
MCS锁——可伸缩的自旋锁
在编写并发同步程序的时候,如果临界区非常小,比如说只有几条或几十条指令,那么我们可以选择自旋锁(spinlock)。使用普通的互斥锁会涉及到操作系统的调度,因此小临界区一般首选自旋锁。自旋锁的工作方式就是让竞争的线程不断地读取一个变量的状态,判断是否满足可以进入临界区的条件。
最简单的自旋锁应该如何实现?假设我们用一个布尔变量表示临界区是否被占用,true表示被占用,false表示没有被占用,那么我们可以考虑这样的(伪)代码:
1 void lock(bool *lck) 2 { 3 while (*lck == true); 4 *lck = true; 5 } 6 7 void unlock(bool *lck) 8 { 9 *lck = false; 10 }
这段代码显然是有问题的。lock函数分为两步执行,第一步是读lck变量的值,第二步是在发现lck变为false之后将其设置为true表示自己进入临界区。问题就在于这两步之间可能会交错执行其他线程的lock,导致多个线程同时进入临界区,因此这个算法是不正确的。
好在现代的硬件都提供了各种强大的read-modify-write(RMW)原子操作,可以原子地执行读改写操作,所谓原子操作就是可以在执行这几个操作的时候不会被其他指令打断,可以实现排他的内存访问,实际是在内存总线层次的临界区操作。现代硬件一般都支持强大的原子操作,例如Intel平台支持在指令前面加上lock前缀锁定总线,实现原子的比较-交换操作(CAS,通过cmpxchg指令,原子地执行判断条件并交换值的操作),原子递增和原子递减(inc和dec指令)操作。还支持一个交换操作,xchg指令,不需要lock前缀,可以原子地交换两个寄存器或一个寄存器和一个内存位置的值。在Intel平台上通过这些基本的原子操作支持几乎所有的原子操作。
在上面这个自旋锁的例子中,我们可以使用一种称为测试-设置(TAS)的原子操作。TAS操作是实际上是一种xchg操作:原子地写入true,并返回之前的值。使用TAS实现自旋锁的思路就是:先尝试将true写进共享的锁变量lck,看返回的值是什么。如果返回false,说明之前lck的值为false,原子操作可以保证只有我一个线程成功地将lck从false变为true了,其他线程如果和我并发争抢这个lck,那么他们得到的都是我改过的值,即true,所以让他们继续自旋等待去吧,等我unlock的时候把lck写入false之后,那些失败的线程中必然有一个能成功地写入true。
下面是使用TAS操作的自旋锁算法的lock()函数的代码:
1 void lock(bool *lck) 2 { 3 while (TAS(lck) == true); 4 }
那么这个自旋算法是否正确了呢?答案是不一定,因为现代的硬件不一定满足顺序一致性,为了提高单核性能,处理器可能会将写操作归并,导致读写乱序,尽管保证单个线程自己看自己的执行结果符合程序顺序,但是在多核多线程环境中,线程看到其他线程的执行顺序不一定符合线程的程序顺序。如果符合的话,这种正确性条件称为顺序一致性,但是现代的硬件一般都会采用有所放松(relax)的条件。好在这种硬件平台都提供了内存屏障(fence或barrier)指令来强制该顺序一致性的地方实现顺序一致性。因此为了编写跨平台且可靠的代码,我们还要加入屏障指令。为了方便,我们用一些跨平台的原子库就好了,比如说libatomic_ops。完整代码如下所示:
1 #include <atomic_ops.h> 2 3 #define SPIN_BODY __asm__ __volatile__("rep;nop" : : : "memory") 4 5 typedef struct { 6 AO_TS_t lock; 7 } spinlock_t; 8 9 AO_INLINE void spinlock_init(spinlock_t *lock) 10 { 11 lock->lock = AO_TS_INITIALIZER; 12 } 13 14 AO_INLINE void spinlock_lock(spinlock_t *lock) 15 { 16 while (AO_test_and_set_acquire(&lock->lock) == AO_TS_SET) { 17 SPIN_BODY; 18 } 19 } 20 21 AO_INLINE void spinlock_unlock(spinlock_t *lock) 22 { 23 AO_CLEAR(&lock->lock); 24 }
其中AO_test_and_set_acquire可以保证这个调用之后的所有操作都一定会出现在这个原子操作之后,即进入临界区的操作不会被乱序到这个原子操作之前。
AO_CLEAR里面也包含了一个屏障,可以保证这条语句之前的操作(即临界区操作)不会被乱序到这条原子操作之后。
用库的好处就是可以方便地编写跨平台的并发代码。库提供的是例如CAS、SWAP、INC、DEC之类的高层语义以及各种屏障的组合,并且将这些接口映射到底层具体的硬件平台。库一般还会提供功能探测的宏用于判断指定的原子操作能否在指定的硬件平台上通过硬件指令高效地实现,如果不能实现,库则会提供相对低效的fallback实现。
顺便提一下关于原子库的选择。
对比一些原子库,我觉得Erlang运行时中自用的原子库是最强大最完整的,提供了所有常用原子操作和所有屏障的完整组合,尽管有很多组合没有实际意义,不过也不费电啊。libatomic_ops同样是一个系出名门的库,但是竟然没有提供SWAP的操作。Erlang运行时中的原子库也可以选择libatomic_ops作为后端,但是由于libatomic_ops没有swap操作,所以ERTS中的ethr_atomic[32]_xchg_<barrier>系列接口都是用CAS模拟的。此外美国阿贡国家实验室有一个openpa,略显简陋。gcc-4.1之后的版本也提供了atomic扩展,不过从这页文档看是针对Intel平台设计的。所以,综上,如果不需要SWAP,那就用libatomic_ops,如果追求全面完整,可以考虑把ERTS中的原子库剥离出来用(甚至可以把ERTS中整个lib都弄出来,这个库里面好东西不少,应该可以满足大部分需求,而且免费跨平台哦)。
好了言归正传,还没有开始介绍本文的主角MCS自旋锁。
MCS自旋锁是用发明人的名字命名的,也就是John Mellor-Crummey和Michael Scott,所以MCS三个字母不涉及这个锁本身具体的意义。我们先说一下MCS锁的工作原理,然后再说为什么一个自旋锁要弄得这么复杂,前面那个不挺好的么,又简洁又高效。关于工作原理,简单地说,MCS锁是一个链表形式的锁,每一个线程是链表中的一个节点,MCS锁用一个tail指针维护链表中的最后一个节点,每一个节点用一个布尔值locked表示自己是否被锁定,以及一个next指针表示在链表中的下一个节点。MCS锁的工作原理是这样的:
- lock:用SWAP操作将tail更新为指向自己;如果tail之前的值为NULL,则表示没有线程在等待,我可以直接获得锁进入临界区。如果tail的值不为NULL,说明前面有线程在等待,那么我也插入链表尾端,将自己的locked设置为true,然后自旋自己的lock等待别人把我的locked的值设置为false退出循环结束等待进入临界区;
- unlock:判断自己的next是否为NULL,如果为NULL,则说明在我后面没有线程在等待了,那么我就是链表中最后一个线程(至少目前是,而且tail还指向我),然后用CAS操作赌一把,将tail设置由指向我自己设置为NULL并返回,如果CAS成功了,那么表示成功释放锁直接返回;如果CAS不成功,刚才在CAS之前有一个比我快的线程先我一步插到我后面,改了tail,那我只能等一会。等什么呢?插到我后面的线程肯定要把我的next设置为他,那我就等next变为不是NULL就好了。如果我next不为NULL了,说明我后面插入了在自旋等待进入临界区的线程了,根据前面lock的操作流程,他们肯定在自旋等待自己的locked。那么既然我要退出临界区了,那我就把临界区进入权转交给插在我后面的那个线程,所以把他的locked字段设置为false,我出来,他进去。
有图有真相,下面的图示展示了MCS锁的工作原理:
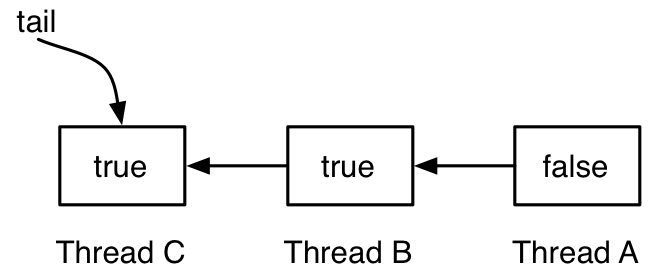
有3个线程,A、B和C。A的locked为false,A在临界区,B和C先后试图lock,由于A在临界区,所以B和C都依次插在后面,并且locked都为true,都在等待。tail指向最后一个插入的节点C。下图是线程A释放锁:
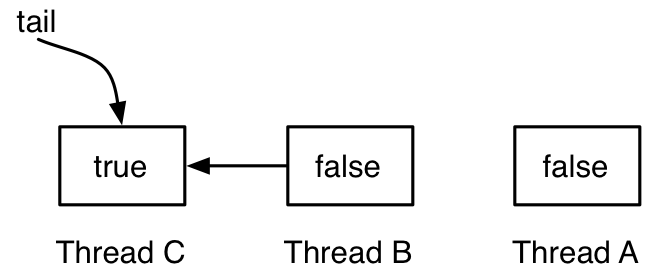
线程A将下一个节点,即线程B的locked设置为false,线程B可以退出等待,进入临界区。线程A将自己从链表中脱离开。
下面展示的是MCS锁的代码。数据结构定义如下:
1 typedef struct _mcs_qnode { 2 int locked; 3 struct _mcs_qnode *next; 4 } mcs_qnode_t; 5 6 typedef union { 7 mcs_qnode_t node; 8 char pad__[CACHE_LINE_ALIGN_SIZE(sizeof(mcs_qnode_t))]; 9 } aligned_mcs_qnode_t; 10 11 typedef struct { 12 AO_t tail; /* 指向aligned_mcs_qnode_t的指针 */ 13 pthread_key_t qnode_key; 14 } mcslock_t;
mcs_qnode_t表示的是线程的节点,由于locked字段是要自旋的,为了避免伪共享的问题,aligned_mcs_qnode_t结构体将mcs_qnode_t对齐到cache线。
下面是初始化、锁和解锁的实现。这段代码用的是libatomic_ops库,但是由于这个库没有SWAP操作,而我是在Intel平台上做这个实验,所以我借用了ERTS中的xchg代码,就是xchg_mb()的实现,后面_mb尾巴的意思是在Intel平台上,xchg本身具有完整的读写屏障语义。
1 static __inline__ size_t 2 xchg_mb (AO_t *var, AO_t val) 3 { 4 AO_t tmp = val; 5 __asm__ __volatile__( 6 "xchgq" " %0, %1" 7 : "=r"(tmp) 8 : "m"(*var), "0"(tmp) 9 : "memory"); 10 /* now tmp is the atomic's previous value */ 11 return tmp; 12 } 13 14 #define SPIN_BODY __asm__ __volatile__("rep;nop" : : : "memory") 15 #define COMPILER_BARRIER __asm__ __volatile__("" : : : "memory") /* 防止编译器乱序 */ 16 17 __inline__ int 18 mcslock_init(mcslock_t *lock) 19 { 20 int res; 21 AO_store(&lock->tail, (AO_t)NULL); 22 res = pthread_key_create(&lock->qnode_key, NULL); 23 return res; 24 } 25 26 __inline__ void 27 mcslock_lock(mcslock_t *lock) 28 { 29 aligned_mcs_qnode_t *qnode, *pred; 30 qnode = (aligned_mcs_qnode_t *)pthread_getspecific(lock->qnode_key); 31 /* 获得当前线程的MCS节点,如果没有就创建一个 */ 32 if (qnode == NULL){ 33 /* 分配节点的时候cache对齐 */ 34 qnode = malloc(sizeof(aligned_mcs_qnode_t) + CACHE_LINE_SIZE - 1); 35 if (qnode == NULL) { 36 abort(); 37 } 38 if (((AO_t) qnode) & CACHE_LINE_MASK) { 39 qnode = (aligned_mcs_qnode_t *) 40 ((((AO_t) qnode) & ~CACHE_LINE_MASK) 41 + CACHE_LINE_SIZE); 42 } 43 qnode->node.locked = 0; 44 qnode->node.next = NULL; 45 pthread_setspecific(lock->qnode_key, (void *)qnode); 46 } 47 pred = (aligned_mcs_qnode_t *)xchg_mb(&lock->tail, (AO_t)qnode); 48 if (pred != NULL) { 49 qnode->node.locked = 1; 50 pred->node.next = &qnode->node; 51 AO_nop_write(); 52 COMPILER_BARRIER; 53 while (qnode->node.locked) { 54 SPIN_BODY; 55 } 56 } 57 } 58 59 __inline__ void 60 mcslock_unlock(mcslock_t *lock) 61 { 62 aligned_mcs_qnode_t *qnode = (aligned_mcs_qnode_t *)pthread_getspecific(lock->qnode_key); 63 if (qnode->node.next == NULL) { 64 /* 我应该是最后一个,赌一把将tail从我设置为NULL */ 65 if (AO_compare_and_swap(&lock->tail, 66 (AO_t)qnode, 67 (AO_t)NULL)) { 68 return; 69 } 70 /* 我的CAS没成功,之前有人插到我后面了,那我只能等 */ 71 AO_nop_write(); 72 COMPILER_BARRIER; 73 while (qnode->node.next == NULL) { 74 SPIN_BODY; 75 } 76 } 77 /* 解锁我后面的那个线程 */ 78 qnode->node.next->locked = 0; 79 qnode->node.next = NULL; 80 AO_nop_write(); 81 COMPILER_BARRIER; 82 }
那么John Mellor-Crummey和Michael Scott为什么要发明这么复杂的自旋锁呢,而且还用到了SWAP和CAS这些高端大气上档次的原子操作?一句话,前面基于TAS的自旋锁在多核系统上不具有很好的可伸缩性。每一次TAS操作都会写入cache,那么所有线程的这条cache线都会失效,当线程数多的时候会导致大量的cache一致性流量。MCS锁的优点在于每一个线程只自旋自己的变量,因此自旋完全可以在自己所在的核心的L1中完成,完全没有任何cache一致性的问题,也不会产生内存访问,也不会产生NUMA跨节点的流量。只有在转交锁的时候需要写入一次后一个线程的lock变量。此外,MCS锁由于使用了链表,所以还能保证公平,线程自然地按照先后次序排好队。
那么由于cache造成的可伸缩性问题到底有多严重?毕竟MCS锁本身也够复杂。我在Intel Xeon Phi 5110P协处理器上做了实验比较上文中两种锁的并发性能。实验创建多个线程同时增加一个共享的计数器,通过自旋锁保护临界区。共享计数器的最终值设置为12000000,每一个线程均分自己的任务,统计不同线程数的情况下的执行时间。由于多个线程的并发锁开销,明显只有1个线程的时候是耗时最短的。Intel Xeon Phi 5110P协处理器有60个通过环状网络连接的核心,每一个核心支持4个硬件线程,也就是说总共支持240个硬件线程。运行频率1.1GHz,而且是不带乱序执行的,所以单核性能还是挺低的。
这款协处理器的具体硬件规范参见 http://ark.intel.com/products/71992/Intel-Xeon-Phi-Coprocessor-5110P-8GB-1_053-GHz-60-core。

将线程数从1逐渐递增到240,看看TAS自旋锁和MCS自旋锁的表现:
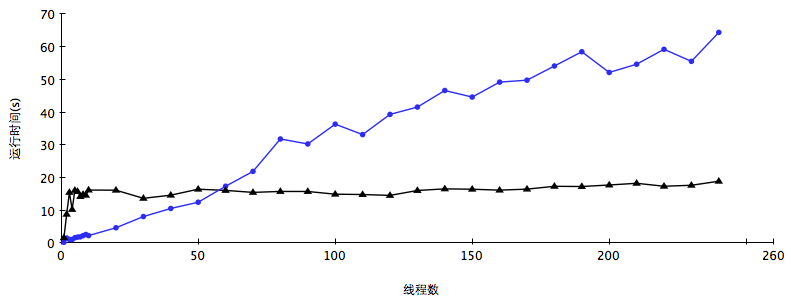
图中蓝色的圆点表示TAS锁的数据,黑色的三角表示MCS锁的数据。可以看出TAS锁的运行时间在线程数较少的时候耗时并不长,但是随着线程数增多的时候,运行时间在不断增长。而MCS锁的运行时间除了在线程数很少的时候非常短,然后基本上保持在一定的水平,说明MCS锁在多核硬件上的伸缩性非常好。
再看下面的profile数据。
下图是TAS锁的profile数据,这个图对应60个线程的时候,这60个线程用满了60个核心,也就是说每一个核心上占用一个硬件线程:
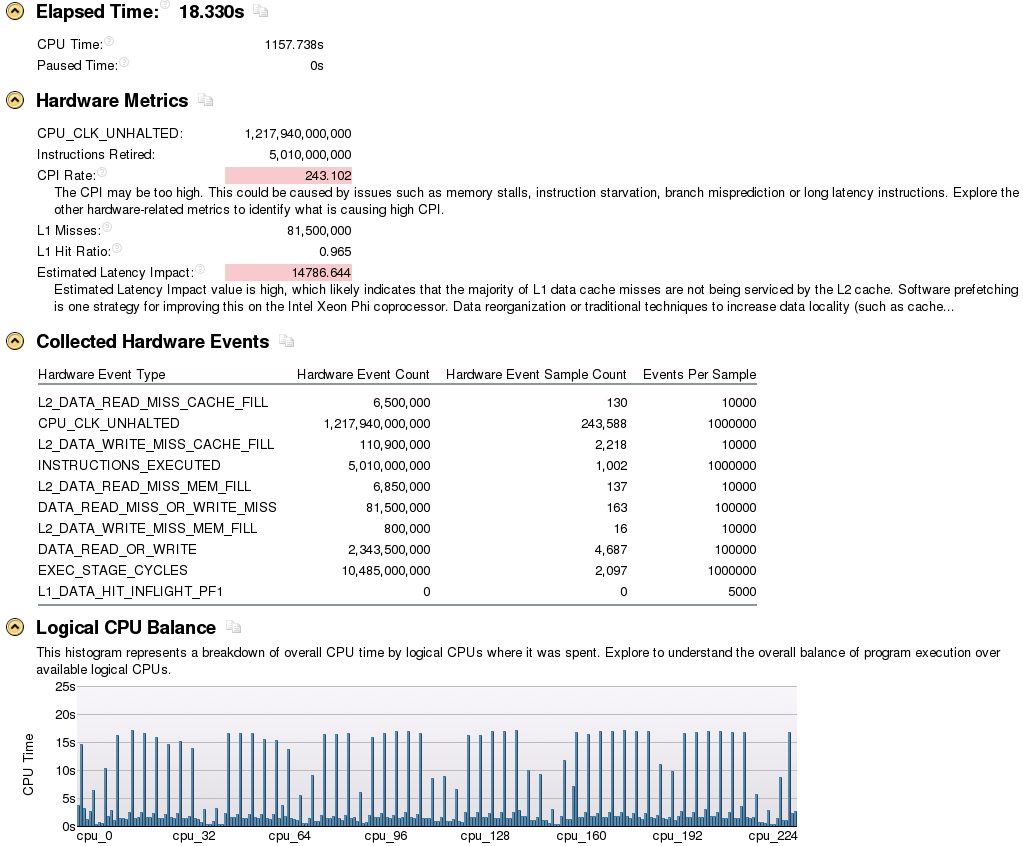
可以看出CPI(clock per instruction)值非常高,表示指令的延迟非常高,这就是cache不断invalidate造成的结果。
下面是MCS锁在同样条件下的profile数据
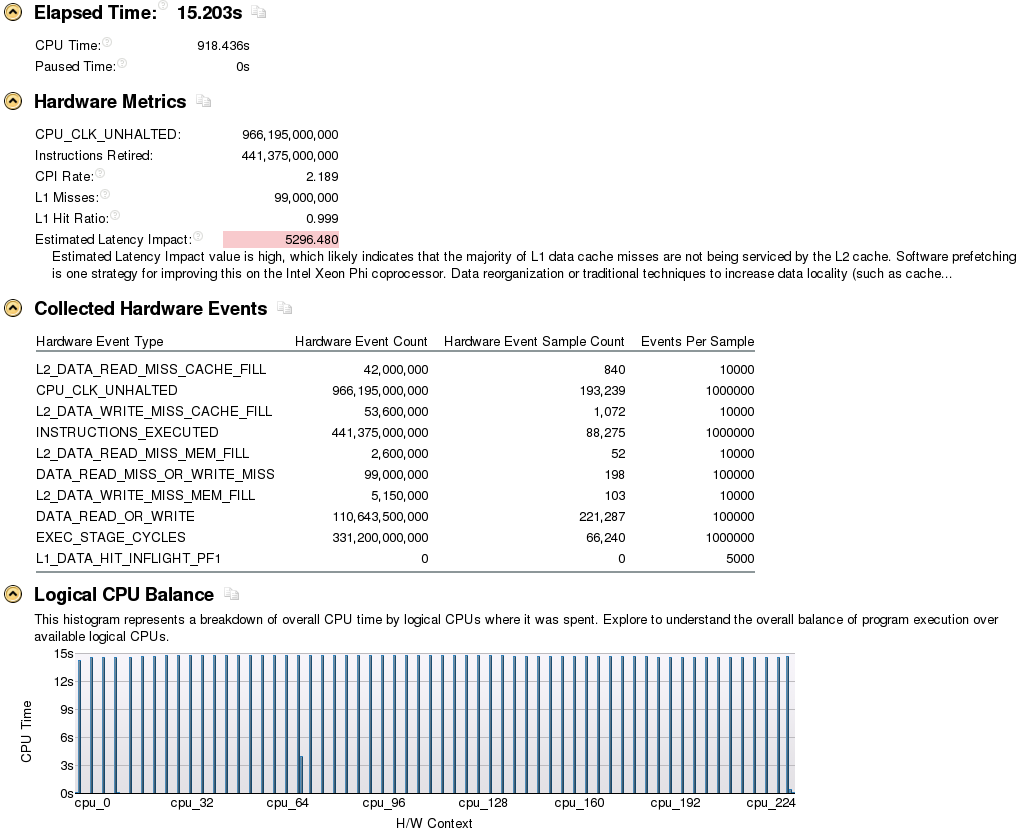
这个CPI小多了,只有2.几,属于非常正常的范围。虽然MCS锁的程序retire的指令是TAS锁的80多倍,但是CPI却只有后者的几百分之一。此外由于MCS锁的公平性,MCS的CPU利用率也比TAS的更为平衡。
所以,小小的自旋锁里,也有不少学问哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号