
20212113齐振华 《Python程序设计》第四次实验报告
课程:《Python程序设计》
班级: 2121
姓名: 齐振华
学号:2021213
实验教师:王志强
实验日期:2022年5月22日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
2. 实验过程及结果
实验分析:
目的:爬取12306上从北京发往济南的车票情况,并实现可视化,可视化采取pyecharts,可视化一等座每个车次剩余情况,二等座车次剩余情况,利用python模拟浏览器爬取数据。
实验设计:
获取网站url,cookie,和user – agent,利用内置模块requests 爬取数据,爬取的数据转为json,并利用正则表达式获取想要的数据,包括车次,起始站,终点站,起始时间,到达时间,历经时间,当天日期,一等座情况,二等座情况,为了获取数据,用split 对数据分割,储存在数组中方便读取。安装pyecharts,通过pyecharts内置功能实现可视化,为了方便采取了pie(饼图)展示。
实验过程:
获取url,打开12306网址,F12,打开network,F5刷新一下,找
图中所有的内容,其中Request URL,为我们要使用的URL,
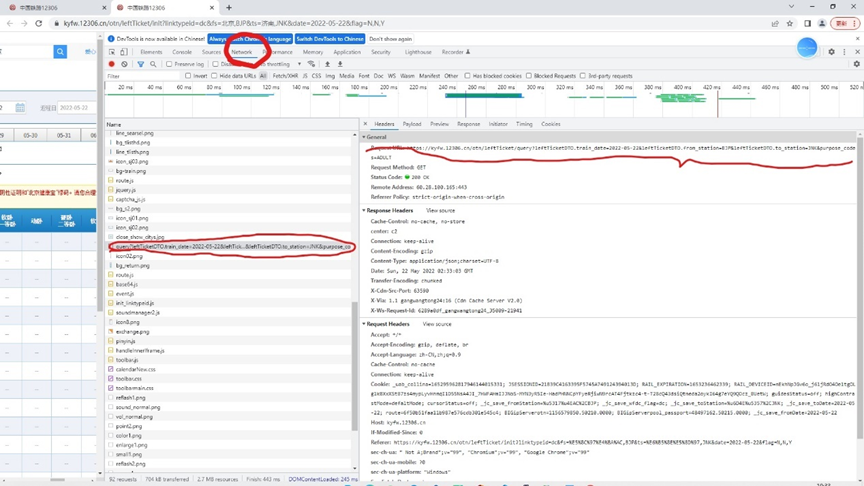
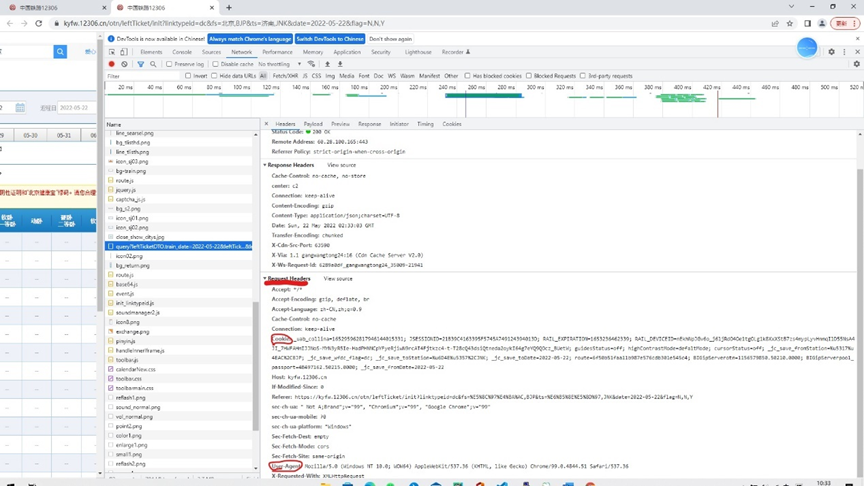
找到,Request Headers
里面的Cookie,和User-Agent为头文件内容
前期工作结束,开始写代码
import re
利用正则表达式,导入内置模块
import requests
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
从pyecharts.charts导入Page,和Pie
为了实现可视化做准备
def send_request():
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2022-05-23&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=JNK&purpose_codes=ADULT'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Cookie': '_uab_collina=165295962817946144015331;
JSESSIONID=083B1616F1E4EEE70222E94F0D8EF32E; RAIL_EXPIRATION=1653236462339;
RAIL_DEVICEID=nEkhNpJGv6o_j6ljRdO4Oe1tgOLg1k8XxXStB7zs4mypLyvHnmqIlD55NsA4JI_7HWFAHmIJJNoS-MYN3yR5Ie-HadPHNNCpYFyeRjiwN9rcAT4Fjtkzc4-t-T28cQ43dsiQtneda2oykI64g7eYQ9QOcz_BUetW;
guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off;
_jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_wfdc_flag=dc;
_jc_save_toStation=%u6D4E%u5357%2CJNK; _jc_save_toDate=2022-05-21;
route=c5c62a339e7744272a54643b3be5bf64; BIGipServerotn=1089470986.24610.0000;
BIGipServerpool_passport=149160458.50215.0000; _jc_save_fromDate=2022-05-23'}
score = requests.get(url, headers=headers)
score.encoding = 'utf-8'
return score
提取数据,将响应的数据转化为json,这一步要利用json在线解析,看一下

复制一下图上的内容,打开json解析网站

在线解析一下,可以看到,数据是以字典的形式储存的,键为data,值为value
值为value也是一个字典,键为result
Map里面为加密的信息,其中“JNK”代表济南等等
def parse_json(score, station):
json_ticket = score.json()将响应数据转化为json
data_lst = json_ticket['data']['result'],找到数据中键位date的数据中,键为result的数据
tplt = "{0:^14}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^16}\t{5:^10}\t{6:^16}\t{7:^18}\t{8:^18}"
print(tplt.format("车次", "起始站", "终点站", "一等座座位剩余情况", "二等座座位剩余情况", "起始时间", "到达时间", "历经时间", "出行时间")).format
为格式化,以tplt中的进行格式化为了美观
print(
'-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------')为了美观分割线
car = []
site = []
site2 = []
创建三个数组来存储每次获取的数据,以便进行数据可视化
for item in data_lst:
d = item.split('|')
利用循环遍历所有数据,并用split进行分割
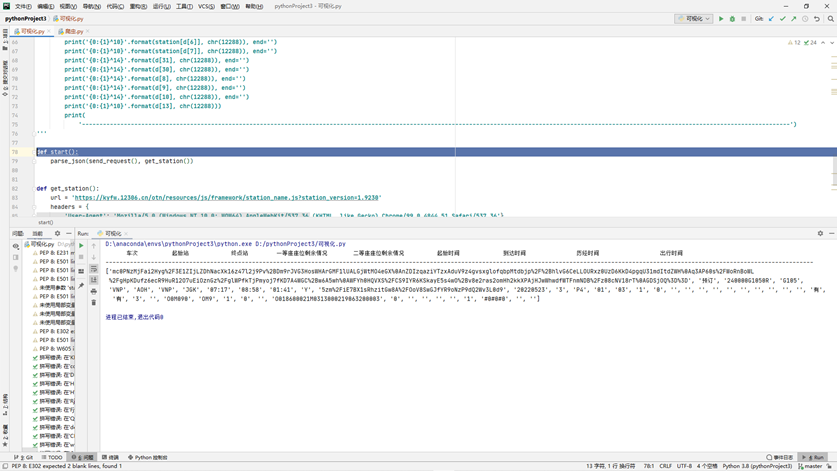
打印了一个数据进行查看,发现这个数组d[3]为车次,d[6]为起始站d[7]为终点站d[31]为一等座剩余情况d[30]为二等座剩余情况d[8]为起始时间d[9]为到达时间d[13]为出行时间d[10]为历经时间
car.append(d[3])储存车次
因为12306车票数量大于20张就会显示有,所以我们存储数据的时候,将‘有’赋值为20,‘无’赋值为0,其他的数据直接存储
if d[31] == '有':
temp = 20
site.append(temp)
elif d[31] == '无':
temp = 0
site.append(temp)
else:
site.append(d[31])
同理二等座也是这样处理,利用判断语句
if d[30] == '有':
temp = 20
site2.append(temp)
elif d[30] == '无':
temp = 0
site2.append(temp)
else:
site2.append(d[30])
print('{0:{1}^10}'.format(d[3], chr(12288)), end='')
print('{0:{1}^10}'.format(station[d[6]], chr(12288)), end='')
print('{0:{1}^10}'.format(station[d[7]], chr(12288)), end='')
print('{0:{1}^14}'.format(d[31], chr(12288)), end='')
print('{0:{1}^14}'.format(d[30], chr(12288)), end='')
print('{0:{1}^14}'.format(d[8], chr(12288)), end='')
print('{0:{1}^14}'.format(d[9], chr(12288)), end='')
print('{0:{1}^14}'.format(d[10], chr(12288)), end='')
print('{0:{1}^10}'.format(d[13], chr(12288)))
这一部分也是为了数据美观,利用format进行格式化
print(
'-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------')
这一部分就是为了实现可视化
def pie_rosetype() -> Pie:
c = (
Pie()
第一个pie图标
.add(
"",
[list(z) for z in zip(car, site)],数据为car[]和site[]中的
radius=["30%", "75%"],内半径,外半径
center=["25%", "50%"],中心位置
rosetype="radius",
radius -> list
饼图的半径,数组的第一项是内半径,第二项是外半径,默认为 [0, 75]
默认设置成百分比,相对于容器高宽中较小的一项的一半
center -> list
饼图的中心(圆心)坐标,数组的第一项是横坐标,第二项是纵坐标,默认为 [50, 50]
默认设置成百分比,设置成百分比时第一项是相对于容器宽度,第二项是相对于容器高度
rosetype -> str
是否展示成南丁格尔图,通过半径区分数据大小,有'radius'和'area'两种模式。默认为'radius'
radius:扇区圆心角展现数据的百分比,半径展现数据的大小
area:所有扇区圆心角相同,仅通过半径展现数据大小
label_opts=opts.LabelOpts(is_show=True),这个决定是否显示部分标签,True为显示,False为不显示。
)
.add(
"",
[list(z) for z in zip(car, site2)],
radius=["30%", "75%"],
center=["75%", "50%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=True),
)
.set_global_opts(title_opts=opts.TitleOpts(title="12306 5月23日车票剩余情况"))set_global_opts
为设置全局配置,这个是设置全局标签,标签为title="12306 5月23日车票剩余情况"
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))部分标签显示格式 {a}(系列名称),{b}(数据项名称)
)
return c
def page_draggable_layout():
page = Page(layout=Page.DraggablePageLayout)
page.add(
pie_rosetype(),
)
page.render("爬虫.html")
创建名字为爬虫.html的可视化文件
if __name__ == "__main__":
page_draggable_layout()
__name__其实是一个内置属性,指示当前py文件调用方式的方法。当上述例子运行的时候,整个程序中不管是哪个位置的__name__属性,值都是__main__,当这个hello.py文件作为模块被导入到另一个.py文件中(即import)比如说world.py,并且你运行的是world.py,此时hello.py中的__name__属性就会变成hello,所谓的入口因为if判断失败就不执行了
def start():
parse_json(send_request(), get_station())
def get_station():
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9230'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
score = requests.get(url, headers=headers)
score.encoding = 'utf-8'避免乱码
stations_name = re.findall('([\u4e00-\u9fa5]+)\|([A-Z]+)', score.text)正则表达式,表示所有的中文和英语
stations_name_date = dict(stations_name)
stations_name_blank = {}创建空子典,交换key和value的值
for item in stations_name_date:
stations_name_blank[stations_name_date[item]] = item
return stations_name_blank
if __name__ == '__main__':
start()
同理
实验结果:
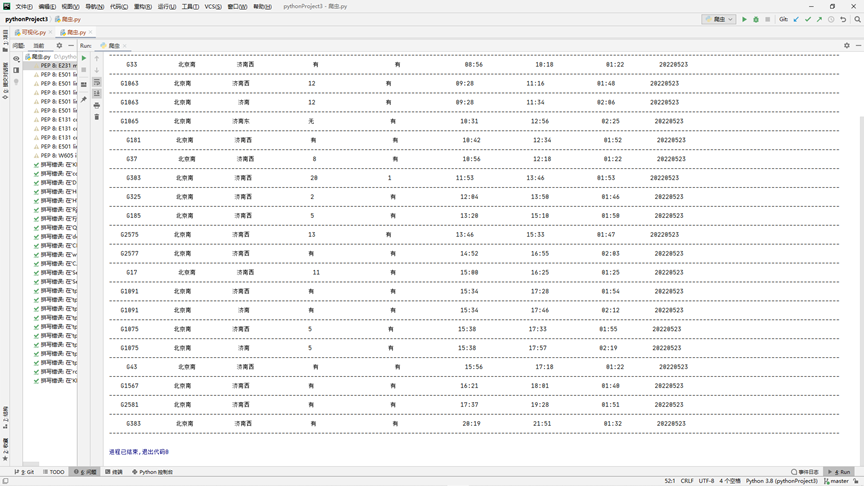
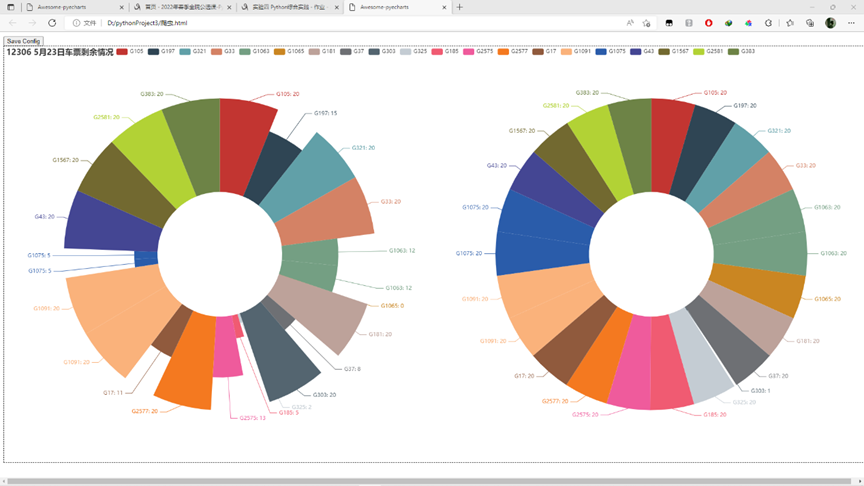
建议
服务器和正则表达式讲的跨度有点大,包括服务器加密,真的搞不懂,在进行实验三的时候,问了很多同学才搞明白大致,做出来。
体会
学了python感觉实现一些想法就比较简单,人生苦短我用python
因为这学期我也在学C语言,相比于C语言,我个人认为,python格式简单,利用方便,但有时候可能正式因为这种简单化,写一些东西就比较难以操作,比如for循环。在同时学习两门语言,有时候写完C语言,再写python,就感觉格式不是很习惯,但是写一段时间就好了。不是很习惯python对字典,集合,数组的赋值和打印读取不是很喜欢。但是对于爬虫来说,python太合适了,相对于c,python
写爬虫很舒服。虽然一学期下来,我对python的学习也仅仅只是它的基础方面,但python的强大,也是足足地吸引着我,希望自己能够在不断地学习中,将python学习的更加好。
全课总结:
学习到了python的基本语法知识,知道了python竟然可以用中文命名,
For,while,循环越用越熟悉了,
知识点
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
元组中的元素类型也可以不相同:
Set (集合)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
:
Dictionary(字典)
字典(dictionary)是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
正则表达式
数字:^[0-9]*$
n 位的数字:^\d{n}$
至少n 位的数字:^\d{n,}$
m-n 位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2 位小数的正数或负数:
^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3 位小数的正实数:
^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或
^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或
^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或^[A-Za-z0-9]{4,40}$
等
函数
参数的传递、实参、形参
例子+(角色+演员)
参数:数量、位置、要一致,否则要使用关键字参数;默认参数的设置
可变参数:*任意多个,**字典
6.3 返回值、作用域
6.4 匿名函数(lamda)*
匿名函数是指没有名字的函数,应用在需要一个函数,但是又不想去费神命名的场合。通常指使用一次,格式如下:
result = lambda[arg1, [arg2, [arg3, ...., argn]]:expression
result用于调用lamda表达式,是中括号是可选参数(至少一个),expression是必选参数
面向对象
对象:某一个具体的事物、实体或事例
类:具有相同属性和行为的一些对象的统称或集合
面向对象三要素:封装、继承、多态!
文件操作及其处理





爬虫开发
10.2 网络爬虫常用技术
(1)网络请求
网络请求有三种模块:Urllib、Urllib3、Requests
①Urllib
它是 Python 内置的 HTTP 请求库,也就是说我们不需要额外安装即可使用,它包含四个模块:
第一个模块 request,它是最基本的 HTTP请求模块,我们可以用它来模拟发送一请求,就像在浏览器里输入网址然后敲击回车一样,只需要给库方法传入 URL还有额外的参数,就可以模拟实现这个过程了。
第二个 error 模块即异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作保证程序不会意外终止。
第三个 parse 模块是一个工具模块,提供了许多 URL处理方法,比如拆分、解析、合并等等的方法。
第四个模块是 robotparser,主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬的,其实用的比较少。
②urllib3
Python2.x 有这些库名可用: urllib,urllib2,urllib3,httplib,httplib2,requests Python3.x 有这些库名可用: urllib,urllib3,httplib2,requests
Python3.x 中将 urllib2合并到了 urllib

服务器
利用socket模块建立服务器和客户端
Socket是计算机之间进行网络通信的一套程序接口,相当于在发送端和接收端之间建立了一个通信管道。在实际应用中,一些远程管理软件和网络安全软件大多依赖于Socket来实现特定功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号