
Java容器-常用知识点
一、Java容器分类
- IteRator
- ListIterator
- Collection
- List
- ArrayList
- LinkedList
- Vector(线程安全)
- Stack(线程安全)
- Set
- HashSet
- LinkedHashSet
- TreeSet
- List
- Map
- HashMap
- LinkedHashMap
- TreeMap
- ConcurrentHashMap(线程安全)
- Hashtable(线程安全)
二、常用知识点
1、第一层级
1.1 迭代器 Iterator 是什么?
是一种设计模式,是一个对象,可以遍历并选择序列中的对象。
1.2 Iterator 怎么使用?有什么特点?
特点:单向移动,安全(在遍历时如果容器内内容更改将会抛出ConcurrentModificationException异常),常用方法:next(),hasNext(),remove()
使用(用于遍历):
//while循环遍历 Collection coll = new ArrayList(); coll.add("abc"); coll.add("def"); Iterator it = coll.iterator(); while(it.hasNext()){ System.out.println(it.next()); } //for循环遍历 Collection coll = new ArrayList(); coll.add("abc"); coll.add("def"); for(Iterator it = coll.iterator();it.hasNext();){ System.out.println(it.next()); } //PS:建议使用for循环实现迭代,因为while循环中,it是在while循环体外创建的,因此while循环结束后,it仍然在内存中占据着一定的空间。
而使用for循环,在循环结束后,it的生命周期也会随之结束。
//注意:循环map时it.next()取的是key
1.3 Iterator 和 ListIterator 有什么区别?
(1)遍历对象:Iterator能遍历set、list、map,ListIterator只能遍历List
(2)遍历方向:Iterator单向,ListIterator双向
(3)方法:ListIterator实现了Iterator接口,并包含其他的功能,如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
2、第二层级
2.1 Collection 和 Collections 有什么区别?
Collection:接口集合,可被实例化,含set、list等
Collections:工具类,不可实例化,含各种操作集合的静态方法,如sort(),reverse(),copy(),binarySearch()等
3、第三、四层级
3.1 list、map和set的区别
主要从有序性和重复性进行区分,详见以前文章《浅谈SET,LIST和MAP》
3.2 HashMap 和 Hashtable 有什么区别?
(1)存储:hashMap允许key和value为null,hashtable不允许
(2)效率:hashTable同步的;而HashMap是非同步的,效率上比hashTable要高
(3)使用:hashtable注释可以看到为保留类,不建议使用。
单线程:hashMap
多线程:concurrentHashMap
3.3 如何决定使用 HashMap 还是 TreeMap?
首选hashMap,插入删除定位元素较快;
若业务需要有序遍历则treeMap。
3.4 各种集合类的实现原理
3.5 ArrayList 和 LinkedList 的区别是什么?
(1)数据结构:ArrayList为动态数组,LinkedList为双向链表
(2)效率:随机访问ArrayList效率高,在非首尾增删元素LinkedList效率高
(3)使用:频繁查找用ArrayList,频繁增删用LinkedList
3.6 Array与List间的转化
Array -> List:Arrays.asList()
List - > Array:ArrayList.toArray()
3.7 Array 和 ArrayList 有何区别?
(1)存储对象:Array支持基本数据类型和对象,ArrayList仅支持对象
(2)大小:Array固定长度,ArrayList动态扩展
(3)方法:ArrayList更多,如addAll(),removeAll()等
3.8 ArrayList 和 Vector 的区别是什么?
(1)线程安全:vector线程安全,ArrayList非线程安全的
(2)性能:vector是同步的,ArrayList不是;ArrayList性能总体更好
(3)扩容:都会动态扩容,vector每次扩一倍,ArrayList扩50%
3.9 在 Queue 中 poll()和 remove()有什么区别?
相同:都是从队列中取出第一个元素,并删除返回的对象
不同:poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常
3.10 怎么确保一个集合不能被修改?
可以用unmodifiableCollection(Collection c)封装成只读集合,例:
List<String> list = new ArrayList<>(); list.add("123"); Collection<String> co = Collection.unmodifiableCollection(list); co.add("456");//此处会抛异常,不允许修改
三、HashMap
1、JDK1.7和1.8的区别
(1)数据结构
1.7:数组+链表
1.8:数组+链表+红黑树(时间复杂度O(logn);转化为红黑树的阈值为8,原因是符合泊松分布;)
(2)插值方法
1.7:头插
1.8:尾插
(3)扩容方法
1.7:插入前扩容;扩容后顺序颠倒;
1.8:插入后扩容;扩容后顺序不变;
2.key和value特点
1.都允许为null。不过key只允许一次,对于的hashcode为0;value允许多个null。
2.string和integer可以作为key(为final类型,具有)
3.存取原理
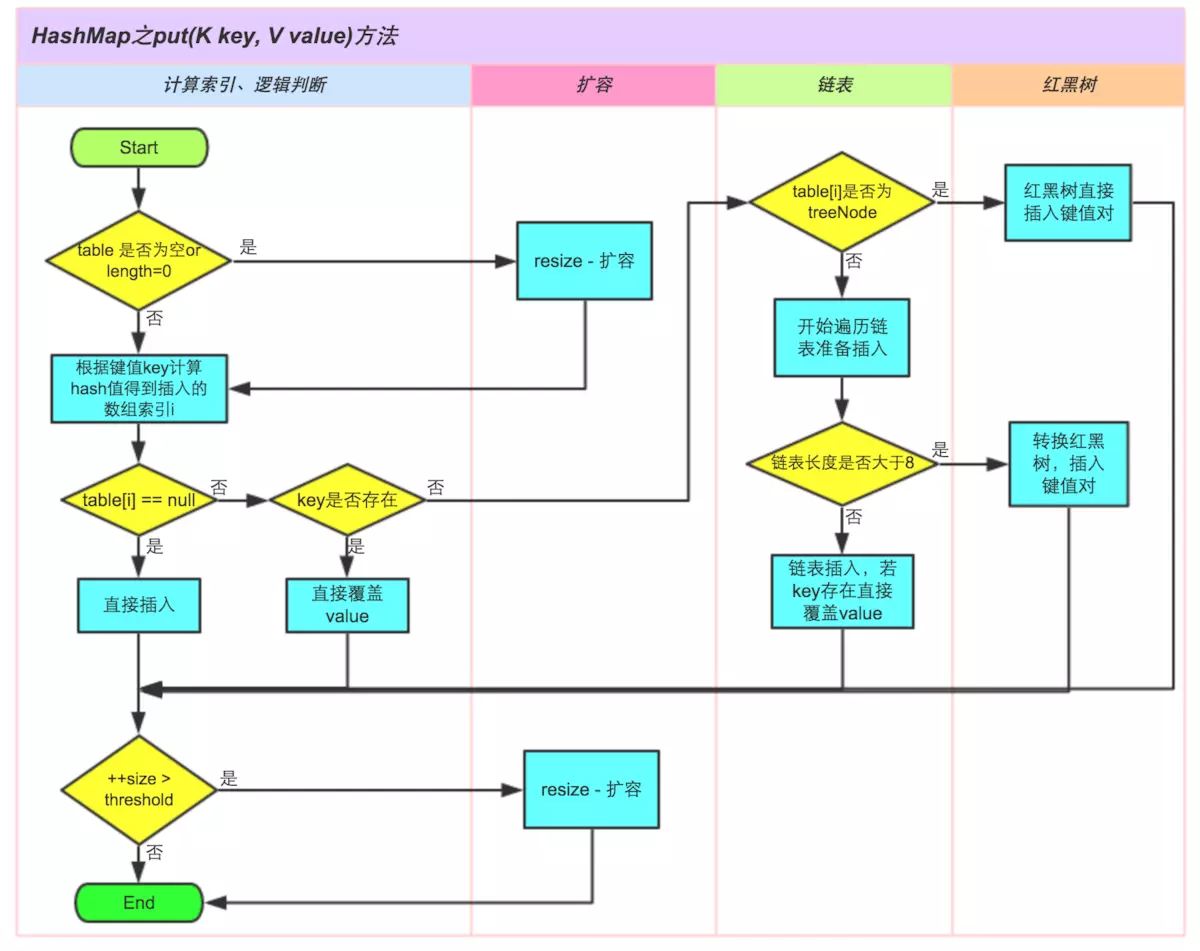
4.线程不安全原因
Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
但是即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
5.默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
(1)默认长度16,太大浪费空间,太小频繁扩容
(2)原因:使存储高效,尽量减少hash碰撞,在((n-1)&hash) 求索引的时候更均匀
深入:计算buckets桶位置的时候,公式为((n-1) & hash),2的幂减去1的数的二进制数的结尾都是1,与hash值进行与运算,会得到其余数。进行按位与操作,使得结果剩下的值为对象的hash值的末尾几位,这样就我们只要保证对象的hash值生成足够散列即可
6.扩容方式?负载因子是多少?为什是这么多?
加载因子设置为0.75而不是1,是因为设置过大,桶中键值对碰撞的几率就会越大,同一个桶位置可能会存放好几个value值,这样就会增加搜索的时间,性能下降,设置过小也不合适,如果是0.1,那么10个桶,threshold为1,你放两个键值对就要扩容,太浪费空间了。
7.HashMap是怎么处理hash碰撞的
也就是说hash重复了怎么办?如果key也重复,则直接替换最小值;key不同则加到链表后面,如果链表长度到达8且数组的长度大于64时,则将链表转为红黑树,如果数组长度小于64,则是进行扩容
8.hash计算规则
(1)通过hashcode()获取hash1
(2)hash1右移16位,得到hash2
(3)hash1与hash2做异或得到hash3
(4)(n-1)&hash3得到桶位置
9.为什么不直接将key作为哈希值而是与高16位做异或运算?
因为数组位置的确定用的是与运算,仅仅最后四位有效,设计者将key的哈希值与高16为做异或运算使得在做&运算确定数组的插入位置时,此时的低位实际是高位与低位的结合,增加了随机性,减少了哈希碰撞的次数。
10.如果两个键的hashcode相同,你如何获取值对象
用equals()比较值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号