

OO第三单元总结
本单元在完成上难度相对前两个单元来说还是相对轻松,对于我来说难点大多集中于图论的一些算法上。
一、采取的设计策略
本单元第一次作业最大的难点在于queryblocksum.在做到这个方法之前,基本上所有的方法我都是按照JML怎么写的我就怎么写——机械实现。先写正常情况,再判异常,其实这是很不应该的。做到queryblocksum时,就意识到完全按照JML规格来不动脑子地实现是极有可能导致CTLE的。由这个方法开始,后面的方法在设计上会着重考虑能不能将计算混入别的方法实现当中,从而分解困难方法,降低复杂度。具体的设计策略可能会体现在容器选择和性能问题上。因此后面再谈。
此外,在处理异常类时,对于计数的实现,我进行了大量的复制粘贴,但是这种多代码重复出现的设计方法应该改变,整理出一个工具类的话(其实指导书也提示了),在实现上,bug如果出现,也会更加集中。这次懒了,而且侥幸没出问题,但是下次应该在过一遍整体架构之后考虑一下重复的方法,把它封装出来,才是合适的设计策略。
每个异常类都有的那么几行代码:
private static int count = 0;
private static HashMap<Integer, Integer> idCount = new HashMap<>();
二、基于JML规格设计测试的方法和策略
JML的所有pre-condition都是全覆盖的,也就是互斥的,所有的pre-condition并集为全集。这也是JML对于测试有利的地方。测试时,就可以针对规格中最大的几个normal_behavior进行单元测试。组合pre-condition的情况,同时也要注意组合post-condition,达到全覆盖,确保每一个分支都至少进行了一次测试。
三、容器选择和使用的经验
浏览一遍要实现的方法,就会发现诸如contains,getxxxx这样的方法,会经常出现获取容器元素的情况。如果按照规格上直接无脑使用ArrayList作为容器装载数据信息,用索引来记录ID,那么非常多的for,以O(n)的复杂度一遍又一遍循环,那么就时间上来看并不太符合设计预期。因此,我学习了HashMap和HashSet(此前单元,诸如多项式求导时没怎么了解哈希类容器,因此没怎么用过,现在看来并不合适)。Hashmap和HashSet的复杂度都与n无关,相对来说的效率是最高的。因此这个单元,哈希类容器的使用绝对是最合适的。另一个强烈的暗示就是第三次作业规格中的public instance model non_null int[] emojiIdList和public instance model non_null int[] emojiHeatList,他的意思其实就是ID和emojiHeat这两个属性是一一对应的。一开始我用了一个Set一个Map,初步想法是如果方法实现下来没有单独关于emojiID属性的处理的话,那么这个属性可以直接删掉。一遍写下来,果然这个属性是不需要的,一个HashMap,直接完美实现该规格——两个属性,且一一对应。
MyPerson中的容器选择:
private final HashMap<Integer, Person> acquaintance;
private final HashMap<Integer, Integer> value;
private final ArrayList<Message> messages;
其中messages受
public List<Message> getMessages()
方法返回值影响。不过这个属性只会在getReceivedMessages方法中使用,这方法的for循环在我看来是跑不掉的,用哈希图反而可能更慢。
MyNetwork中的容器选择:
private final HashMap<Integer, Person> people;
private final HashMap<Integer, Group> groups;
private final HashMap<Integer, Message> messages; private final HashMap<Integer, Integer> emojiHeats;
private final HashMap<Integer, HashMap<Integer, Integer>> adjacent;
可以看到全部选择了HashMap,甚至还有哈希图的嵌套容器。
MyGroup中的容器选择:
private final HashMap<Integer, Person> people;
同样也是哈希图。而且从强测表现来看,这样的容器选择比较正确。
总结来看,如果要求中有两种属性绑定现象比较明显的话,那么我觉得使用哈希图是比较好的选择。
四、性能问题
本次作业卡性能的重点有几个方法。我没有因为算法问题TLE,是因为另一个原因,让我吸取了教训。
除了常见的关于n的复杂度优化,O(1)也埋的有坑···因为比较懒,我在很多方法中,关于getPerson方法,都是无脑直接使用这个方法一次又一次的调用(因为JML规格中就是这么写的),出于对哈希图O(1)的考虑,我基本没有想思考过这个竟然可能会出问题。结果出了问题··后来经过和舍友的探讨,我才明白了O(1)并不真的“1”,只是它的复杂度和指令数可以看成没有关系,但是从哈希图读取value的过程并不是迅速的,它也是需要耗费一些时间的,它的均摊复杂度是O(1)。因此如果不设置局部变量来存储Person,当指令数上去了,人数上去了,查图的时间其实是比较慢的,一万条指令会出现超时。当我设置变量之后,直接快了0.6秒有余,真的非常惊人!
修改前:(不完整代码)
xxxx
else if (getMessage(id).getPerson1().isLinked(getMessage(id).getPerson2())) {
throw new MyRelationNotFoundException(getMessage(id).getPerson1().getId(),
getMessage(id).getPerson2().getId());
} else if (!(getMessage(id).getGroup().hasPerson(getMessage(id).getPerson1()))) {
throw new MyPersonIdNotFoundException(getMessage(id).getPerson1().getId());
} else {
if (getMessage(id).getType() == 0) {
getMessage(id).getPerson1().addSocialValue(getMessage(id).getSocialValue());
getMessage(id).getPerson2().addSocialValue(getMessage(id).getSocialValue());
getMessage(id).getPerson2().getMessages().add(0, getMessage(id));
}
xxxxx
这是其中问题最严重的部分,大量的getMessage,getPerson同样会造成时间增加很多。
此外,对于一些算法我有一些总结。
第一次作业难点在于queryBlockSum。单看这个JML描述感觉非常难以理解这个方法是在干嘛,从方法名字获得一些启发再加上大佬提点,我明白了其实就是求连通块儿的个数。机械的按照JML规格进行for循环一定会超时。经过思考,连通块的计数可以在构建图的过程中就进行(没有删边操作)。增加一个节点(addPerson时,这个节点就是一个连通块,此时它还不与其他任意节点产生联系),连通块儿个数直接加一。在增加边时,对两个节点进行判断,如果这两个节点已经连通(isCircle),那么增加的这个边不会对连通块个数产生影响;如果这两个节点未连通,那么增加一个边会让两个连通块连通,也就变成了一个连通块。这样计算,就可以将连通块作为Network的内部属性,在queryBlockSum时直接返回这个属性,非常快速,避免了超时问题。
public int queryBlockSum() {
return blockNum;
}
(很快的就得到了正确答案)
第一次作业另一个难点在于isCircle的实现。我直接使用了递归的算法,对递归中已经查找过的点进行标记(如果不标记,时间复杂度会大大增加),可以实现O(n)的复杂度,勉强可以符合强测要求。(另外,听说有并查集这个东西可以更快,我大概学习了这个内容,不过没有在自己的代码实现,也大概是因为这个问题,最后一次作业被人hack了一组数据,sendIndirectMessage中先判断连通再计算最短路径的复杂度应该是相当高的)。
第二次作业难点有Group的getAgeMean和getAgeVar。直接进行for循环,每次调用方法都算一遍年龄总和什么的再进行计算,应该也会导致超时。像queryBlockSum一样,能够在平时算好的就尽量算好。设置好年龄和和年龄平方和两个属性。组内加人(addPerson)时,两个属性分别进行增加;删人(delPerson)时,两个属性分别减少。这样在计算年龄平均值和方差时,直接使用这两个属性进行计算,也能避免for循环。其中,方差可以利用这两个属性计算出来,只要用公式推导一下就行。
public int getAgeMean() {
xxxx
return (ageSum / length);
}
public int getAgeVar() {
xxxx
int varSum = age2Sum - 2 * getAgeMean() * ageSum + length * getAgeMean() * getAgeMean();
return (varSum / length);
}
第三次作业难点很显然就是sendIndirectMessage。求两点间最短路径,经过我的学习,有两种算法,一种是Dijkstra,一种是Floyd(复杂度O(n3))。后者虽然比较简单,但是复杂度上应该是更高的。所以我选择了前者。我新增了一个容器用来装载每个节点的邻边信息(空间复杂度应该牺牲了很多)。另外,建立了工具类Dijkstra来专门计算最短路径。Dijkstra的算法复杂度是O(n2),不过在随机性比较强的数据中,很多时候不用遍历完,就已经获得了两点之间的最短路径,我的算法也是根据是否已经找到终点来判断要不要打算while循环的,在这一点上,均摊复杂度应该会有所降低。但是纠结的一点就是我未另外建立容器来存储两点间的最短距离。如果数据是多次询问重复的两点间最短路径,那么存储距离会变得简单很多,但如果每次询问的都是不同的两个人,那么存储反而还浪费时间。
五、作业架构设计
架构上,除了最后一次作业自己增加了用来计算最短路径的工具类,前两次作业都是老老实实地按照接口规格来完成的。在前两次作业只使用了一个容器来存储Network中的人,边的信息没有在Network中存储,而是分给了每一个Person来存储。
第一次作业:
MyPerson:
private final HashMap<Integer, Person> acquaintance;
private final HashMap<Integer, Integer> value;
MyNetwork:
private final HashMap<Integer, Person> people;
第二次作业:
MyPerson:
private final HashMap<Integer, Person> acquaintance;
private final HashMap<Integer, Integer> value;
private final ArrayList<Message> messages;
MyNetwork:
private final HashMap<Integer, Person> people;
private final HashMap<Integer, Group> groups;
private final HashMap<Integer, Message> messages;
MyGroup:
private final HashMap<Integer, Person> people;
第三次作业:
MyPerson:
private final HashMap<Integer, Person> acquaintance;
private final HashMap<Integer, Integer> value;
private final ArrayList<Message> messages;
private final HashMap<Integer, Integer> emojiHeats;
private final HashMap<Integer, HashMap<Integer, Integer>> adjacent;
MyNetwork:
private final HashMap<Integer, Person> people;
private final HashMap<Integer, Group> groups;
private final HashMap<Integer, Message> messages;
MyGroup:
private final HashMap<Integer, Person> people;
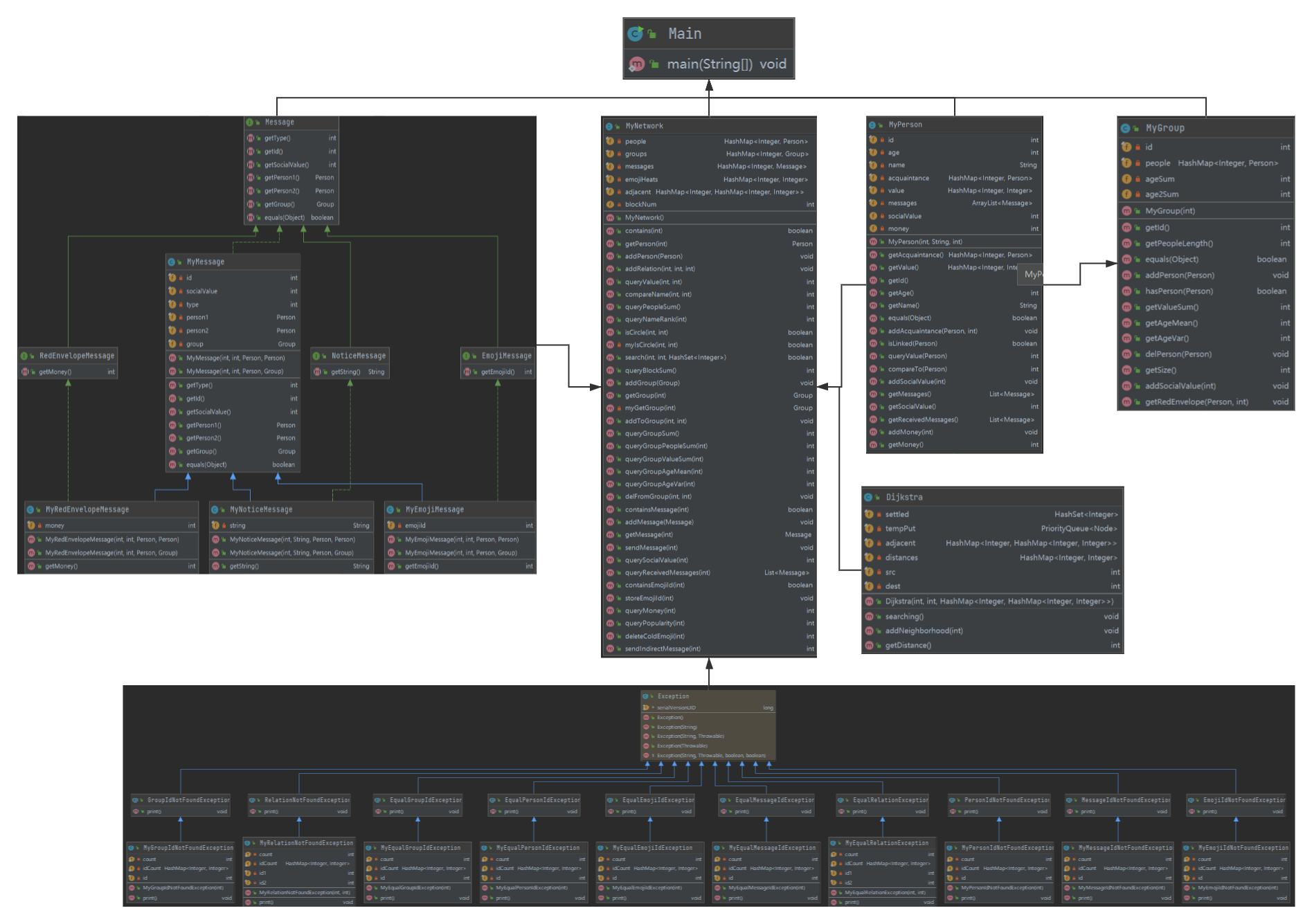
上图为第三次作业的大概架构。因为基本全部不是自己构造的,所以在大体架构上没什么可说的。
不过具体实现上,还是会增加一些自己需要用的而JML没有给出的方法。比如在给红包,算钱的时候,这个行为应该由Group内部来实现,只需要为这个类提供钱和金主就行,因此我会在MyGroup增加getRedEnvelope方法。与此类似的还有增加社交值。也是在Group内部实现,因此增加addSocialValue.
public void addSocialValue(int valueM) {
xxxx
}
public void getRedEnvelope(Person per, int money) {
xxxx
}
还有一种情况,就是当有很多代码重复的时候,也应该考虑把他分离出来。比如很多方法规格中都有通过id来获得具体的group。这样其实不用在每个方法中都写一遍判异常(要求使用的方法里只会返回NULL),只需要在自己再另写一个功能类似的myGetGroup方法在这里面把异常判好,代码也会简洁很多。
public Group getGroup(int id) {
if (groups.containsKey(id)) {
return groups.get(id);
}
return null;
}
private Group myGetGroup(int id) throws GroupIdNotFoundException {
if (!groups.containsKey(id)) {
throw new MyGroupIdNotFoundException(id);
} else {
return groups.get(id);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号