L2G4-InternVL 多模态模型部署微调实践
L2G4-InternVL 多模态模型部署微调实践
数据集样本数量 = batch_size * accumulative_counts * step
- 由于显存有限,不能将数据集一次投入到模型中进行前向传播、计算损失、反向传播和参数更新,而是将数据分成若干个小批次(batch)。每个批次会通过前向传播、计算损失和反向传播来更新模型的权重。
batch_size就是每个批次包含的样本数量。accumulative_counts(或称为梯度累积步数)是指在进行一次参数更新之前,累积的梯度计算次数,即累积batch_size * accumulative_counts个样本后再更新一次参数。step是每次参数更新的过程,即做一次前向传播、计算损失、反向传播和参数更新。因此,这个公式的意思是,更新step次参数,每次更新使用batch_size * accumulative_counts个样本。 epoch:表示模型对整个训练数据集进行一次完整的遍历。一次训练不足以让模型对数据集学习得很好,epoch数表示数据集要在模型上跑多少次。
多模态大模型参数解读



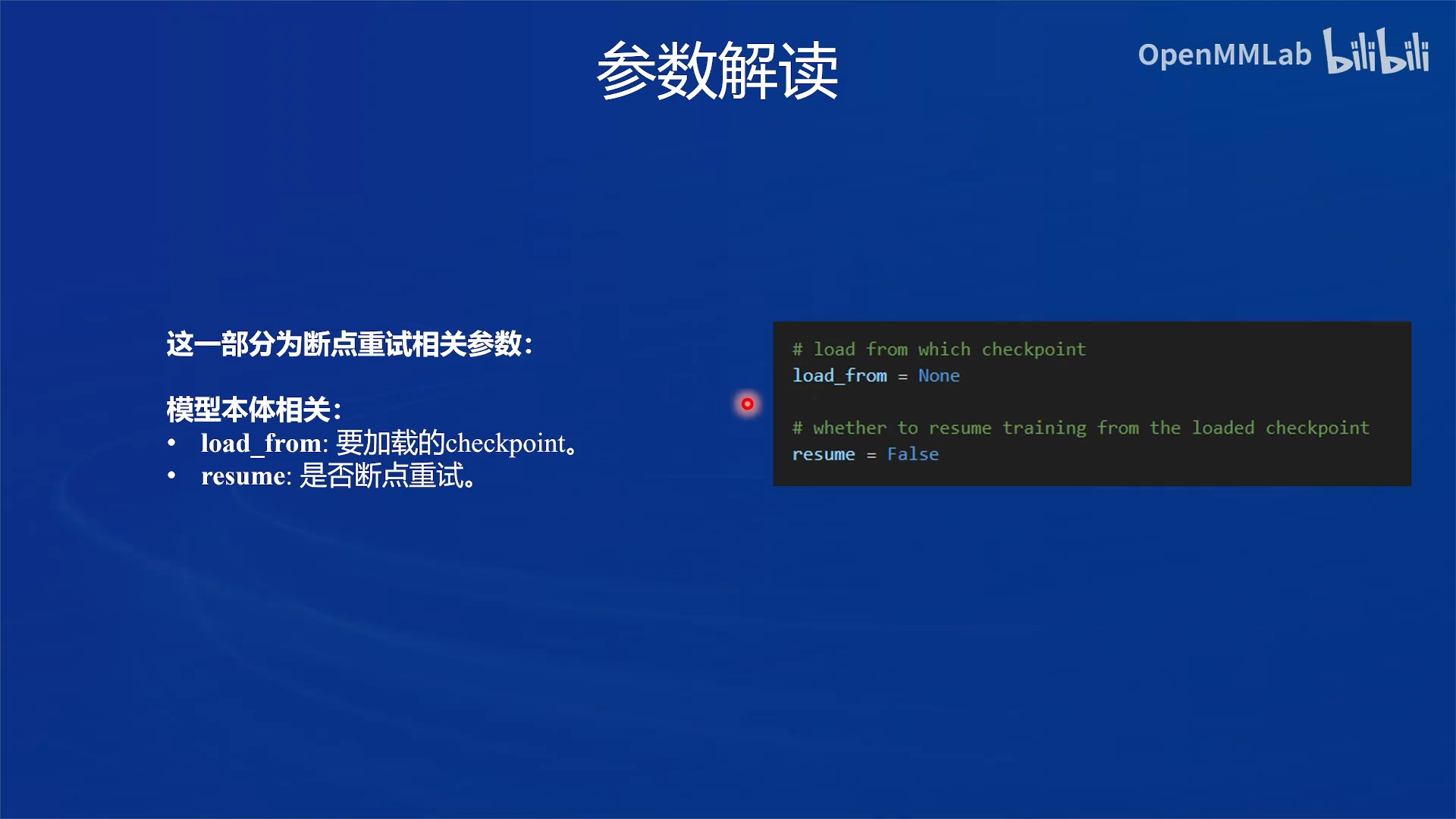
语言模型参数解读
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| sequence_parallel_size | 并行序列处理的大小,用于模型训练时的序列并行 |
| batch_size | 每个设备上的批量大小 |
| dataloader_num_workers | 数据加载器中工作进程的数量 |
| max_epochs | 训练的最大轮数 |
| optim_type | 优化器类型,例如 AdamW |
| lr | 学习率 |
| betas | 优化器中的 beta 参数,控制动量和平方梯度的移动平均 |
| weight_decay | 权重衰减系数,用于正则化和避免过拟合 |
| max_norm | 梯度裁剪的最大范数,用于防止梯度爆炸 |
| warmup_ratio | 预热的比例,学习率在这个比例的训练过程中线性增加到初始学习率 |
| save_steps | 保存模型的步数间隔 |
| save_total_limit | 保存的模型总数限制,超过限制时删除旧的模型文件 |
| prompt_template | 模板提示,用于定义生成文本的格式或结构 |
| ...... | ...... |
如果想充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。 ⚠但需要注意的是,在训练 chat 模型时调节参数batch_size有可能会影响对话模型的效果。

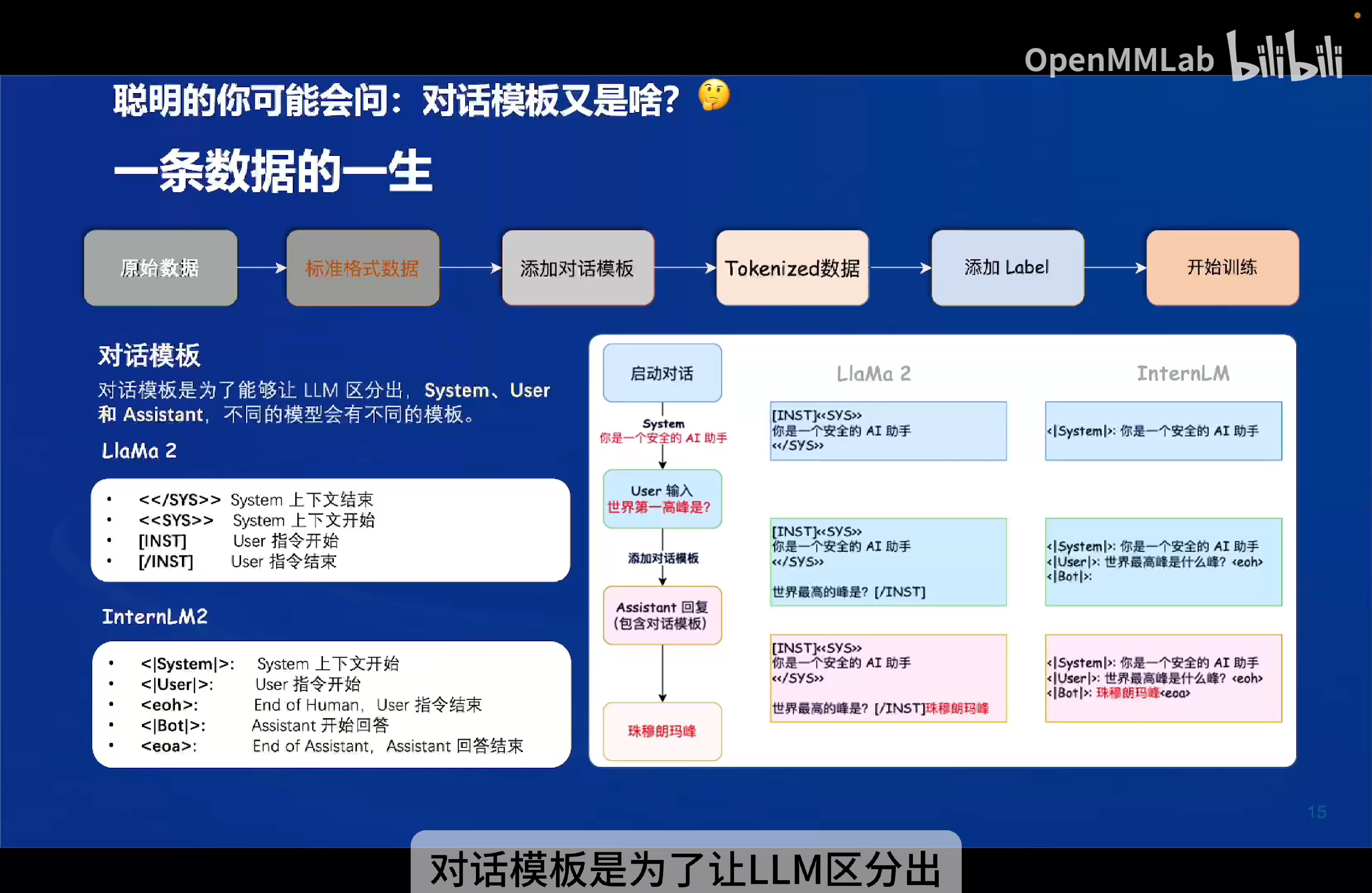
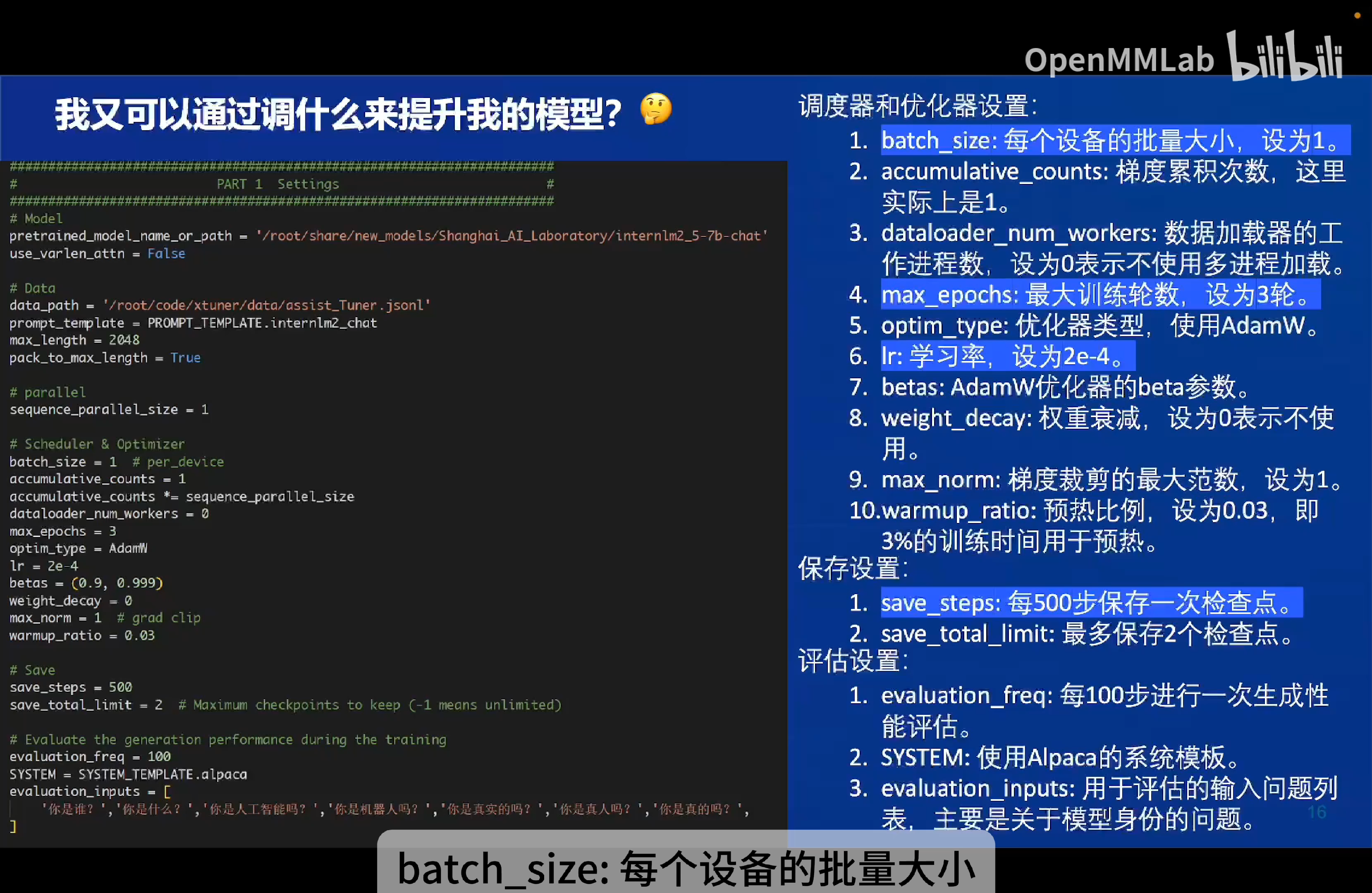
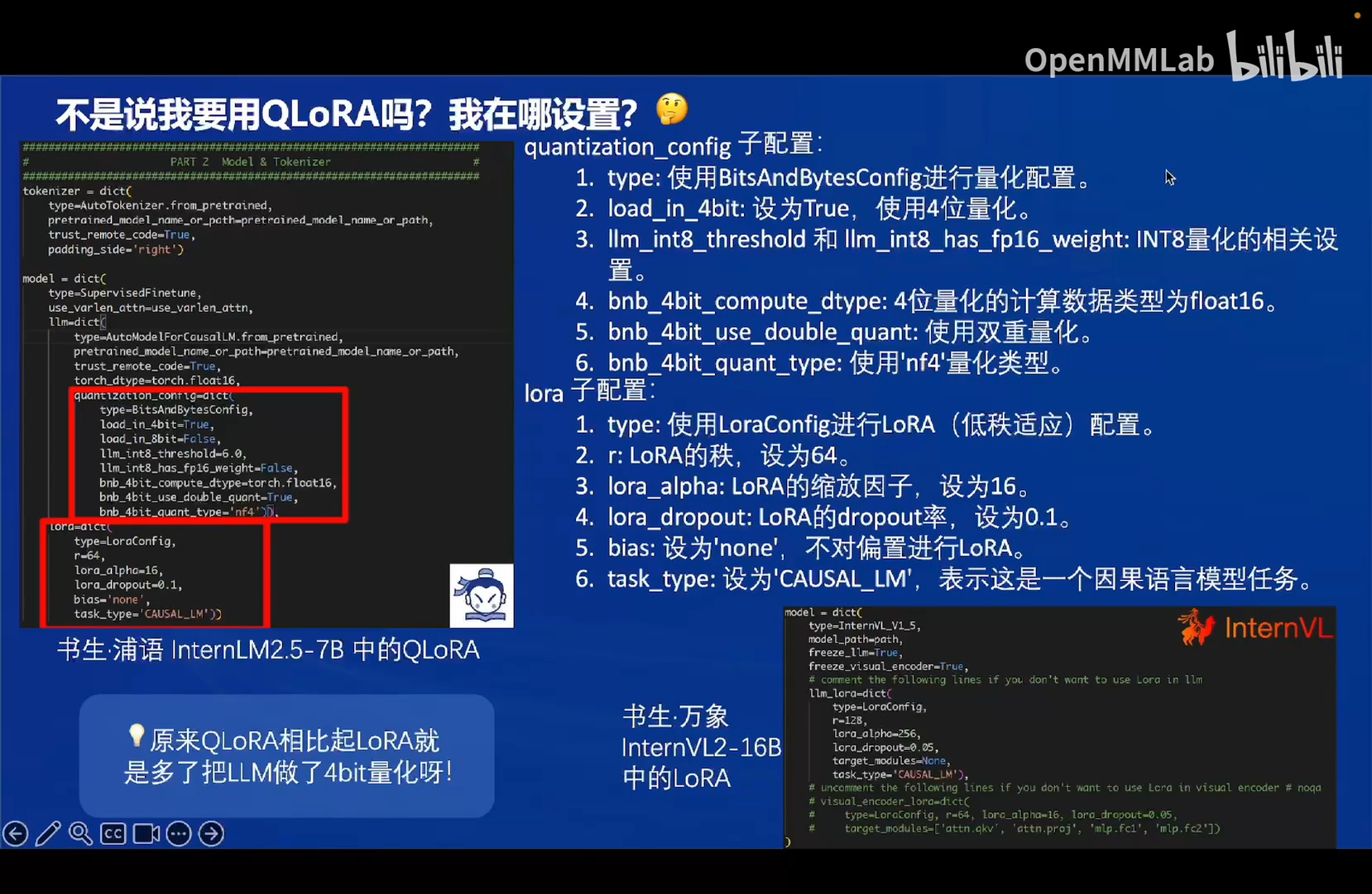
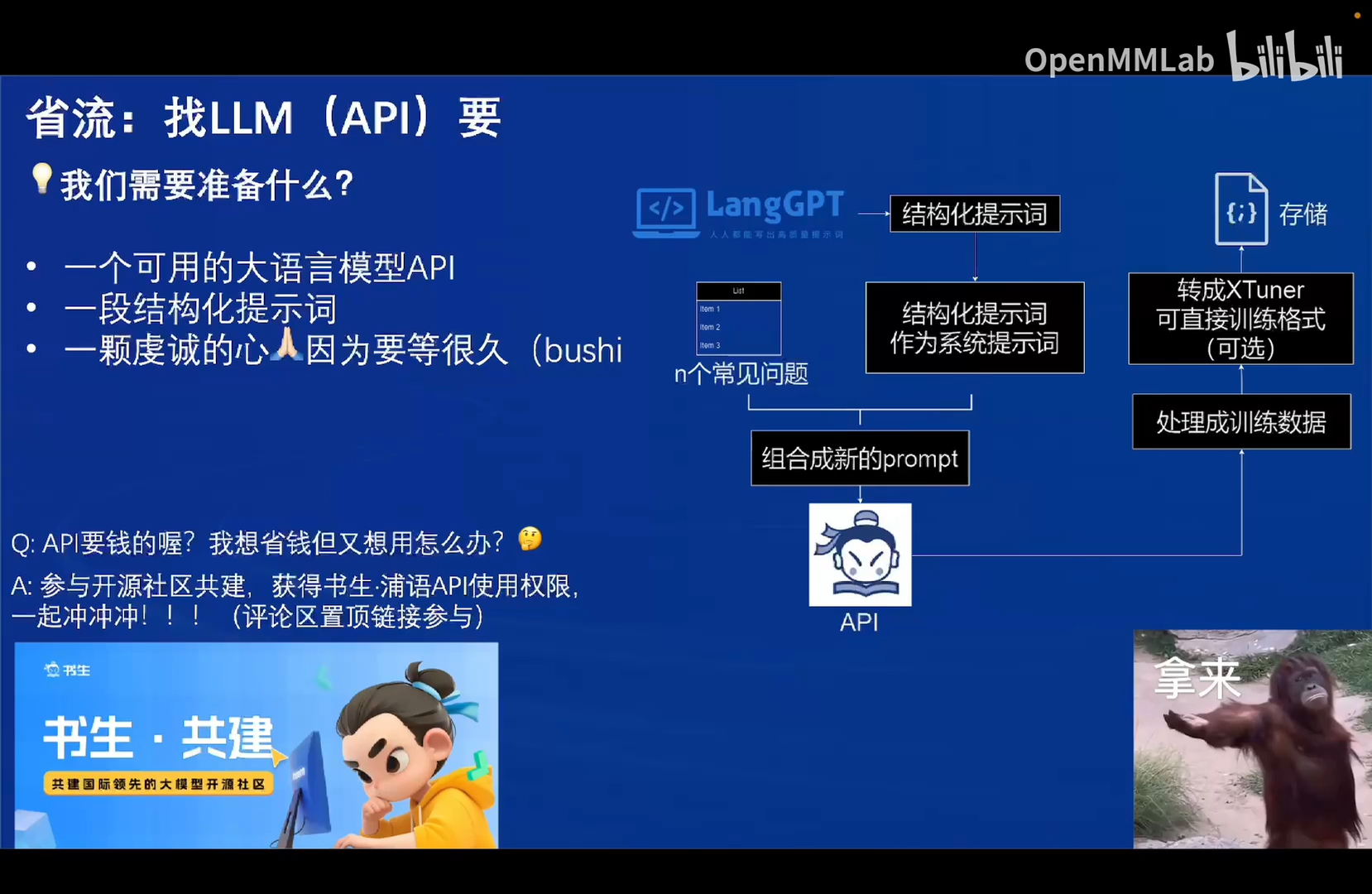
如何准备训练数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号