

HashSet集合--java进阶day11
1.HashSet

HashSet具备去重的功能,但不具备排序
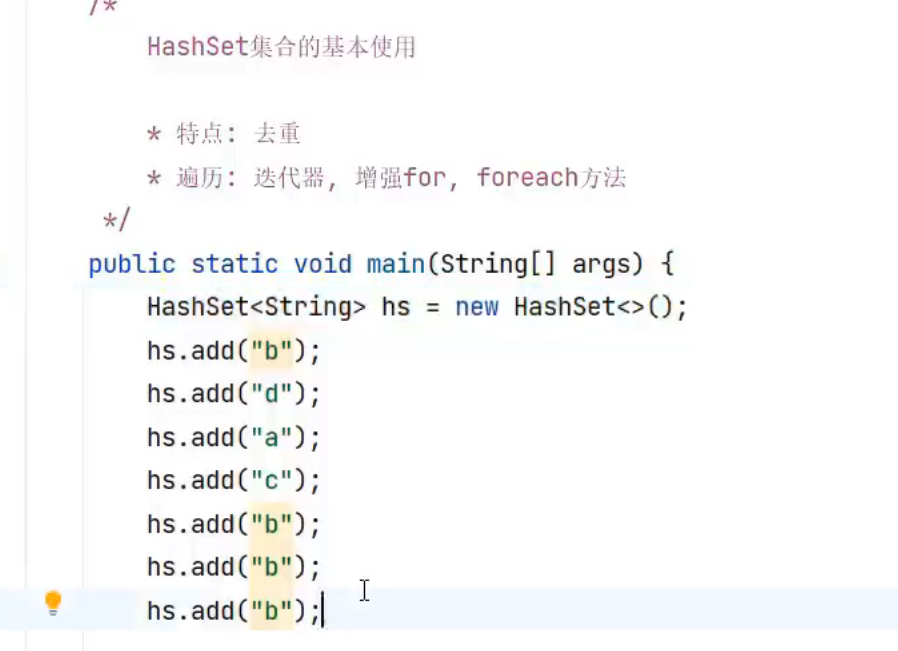
..
可以看见,多次添加的元素都没有被打印

2.HashSet的使用
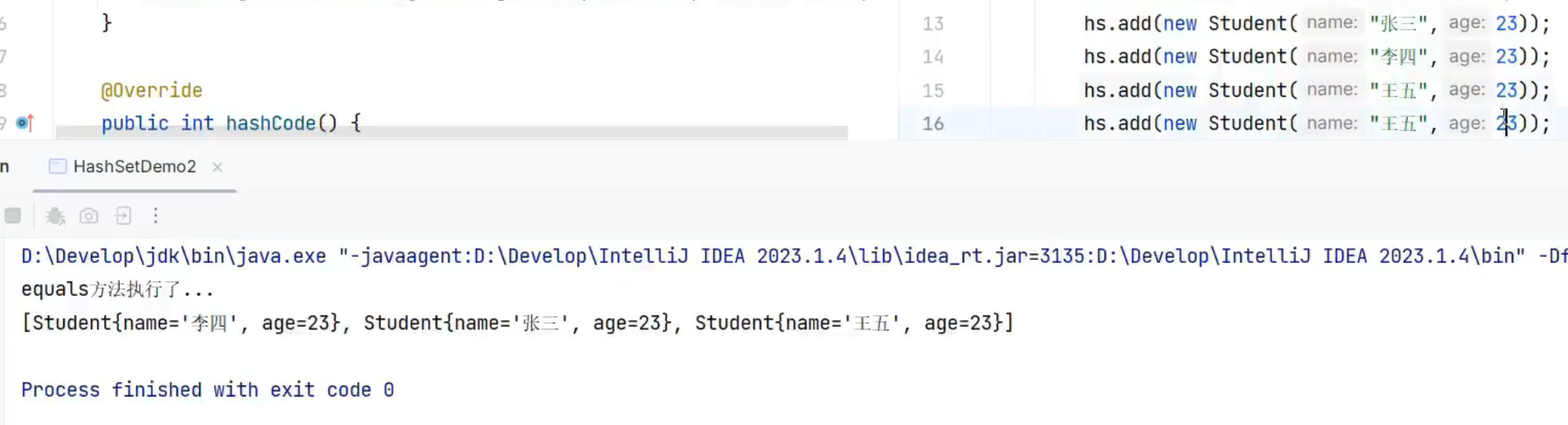
HashSet必须重写hashcode和equals方法,二者少了其一都无法正常使用HashSet

刚才我们使用的是String泛型进行演示,这是java写好的类,无法看出HashSet的本质,这里我们编写一个学生类进行演示
[1]hashcode和equals方法都未重写时,无去重功能

[2]hashcode未重写时,依旧无去重功能
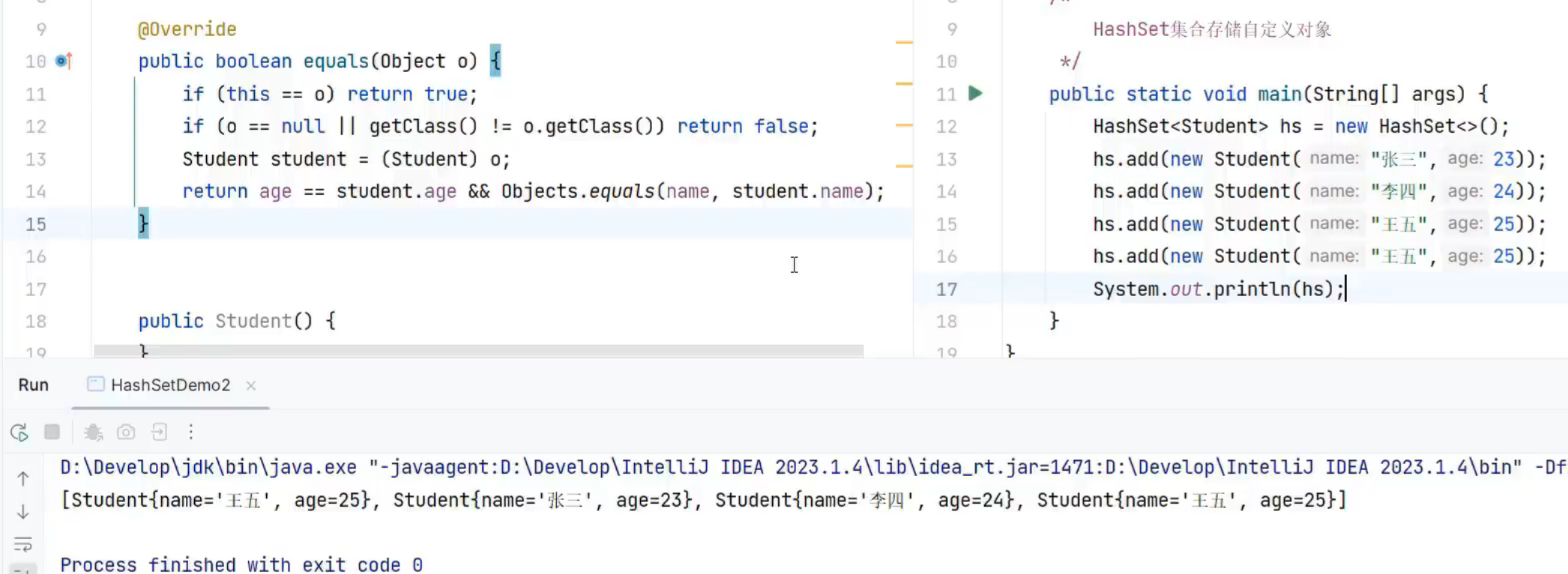
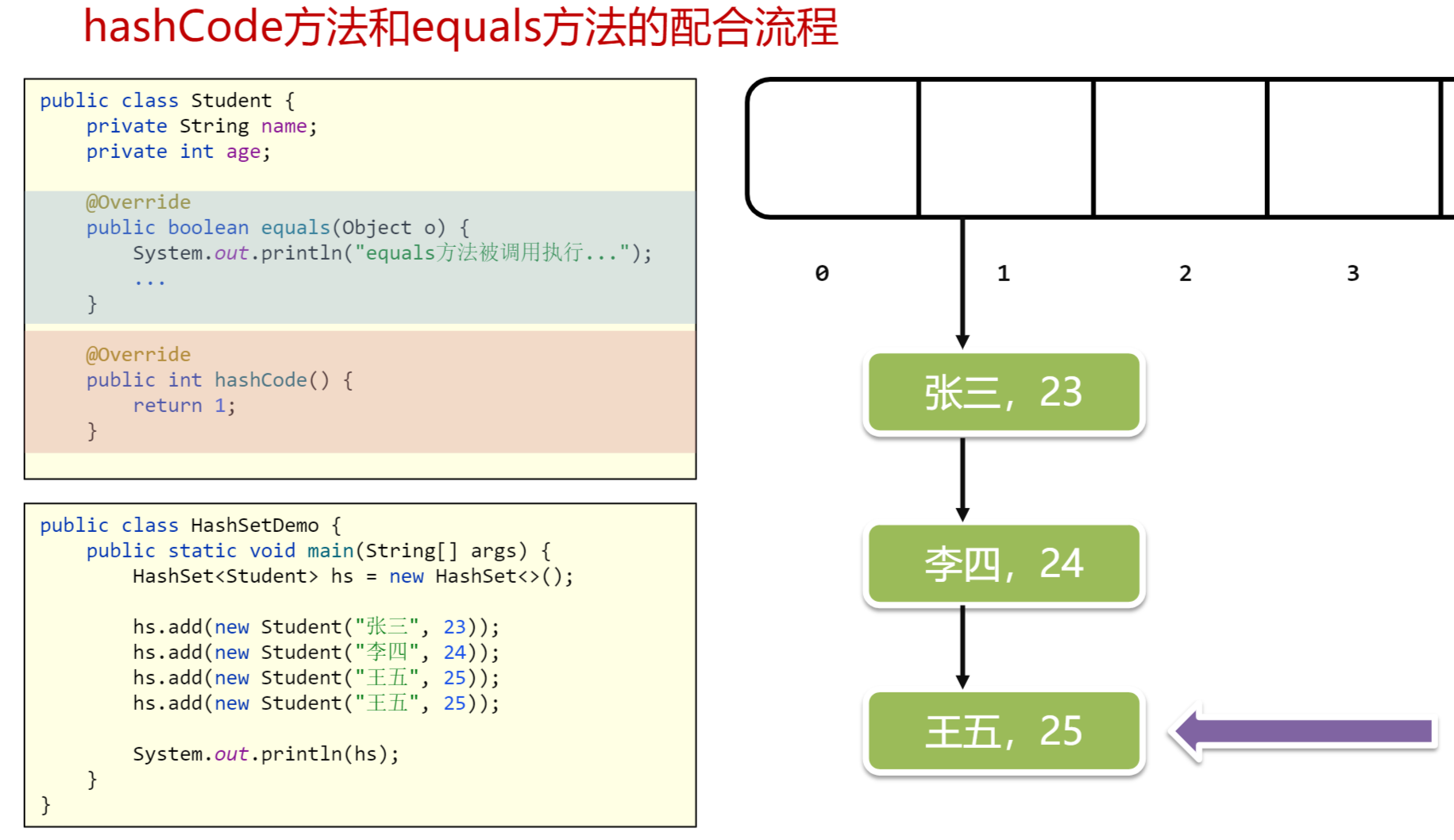
[3]hashcode和equals全部重写,王五被去重

3.HashSet内部简聊
HashSet的数据结构是哈希表

红黑树在最后讲解,我们先看哈希表中数组加链表的结构
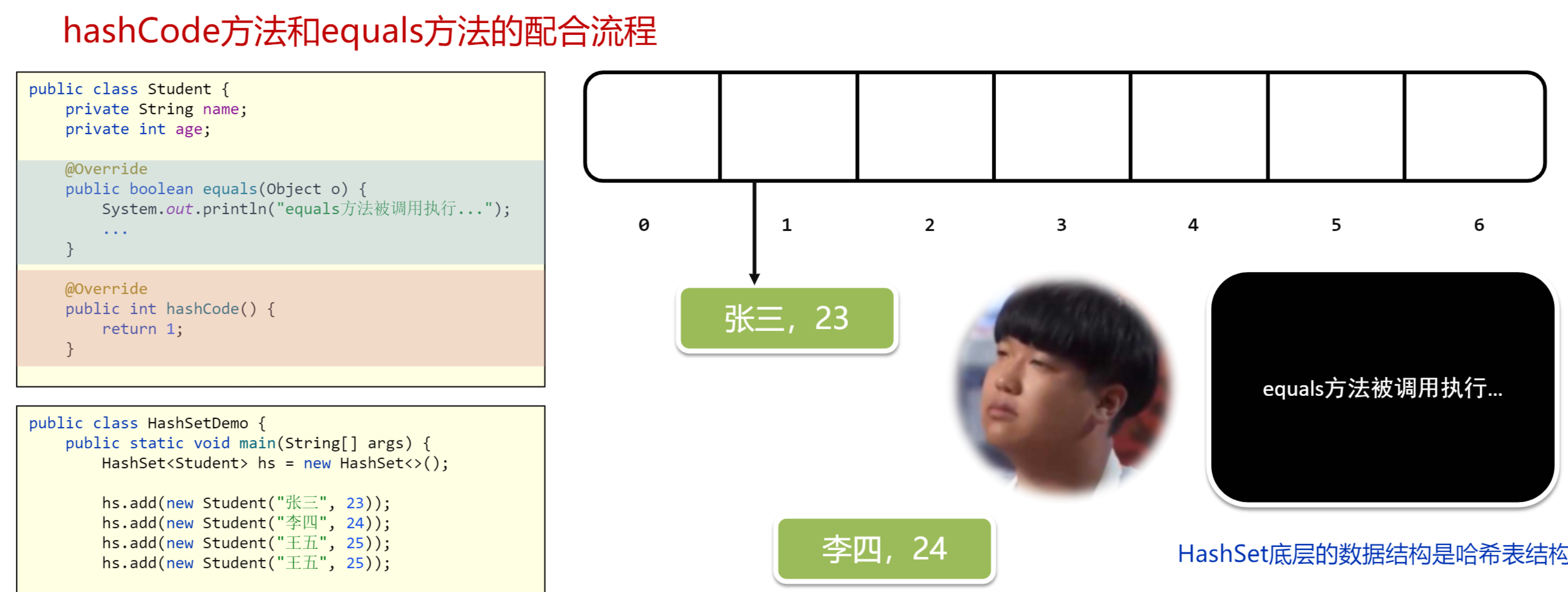
当我们创建了HashSet集合后,就会产生哈希表,哈希表最初的样子就是一个数组

当我们往集合中添加张三时,它会自带调用对象的hashcode方法
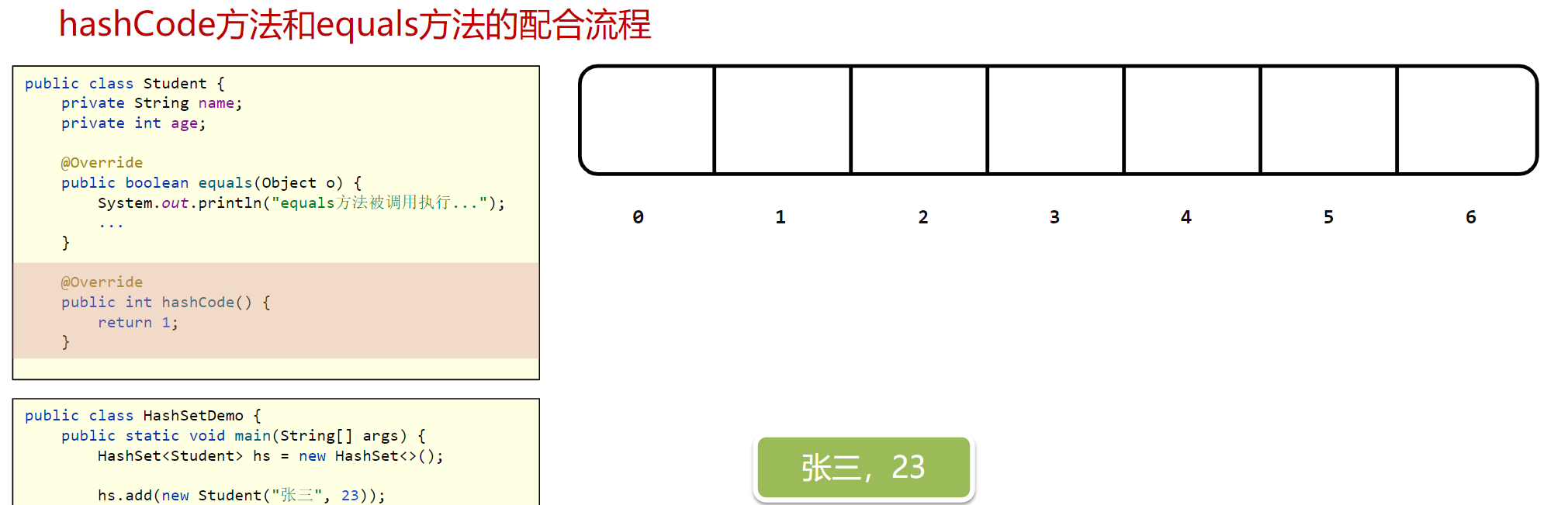
hashcode返回的值,可以看成是坐火车时的座位号,张三拿着1号,看见座位上没有人,就坐上去了(将张三存入1号索引位置)
张三的存入方式不是直接存进去,而是形成一个链表将张三挂在1号索引
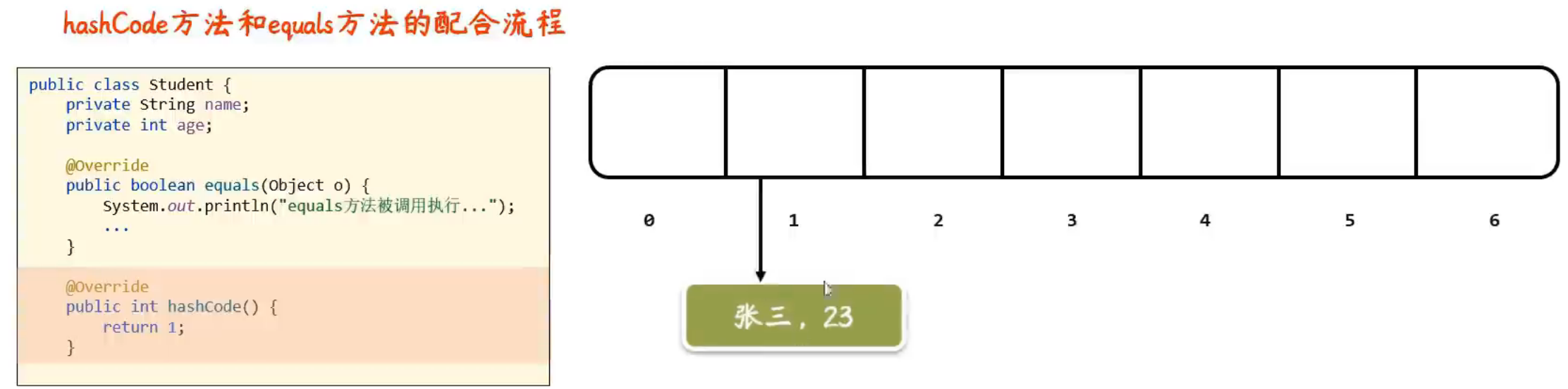
接着添加李四,自动调用hashcode方法,李四也拿着1号座位号,发现已经有人在上面了
此时就调用equals方法,发现李四和张三内容不一样,不一样就可以接着往1号索引存
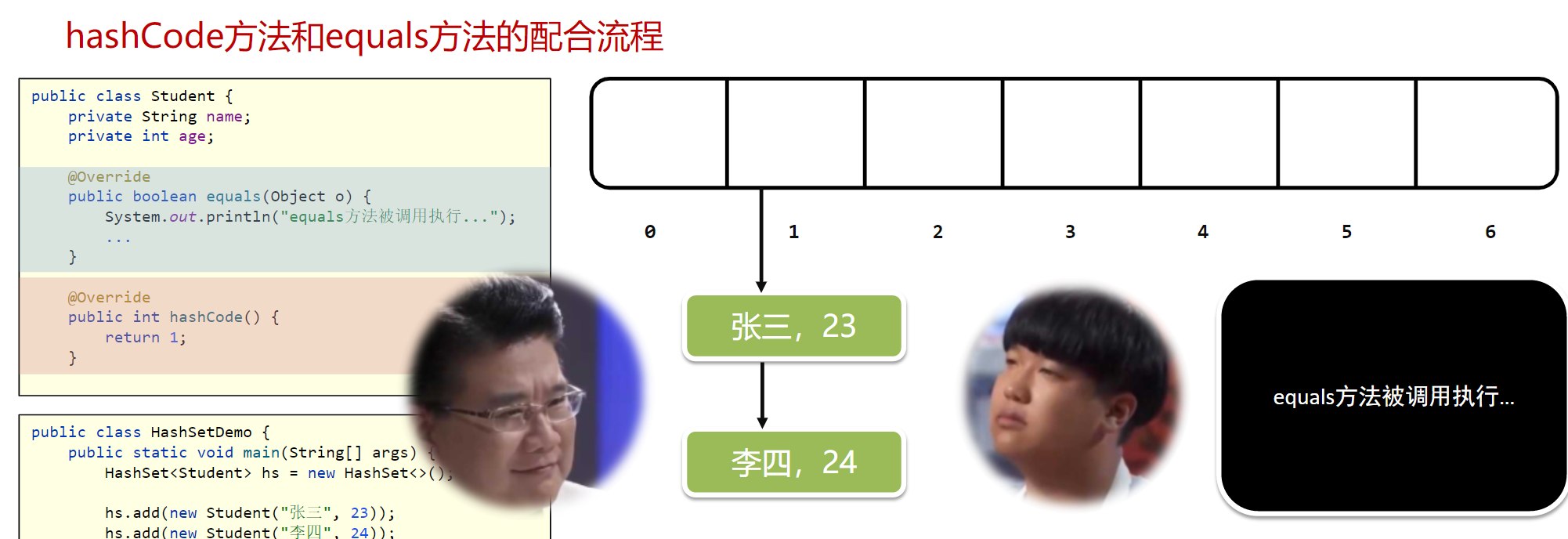
以此类推,将所有不同的对象都存在了1号索引,多出的王五因为equals方法将被去重
详细流程:https://kdocs.cn/l/ck3AUjfXj4fv?linkname=150996947
总结

4.hashcode改造
了解HashSet存储元素的流程后,我们会发现一个问题:

这样就会导致HashSet在查询方面性能较低,需要优化
思路:如果在面对不同的对象时,hashcode返回的值也不同,就可以减少equals调用次数,集合里的索引位置也能利用充分

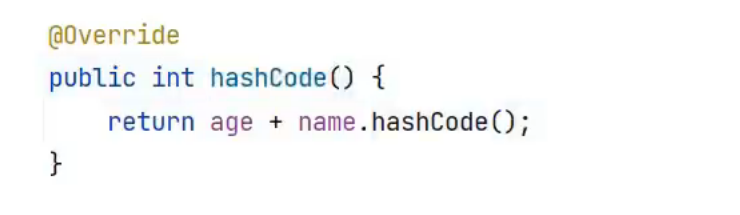
我们将对象的属性放入hashcode中,这样就能让不同的对象拿到的返回值不同,存入的索引位置也就不同了

下图报错的原因是因为name是String,使用加号导致age和name都变为了字符串,返回值是int

仔细想想,我们重写的hashcode方法来源于object,String类继承了object,那么String类就也有它自己重写过的hashcode方法,我们可以通过name(字符串对象)调用String类的hashcode方法
右键运行,equals只调用了一次用于去重,说明每个对象拿到的座位号都不同,减少了全挤在一个索引位置的概率
以后我们不需要手动重写,直接快捷键生成即可

5.hashCode方法介绍
hashCode是Object类里的一个方法,其底层逻辑就是调用C++代码计算出一个随机数

其中hashCode返回的数组称为哈希值

如果我们不重写hashCode方法,那每一个对象所拿到的哈希值都不一样,就会导致无法去重

6.HashSet原理解析:重点看JDk8版本
HashSet在JDK7和JDK8版本底层数据结构略有差异

1.JDK7版本HashSet内部操作

2.JDK8版本HashSet内部操作
JDK8版本,HashSet底层结构是哈希表

[1]创建HashSet集合
表面是创建HashSet集合,但实际是创建HashMap集合,HashMap当中会帮我们构造一个长度为16的空数组

[2]添加方法内部逻辑
当我们使用add方法进行添加时,会自动调用对象的hashCode方法计算出要存入的索引位置

光知道这些还不够,我们需要了解清楚add方法内部究竟干了什么,进入add方法内部,发现add方法调用了put方法,是在这里面做的添加

继续跟进put方法,里面调用了hash()方法,hash方法又是干什么的呢?

跟进hash方法,其中参数key是我们添加的对象,先判断了我们的对象是否为空,是空就返回0,防止空指针异常

若不是空,就调用了对象的hashCode方法,获取到了原始哈希值(我们重写hashCode后返回的年龄等)

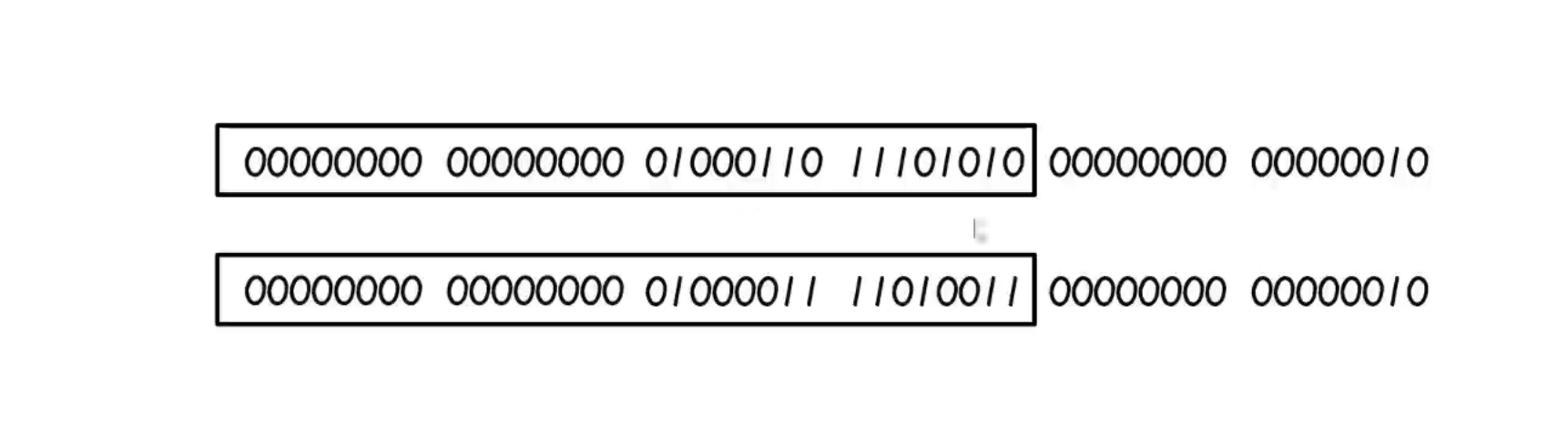
接着将我们的原始哈希值进行了右移16位--哈希扰动,然后再将扰动后的哈希值与原始哈希值做异或操作--二次哈希

哈希扰动可以将数据以二进制形式向右移动16位,目的就是让每个数据的相似度减少,让更有价值的数据参与运算
可以看见下图中,红框里两个数据的重复率特别高

经过哈希扰动后,两个数据后面16位不再相同
将原始哈希值和扰动后的哈希值进行二次哈希(异或操作),得到最终的哈希值,再将哈希值模与数组长度就可以得到应存入的索引位置
进行如此复杂的计算,目的是为了减少计算出过多重复的索引位置,导致某个链表挂载过多的数据,降低效率

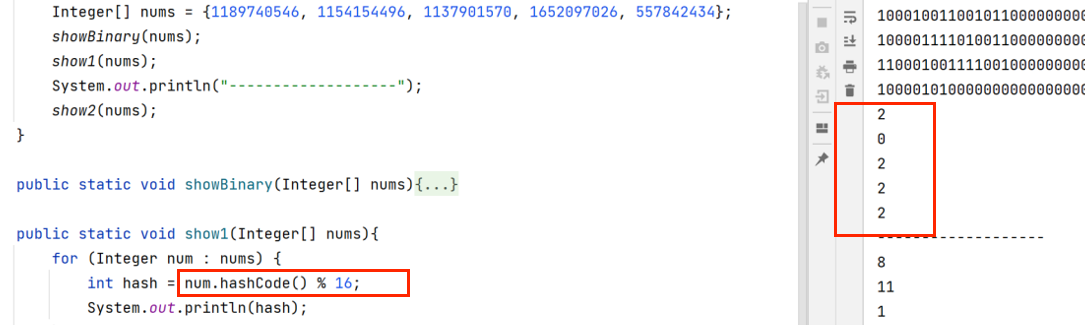
如下图,直接拿着原始哈希值模与数组长度,计算出来的索引位置大多重复
而通过哈希扰动和二次哈希计算出的哈希值,再模与数组长度,算出的索引位置几乎无重复
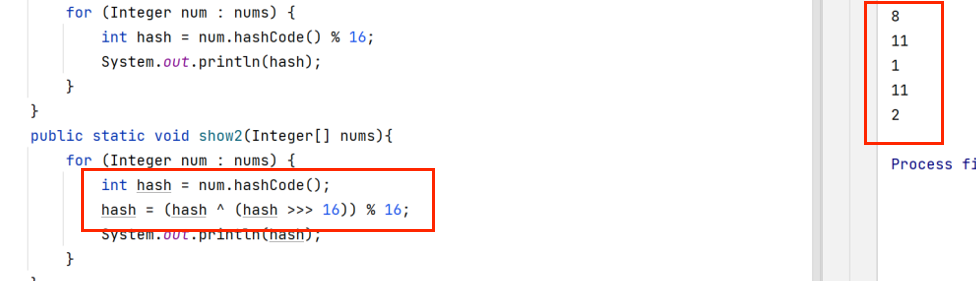
如此操作就能使得不同的数据尽可能的挂在不同的索引位置,而且还能减小数据的大小,假如对象年龄是88,通过这种计算就能使算出的索引很小,防止数组长度过大,占据内存
注意: 源码中并不是将哈希值模与数组长度计算索引位置,而是拿着数组长度减1,再与哈希值

n是数组长度,hash就是哈希值,这种计算方式和哈希值模与数组长度计算出的结果是一致的,系统使用这种计算方式的原因--与操作的运算效率比模与更高
[3]存入原理
拿着刚才计算好的索引存入对应的索引位置,如果存入的位置为空则直接存入,否则调用equals方法判断数据是否重复,不重复则挂在前数据下面

[4]扩容原理
尽管我们进行了如此复杂的操作,依旧可能会有某个链表上挂着多个元素,导致查询效率降低
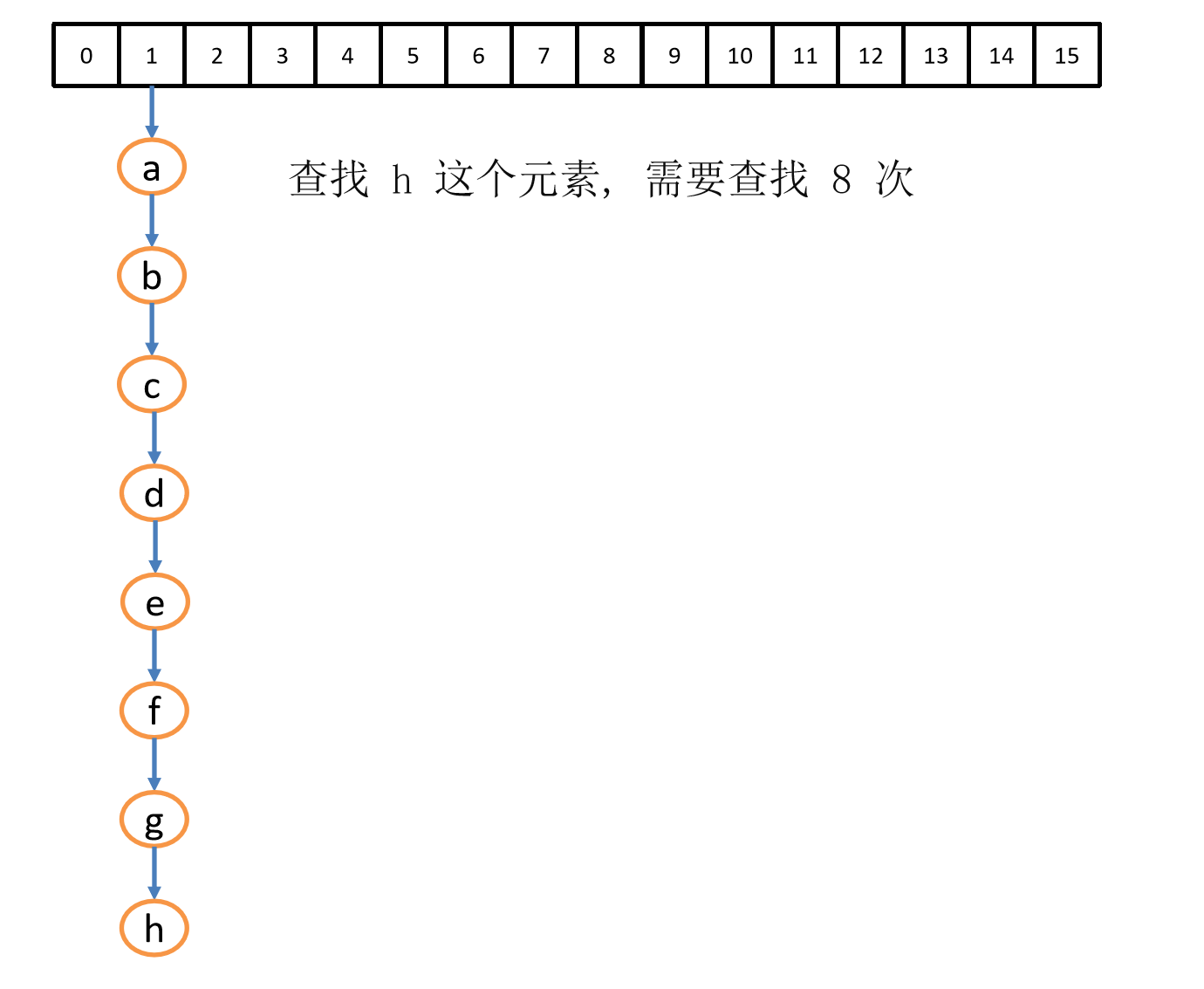
解决这个问题有两种方法,分别是扩容数组,链表转红黑树
1.扩容数组
如果我们将数组长度增大,那么存入的数据就需要重新计算对应的下标,使得每个数据尽可能挂在不同索引位置

A:当数组中存了12个元素后,在存第13个元素时,会扩容原数组的2倍(并不是存满12个索引,是存了12个元素就会扩容)
原数组长度为16,现在已经存了12个元素了
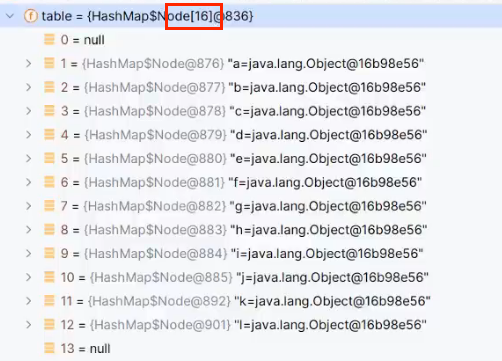
当我们存入第13个元素时,数组长度变为了32
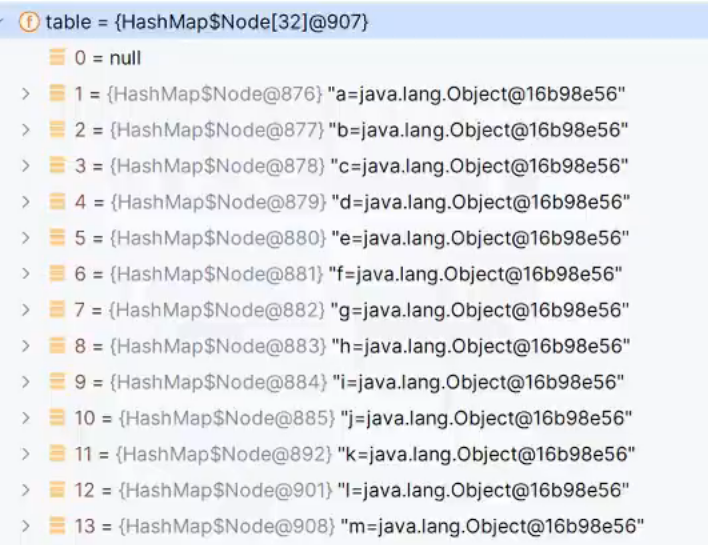
B:当链表上挂载的元素超过了8个,数组长度没有到达64时,扩容数组

A和B中,满足了其一就会扩容数组,扩容完成后,即使再满足另外一个条件,也不会继续扩容了
2.链表转红黑树
如果链表挂载的元素超过了阈值,而且数组长度到达了64(只能小于64),就会进行树化操作

如图,treeifyBin即树化操作,会判断数组长度是否到达64,未到达64,则会继续扩容数组,到达了64则会转红黑树


 浙公网安备 33010602011771号
浙公网安备 33010602011771号