
「BUAA OO」第一单元总结
「BUAA OO」第一单元总结
零、任务简介
一言以蔽之,就是去括号、展开算术表达式。具体而言:
-
第一次作业只有常数、单独的自变量x、单层括号,实现的是:\((x+1)*(x+2)\) -> \(x**2+3*x+2\)
-
第二次作业引入了三角函数、自定义函数、求和函数,实现的是:\(x*(sum(i,1,10,(sin(x)+i)))\) -> \(10*x*sin(x)+55*x\)
-
第三次作业引入了表达式因子,实现的是:\((x+1*sin((x+2*(x+3)))\) -> \(sin((3*x+6))+x\)
一、引言
在刚看到第一次的作业时,我第一反应就是采用堆栈的方式,先将中缀表达式转换成后缀表达式进行解析,然后把每一个元素实例化为一个可以进行运算的对象,最后再取出栈中的计算符与“数”进行运算即可。我一开始也考虑过这样以面向过程为主的模式是否有违老师、助教的设计初衷......不过实践证明这样做实在是太舒服了,流程思路极其简单清晰且不易有bug,因此也就这么干完了三次作业。(关于 面向过程 or 面向对象 的一些探讨,将置于本文末尾)
二、核心架构
由于我的程序架构与大部分同学很不一样,所以在此先赘述一下。
核心架构分为2个模块:
堆栈解析部分
-
先进行一些预处理,如去掉空格、把
-++换为-、把**换为^ -
然后根据运算符的优先级将中缀表达式转换成后缀表达式:
(x+1)^2 -> x 1 + 2 ^、(3*sin(x))^2 -> 3 sin(x) * 2 ^、(f(x,sin(x))+1)*sum(i,1,2,x) -> f(x,sin(x))+1) 1 + sum(i,1,2,x) * -
再依序取出运算符、“数”(实际上需要先实例化为一个支持运算的对象,具体见”数据结构定义“),直接进行运算
-
最后输出栈中唯一所剩的“数”即可
数据结构定义
由于我每次都是面向最终结果来定义数据结构,所以优点在于很便于优化,缺点在于特化性太强而拓展性差。具体分析如下:
第一次作业
先分析出最终结果一定形如:
故中间过程只需以 Factor 为单位进行运算,且每一个 Factor 内只需存有一个一维数组成员 factors,其中 factors[i] 即表示 \(x^i\) 项的系数为 factors[i]
然后再定义出运算法则即可,例如 Factor 间加法与乘法定义如下:
public Factor add(Factor second) {
BigInteger[] result = new BigInteger[9];
for (int i = 0; i < result.length; i++) {
result[i] = factors[i].add(second.getFactors(i));
}
return new Factor(result);
}
public Factor mul(Factor second) {
BigInteger[] result = new BigInteger[9];
Arrays.fill(result, BigInteger.valueOf(0));
for (int i = 0; i < result.length; i++) {
for (int j = 0; j <= i; j++) {
result[i] = result[i].add(factors[j].multiply(second.getFactors(i - j)));
}
}
return new Factor(result);
}
第二次作业
同样地,先分析出最终结果一定形如:
故中间过程只需以 Expr 为单位进行运算,且需建立层次结构如下(以下表示的是类中的全部成员,具体的 uml 图将在后文给出):
\(Expr: ArrayList\)< \(Factor\) >\(\ factors\)
\(Factor:BigInteger\ k、BigInteger\ a、ArrayList\)< \(Sin\) >\(\ sins、ArrayList\)< \(Cos\) >\(\ coses\)
\(Sin:BigInteger\ b、BigInteger\ p、BigInteger\ m\)
\(Cos:BigInteger\ c、BigInteger\ q、BigInteger\ n\)
然后再定义出运算即可:
-
Factor 间的乘法:
public Factor mul(Factor factor) { BigInteger k = this.k.multiply(factor.getK()); BigInteger a = this.a.add(factor.getA()); ArrayList<Sin> sins = new ArrayList<>(this.sins); sins.addAll(factor.getSins()); ArrayList<Cos> coses = new ArrayList<>(this.coses); coses.addAll(factor.getCoses()); return new Factor(k, a, sins, coses); } -
Expr 间的运算(以加法与乘法为例):
public Expr add(Expr expr) { ArrayList<Factor> factors = new ArrayList<>(expr.getFactors()); factors.addAll(this.getFactors()); return new Expr(factors); } public Expr mul(Expr expr) { ArrayList<Factor> factors = new ArrayList<>(); for (Factor factor : this.factors) { for (int j = 0; j < expr.getFactors().size(); j++) { factors.add(factor.mul(expr.getFactors().get(j))); } } return new Expr(factors); }
第三次作业
第三次作业的数据结构与第二次作业极其类似,最终结构一定形如:
有所不同的地方仅在于 Sin 、 Cos 的内部成员(因为引入了表达式因子,所以涉及到了递归构造):
\(Sin:BigInteger\ b、Expr\ expr\)
\(Cos:BigInteger\ c、Expr\ expr\)
基础运算法则完全一致,不再举例
小结
上述2个模块,以面向过程为主,对象为过程的实现提供了简单清晰、整体化、封装化的方法。且2个模块间实质性的耦合度很小,便于分析与调试。
(很有意思的一点是我面向过程的函数在三次作业中基本不用修改,都是很核心的代码,每一次作业的迭代仅仅是需要在同一内核的基础上向上不断加强扩展封装;反而是对象相关的部分,由于数据结构特化的原因,每次都要重构不少、扩展性明显较弱)
三、具体结构与度量分析
第一次作业
1、结构示意

附上一些函数说明:
pre:一些预处理
change:中缀表达式 -> 后缀表达式
result:后缀表达式 -> 最终的 Factor 结果
2、度量分析
1)方法复杂度分析
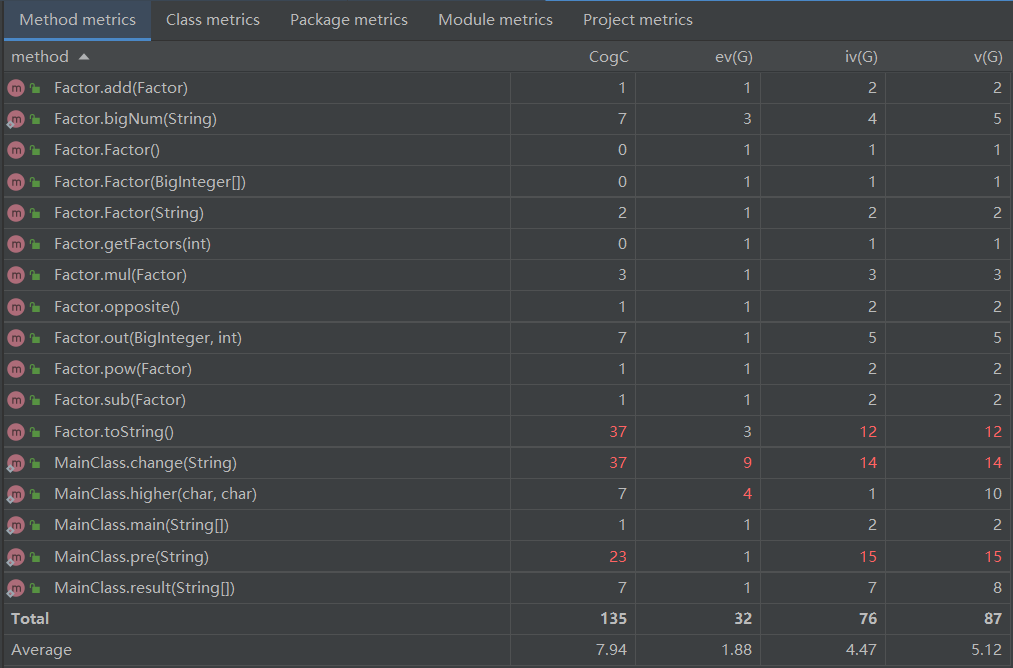
红得挺厉害...毕竟有一半是面向过程嘛,正常正常
除了 MainClass 中面向过程的 pre 、change 等函数以外(尤其是 change ,毕竟仅用一个函数就以堆栈的方法实现了中缀表达式转后缀表达式,认知复杂度确实高),注意到 Factor 的 toString 函数的复杂度也很高——这是因为为了性能而做了一些优化调整,相关的判断都整合进了 toString 中
2)类复杂度分析
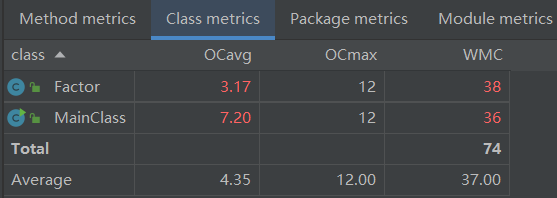
复杂度较高,因为无论是堆栈的过程还是表达式做乘法、toString的过程,都有条件判断与循环体的大量运用甚至嵌套——现在看来,这一部分其实很有改进的空间。
第二次作业
1、结构示意
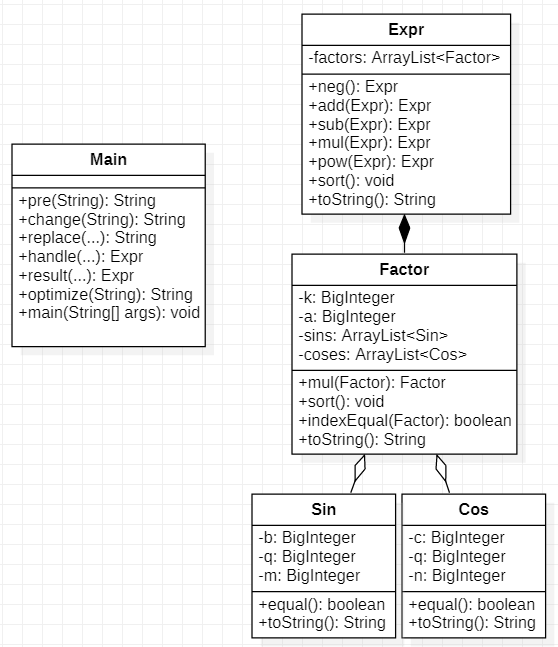
附上一些新增的函数说明:
replace:进行自定义/求和函数的替换
handle:进行自定义/求和函数的处理计算
optimize:优化模块
sort:整理模块(其实应该是sort out/arrangement...为了方便就直接命名为sort了)
2、度量分析
1)方法复杂度分析
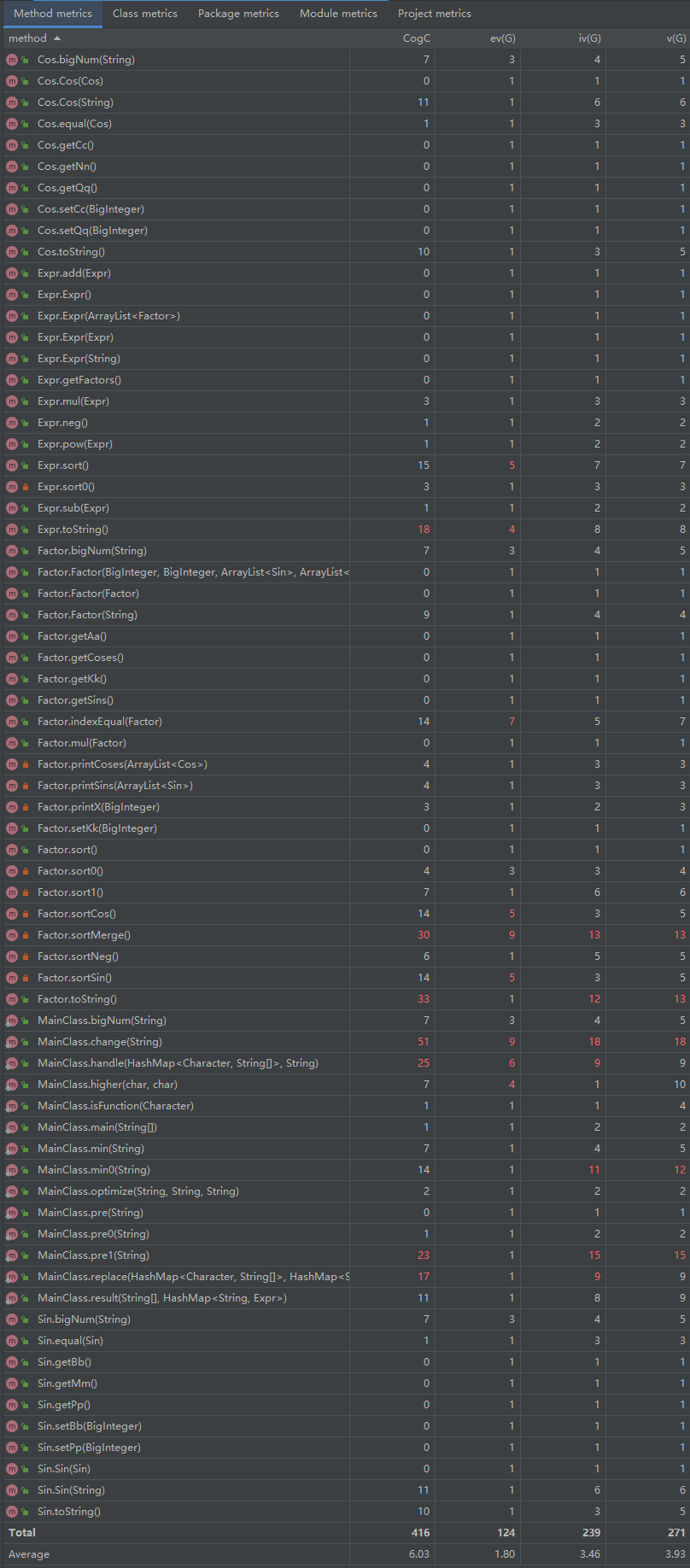
看起来可能又多又红......运行复杂度可能确实有点高 但是我担保设计思路绝对是简单的()
跟第一次作业一样,红的地方主要是一些面向过程的实现函数以及 toString 方法
值得一提的是,由于三角函数的引入,从这周开始有了大量的整合、优化板块,这些方法及其复杂度较高的原因将会在后文里专开一个板块进行分析
2)类复杂度分析
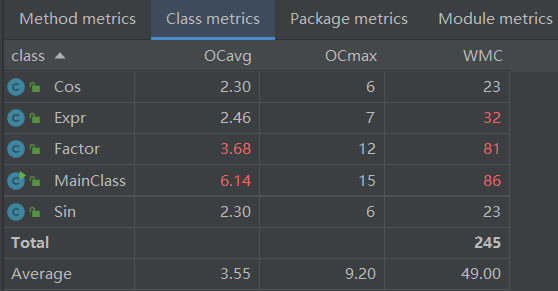
复杂度依旧较高(甚至比第一次高了更多了)
其中很大一个原因可能是在于优化模块内的判断、循环确实多,属于是牺牲了时间、空间才换来更简单的结果了
第三次作业
1、结构示意
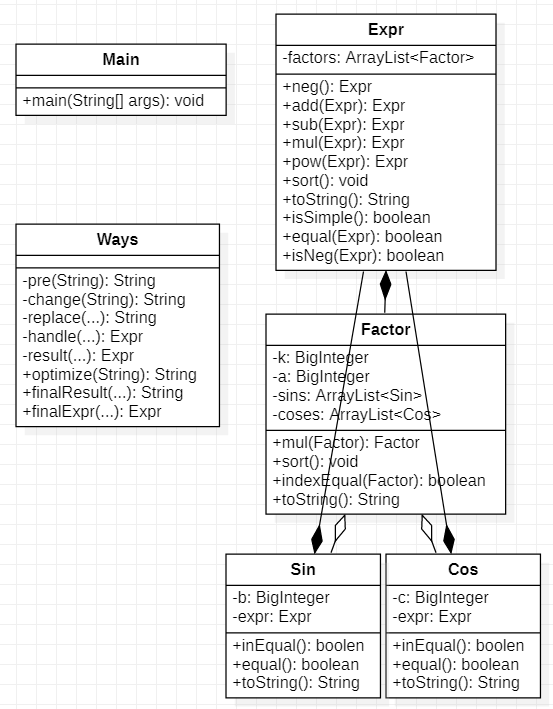
这周函数略微有点多了,于是我把原本在 MainClass 里的函数全部提取出来放到了Ways里,Ways即为我自己建立的函数库
再附上一些新增的函数说明:
finalResult = pre+change+replace+handle+result+optimize(对函数进行了封装,便于实现递归)
finalExpr = finalResult+pre+change+replace+handle+result(产生 Expr 以供递归使用)
isSimple:判断一个表达式是否是一个简单表达式,即能否直接作为一个简单因子(三角函数内是简单因子则不用再加括号)
2、度量分析
1)方法复杂度分析
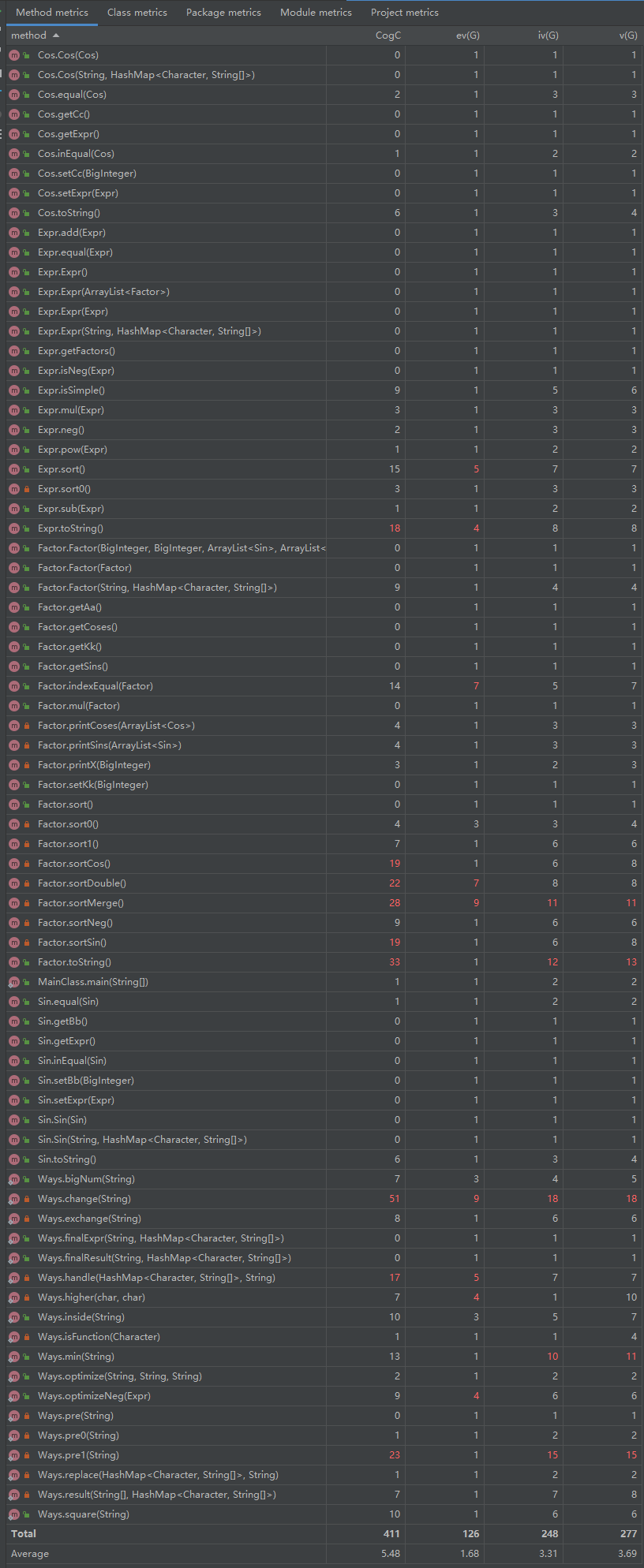
大体问题与第二次作业相似,不再复述
2)类复杂度分析
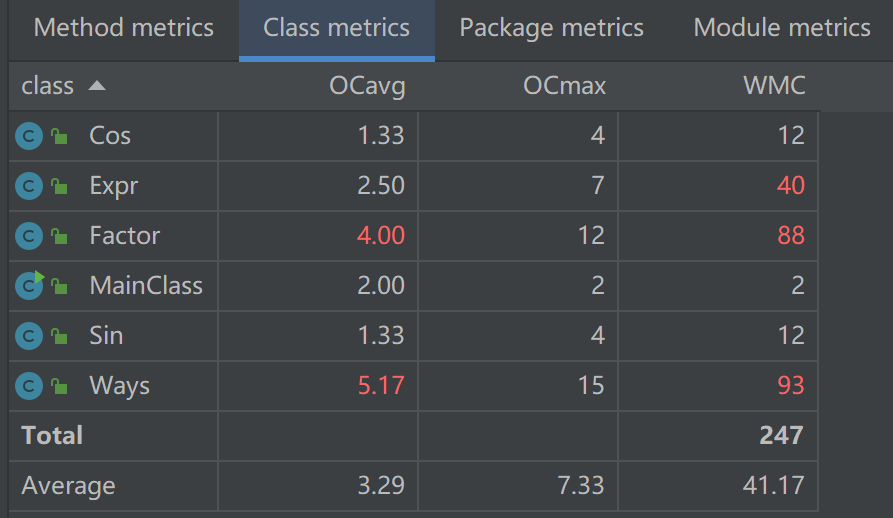
大体问题还是与第二次作业相似,也不再复述
四、优化相关
第一次作业
我的数据结构自带同类项的整理,故只需较为单纯地做2个优化:
- 正项的提前:如
-x+1->1-x - 平方项的优化:
x**2->x*x
最终很轻易地拿到了强测的满分
第二次作业
采用“高内聚低耦合”的理念,我的优化建立在三个层次上(优化层次自底向上):
Factor 层次
-
sort:自整理,包含以下部分:
- sort0:搜寻系数k、sin内是否为0,为0则整个 Factor 直接为0
- sort1:搜寻sin、cos的指数是否为0,为0则可以从 ArrayList 里去掉该sin/cos
- sortNeg:搜索sin、cos内的式子是否为负,为负则提出负号
- sortMerge:合并括号内的式子相等的sin/cos
- sortSin:给 ArrayList<sin> 实现一个内部排序(便于后续比对)
- sortCos:给 ArrayList<cos> 实现一个内部排序(便于后续比对)
Expr 层次
- sort:自整理,包含以下部分:
- 对每个 factor 自整理一次
- sort0:搜索是否有首系数为0的 factor,为0则可以从 ArrayList 里去掉该 factor
- 合并:合并除系数以外各项参数相同的 factor
顶层
- optimize:进行三角函数的转换优化(打表式暴力优化)
- 把 \(sin^2(x)\) 直接替换为 \((1-cos^2(x))\)
- 调用 finalResult 函数,把再跑一次的结果存下来
- 再进行诸如 \(cos^2(x**2)\) -> \((1-sin^2(x**2))\) 、\(sin^2(1)\) -> \((cos^2(1)-cos(2))\) 的替换,重复上述2步
- 将存取的多个表达式进行比较,挑取最短的输出
这样的优化方式很暴力且并不全面,但对于第二次的规则而言已经比较有用了,笔者实测能拿到强测的满分
第三次作业
第三次作业的优化大局与第二次作业比较类似;但是由于三角函数内允许表达式因子,所以既增加了相同项比较的难度,也加大了优化的灵活性。
与第二次作业相类似的按“高内聚低耦合”进行优化的理念不再赘述;由于优化面更广了,所以这里按模块化视角进行叙述,共计1个基础模块+3个进阶模块:
自整理
这是基础模块,包含第二次作业中 Factor 、 Expr 层次内自整理的全部内容
平方优化
为了实现 \((1-cos^2(x))\) -> \(sin^2(x)\) ,且考虑时间复杂度的影响,我设计了两个版本:
- 满血版:暴力搜索所有三角函数平方项,均进行替换、再计算并存取
- 残血版:只进行部分特判,如\(sin^2(x)\)、 \(sin^2(x**2)\) ,不考虑 \(sin^2((x+1))\) 等复杂情况
二倍角优化
这一优化我放置在了 Factor 层次,例如: \(6*sin(x)*cos(x)\) -> \(3*sin((2*x))\)
但注意不要出现\(6*sin^2(x)*cos^2(x)\) -> \(3*sin(x)*cos(x)*sin((2*x))\)
Sin负项优化
实现了 \(sin^3((x-1))*cos((x-1))+sin^3((1-x))*cos((1-x))\) -> \(0\)
反思
优化还是很不全面,这次强测就未能满分了,且最终输出里局部出现了 \(25*x**4*sin((2*x))+25*x**4*sin(x)*cos(x)\) 这样的结果——这是考虑不充分、将二倍角优化只建立在 Factor 层次所导致的后果;实际上,应当将二倍角的化简也建立在最顶层进行比较判别。(另外我好像听说强测点里不涉及二倍角的优化,这波属实反向优化了)
且时空间复杂度极高,其后果将在下一个章节进行进一步的叙述
五、测试与debug
测试
自测
在自测中,我主要是面向自身代码测试,纯手搓数据。这样做的原因如下:
- 代码的功能性分割强,主要做的是局部功能测试
- 设计架构清晰,自己相对比较清楚容易出 bug 的地方,故针对性搓数据即可
- 时间有限(高工这学期的课有一点点多,我一般是周五凌晨才开始写OO,每次作业的平均总用时在12小时左右,特别是第一次作业是在8小时内赶完的......
第一次没空写测试程序导致我后面也懒得写了) - 自己对优化板块更感兴趣,动力比较足,所以重优化轻测试了
第一次作业,以我的架构很难出错,几乎不用怎么测试;第二次作业我手搓了10+条数据,在自测找 bug 的过程中大部分数据都发挥了作用,很有效;第三次作业,整体架构变化不大,也没怎么测正确性,反而是针对优化而构造的数据较多
这个单元可能是出于侥幸而没有出正确性错误,但下个单元可能势必会将自动化测试提上日程。
互测
由于没写自动化评测机+我的架构与他人不同而难以想象他人可能会有的 bug,所以我完全是佛系参与互测了(不过我依然阅读了他人的代码;虽说没能看出什么 bug,但还是能大体感受到设计者的设计思想架构)
debug
第一、二次作业完美通过,值得一提的是第三次作业
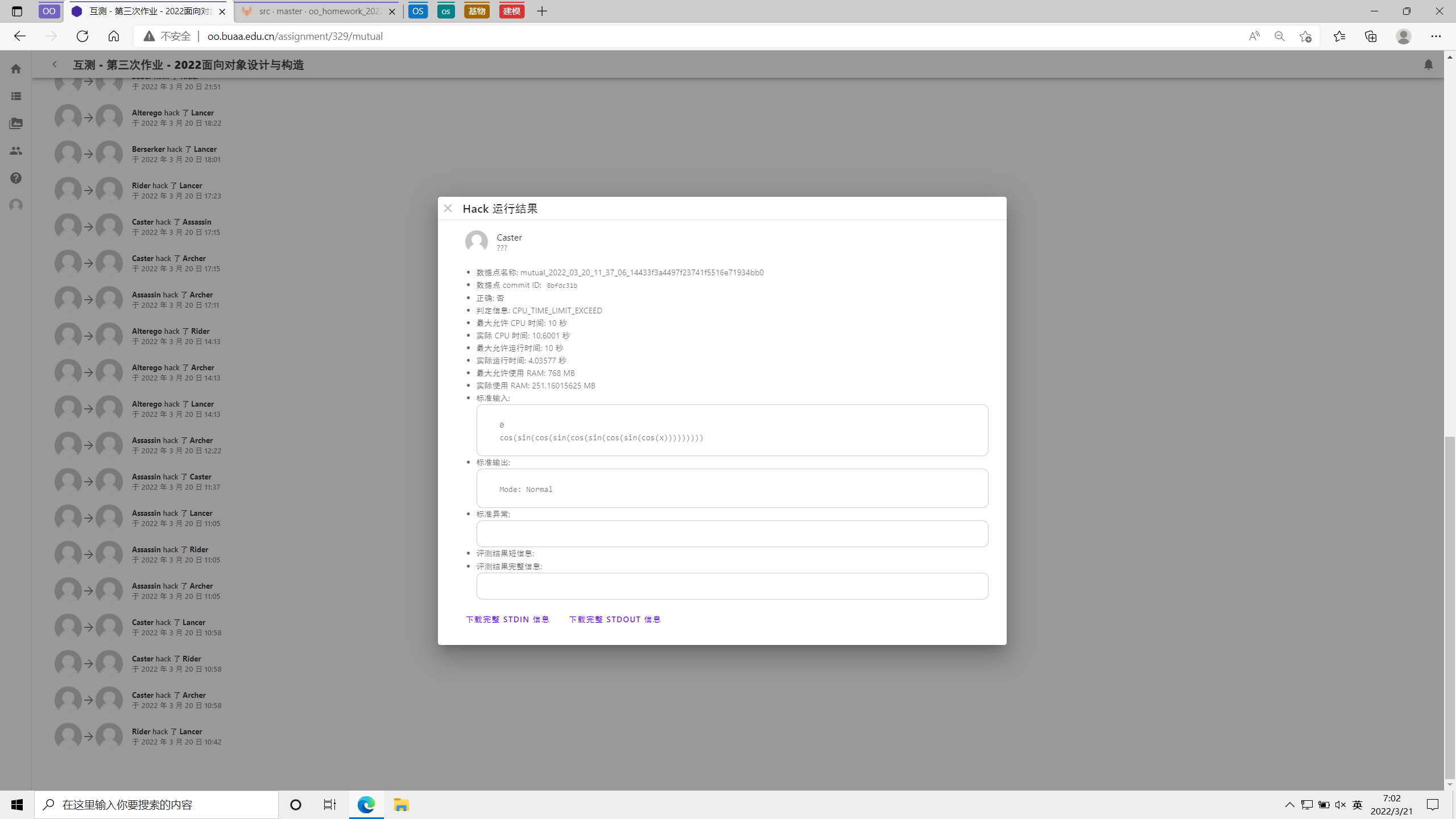
初见 tle
当我花了好几个小时、兴高采烈地搞完四个板块的优化后,在周六下午一提交,却发现了这......
我当即意识到是自己的优化模块过于复杂,然后自行分析复杂度+面向评测机编程后,删掉了部分优化模块
忍痛割爱后
最终只保留了自整理+残血版平方优化+二倍角优化,时间压缩到了这样:
寄!
在互测开始几小时后,我就发现自己被 hack 成功了一次......忐忑地以为自己可能被 hack 更多次,结果到最后也只有这一次被 hack 成功
第二天早起一看,发现居然是这样......真是既在意料之外,又在情理之中......
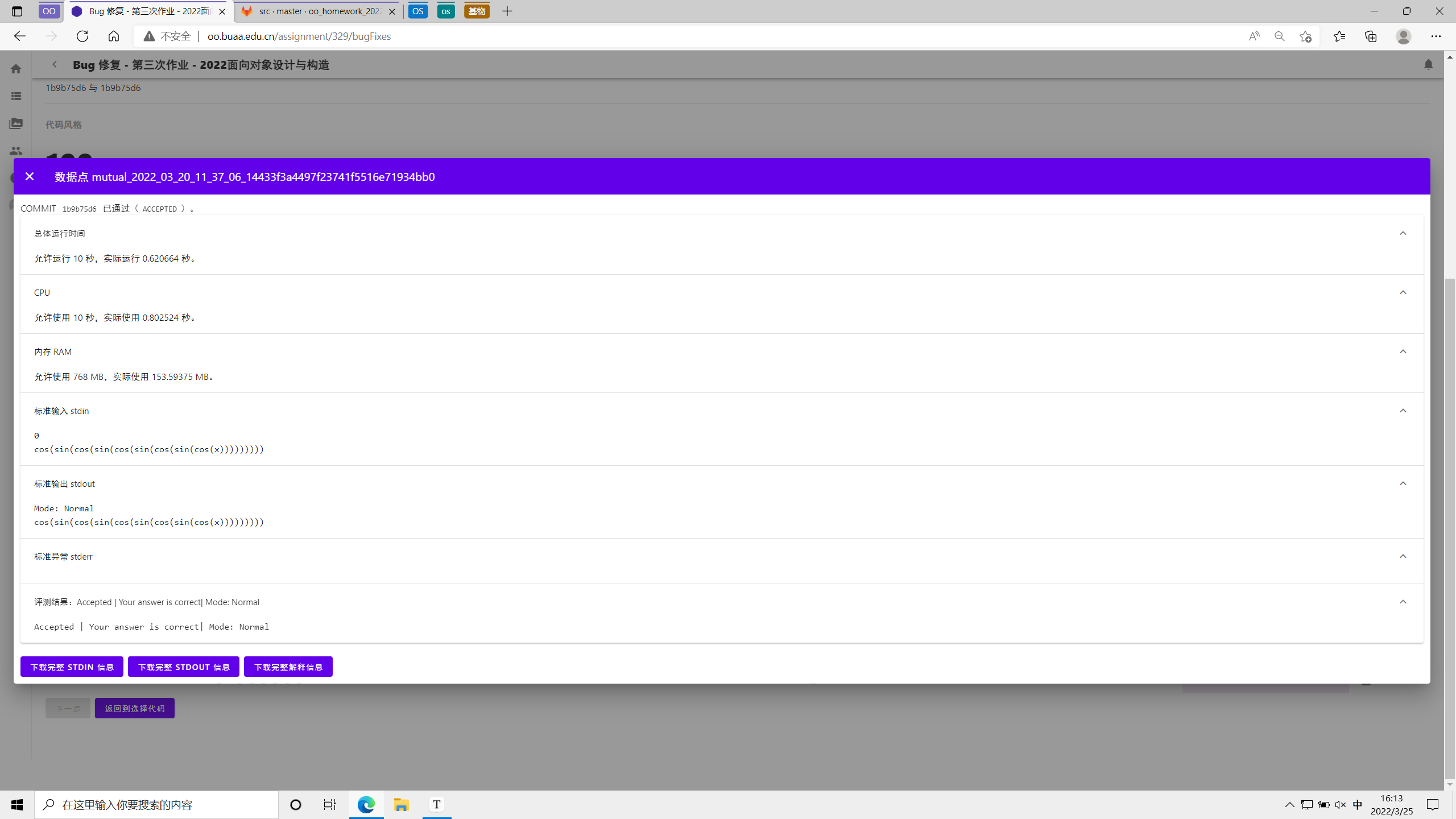
bug 修复很简单,进一步注释掉剩下的优化模块即可,这样程序运行起来就快得多了()
反思
一方面,其实在中测 tle 的时候,我已经考虑到熔断机制了,并且试着做了一下熔断;不过后来觉得没啥必要,就没有保留;现在看来确实还是失策了。
另一方面,出现这种情况的本质原因还是程序的时间复杂度过高(同时,内存用量大也说明空间复杂度高)——优化模块可能还是过于暴力了。
第一单元的作业已经在此为我敲响了警钟,今后务必要重视程序的时间效能(昨晚吃饭时正巧偶遇了我梦拓,他也跟我说后续单元里时间很重要)。
六、心得体会
面向对象 or 面向过程?
这是我此时此刻最想反思与探讨的一点。尽管我自嘲我自己是面向过程的;但与此同时,我认为本单元的核心解析部分确实就应该是面向过程的。
关于解析,“表达式的层次化解析”、“以面向对象的方式建立表达式的层次结构”,听起来很高大上,但也免不了要先逐字符解析,然后再化为表达式——我认为这一部分的处理几乎必然是面向过程的;而解析完以后所做的表达式建类、实例化对象、表达式作为对象参与运算,这些板块的内容我认为我所做的内容,与大家面向对象的方式倒也没有本质上的区别。归根结底,我认为有两个要点:
-
字符串这一待解析形式。
可以做一个比较:pre2 中的冒险者游戏就是一个典型的很适合面向对象的形式主题,个体自身的整体性明显,操作都是一条一条、及其清晰准确的,于是在教程的引导下我们也都建立了合适的抽象、继承等逻辑,初步体会到了面向对象的设计思想;
而对于字符串处理,要解析的话,怎么着也得先读入、接着拿去建类、建好了类再拿回来建立层次结构(其中可能还涉及到所谓”递归下降“的方法)......官方 training 里的 Parser、Lexer 大概就是这样分步做了解析——总之是无法从一开始就面向对象的。
我认为在思考自己的方法“是否面向对象”的时候,解析板块,也即本单元的内核,绝对是不容忽略的。
-
对于”表达式树“的本质理解。
在大量阅读其他同学的博客后
(毕竟我这儿交得比较晚嘛),我发现大家对于“表达式树”各有理解:有的同学主要阐述了递归下降法并给出了图例,有的同学甚至直接明确指出“本单元不需建立表达式树”,还有的同学“在转换为后缀表达式后再建立了表达式树”......我的观点与一部分同学的观点一致——无论自己有没有意识到,本单元的解析处理过程本质上全是在“建立表达式树”的过程(递归下降就是在延展树的深度;而栈堆与树本质上本来就是等价的)。
在我看来,”层次化“的过程本身无关面向对象/面向过程,关键还是层次化的具体内容。pre2 里冒险者、装备的层次化无疑就很面向对象;而本单元里的表达式树我认为其本质上就很面向过程。
说了这么多,我的结论主要有两条:
-
本单元作业的设计本身就不是很纯粹的面向对象。
-
面向过程/面向对象归根结底都只是设计思想罢了,终究还是为实现设计目标而服务的。当然,在《面向对象设计与构造》这门课程中我们自然更应该去尝试培养自己面向对象的设计思想;但我认为具体情况还是可以具体分析的,即使在OO这门课程里,我觉得也没必要对面向过程讳莫如深,清晰合适的架构可能更为重要。
(最后这一部分主观感受居多,恳请大家批评指正、欢迎讨论交流!)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号