MySql常见优化收集(一)
MySql常见优化收集(一)
1.建表
1.1表结构
CREATE TABLE `t` (
`id` bigint NOT NULL AUTO_INCREMENT,
`mobile` bigint DEFAULT NULL,
`PASSWORD` varchar(64) COLLATE utf8mb4_general_ci DEFAULT NULL,
`username` varchar(64) COLLATE utf8mb4_general_ci DEFAULT NULL,
`sex` tinyint NOT NULL DEFAULT '1',
`birthday` datetime DEFAULT NULL,
`amount` decimal(18,2) DEFAULT NULL,
`ismaster` tinyint(1) DEFAULT NULL,
`istest` bit(1) DEFAULT NULL,
`updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
总共有100w条数据
1.2数据库信息
| VERSION() |
|---|
| 8.0.25-0ubuntu0.20.04.1 |
1.3服务器信息
model name : Intel® Xeon® Platinum 8269CY CPU @ 2.50GHz
cpu MHz : 2500.002
cache size : 36608 KB
cpu cores : 1
apicid : 1
initial apicid : 1
2.limit分页常见优化
2.1普通写法
select * from t limit 990000,10;
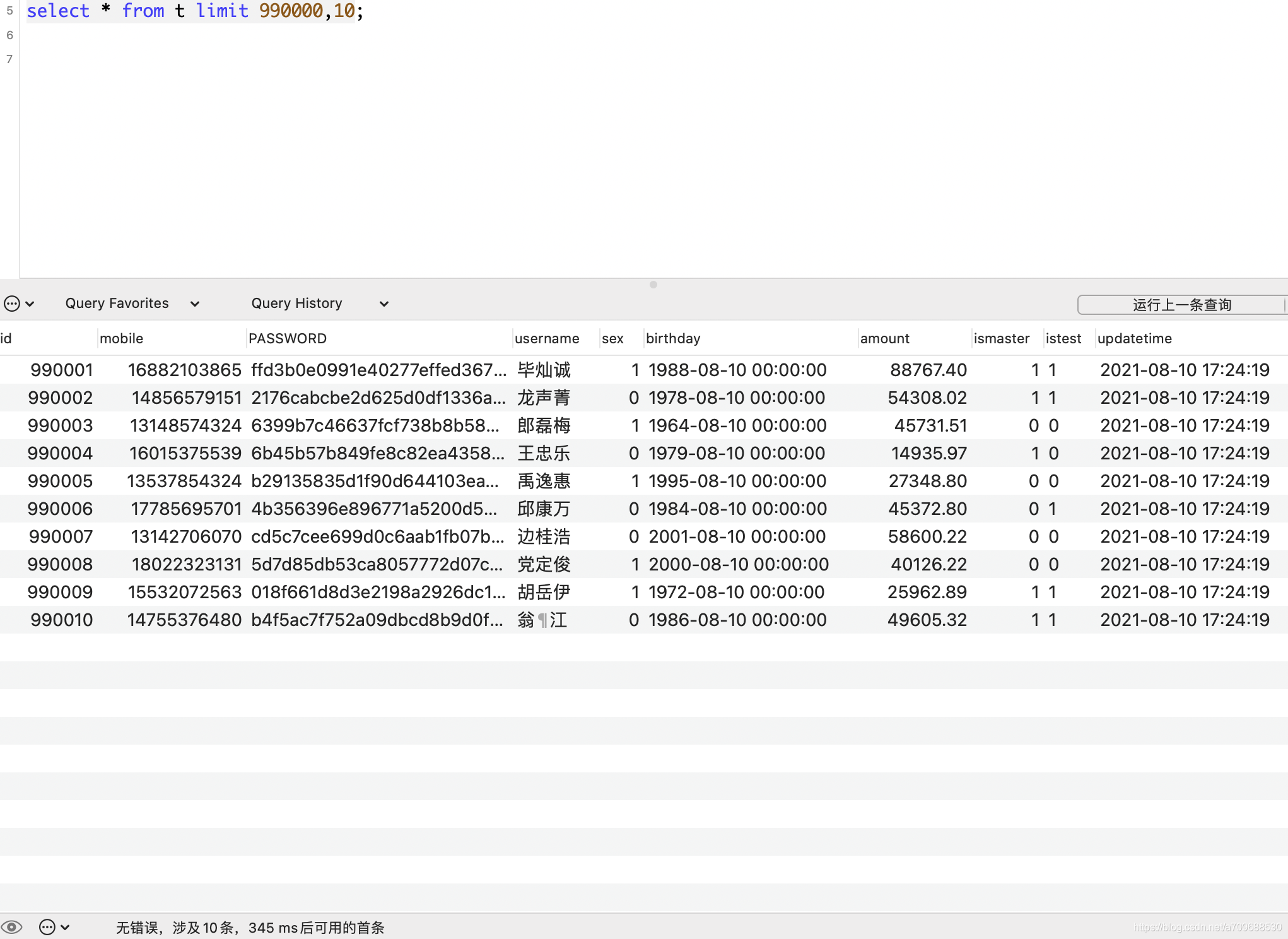
大概需要花费350ms左右
2.2通过递增的id优化后
select * from t where id>=900000 limit 10

查询花费大概26ms,提升了大概10倍的速度;
当然了,这种写法可能在一些情况下不适合,如:
- 表中不存在递增的字段
- 表中递增的字段非连续,(比如说删掉了其中几条数据)。
2.3解决id递增不连续的分页(一)
select * from t where id >= (select id from t limit 900000,1) limit 10

耗时140ms,大概是之前的一半
2.4解决id递增不连续的分页(二)
select * from t t1 join (select id from t t2 limit 900000,10) t3 on t1.id = t3.id

后续待定…😁
本文来自博客园,作者:zhooke,转载请注明原文链接:https://www.cnblogs.com/zhooke/p/15399358.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号