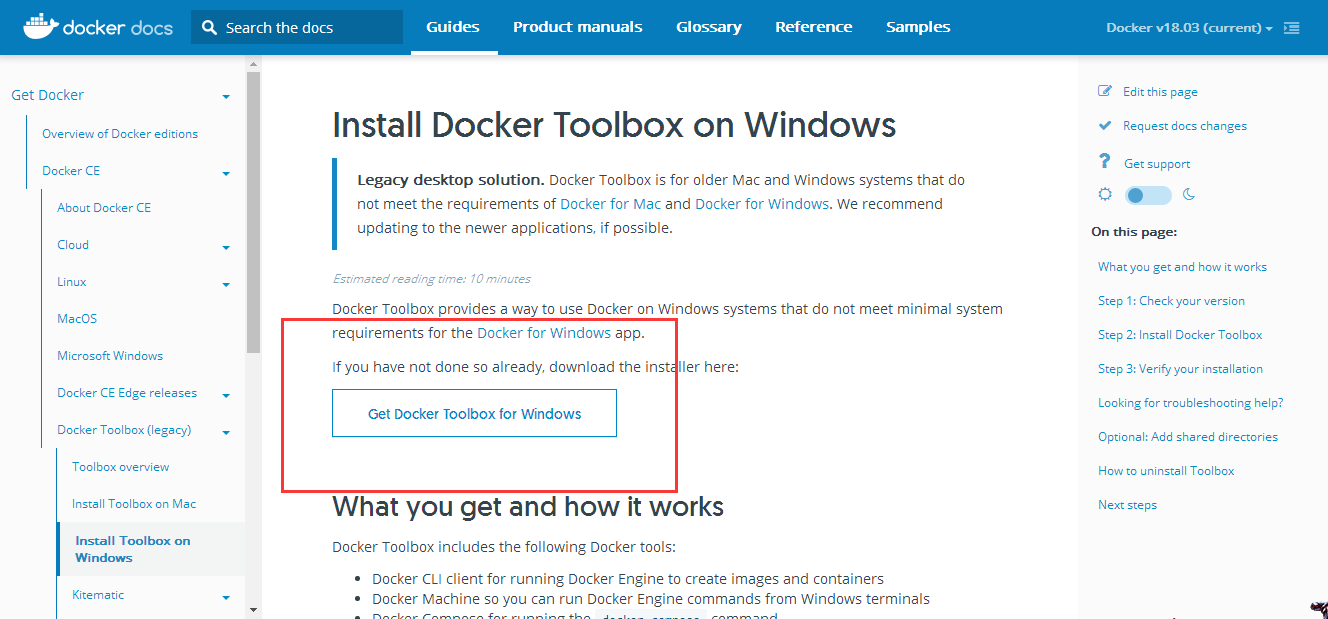
下载下一步下一步就可以了。
测试是否安装好了。
在cmd中输入命令docker
看到以下界面那么小伙子,你就安装成功了!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号