
手写-- K-means++
1. K-means++原理
K均值聚类属于启发式方法,不能保证收敛到全局最优,初始中心的选择会直接影响聚类结果。K-means是随机选择样本点作为聚类中心,容易造成算法局部收敛或者需要较多迭代次数,而K-means++将初始点的选择转化为概率问题,容易得到更好的初始聚类中心,加速算法收敛。下图是算法的步骤,转载自Yixuan-Xu的博客,有兴趣了解K-means算法的小伙伴可以进传送门看一看。


2.算法实现
- 利用sklearn的数据库生成数据集
# make datasets X,y=datasets.make_blobs(n_samples=500,n_features=2,centers=3,cluster_std=1.2,center_box=(-5,10))
- 初始化K个聚类中心点
def center_select(X,y,k): ''' 初始化聚类中心点 Parameters ------------------ :param X: 数据集 :param y: 显示原始数据集不同团簇之间的颜色 :param k: 将数据集分成K类 Return ------------------ return X[centers_index,:]: 初始化的中心点坐标 ''' if k<2 or k>len(X): print('k should be more than 1 and less than len(X)') return k centers_index=[] for i in range(k): if i==0: first_index=int(np.random.random()*len(X)) centers_index.append(first_index) else: res=np.zeros(len(X)) for j in centers_index: sub=np.square(X-X[j,:]) distance=np.sum(sub,axis=1) res+=distance proba=np.cumsum(res/np.sum(res)) # Roulette selection val=np.random.random() for m,k in enumerate(proba): if val<k: centers_index.append(m) break return X[centers_index,:]
- 聚类迭代
def k_mean(X,y,k,iter=1000): ''' K-means++迭代更新 Parameters ------------------ :param X: 数据集 :param y: 显示原始数据集不同团簇之间的颜色 :param k: 将数据集分成K类 :param iter: 迭代次数 Return ------------------ return center: 迭代后的聚类中心点坐标 ''' center=center_select(X,y,k) X_label=np.insert(X,X.shape[1],-1,axis=1) # show begin plt.scatter(X[:,0],X[:,1],c=y) plt.scatter(center[:,0],center[:,1],marker='+',c='red',s=500) # iteration for i in range(iter): dis_res=np.zeros((len(X),k)) for j in range(k): sub=np.square(X-center[j,:]) distance=np.sum(sub,axis=1) dis_res[:,j]=distance label=np.argmin(dis_res,axis=1) X_label[:,-1]=label # update center for m in range(k): cache=X[X_label[:,-1]==m] center[m,:]=np.sum(cache,axis=0)/len(cache) # show result plt.figure() plt.scatter(X[:,0],X[:,1],c=y) plt.scatter(center[:,0],center[:,1],marker='+',c='red',s=500) return center
- 调用迭代函数
# cluster center=k_mean(X,y,3,iter=1000)
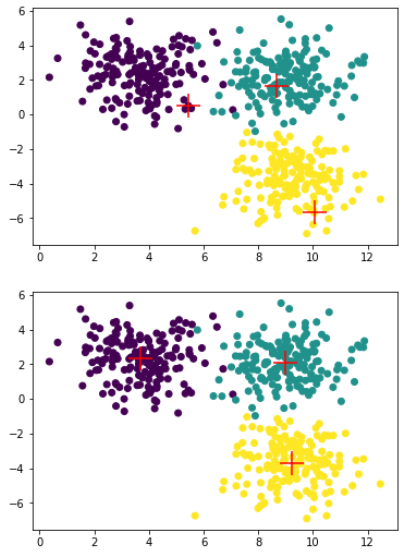
- 输出初始聚类中心与迭代结束后聚类中心图像

 浙公网安备 33010602011771号
浙公网安备 33010602011771号