

Hadoop基础之MapReduce中Shuffle
Hadoop基础之MapReduce中Shuffle
shuffle
- maptask:map端可以执行的一个进程
- reducetask:reduce端可以执行的一个进程
- shuffle是介于maptask和reducetask之间的一个过程
- shuffle可以分为map端的shuffle和reduce端的shuffle
执行过程
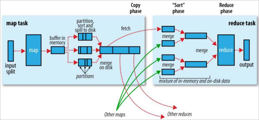
- shuffle是MR处理中的一个过程,它的每一个处理步骤是分散在各个maptask和reducetask节点上完成的
- 每个map读取原数据的一部分(inputSplit),执行Mapper操作
- 从Mapper端输出的键值对数据进入到环形缓冲区(100M)
- 环形缓冲区容量达到80%产生溢写,写入到磁盘缓冲区
- 在磁盘缓冲区中分区(partitioner),排序(sort),合并(combiner)
- 由reducetask向maptask拉取数据,进行分组排序(归并算法)
- 把数据组合成(key,序列)发送到Reducer类中执行
- 在Reducer类中处理数据,把结果写到文件中
分区(paratitioner)
- 根据不同的业务逻辑需求进行不同的数据分区,分区的数量与reduce数量有关
- 分区数量与reduce数量的关系
- 分区数量 = reduce数量
- 每个reduce找到自己相应的分区
- 分区数量 < reduce数量
- reduce的数量不够分配每个分区的内容,执行时会报错
- 分区数量 > reduce数量
- 每个reduce找到自己的分区,但是会有剩余reduce,浪费资源
- 特殊情况:N个分区对应一个reduce
- 所有分区的内容都在这个reduce处理,相当于梅分区
- 设置分区数量
job.setNumReduceTasks((Integer)object);
- 默认分区方式
- HashPartitioner extends Partitione<key,value>
- 重写分区方式
- getPartitioner(key,value,numReduceTask)
- 通过key的hashCode值和int的最大值进行与运算,对reduce数量(分区)取余,余数就是当前这个数据所在分区的编号
- 自定义分区方式
- 自定义类继承Partitioner<key,value>
- 重写getPartition方法,定义分区规则
- 规则里,每种条件的返回值(一个整型数字)作为分区的编号
- 分区数量在这个类中是一个确定值,要小于等于reduce数量,尽量保持一致
- 在Driver中设置reduce的数量和要使用的自定义分区类
job.setPartitionerClass((Class<? extends Partitioner>) object);
排序
- 在执行完的MapReduce结果中,key是按照自然顺序(默认顺序)排序的,而value不进行排序
- 默认排序规则
- 原有数据类型实现WritableComparable接口,重写compareTo方法
- 在方法中定义默认规则,升序降序方式按照返回值是正数还是负数
- 自定义数据类型默认排序
- 在自定义数据类型中,如果需要充当Key的泛型,必须实现Comparable接口
- 重写compareTo方法,在方法内定义默认排序规则
- 自定义排序规则
- 如果MR本身提供的数据类型或自定义序列化类型的默认排序规则无法满足某个业务逻辑的需求的时候,需要自定义排序规则
- 自定义排序规则值对当前的业务逻辑有效,不影响其他使用此类型的业务
- 继承WritableComparator类,重写compare方法,使用构造器注册
public className (){ super(排序类型.class,true); }
- 实现WritableComparable接口和继承WritableComparator的区别
- WritableComparable用于序列化类型的默认排序
- WritableComparator用于序列化类型的自定义排序
- WritableComparable是实现implements接口,有比较的数据泛型
- WritableComparator是extends类,没有比较的数据泛型
- WritableComparable重写comparaTo方法,一个参数
- WritableComparator重写compare方法,两个参数
- WritableComparable无需注册,写在自定义序列化类型内部,无需调用
- WritableCompaarator为单独定义类,通过构造方法注册自己
- 在Driver中设置自定义排序规则
job.setSortComparatorClass((Class<? extends RawComparator>) object);
随机抽样排序
- 部分排序
- 在结果文件中,每个文件内的数据有序,但是全局文件无需,MR中正常执行的代码都是部分排序
- 全排序
- 对于所有结果文件来说,不仅仅每个文件内部有序,而且全局有序
- 如果数据中某部分特别集中,而且分区的标准特别难确定,就会造成reduce端计算的数据倾斜问题,导致计算时间过长
- 随机抽样
- 设置分区类
job.setPartitionerClass(TotalOrderPartitioner.class);
- 使用随机抽样获取临界点
- 第一个参数:每个值被抽取到的概率
- 第二个参数:抽取到的样本数量
- 第三个参数:切片的数量
InputSampler.Random randomSampler = new InputSampler.RandomSampler((double)para[0],(int)para[1],(int)para[2]);
- 把获取的临界点写入partition.lst文件
InputSampler.writePartitionFile(job,randomSampler);
- 如果有已知的临界点序列化文件,可以直接使用此文件
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(),new Path((String)samplePara));
- 输入路径要在执行随机抽样之前
- 源文件必须是序列化文件才可以进行抽样
//设置文件类型为序列化文件 job.setInputFormatClass(SequenceFileInputFormat.class);
- Mapper端的KeyIn和ValueIn根据实际情况填写
- 序列化文件每行都有key和value,读取的时候可以按照key和value的类型读取
- 可以通过hdfs dfs -text xxx.seq (windows端 hdfs.cmd dfs -text xxx.seq)
二次排序
- 在一个排序条件无法满足的时候,可以选择两个或以上的条件同时排序
- 默认提供的序列化类型可以在默认排序规则里进行二次排序
- 自定义序列化类型可以在默认排序规则和自定义排序规则里进行二次排序
package mapReduce.join.mapJoin; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class ComputerSalesOrder implements WritableComparable<ComputerSalesOrder> { private String serialNumber = "";//流水号 private String product = ""; //商品编号 private Integer money = 0; //商品价格 private String time = ""; //成交时间 private String brand = ""; //品牌 private String type = ""; //商品类型 private String flag = ""; //设置标识 public String getSerialNumber() { return serialNumber; } public void setSerialNumber(String serialNumber) { this.serialNumber = serialNumber; } public String getProduct() { return product; } public void setProduct(String product) { this.product = product; } public Integer getMoney() { return money; } public void setMoney(Integer money) { this.money = money; } public String getTime() { return time; } public void setTime(String time) { this.time = time; } public String getBrand() { return brand; } public void setBrand(String brand) { this.brand = brand; } public String getType() { return type; } public void setType(String type) { this.type = type; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } @Override public int compareTo(ComputerSalesOrder computerSalesOrder) { //商品编号为排序第一序列 if(this.product.equals(computerSalesOrder.getProduct())){ //商品类型为第二序列 if(this.type.equals(computerSalesOrder.getType())){ if(this.time.equals(computerSalesOrder.getTime())){ return -(this.money-computerSalesOrder.getMoney()); //上述都满足,按照销售额倒叙排列 }else{ return this.time.compareTo(computerSalesOrder.getTime()); } }else{ return this.type.compareTo(computerSalesOrder.getType()); } }else{ return this.product.compareTo(computerSalesOrder.getProduct()); } } @Override public void write(DataOutput out) throws IOException { out.writeUTF(serialNumber); out.writeUTF(product); out.writeInt(money); out.writeUTF(time); out.writeUTF(brand); out.writeUTF(type); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { this.serialNumber = in.readUTF(); this.product = in.readUTF(); this.money = in.readInt(); this.time = in.readUTF(); this.brand = in.readUTF(); this.type = in.readUTF(); this.flag = in.readUTF(); } @Override public String toString() { return "流水信息@:" + "流水号='" + serialNumber + '\'' + ",商品号='" + product + '\'' + ",销售额=" + money + ",成交时间='" + time + '\'' + ",产品品牌='" + brand + '\'' + ",产品类型='" + type; } }
倒排索引
- 通过具体的内容,反推出这个内容的位置,这种业务关系,叫做倒排索引
- 获取当前读取的文件名
String file = ((FileSplit) context.getInputSplit()).getPath().getName();
Combiner合并
- Combiner是map端shuffle的一个部分,根据实际的业务逻辑可以使用过也可以不使用
- 它的实际作用就是在map端执行reduce的操作
- reduce端可能由于任务分配不均导致工作量巨大,而map端相对轻松,属于map和reduce端的数据倾斜状态,如果想保持一种均衡的状态,就需要让map端帮助reduce端完成部分工作
- combiner的作用域只有当前map,耳reduce端还需要对所有map数据进行汇总
分组排序
- 分组:按照某个特征相同,形成一组
- MapReduce中的执行位置:reduce端的shuffer
- MapReduce中使用分组的时间:进入reduce端之前,按照Key相同的,value进行分组
- 分组依据
- 默认序列化类型:如果内容完全一致,自然形成一组
- 自定义序列化类型(多个字段):根据人为的需求,定义规则,设定分组条件
- 默认的排序规则就是分组规则
- 自定义分组规则
- 分组类继承WritableComparator类
- 重写compare方法
- 使用构造器注册
package mapReduce.group; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class GroupGSort extends WritableComparator{ public GroupGSort(){ super(GroupData.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { GroupData groupDataA = (GroupData)a; GroupData groupDataB = (GroupData)b; return groupDataA.getRegion().compareTo(groupDataB.getRegion()); } }
- driver设置分组
job.setGroupingComparatorClass((Class<? extends RawComparator>) object);
- 排序与分组的区别
- 排序
- 排序是按照某种规则,让数据拥有一定的顺序进行显示
- 在map端的shuffle执行
- 在MR中,所有的key必须排序(必须有默认排序规则),value可不排序
- 默认排序规则往上翻
- 分组规则是按照某种规则将相同的数据分为一组
- 分组本质上就是排序,按照排序走,如果排到相同的自然形成一组
- 在reduce端的shuffle执行
- 默认的排序规则就是分组规则
join业务
- join在数据库中表示多表连接
- 在MapReduce中可以连接不同文件的数据
- 相对于join在数据库中的实际操作来说,MapReduce中的join更多的是相当于一种思想
- reduce端:举个栗子,仅供参考,代码只有一部分,我太懒了
package mapReduce.join.reduceJoin; import mapReduce.common.MRUtils; import org.apache.commons.beanutils.BeanUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class ComputerSerialApp { public static class ComputerSerialMapper extends Mapper<LongWritable, Text,ComputerSalesOrder, NullWritable>{ ComputerSalesOrder newKey = new ComputerSalesOrder(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //获取数据 String line = value.toString(); //拆分 String[] datas = line.split("\t"); if(datas.length == 4){ //长度为4判定为文件ComputerSalesOrder newKey.setSerialNumber(datas[0]); newKey.setProduct(datas[1]); newKey.setMoney(Integer.parseInt(datas[2])); newKey.setTime(datas[3]); newKey.setFlag("order"); }else if (datas.length == 3){ //长度为3判定为文件ComputerBrand newKey.setProduct(datas[0]); newKey.setBrand(datas[1]); newKey.setType(datas[2]); newKey.setFlag("brand"); } context.write(newKey,NullWritable.get()); } } public static class ComputerSerialReducer extends Reducer<ComputerSalesOrder,NullWritable,ComputerSalesOrder,NullWritable>{ /** * ComputerSalesOrder * serialNumber product money time flag * * ComputerBrand --仅仅一条 * product brand type flag */ @Override protected void reduce(ComputerSalesOrder key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { List<ComputerSalesOrder> orderList = new ArrayList<>(); ComputerSalesOrder brand = new ComputerSalesOrder(); for (NullWritable value : values) { String flag = key.getFlag(); if (flag.equals("order")) { try { ComputerSalesOrder order = new ComputerSalesOrder(); BeanUtils.copyProperties(order,key); orderList.add(order); } catch (Exception e) { e.printStackTrace(); } }else if(flag.equals("brand")){ try { BeanUtils.copyProperties(brand,key); } catch (Exception e) { e.printStackTrace(); } } } //将名字写入 for (ComputerSalesOrder computerSalesOrder : orderList) { computerSalesOrder.setBrand(brand.getBrand()); computerSalesOrder.setType(brand.getType()); context.write(computerSalesOrder,NullWritable.get()); } } } public static void main(String[] args) { String[] paths = {"E:/input/join/reduceComputerOrderAndBrand","E:/output/join/reduceComputerOrderAndBrand"}; MRUtils.submit(ComputerSerialApp.class,paths,"sort",ComputerSalesSort.class,"group",ComputerSerialGroup.class/*,KeyValueTextInputFormat.class*/); } }
- map端:举个栗子,依然还是懒,懂得都懂
package mapReduce.join.mapJoin; import mapReduce.common.MRUtils; import mapReduce.join.reduceJoin.ComputerSalesSort; import mapReduce.join.reduceJoin.ComputerSerialGroup; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class ComputerSerialApp { public static class ComputerSerialMapper extends Mapper<LongWritable, Text,Text,Text>{ Map<String, ArrayList<String>> brandMap = new HashMap(); @Override protected void setup(Context context) throws IOException, InterruptedException { String brandName = context.getCacheFiles()[0].getPath().toString(); System.out.println(brandName+"jhsdhkosdhkoashklasdjklasdhiodhjkladhjklads"); BufferedReader bufferedReader = new BufferedReader(new FileReader(brandName)); String line = ""; while((line = bufferedReader.readLine()) != null){ try { String[] brand = line.split("\t"); ArrayList<String> list = new ArrayList<>(); list.add(brand[1]); list.add(brand[2]); brandMap.put(brand[0],list); } catch (Exception e) { e.printStackTrace(); } } bufferedReader.close(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] order = line.split("\t"); String serialNumber = order[0]; String product = order[1]; ArrayList<String> list = brandMap.get(product); String brand = list.get(0); String type = list.get(1); String money = order[2]; String time = order[3]; context.write(new Text(serialNumber+"\t"+product+"\t"+brand+"\t"+type+"\t"+money+"\t"+time),new Text("")); } } public static void main(String[] args) { String[] paths = {"E:/input/join/reduceComputerOrderAndBrand/ComputerSalesOrder.txt","E:/output/join/mapComputerOrderAndBrand"}; try { Object[] object = new Object[]{new URI("file:///E:/input/join/reduceComputerOrderAndBrand/ComputerBrand.txt"), 0}; MRUtils.submit(ComputerSalesOrder.class,paths,object); } catch (URISyntaxException e) { e.printStackTrace(); } } }
并行度(切片)
- reduce端的并行度
- 通过setNumReduceTask(n)设置并行度,n为reduce的并行度
- 每个节点都可以有0-N个reduceTask,根据测试,reduceTask的数量与DataNode的数量保持一致的时候可以达到最快的计算速度
- map端的并行度
- map端的并行度与reduce端的并行度毫无关系
- 切片机制
- 按照128M的大小对数据进行切片,与block块保持一致
- 每一个切片叫做InputSplit
- 如果输入路径有多个文件,每个文件分别做切片处理
- 输入格式化
输入格式化
| TextInputFormat | 最普通的文本文档格式,MapReduce中默认使用的格式类型 |
| SequenceFileInputFormat | 序列化文件格式,文件中有key和value,分别有各自的类型 |
| KeyValueFileInputFormat | 是普通的文本文档,但是每行数据都有KeyValue,类型都是Text |
| NLineInputFormat | 普通的文本文档,打破原有的分片规则,按行分片 |
| CombineTextInputFormat | 针对小文件处理的一种格式,为了避免每个小文件对应一个InputSplit,导致过多mapTask产生,而每个mapTask中执行的内容特别少 |
| 自定义格式化类型 | |
链式MR
- 如果业务逻辑比较复杂的时候,可以使用多个Mapper和Reducer进行链式操作
- 全局可以有多个Mapper类,但是只能有一个Reducer类
- Reducer之前的Mapper类不管有多少个,本质上都属于一个Mapper
- Reducer之后的Mapper类,名字是Mapper,但是却属于Reducer
- 本质上当前业务中只有一个Mapper和一个Reducer
计数器
- 在业务逻辑中,如果需要对立面的一部分数据进行统计数量的时候
- 分为Map端的计数器和Reduce端的计数器
- Map端与Reduce端计数器写法一致,位置和显示有区别
压缩
- 在MR计算过程中,为了节省一定的空间可以使用压缩机制
- 压缩需要消耗时间和资源对文件重新编码,属于用时间换空间的方式
- 是否压缩,按照什么方式压缩,要根据实际情况进行选择
压缩的位置 压缩格式与对应编码/解码器压缩性能对比、
| Map前压缩 | Map后压缩 | Reducer之后压缩 | |||
| 压缩格式 | hadoop自带? | 算法 | 文件扩展名 | 是否可以切分 | 压缩后,原程序是否需要修改 |
| DEFAULT | 是,直接使用 | DEFAULT | .default | 否 | 和文本处理一致,不需要更改 |
| Gzip | 是,直接使用 | DEFAULT | .gz | 否 | 和文本处理一致,不需要更改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一致,不需要更改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy | .snappy | 否 | 和文本处理一致,不需要更改 |
| 压缩格式 | 编码/解码器 | ||||
| DEFLATE | org.apache.io.compress.DefaultCodec | ||||
| gzip | org.apache.io.compress.GzipCodec | ||||
| bzip2 | org.apache.io.compress.BZip2Codec | ||||
| LZO | org.apache.compression.lzo.LzopXodec | ||||
| Snappy | org.apache.io.compress.SnappyCodec | ||||
| 压缩率:bzip2>gzip>LZO | |||||
| 耗时:bzip2>gzip>LZO | |||||
如有问题,请发送邮件至buxiaqingcheng@163.com或者buxiaqingcheng@dingtalk.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号