
SqlServer 中字符串 Split 的新用法
1. 网上介绍的文章对于旧版的 sql split 均是用 patindex 或 CHARINDEX 等函数来查找分隔字符来实现。
create function f_splitStrByCharIndex (@input varchar(100))
returns @result table (str varchar(100)) as
begin
-- 1. 对于老的SQL数据库,基本上所有的网络上的文章采用的方式,都是类似于下面的用 patindex 或 charindex 函数
declare @pos int
SELECT @pos = CHARINDEX(',',@input)
while (@pos>0 and @pos<len(@input))
begin
insert into @result(str)
select substring(@input, 0, @pos)
SELECT @input = substring(@input, @pos + 1, len(@input))
SELECT @pos = CHARINDEX(',',@input)
end
insert into @result(str)
select @input
return
end
2. 对于新版本的sqlserver数据库,可以直接用 openjson
核心语句是:SELECT [value] from OPENJSON('[1,2,3,4,5]')
-- 2. json 方式
insert into @result (str) SELECT [value] from OPENJSON('['+@input+']')
3. 对于老版本的 sql server 其实也有其它办法:
declare @sql nvarchar(max)
select @sql = 'select ''' + replace('1,2,3,4,5', ',',''' union all select ''') + ''''
insert into @tb3(str)
exec sys.sp_executesql @sql
效率比较:
declare @dt1 datetime,
@dt2 datetime,
@dt3 datetime,
@dt4 datetime
declare @tb1 table (str varchar(100))
declare @tb2 table (str varchar(100))
declare @tb3 table (str varchar(100))
declare @c1 int,
@c2 int,
@c3 int
select @c1 = 0, @c2 = 0, @c3 = 0
select @dt1 = getdate()
while @c1 < 1000
begin
insert into @tb1(str)
select *
from dbo.f_splitStrByCharIndex('1,2,3,4,5')
select @c1 = @c1 + 1
end
select @dt2 = getdate()
while @c2 < 1000
begin
insert into @tb2(str)
SELECT [value] from OPENJSON('['+'1,2,3,4,5'+']')
select @c2 = @c2 + 1
end
select @dt3 = getdate()
while @c3 < 1000
begin
declare @sql nvarchar(max)
select @sql = 'select ''' + replace('1,2,3,4,5', ',',''' union all select ''') + ''''
insert into @tb3(str)
exec sys.sp_executesql @sql
select @c3 = @c3 + 1
end
select @dt4 = getdate()
select (select count(1) from @tb1),
(select count(1) from @tb2),
(select count(1) from @tb3),
datediff(ms, @dt1, @dt2),
datediff(ms, @dt2, @dt3),
datediff(ms, @dt3, @dt4)
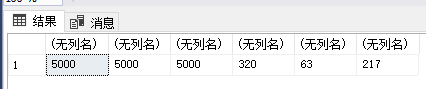



个人强烈推荐升级数据库,使用 json 的方式。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号