

Linux系统出现了性能问题,一般我们可以通过top、iostat、free、vmstat等命令来查看初步定位问题。
iostat常见用法:
$iostat -d -k 1 10 #查看TPS和吞吐量信息
$iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
$iostat -c 1 10 #查看cpu状态
参数
-d 表示,显示设备(磁盘)使用状态;
-k某些使用block为单位的列强制使用Kilobytes为单位,同样可以使用-m。
-x获得更多统计信息,如avgrq-sz avgqu-sz await svctm %util。
-c获取cpu部分状态值。
1 10表示,数据显示每隔1秒刷新一次,共显示10次。
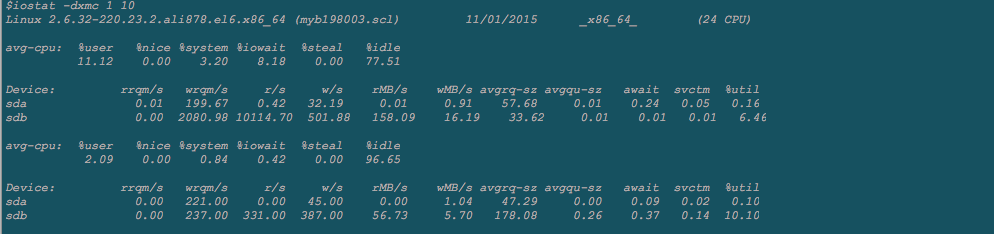
svctm是平均每次请求的服务时间。
单磁盘:
(r/s+w/s)*(svctm/1000)=util。举例子:如果util达到100%,那么此时 svctm=1000/(r/s+w/s),假设IOPS是1000,则svctm大概在1毫秒左右,如果长时间大于这个数值,说明系统出了问题。
多磁盘:
计算设备服务的并发请求数:
concurrency = (r/s+w/s)*(svctm/1000)=(avgqu-sz*svctm)/await
理解:
1.处理完(r+w)/s的时间=(r+w)/s*(svctm/1000,单位转化为秒),然后处理单位1s,相当于一秒中处理了这么多的请求,如果结果大于1一定是有并发的,不然怎么处理的过来呢?
2.处理完队列里的请求需要avgqu-sz*svctm毫秒,及实际需要等待的时间,但是只用了await时间等待,所以考虑是否有并发?如果大于1,一定有的。
vmstat常见用法:
vmstat -S M 1 3
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
虚拟内存运行原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。

字段说明:
Procs(进程):
r: 运行队列中进程数量,等待CPU的调度
b: 等待IO的进程数量,出于不可中断的休眠(通常意味着等待IO, 例如磁盘/网络/用户输入等)
Memory(内存):
swpd: 使用虚拟内存大小(多少块被交换到了磁盘)
free: 可用内存大小
buff: 用作缓冲的内存大小(输出)
cache: 用作缓存的内存大小(写入)
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间)
wa: 等待IO时间
一个重要的提示:内存、交换区以及I/O统计的是块数而不是字节。在GNU/Linux,块大小默认是1024字节。
cpu密集型服务器通常在us列会有很高的值,也可能表现在sy列,超过20%就足以令人不安了。
一般不用担心上下文切换,除非每秒超过100 000次或者更多,当操作系统停止一个进程而运行另一个进程时,就会产生上下文切换。如果执行了一个非覆盖扫描索引,就会先从索引中读取元素,然后根据索引再从磁盘上读取页面,如果页面不在操作系统缓存中,就需要从磁盘进行物理读取,将会导致上下文切换中断进程处理,直到I/O完成。
io密集型工作负载下,CPU花费大量时间在等待I/O请求,意味着vmstat会显示很多处理器在不可中断休眠(b列)状态,并且wa这一列的值会很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号