第三章 词法分析
第三章 词法分析
章节脉络
词法分析器的核心任务是读入字符流,产生记号(token)序列,交给语法分析使用;
换言之,词法分析的IO接口如下图所示:

下面是一个词法分析的IO接口的具体例子:

IO接口明确后,我们该如何实现一个词法分析器呢?
有两种方法:手工构造法和自动生成。简单来说,手工构造法就是完整地编码实现IO接口,代码量大,而自动生成只需编写词法规则,将词法规则交给词法分析器的生成器就可以直接生成一个词法分析器的完整程序,代码量小。
-
手工构造法的核心是状态转换图,通过模拟转换图的过程,就可以实现词法记号的识别,一个典型的转换图和它的算法实现如下:

但是,构造能够完美识别所有词法记号的转换图并非易事,有许多困难。其中一个便是标识符和关键字的区分问题,造成的原因是关键字是符合标识符的模式的,要把关键字从标识符中挑出来。要解决这个问题,方法很多,比如:(1)改造转换图;(2)关键字表算法
改造转移图的例子如下,这个例子中我们通过改造转换图使它能够单独识别出关键字
if
关键字表算法的算法流程如下:

-
自动生成词法分析器的流程很简单。首先编写词法规则,将词法规则交给词法分析器生成器,然后生成器就可以输出完整可用的词法分析器的代码了。流程图如下所示:
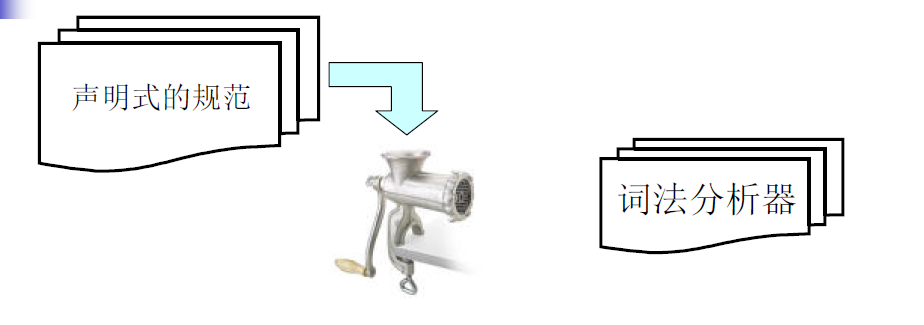
典型的,我们一般用正则表达式来描述词法规则(即上图中的声明式的规范)。但是,要从正则表达式最终得到词法分析器的代码,还需要经过一系列的中间环节,如下图所示:
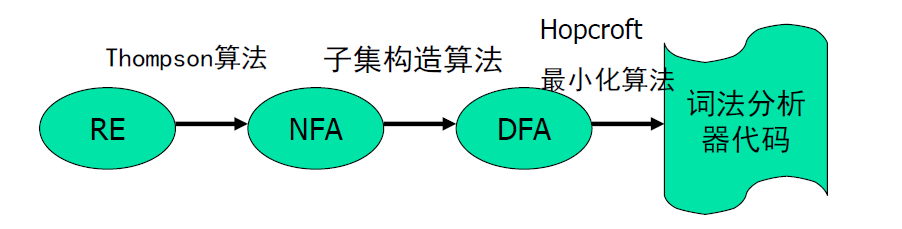
因此,我们要学习:
- 正则表达式的知识
- NFA、DFA的知识
- 如何从RE到NFA、NFA到DFA、DFA最小化的三个算法
可以说的是,最终的DFA是一个有向图,我们只需要用算法模拟这个有向图即可得到词法分析器的代码。
最后,我们还要额外学习如何从NFA得到RE。
词法记号、模式、词素
- 词法记号(单词,token):源语言文法的终结符,用<token name, token value>表示。
- 词法规则(模式,pattern):源语言中特定记号的构成规则,可以用正则表达式表示
- 词法单元(词素,lexeme):源程序中和记号的模式相匹配的字符串
正则表达式\(\Leftrightarrow\)正则语言
定义:可以用一个正则表达式定义的语言称为正则语言。
句式:......的所有字符串集合
例1

切入点:
- 从字符个数的奇偶性来描述
- 以...开头,以...结尾的
*:零个或多个...组成的- 包含/不包含...子串/子序列
例2

-
仅包含两个1:先把两个1写出来,在前后和它们之间插入任意多个0
-
不包含连续的0,有以下情况:
- 空串
- 以0开头
- 单个0
- 01开头
- 以1开头
其中1或01开头可以重复任意多次
-
由两部分组成
(1*01*01*)表示仅包含两个0的01字符串,将它整体做闭包运算,就可以得到偶数个0的字符串(0个或者2的倍数个)- 再考虑这个字符串可能会以1结尾,所以在最后加上
1*
正则表达式的运算律
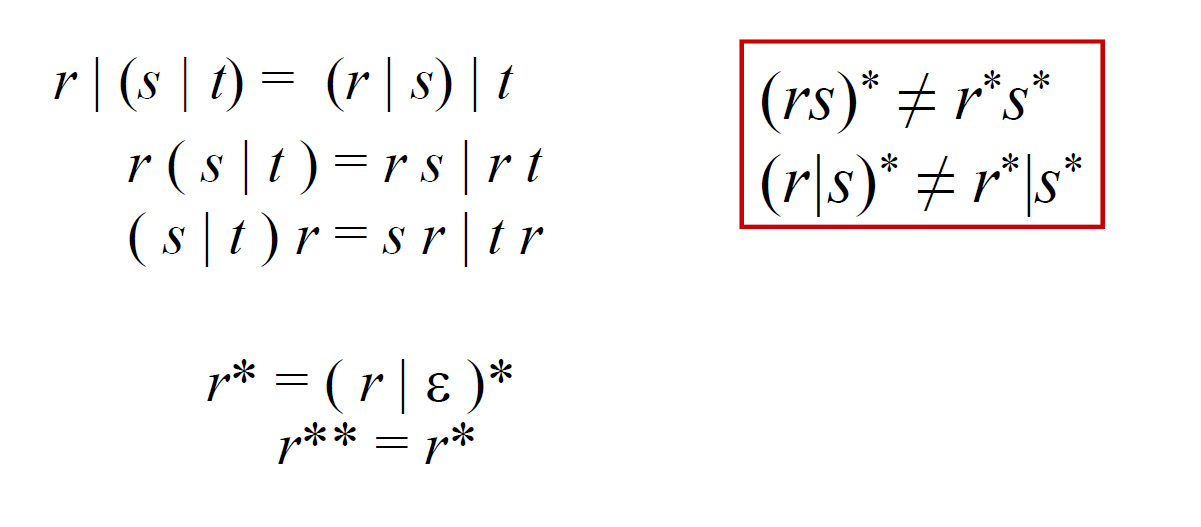
|可结合- 连接对
|可分配(左分配和右分配) - 闭包中一定包含\(\epsilon\)
*具有幂等性
常见正则定义
1、C语言的标识符

2、无符号数

扩展的正则表达式

正则表达式\(\Leftrightarrow\)状态转换图
例1
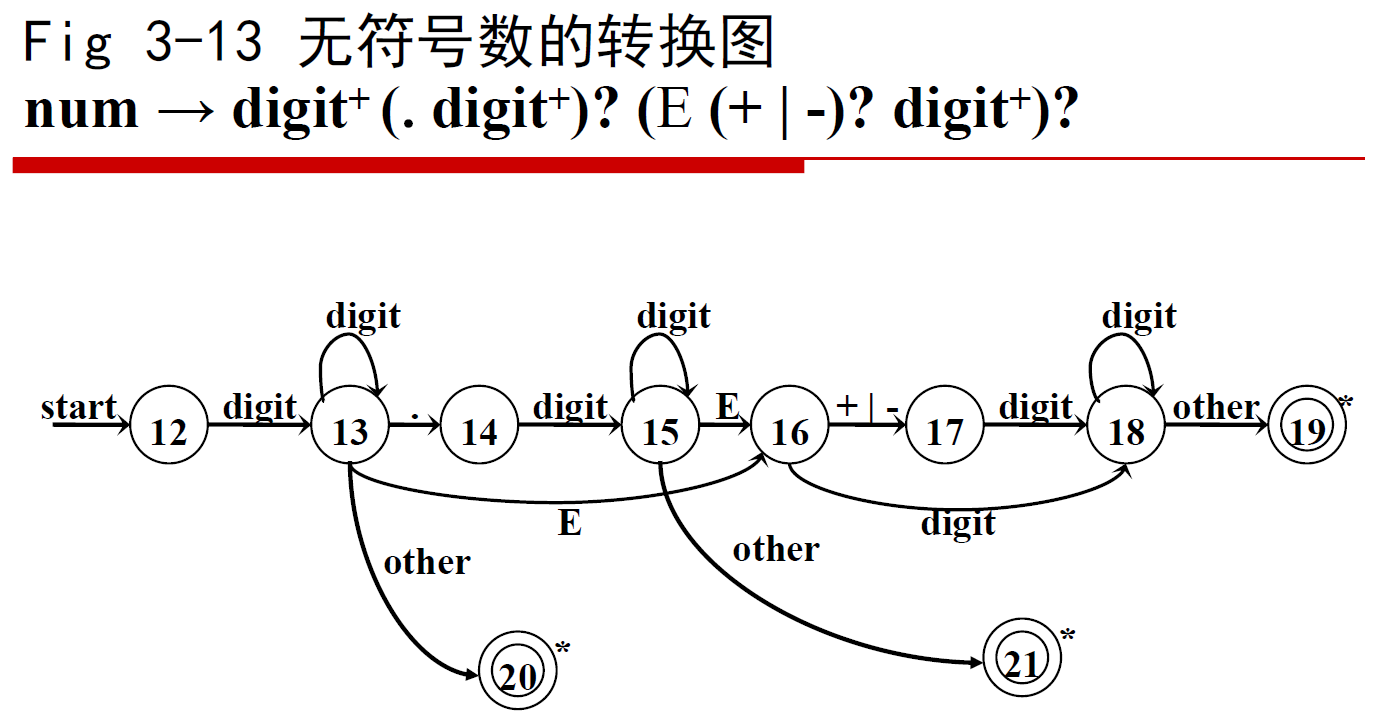
总结出一些表达方式:
-
kleene闭包:自旋表示,例如
digit*可以表示为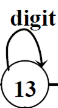
-
正闭包:一个状态转移+自旋表示,例如
digit+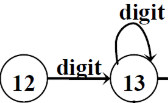
-
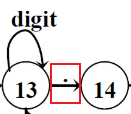
单个字符(集):用一条边(动作)表示,例如
.
-
?:这个比较复杂,用上面的例子做解释,先表示正则表达式里的问号从左到右为1,2,3- 1,3:后面的两个部分都可以不存在,从状态13直接转移到终止状态
- 3:第三部分可以不存在,从状态15直接转移到终止状态
- 1:第二部分可以不存在,但第三部分存在,从状态13读入一个
E转移到状态16 - 2:
(+|-)可以不存在,但E后有数字,从状态16读入一个数字转移到状态18,然后自旋读入数字
例2
幂集
数学上,集合的幂集(英语:power set),定义为由该集合全部子集为元素构成的集合。给定集合S,其幂集P(S)以符号表示即为:
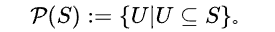

NFA和DFA
- [NFA]
(a|b)*abb
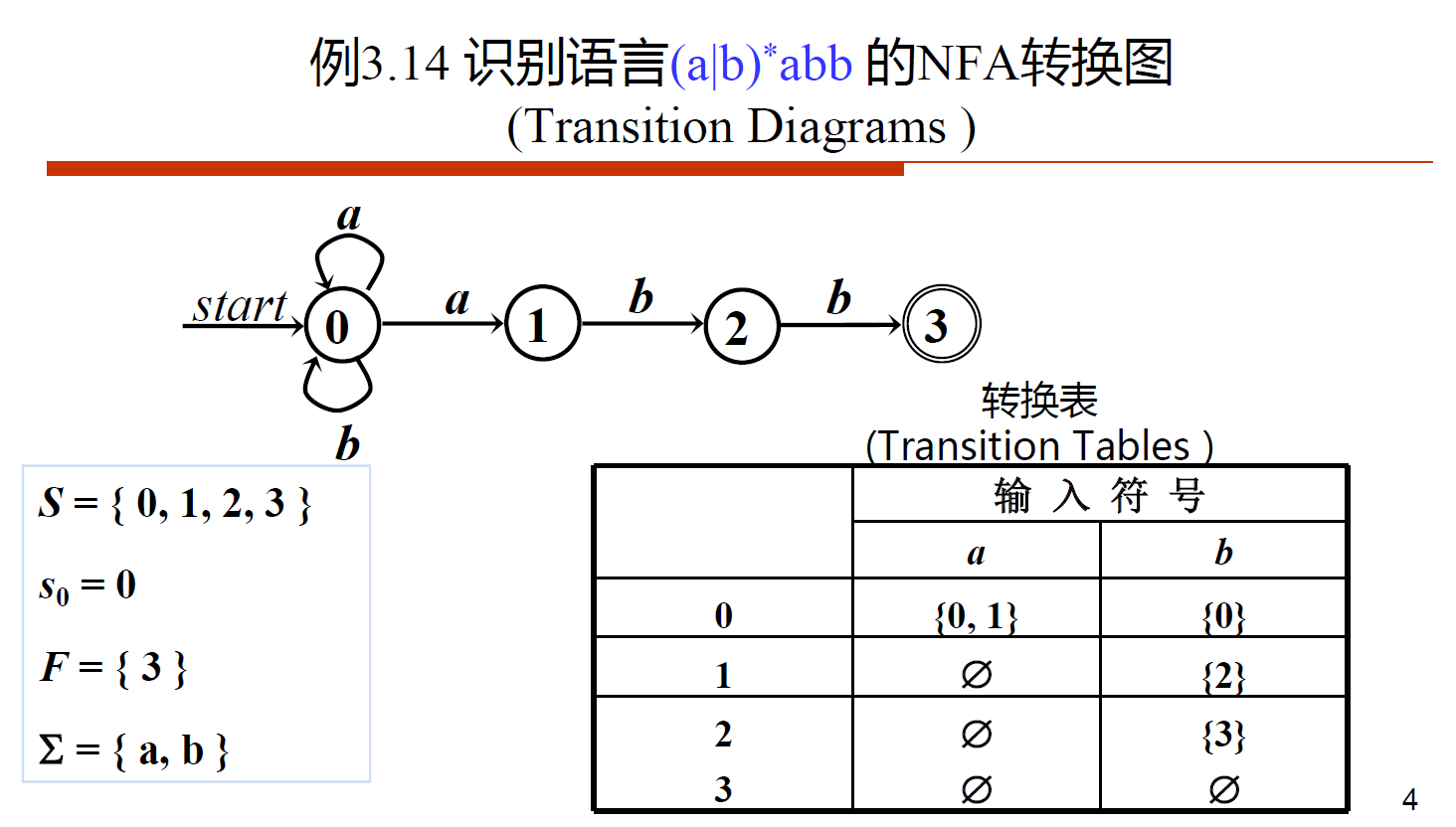
- [DFA]
(a|b)*abb
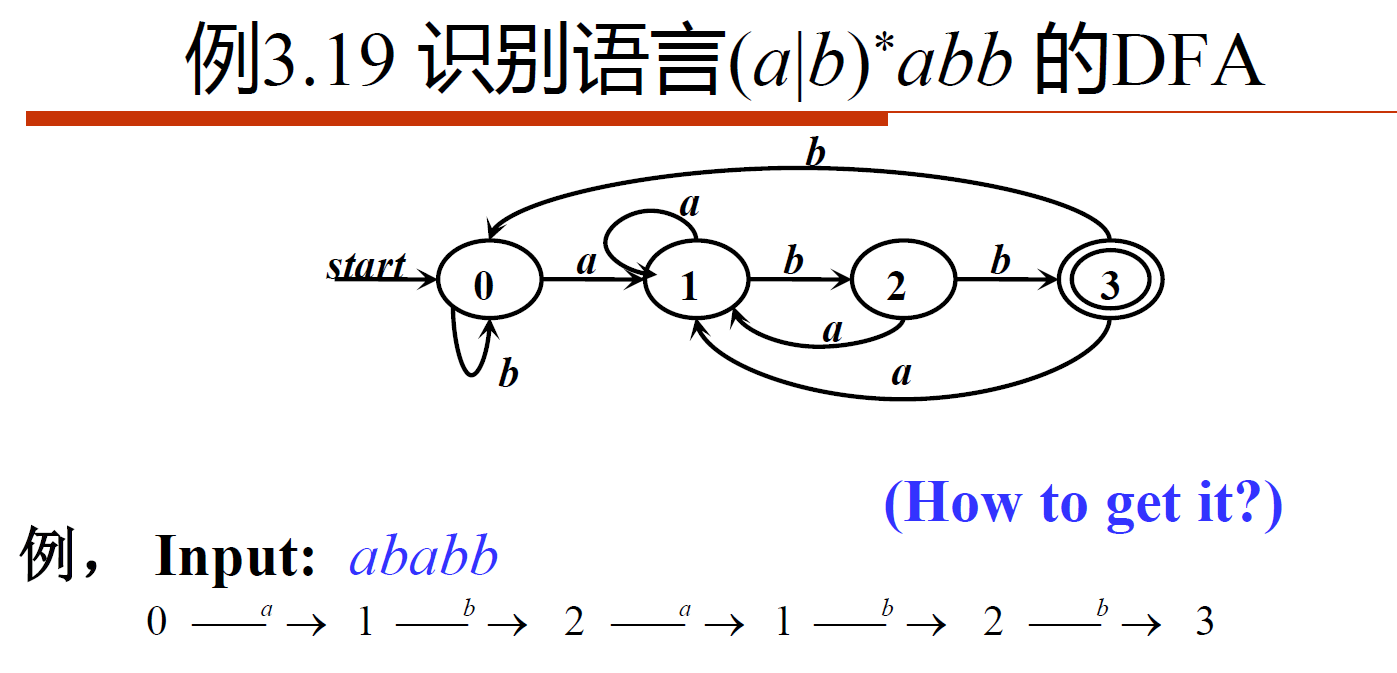
- [NFA]
aa*|bb*
- [DFA] 包含子串000的01串
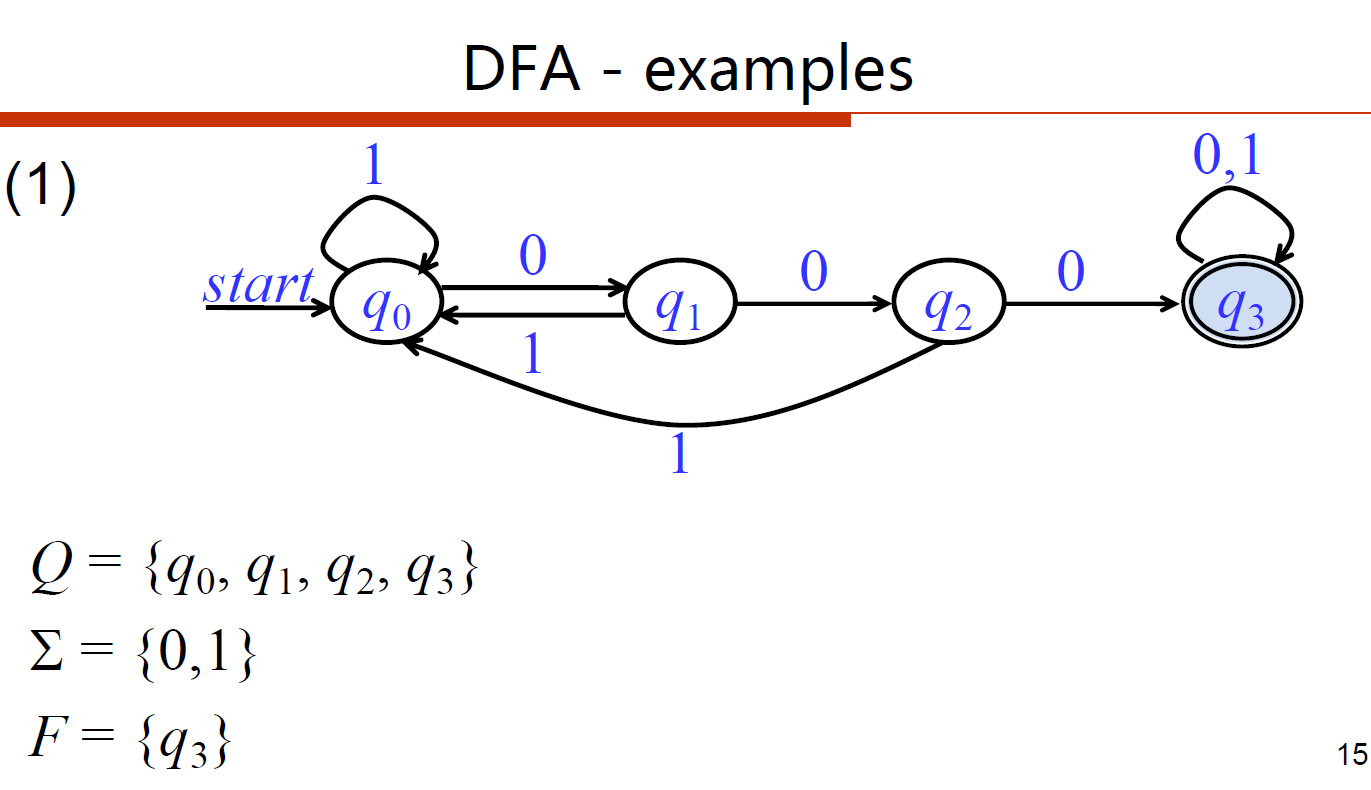
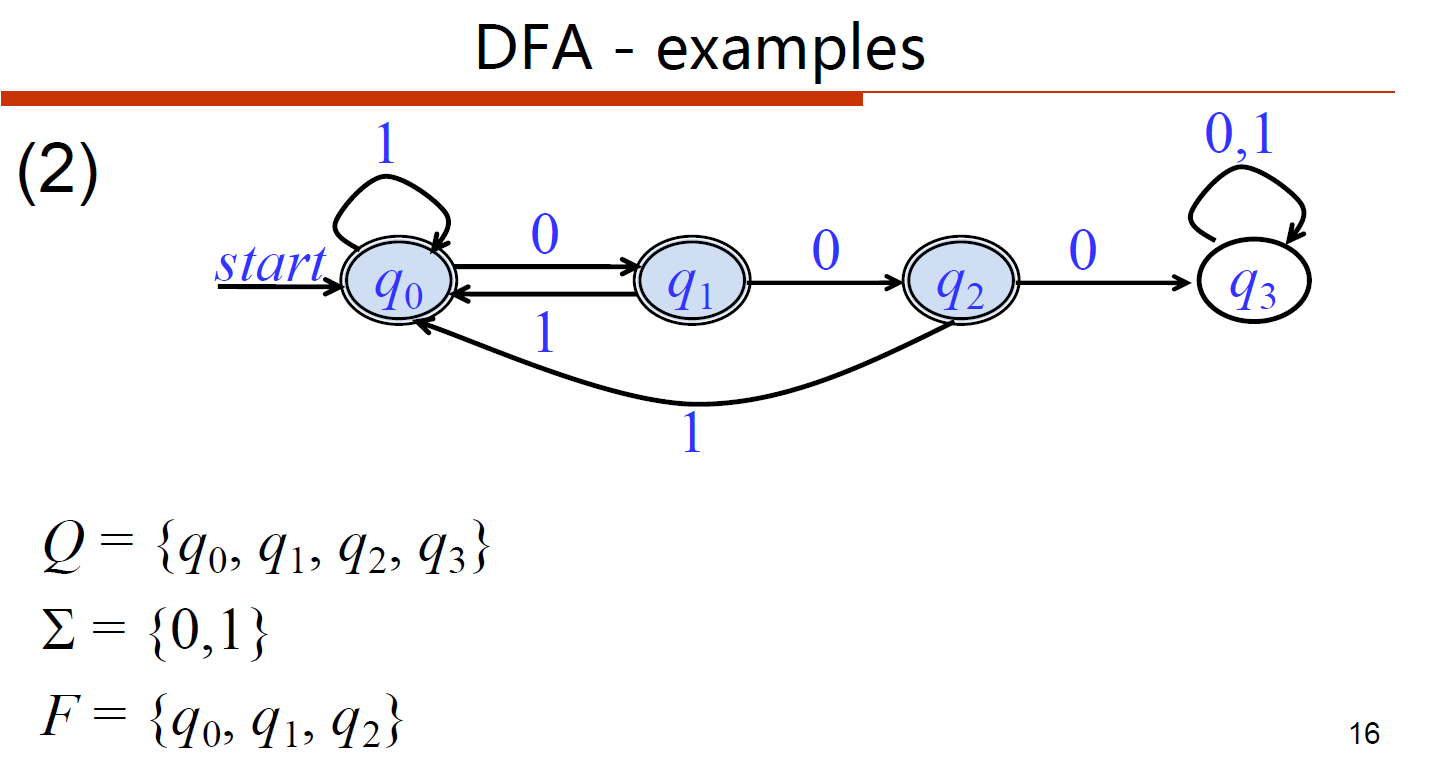
- [DFA]不包含子串000的01串
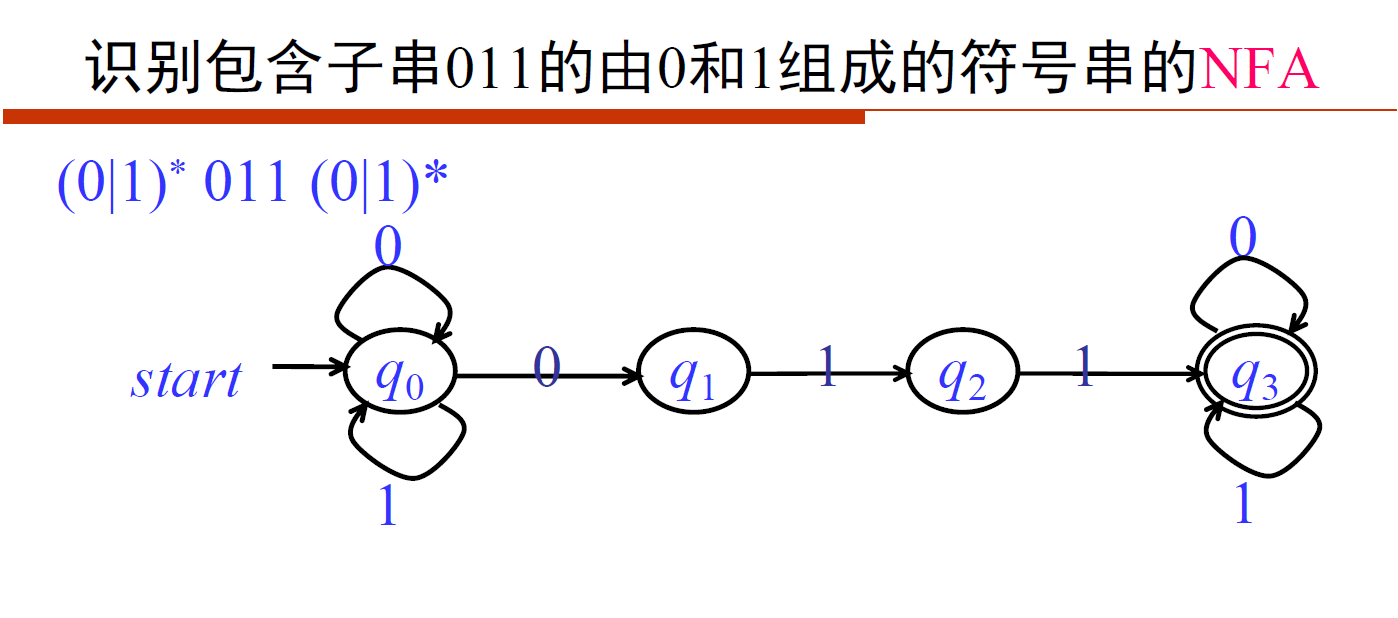
- [NFA]包含子串011的01串
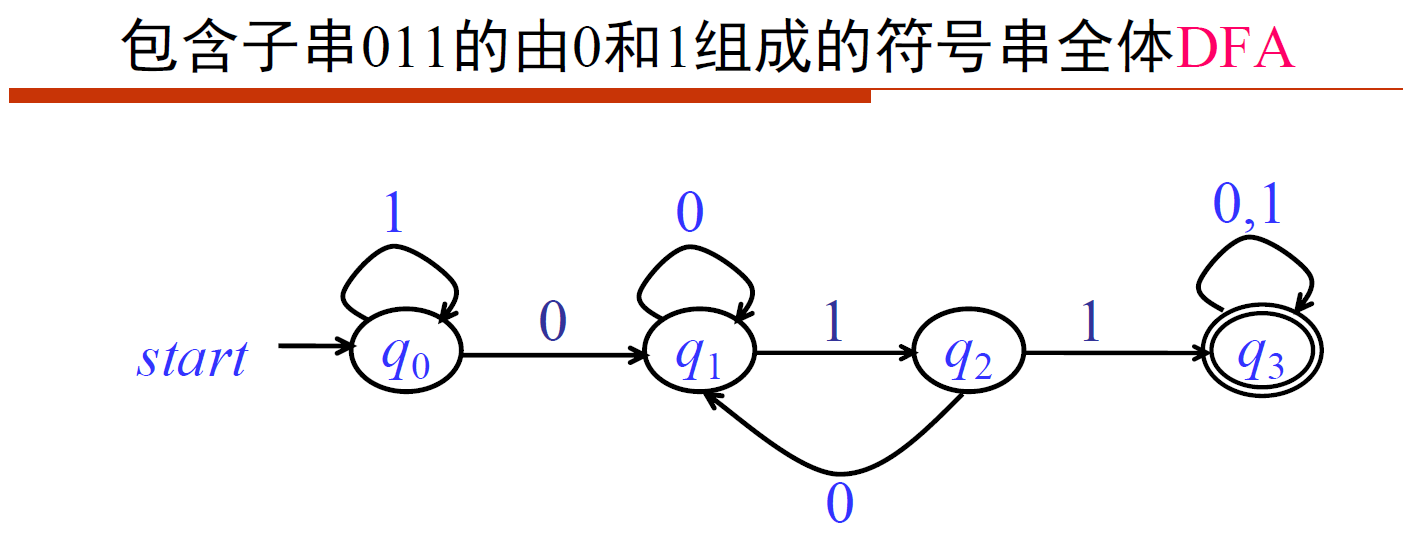
- [DFA]包含子串011的01串
- [DFA]不包含子串011的01串
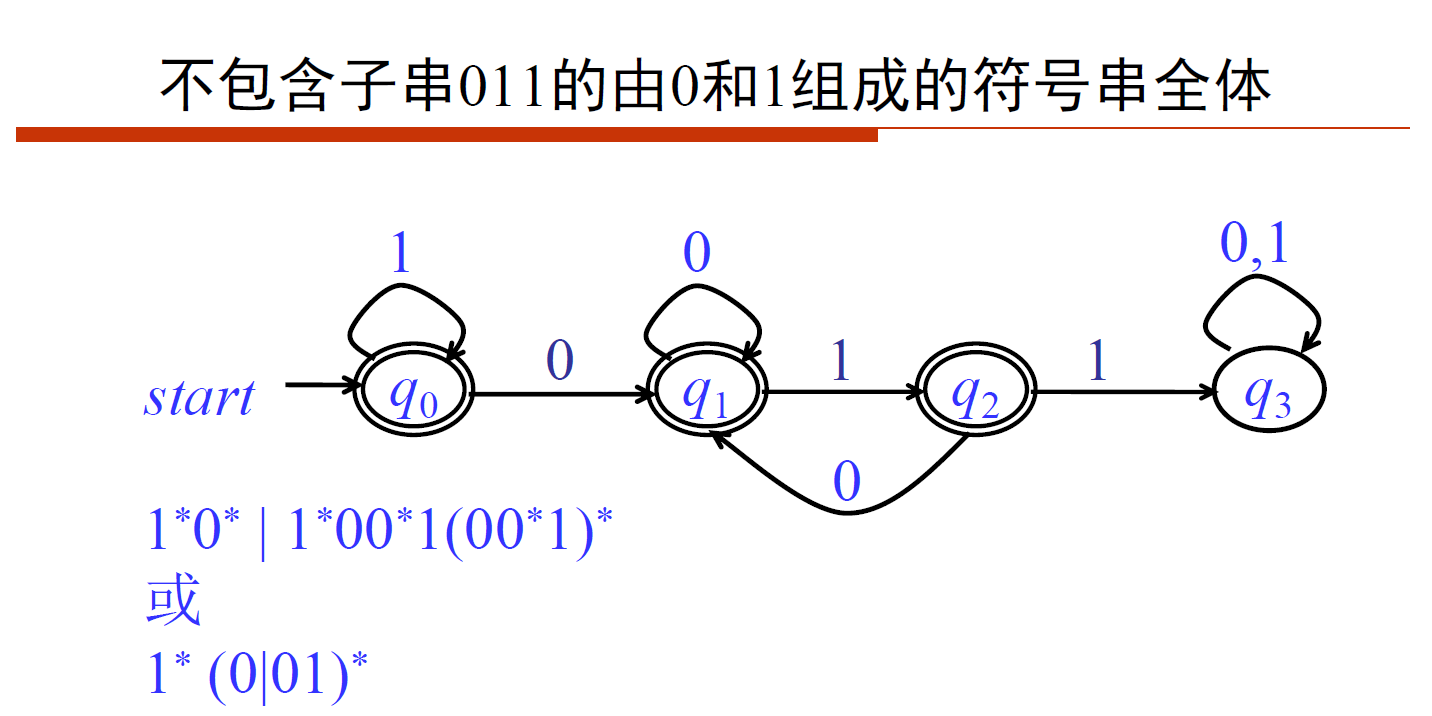
- [DFA]不包含子序列011的01串
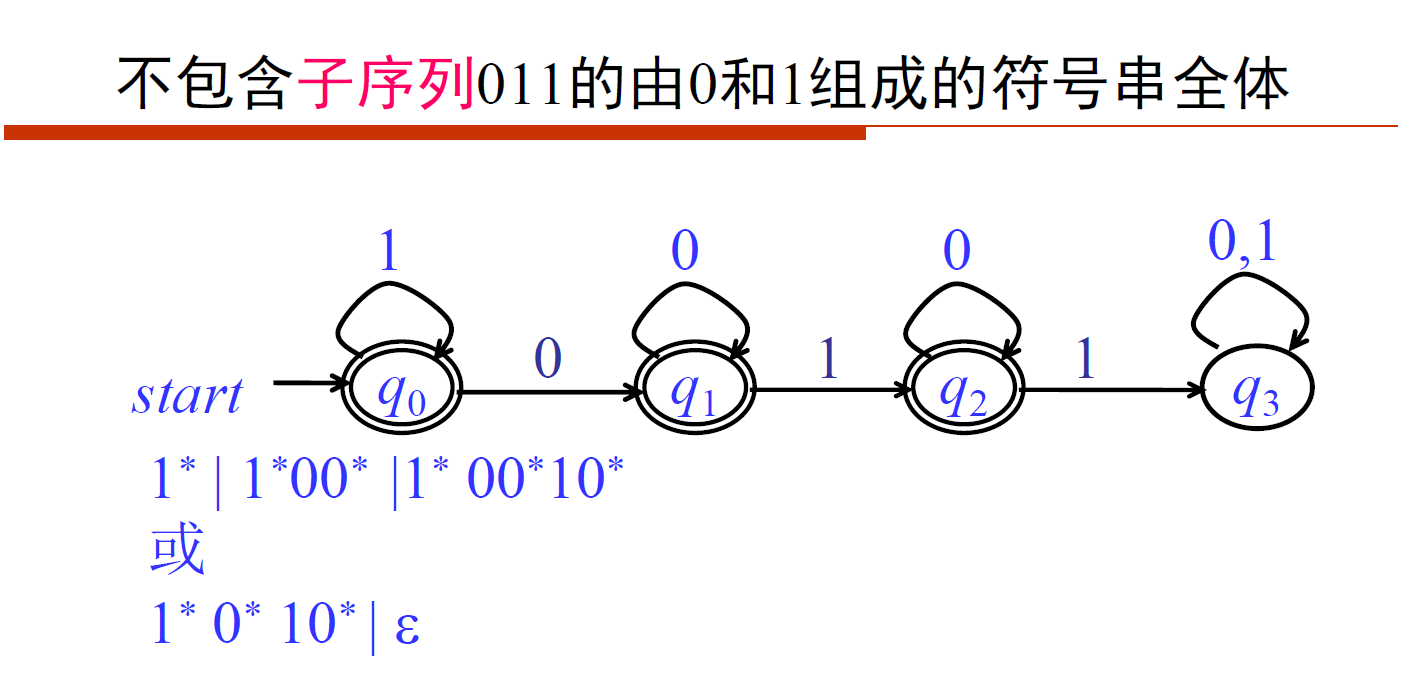
- [DFA]模3余0的01串
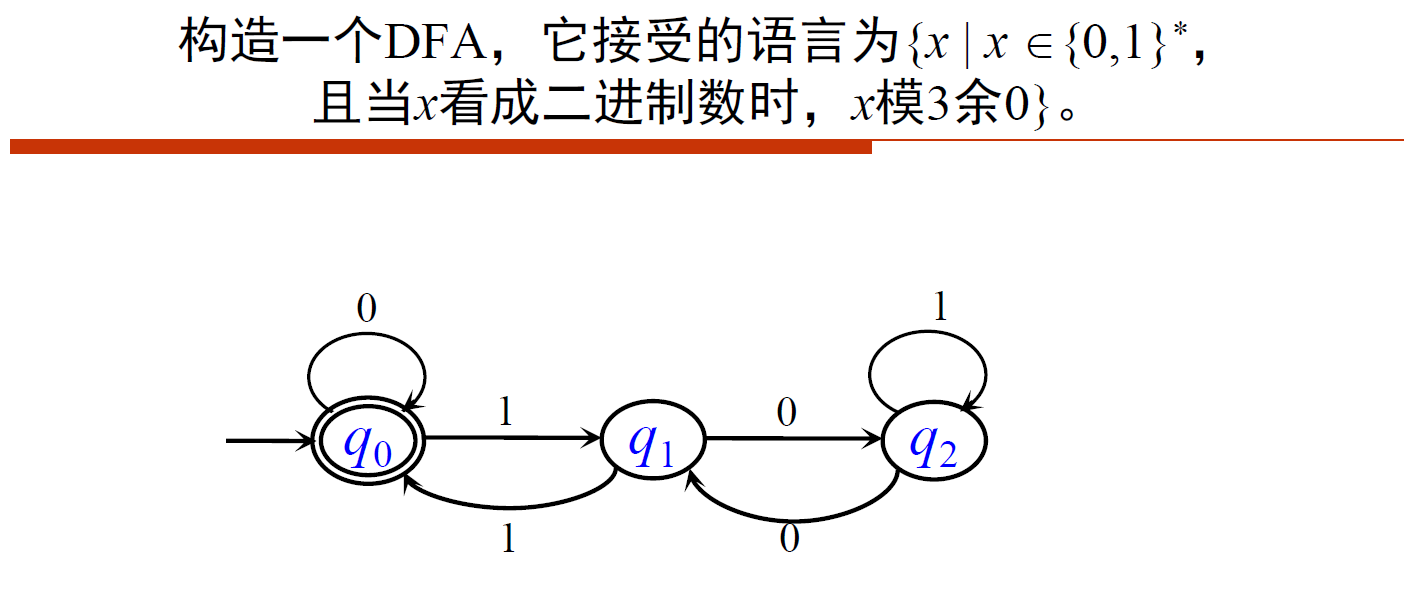
- [DFA]01个数都是偶数的01串
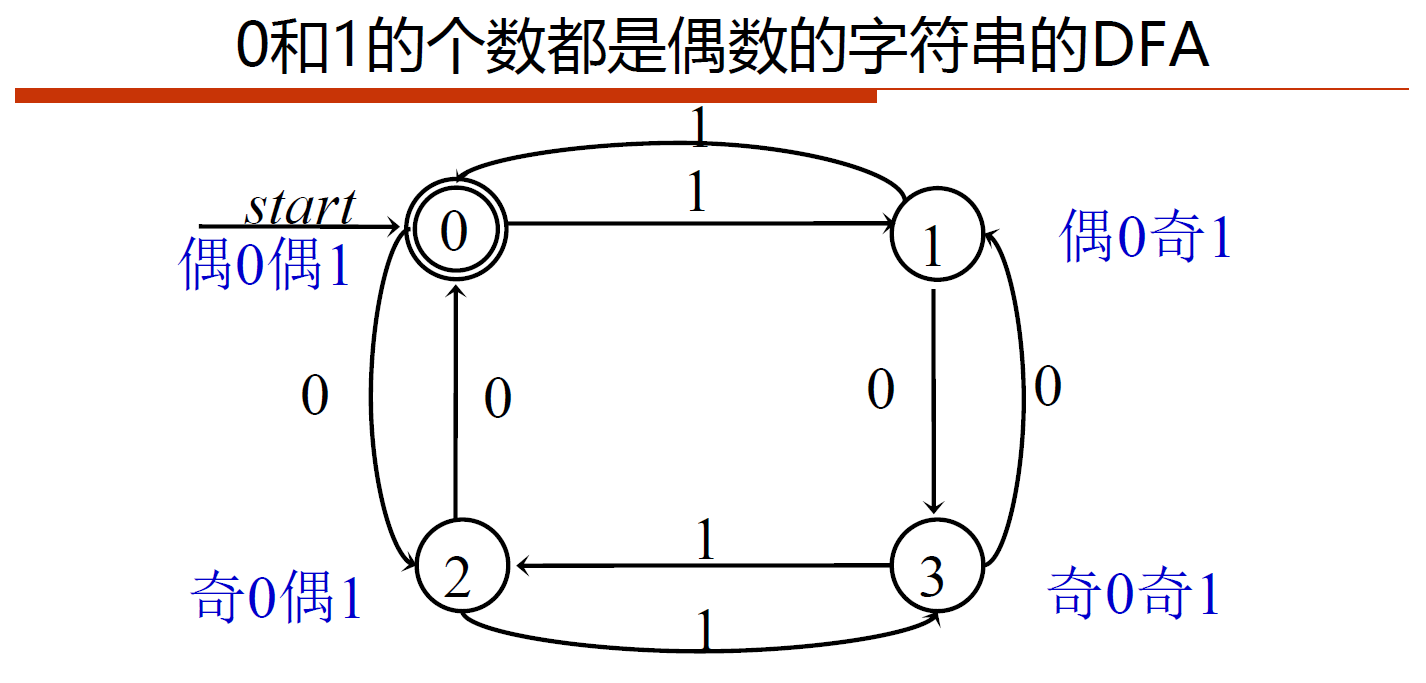
RE\(\Rightarrow\)NFA:Thompson算法
1、算法流程
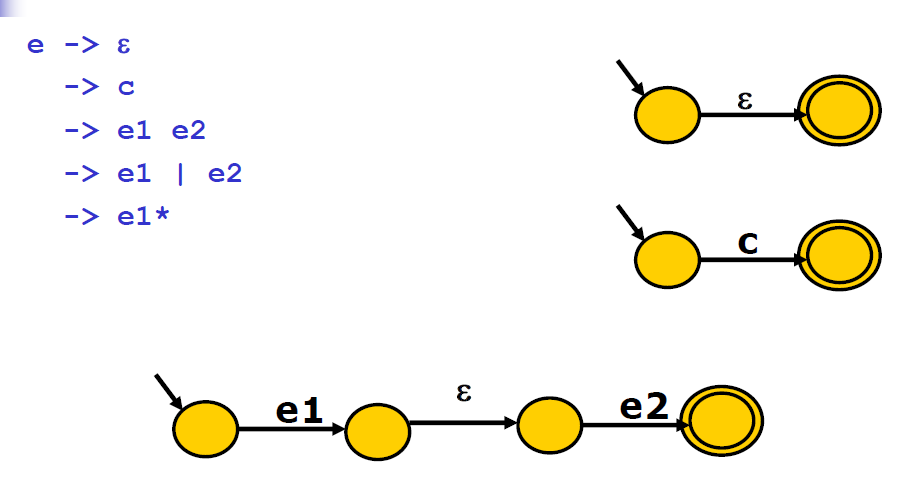
对于\(\epsilon\)和单个符号,直接构造。

对于正则表达式的连接、选择和闭包,递归构造
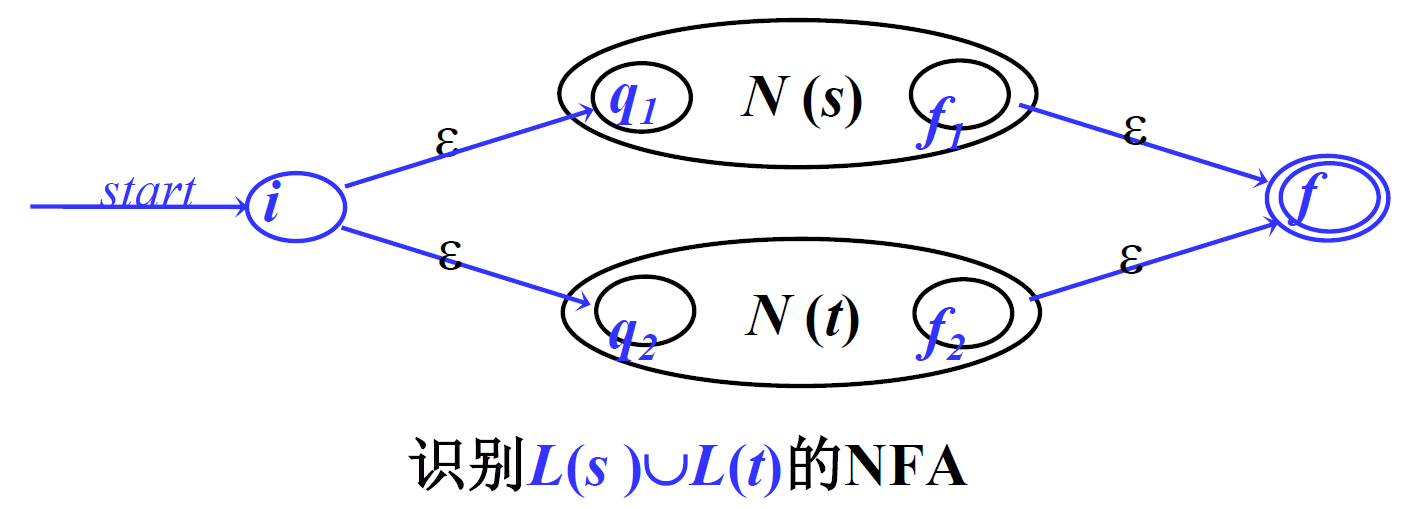
- 选择:增加初始状态S和终止状态T,将原来的两个初始状态与S用\(\epsilon\)相连,原来的两个终止状态与T也用\(\epsilon\)相连。
- 连接:将第一个NFA的终止状态与第二个NFA的初始状态用\(\epsilon\)相连,第一个终止状态变为非终止状态。
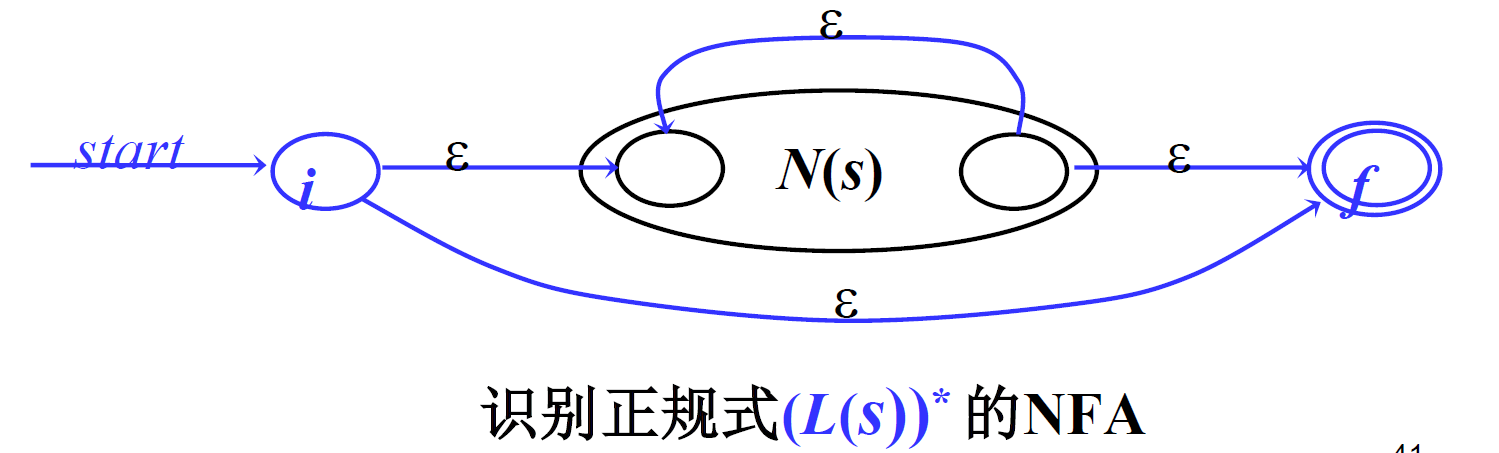
- 闭包:增加初始状态S和终止状态T,S与T用\(\epsilon\)相连,将原来的初始状态与S用\(\epsilon\)相连,原来的终止状态与T也用\(\epsilon\)相连,原初始状态和原终止状态也用\(\epsilon\)相连。
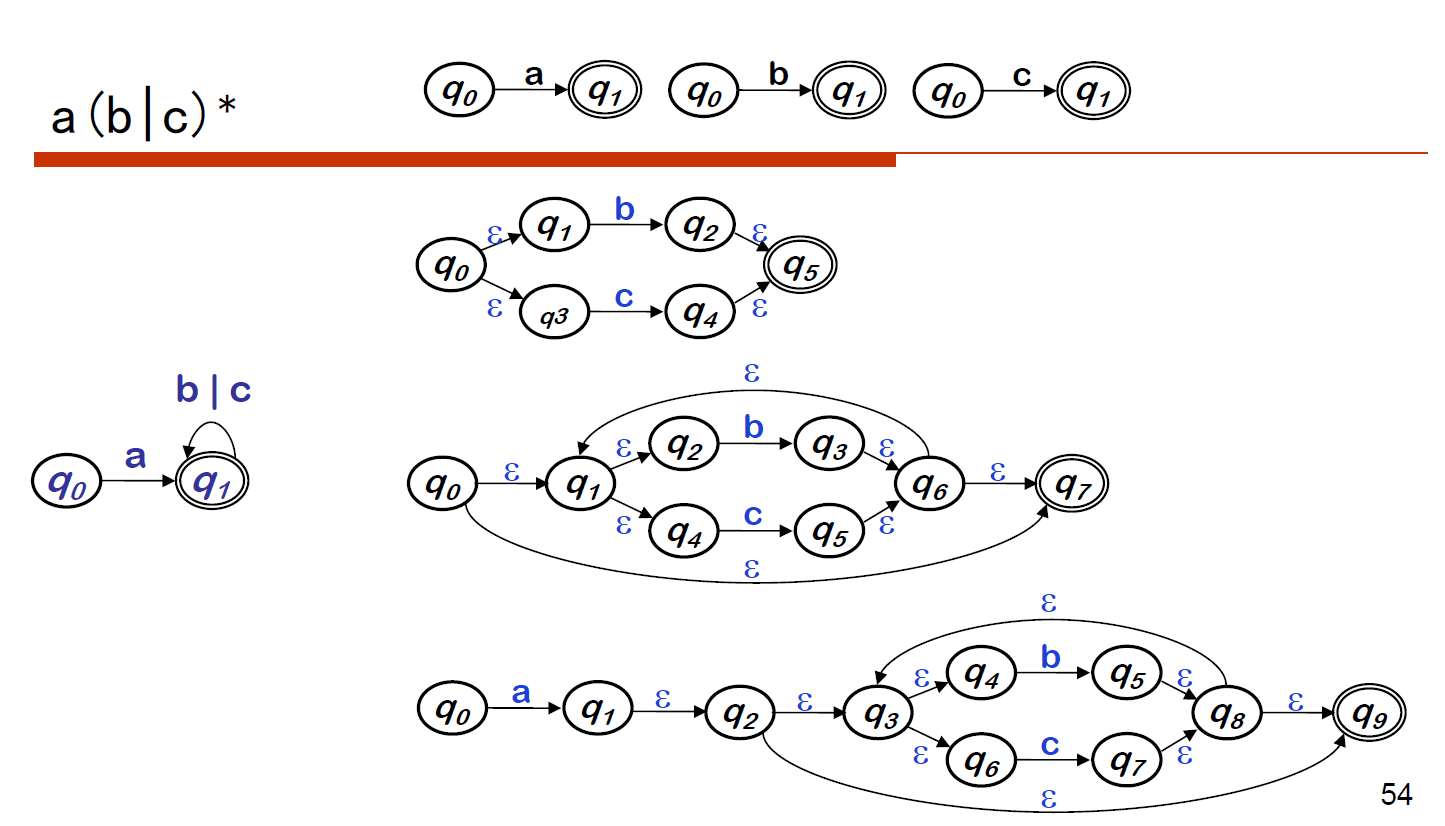
2、例子
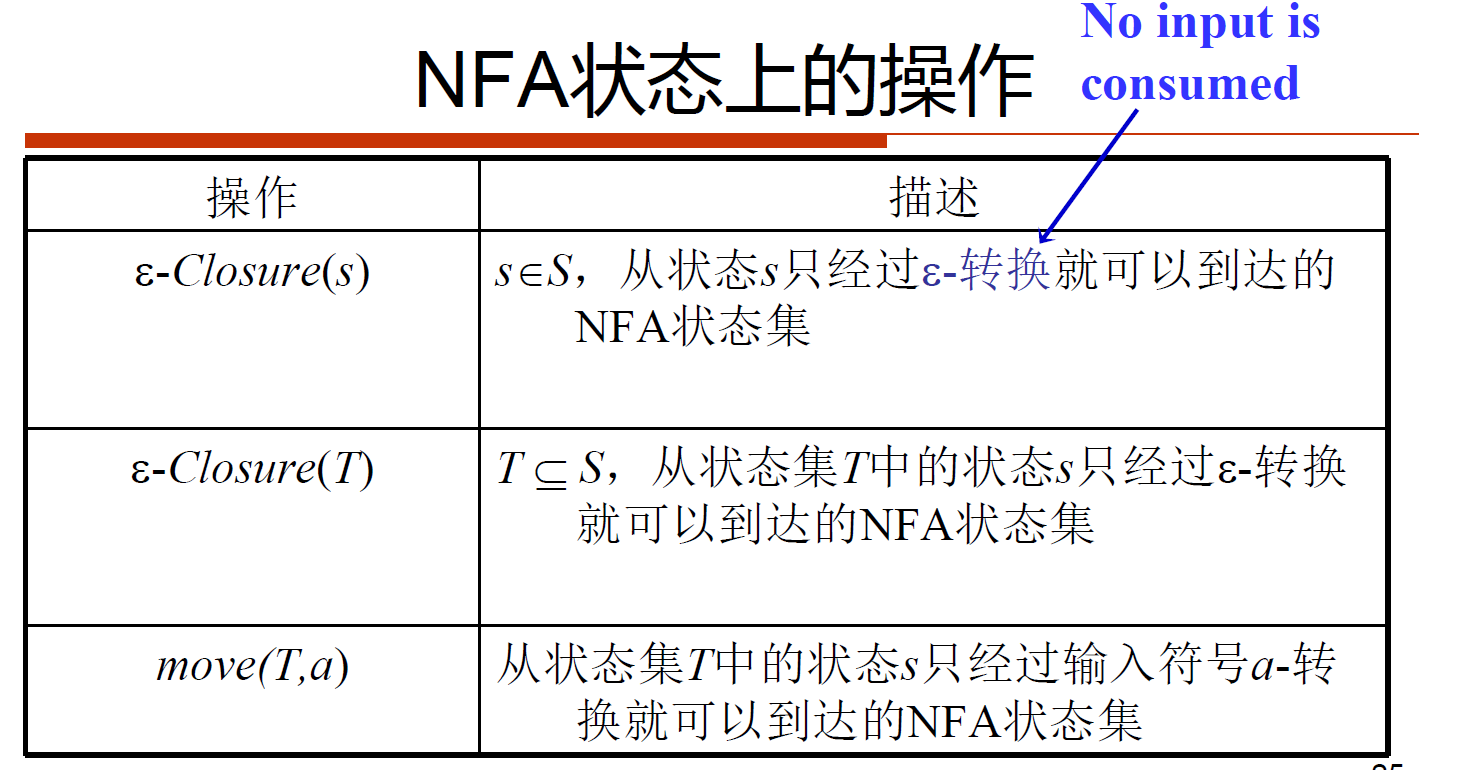
NFA\(\Rightarrow\)DFA:子集构造法
1、算法流程
注意:\(\epsilon-closure\)包括自己



2、例子
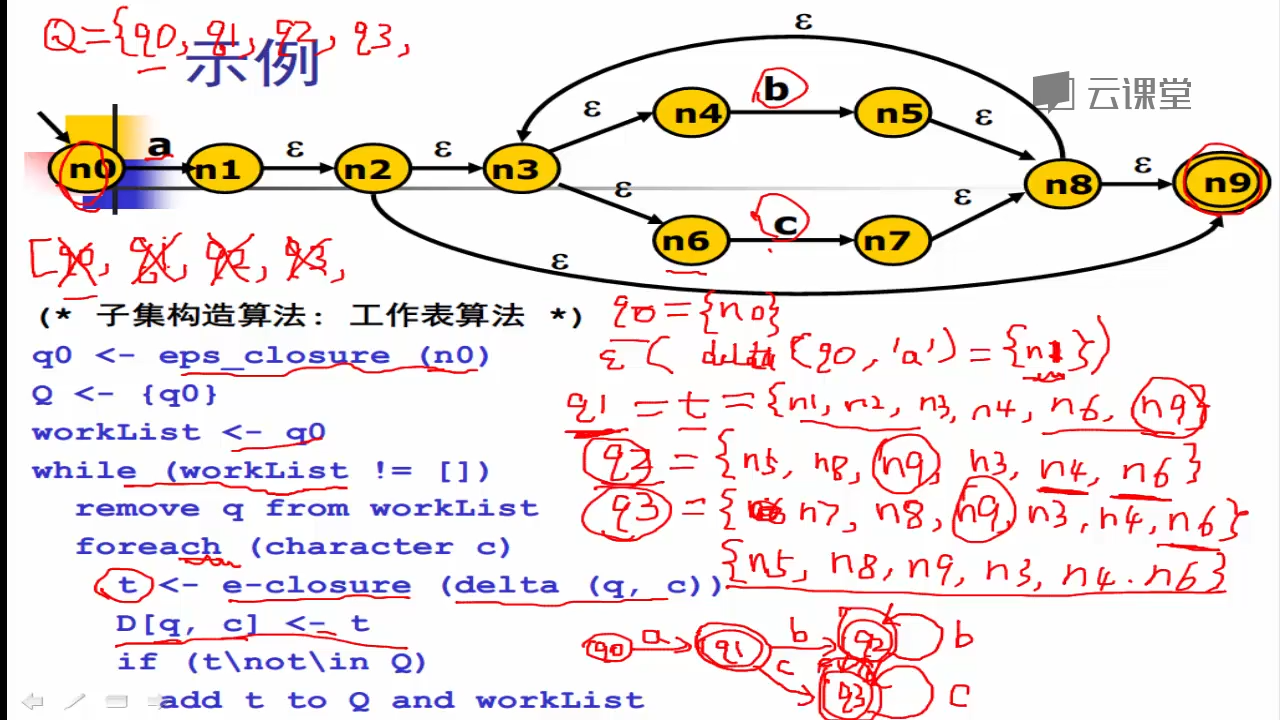
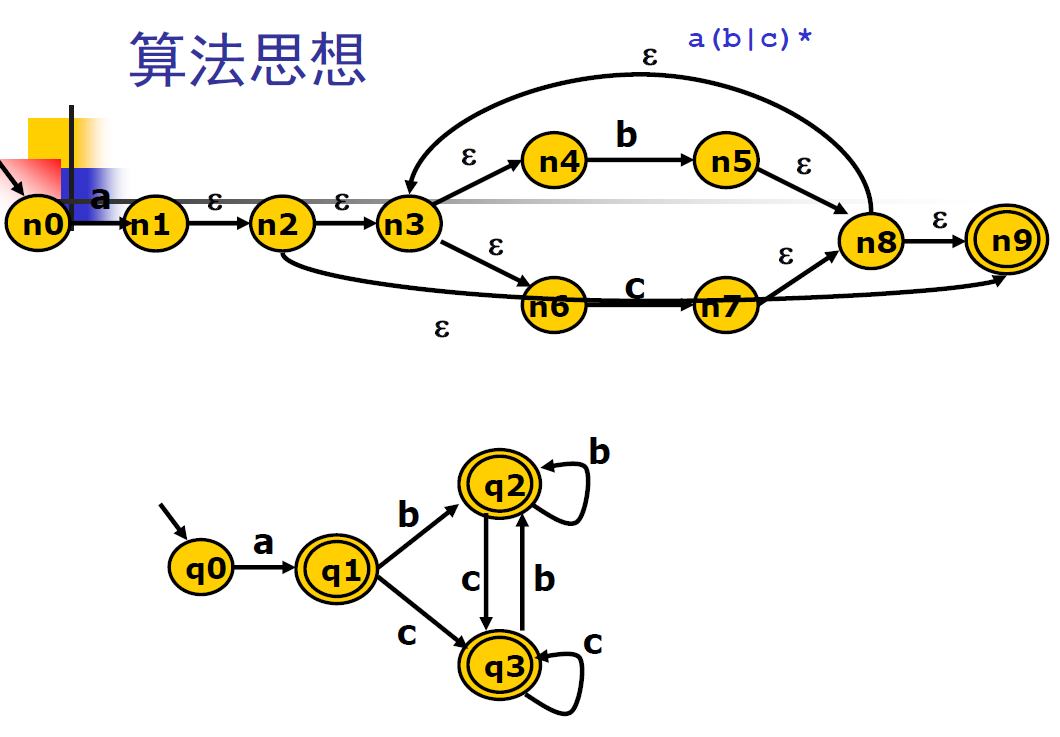
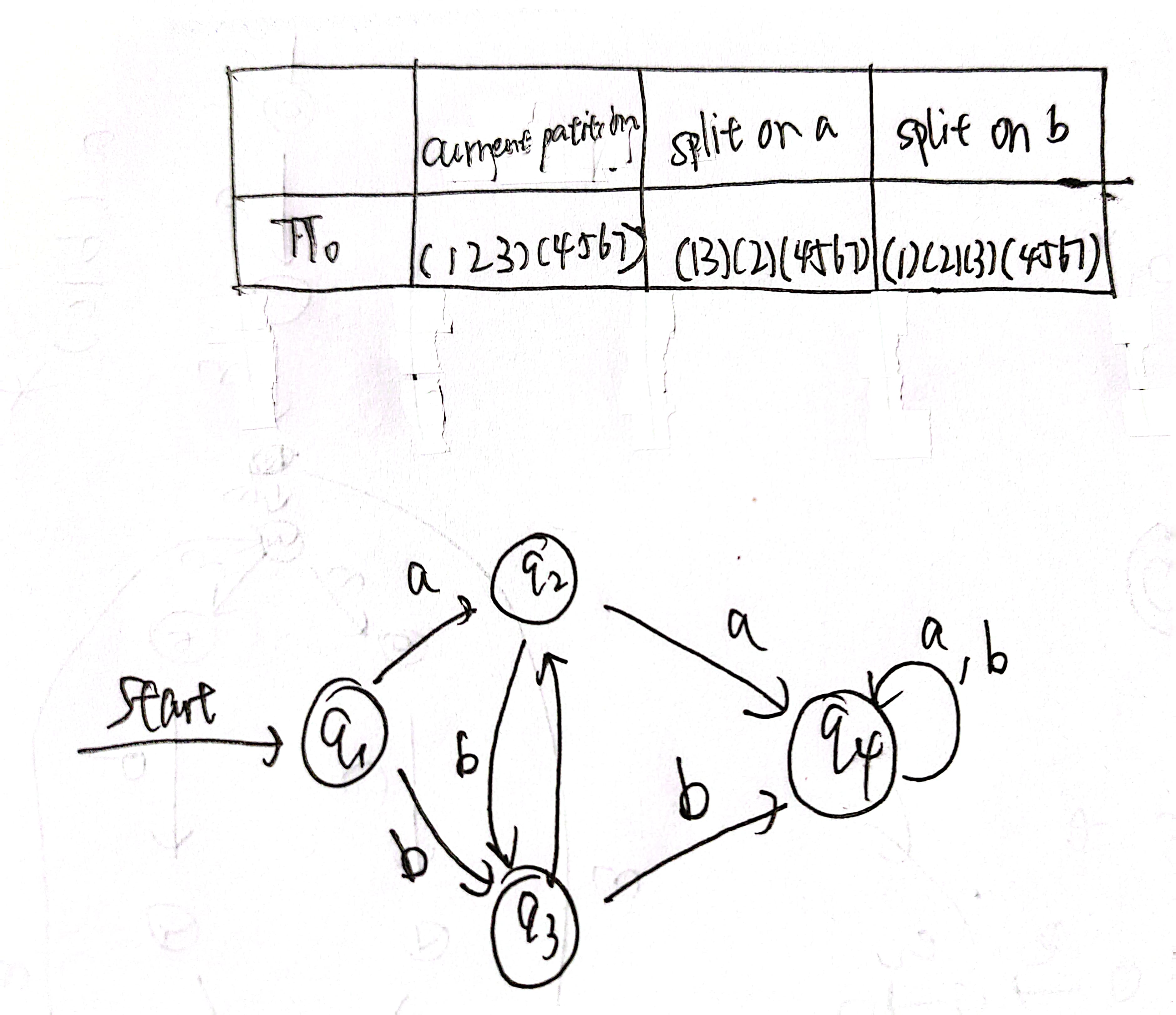
3、练习
- 题目及答案
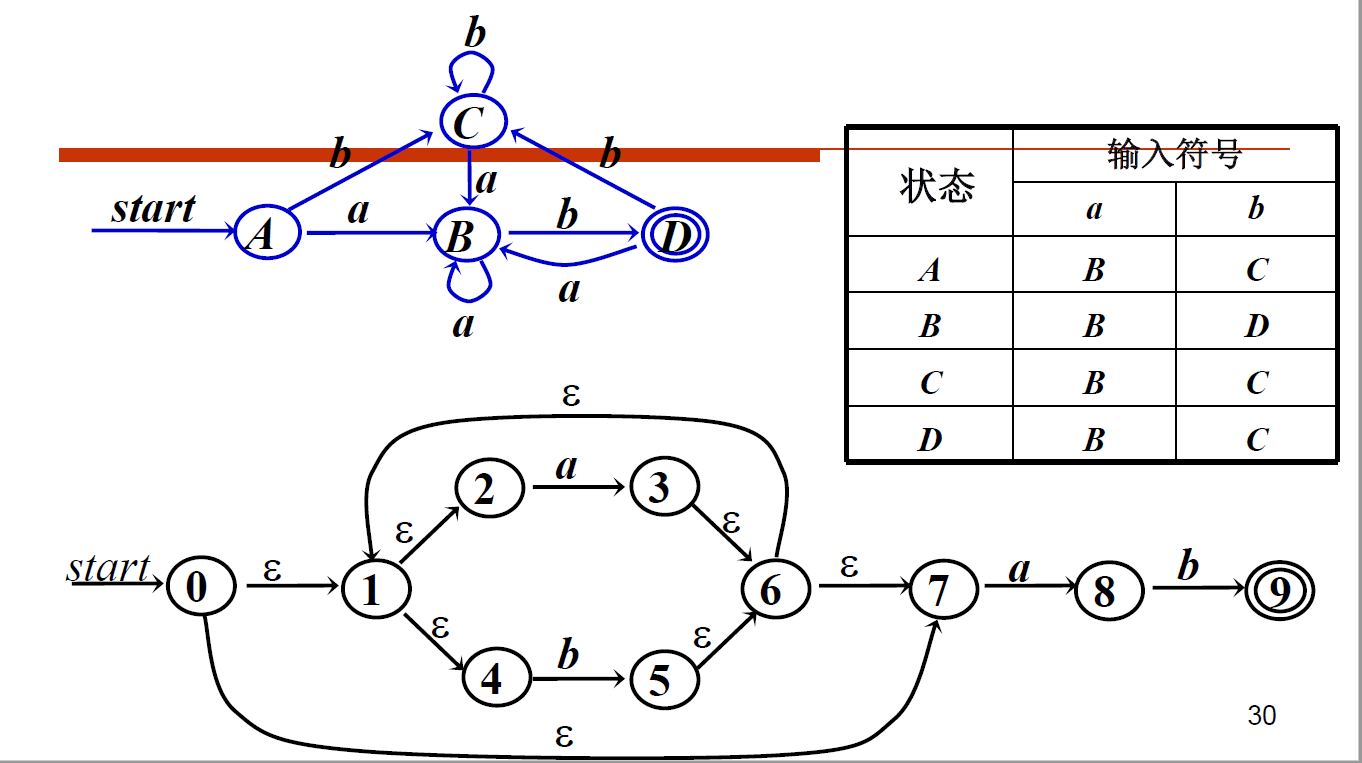
- 我的做法
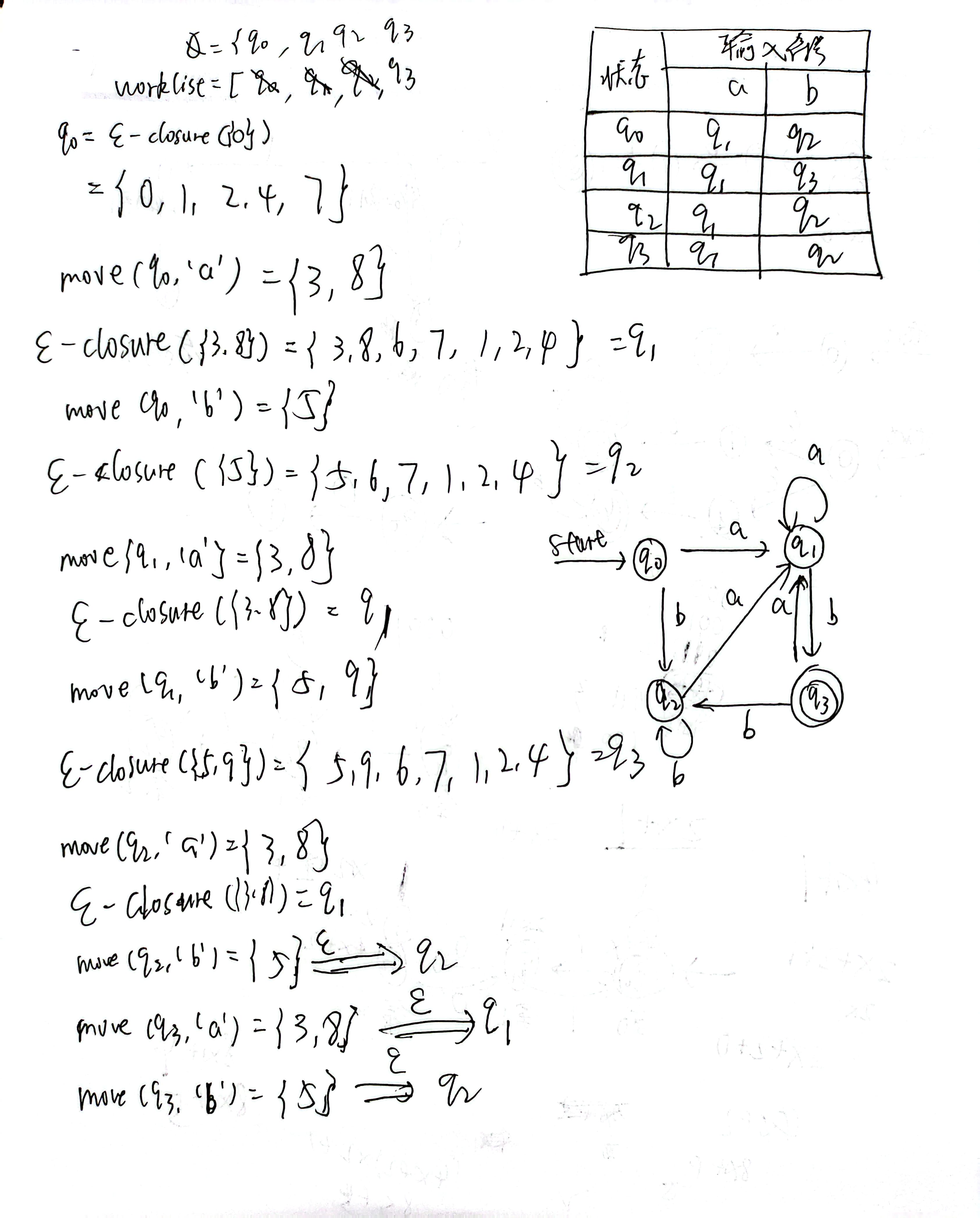
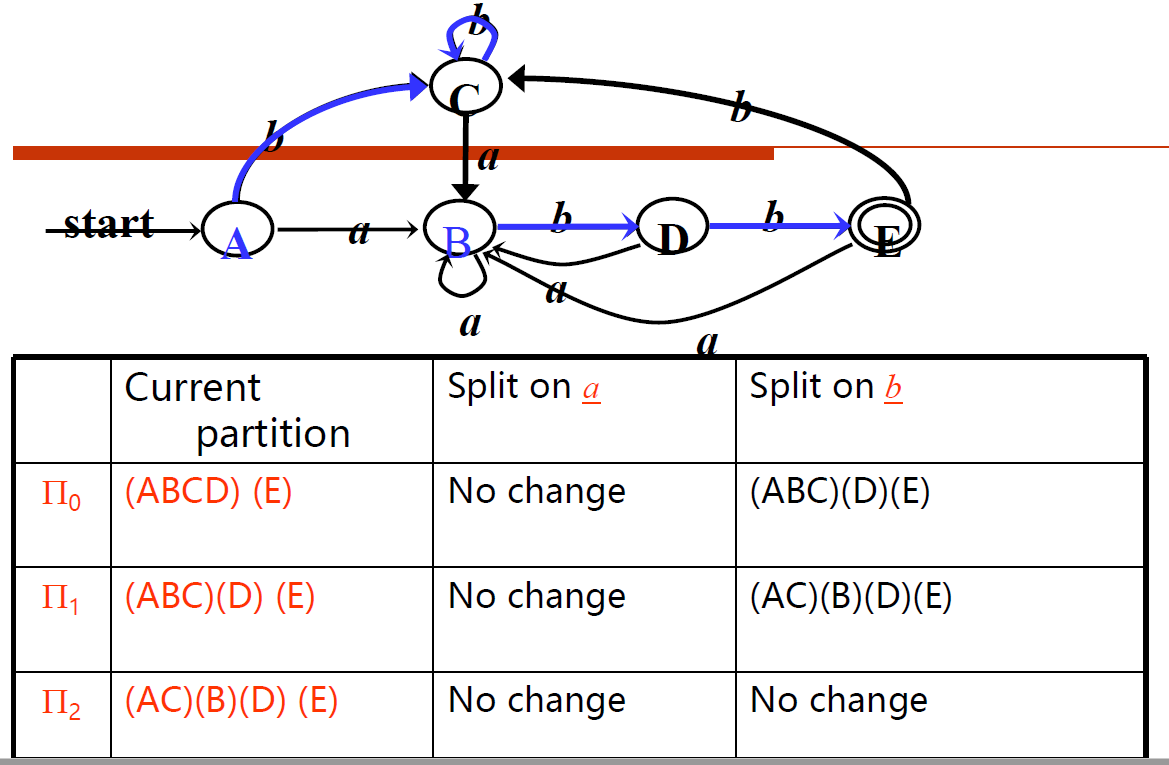
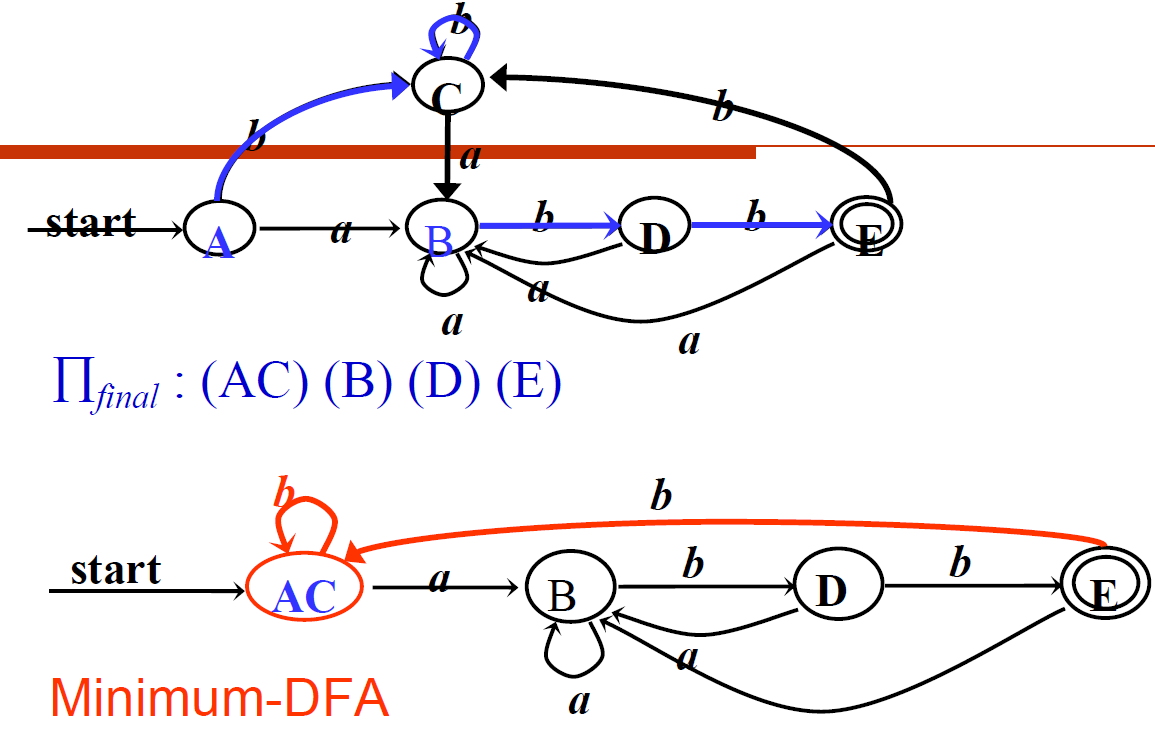
DFA最小化:Hopcroft算法
1、算法流程

解释:
- 初始划分\(\Pi_0\)包括两个组:接受状态组和非接受状态组
- 对于每个组,遍历字符集,如果对于字符\(c\),将通过c转移到相同组的状态划分为一组,转移到不同组的状态划分到不同组,直到不可继续划分为止(组内只有一个状态或者对于任意字符组内状态转移到的组都相同)
- 把一个组并为一个代表状态r(每组任取一个状态做“代表” ,删去其余状态),并把到达这些状态的箭弧都改作到达r;类似地,从这个组中的每个状态出发的弧,都改作从r出发。这样得到的状态转换图所对应的DFA M1 就是与M等价的具有最少状态的DFA。
- 去除死状态(任何字符都只能转移到自己的)
2、例子
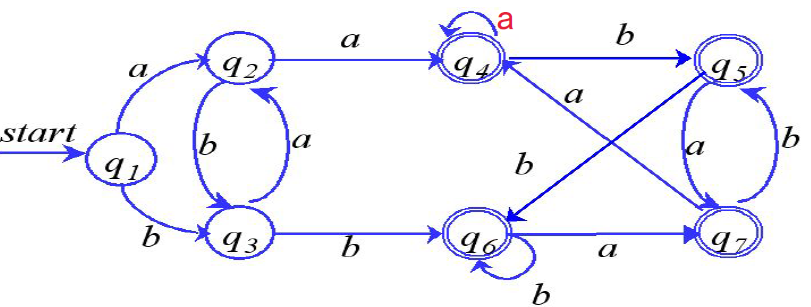
3、练习
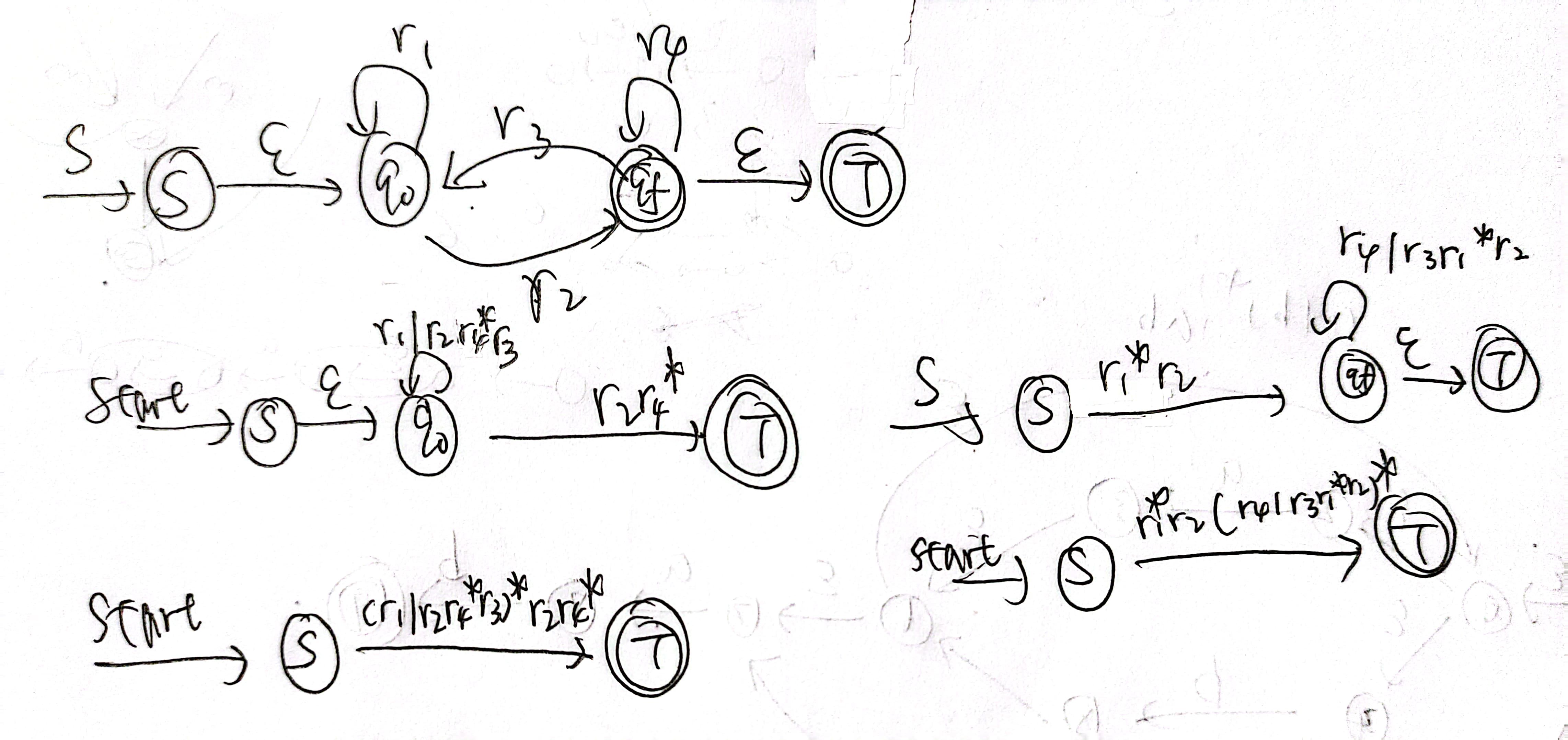
NFA\(\Rightarrow\)RE
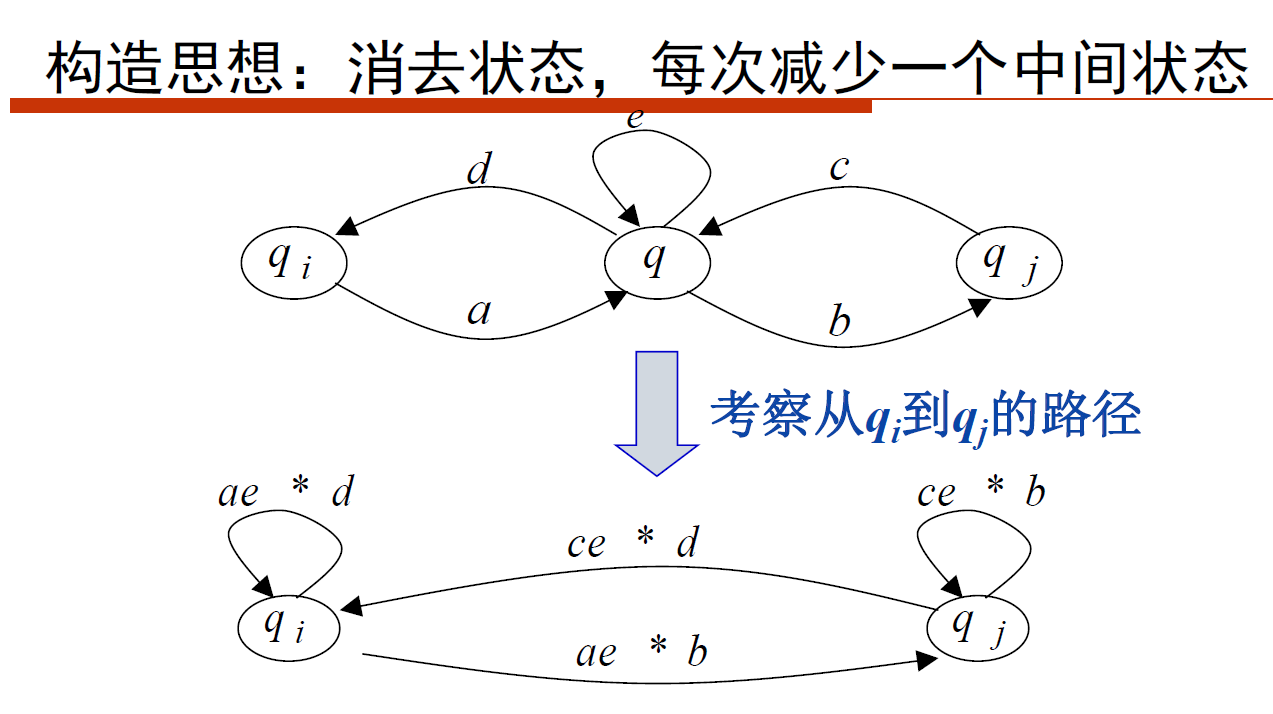
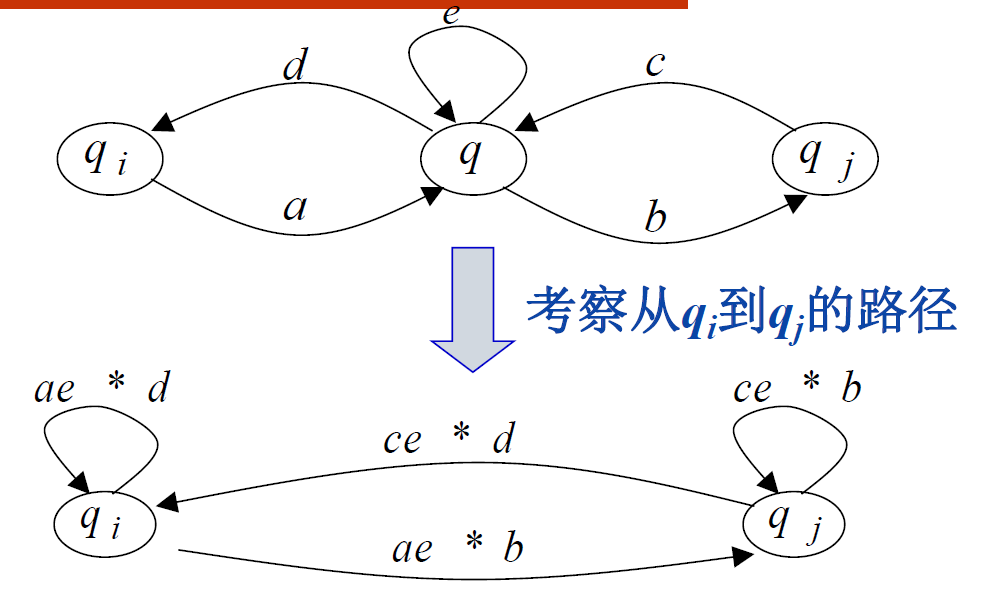
1、算法思想

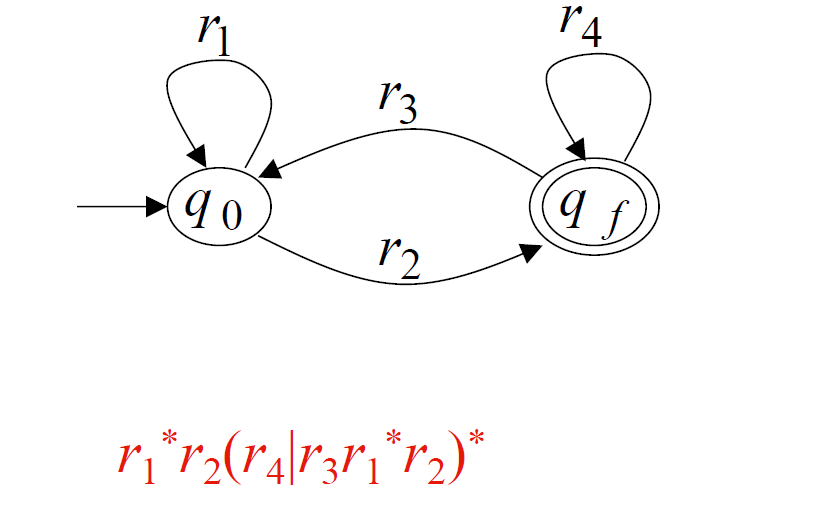
2、例子
关于消除状态的典型例子:
消除一个状态,只需要改变它的两个邻点A、B的边即可
考虑四种边:
- A到自己的边
- A到B的边
- B到自己的边
- B到A的边
注意自环要用闭包表达出来,经过一个有自环的状态再到另一个状态时,正则表达式里都会加上一个闭包
3、练习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号