
DOM&SAX解析XML
在上一篇随笔中分析了xml以及它的两种验证方式。我们有了xml,但是里面的内容要怎么才能得到呢?如果得不到的话,那么还是没用的,解析xml的方式主要有DOM跟SAX,其中DOM是W3C官方的解析方式,而SAX是民间(非官方)的,两种解析方式是很不一样的。下面通过例子来分析两种解析方式的区别。
下面是要解析的xml文档
1 <?xml version="1.0" encoding="utf-8"?> 2 <学生名册> 3 <!--http://www.cnblogs.com/zhi-hao/--> 4 <学生 学号="A1"> 5 <姓名>CIACs</姓名> 6 <性别>男</性别> 7 <年龄>22</年龄> 8 </学生> 9 <学生 学号="A2"> 10 <姓名>zhihao</姓名> 11 <性别>男</性别> 12 <年龄>23</年龄> 13 </学生> 14 </学生名册>
DOM(Document Object Model)文档对象模式,从名字上就可以知道,DOM应该是基于文档对象来解析的。在DOM解析方式中主要用到了以下四个接口
1、Document接口,该接口是对xml文档进行操作的入口,要想操作xml,必须获得文档的入口。
2、Node接口,存储xml文档的节点的
3、NodeList接口
4、NameNodeMap接口,存储的是xml中的属性。
DOM中的基本对象有Document,Node,NodeList,Element和Attr。有了这些就可以解析xml了


1 package xmlTest; 2 3 import java.io.File; 4 5 import javax.xml.parsers.DocumentBuilder; 6 import javax.xml.parsers.DocumentBuilderFactory; 7 8 import org.w3c.dom.Attr; 9 import org.w3c.dom.Document; 10 import org.w3c.dom.Element; 11 import org.w3c.dom.NamedNodeMap; 12 import org.w3c.dom.Node; 13 import org.w3c.dom.NodeList; 14 /** 15 * 16 * @author CIACs 17 * 2014-09-22 18 */ 19 20 public class DOM { 21 22 public static void main(String[] args) throws Exception { 23 //获得解析工厂实例 24 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 25 //通过工厂获得DocumentBulider 26 DocumentBuilder db = dbf.newDocumentBuilder(); 27 //获得文档对象的入口 28 Document doc = db.parse(new File("student.xml")); 29 //获得根元素 30 Element root = doc.getDocumentElement(); 31 //开始解析 32 parseElement(root); 33 } 34 private static void parseElement(Element element) 35 { 36 String tagName = element.getNodeName(); 37 System.out.print("<"+tagName); 38 //获得元素属性 39 NamedNodeMap map = element.getAttributes(); 40 if(null != map) 41 { 42 for(int i = 0;i < map.getLength();i++) 43 { 44 Attr attr = (Attr)map.item(i); 45 String attrName = attr.getName(); 46 String attrValue = attr.getValue(); 47 System.out.print(" "+attrName + "=\""+attrValue+"\""); 48 } 49 } 50 System.out.print(">"); 51 52 //获得元素的孩子节点 53 NodeList child = element.getChildNodes(); 54 55 for(int i = 0;i < child.getLength();i++) 56 { 57 Node node = child.item(i); 58 //判断节点类型 59 60 short nodeType = node.getNodeType(); 61 62 if(nodeType == Node.ELEMENT_NODE) 63 { 64 parseElement((Element)node); 65 } 66 else 67 if(nodeType == Node.TEXT_NODE) 68 { 69 System.out.print(node.getTextContent()); 70 } 71 else 72 if(nodeType == Node.COMMENT_NODE) 73 { 74 System.out.print("<!--"+node.getTextContent()+"-->"); 75 } 76 } 77 System.out.print("</"+tagName+">"); 78 } 79 }
输出结果:

当然你可以直接输出内容,不用控制格式。
SAX(Simple APIs for XML)面向xml的简单APIs。SAX解析xml的一般步骤如下
1、创建SAXParserFactory对象; SAXParserFactory spf = SAXParserFactory.newInstance();
2、使用上面创建的工厂对象创建SAXParser解析对象;SAXParser sp = spf.newSAXParser();
3、创建SAXHandler处理器,而这个SAXHandler类要继承DefaultHandler,自己重新编写其中的方法,主要有 public void startElement(String uri, String localName, String qName,Attributes attributes) throws SAXException{ } 这个方法是在读取xml数据的节点元素开始时触发,需要实现这个方法进行标记元素的名字的操作; public void characters(char[] ch, int start, int length)throws SAXException{ } 这个方法可以处理节点之间的数据; public void endElement(String uri, String ocalName, String qName)throws SAXException { } 这个方法在处理节点元素终止时触发,可添加代码来将节点数据进行存储。
下面是解析xml的代码
1 package xmlTest; 2 3 import java.io.File; 4 import javax.xml.parsers.SAXParser; 5 import javax.xml.parsers.SAXParserFactory; 6 7 import org.xml.sax.Attributes; 8 import org.xml.sax.SAXException; 9 import org.xml.sax.helpers.DefaultHandler; 10 11 /** 12 * 13 * @author CIACs 14 * 2014-09-22 15 */ 16 17 public class Sax { 18 public static void main(String []args) 19 { 20 try 21 { 22 //获得sax解析工厂实例 23 SAXParserFactory spf = SAXParserFactory.newInstance(); 24 //获得sax解析器 25 SAXParser sp = spf.newSAXParser(); 26 //获得SAXHandler,该类是继承自DefaultHandler的 27 SAXHandler handler = new SAXHandler(); 28 //开始解析xml文档 29 sp.parse(new File("student.xml"), handler); 30 31 } 32 catch(Exception e) 33 { 34 e.printStackTrace(); 35 } 36 } 37 38 } 39 40 class SAXHandler extends DefaultHandler 41 { 42 private String currentElement; 43 private String currentValue; 44 private String attrName; 45 private String attrValue; 46 @Override 47 public void startElement(String uri, String localName, String qName, 48 Attributes attributes) throws SAXException { 49 currentElement = qName; 50 for(int i = 0;i < attributes.getLength();i++) 51 { 52 attrName = attributes.getQName(i); 53 attrValue = attributes.getValue(i); 54 System.out.println("属性: "+ attrName + "=" + attrValue); 55 } 56 57 } 58 @Override 59 public void characters(char[] ch, int start, int length) 60 throws SAXException { 61 currentValue = new String(ch,start,length); 62 } 63 @Override 64 public void endElement(String uri, String localName, String qName) 65 throws SAXException { 66 67 if(currentElement.equals(qName)) 68 { 69 System.out.println(currentElement + "=" + currentValue); 70 } 71 } 72 }
输出结果:
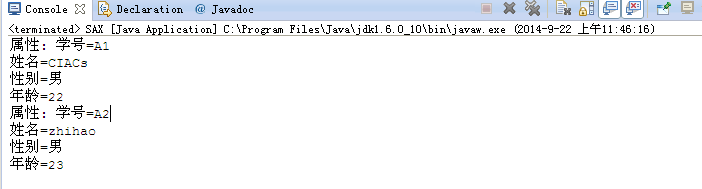
这里我也是直接输出xml的内容,并没有写到硬盘,在实际应用时你可以把内容存在Map中。
总结:
通过上面的两个解析实例,我们可以看出DOM解析XML时,首先将xml文档整个加载到内存中,然后就可以随机访问内存中的文档对象树(dom解析器是把xml解析成树形结构的)。SAX是基于事件的而且是顺序的,就是读到某个标签时就会调用相应的方法,一旦经过了某个元素之后,我们就没办法再去访问了。DOM由于要把整个xml加载到内存中,所以当xml很大时,内存就可能会溢出,而SAX不用事先把xml文档加载到内存中,占用内存小,相对而言SAX是面向xml的简单APIs,在开发上比较复杂,要开发者去实现事件处理器,但会更灵活,而DOM会更易于理解和开发。对于大型的xml文档,我们通常会使用SAX的方式去解析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号