



第一次个人编程作业
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 论文查重算法设计、Git管理、JProfiler使用、单元测试、完成PSP表格 |
1. GitHub地址
-
可运行的jar包已经发布至仓库的release包内
2. PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 50 |
| Development | 开发 | 360 | 420 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 40 | 50 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 360 | 300 |
| · Code Review | · 代码复审 | 120 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 90 |
| Reporting | 报告 | 120 | 150 |
| · Test Repor | · 测试报告 | 120 | 120 |
| · Size Measurement | · 计算工作量 | 30 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| · 合计 | 1600 | 1670 |
3. 计算模块接口的设计与实现过程
3.1 类的使用
SimHashUtils: SimHash算法的工具类,对文本进行分词,获取词的MD5加密过后哈希值,进行加权、合并、降维操作。
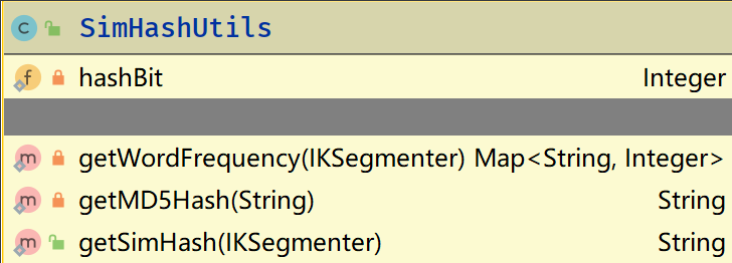
private getWordFrequency(IKSegmenter)是对文本的分词频率进行计算,利用一个哈希表存储起来private getMD5Hash(String)利用MD5加密算法获取词的哈希值,其中hashBit用来固定每个词的哈希长度,以便后续的合并操作,如果哈希值的长度小于hashBit则末尾填充0。public getSimHash(IKSegementer)是获取SimHash的值的方法,其中会对分词的哈希值进行加权、合并、降维的操作,其中获取分词频率则是调用了getWordFrenquency()方法,获取词的哈希值则是调用了getMD5Hash()方法。
此类只有getSimHash()方法是对外开放的,即其他类可以直接调用getSimHash()方法获取哈希值,而不需要暴露获取分词频率和获取哈希值的方法
-
FileUtils: 对文件进行读写操作的工具类。![]()
getSegmenterByFile():通过调用该方法传入文件路径获取IKSegmenter,writeFile():通过传入计算出的相似度和文件路径来把论文查重的结果写入到对应文件路径的文件中。
-
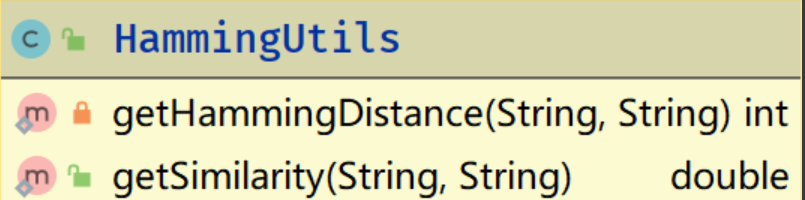
HammingUtils: 获取海明距离并计算相似度的工具类。
-
private getHammingDistance():对传入的两个哈希值进行海明距离的计算 -
public getSimilarity():对传入的两个哈希值进行相似度的计算,在此方法中会调用getHammingDistance()来计算哈希值之间的海明距离。此类只有
getSimilarity()方法是public 的,这样其他类可以直接调用此方法获取相似度,而不对外暴露getHammingDistance()的方法。
ProcessUtils: 对整个查重过程进行封装,测试的时候只需要调入该类的方法,传入原文件路径,抄袭论文的路径,输出答案文件的路径即可。

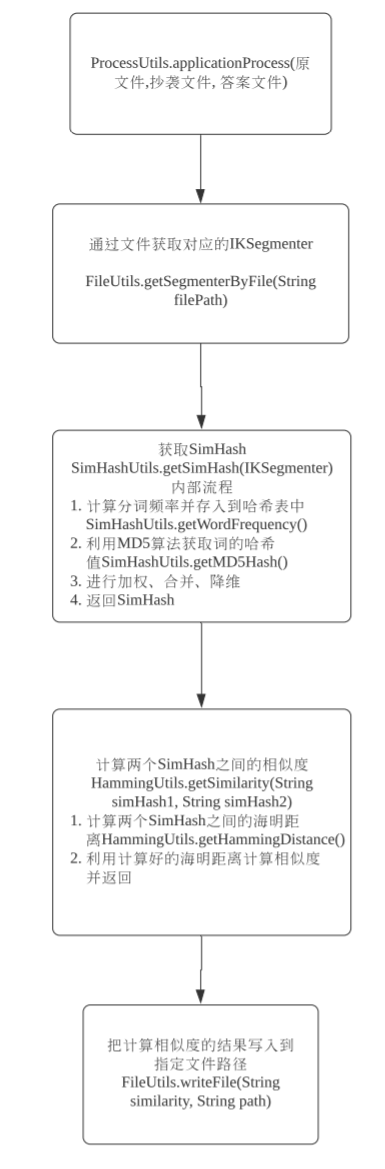
3.2 各类、各函数之间的关系图
3.3 关键算法及独到之处
1. SimHash
- 分词,本项目导入
IKAnalyzer的包,对文本进行分词,其中IKSegmenter存了分词的内容。 - hash,此处利用MD5加密算法,把词转化成一堆0和1的bit。
- 加权,利用步骤2得到的hash,对每个bit进行加权,这里的权重依照的是各词的词频,比如一个词的词频是5,则当bit为0时,对应bit位置的值减去5,当bit为1时,对应bit位置的值加上5。假设hash的长度为5,该词的hash加权之前为01001,加权之后则为-5 5 -5 -5 5
- 合并,对每个加权后的值进行合并,比如其中一个词加权之后-5 5 -5 -5 5,另一个为5 5 5 5 5 5,则进行对应相加。
- 降维,每个词的哈希值加权合并之后如果大于0则置为1,小于或等于0则置为0
2. 海明距离和相似度计算
- 海明距离,拿到计算好后的文本SimHash值进行比对,每对应一位如果不相等则海明距离加一。
- 相似度计算,根据Jaccard系数,相似度 = 两个SimHash之间的交集 / 两个SimHash的并集,Jaccard系数越大,则相似度越高,越小则相似度越低。而交集 = SimHash的长度 - 海明距离,并集 = SimHash长度 + 海明距离。
4. 计算模块接口部分的性能改进
这里测试的是orig.txt和orig_08_add.txt查重的性能分析
4.1 内存消耗
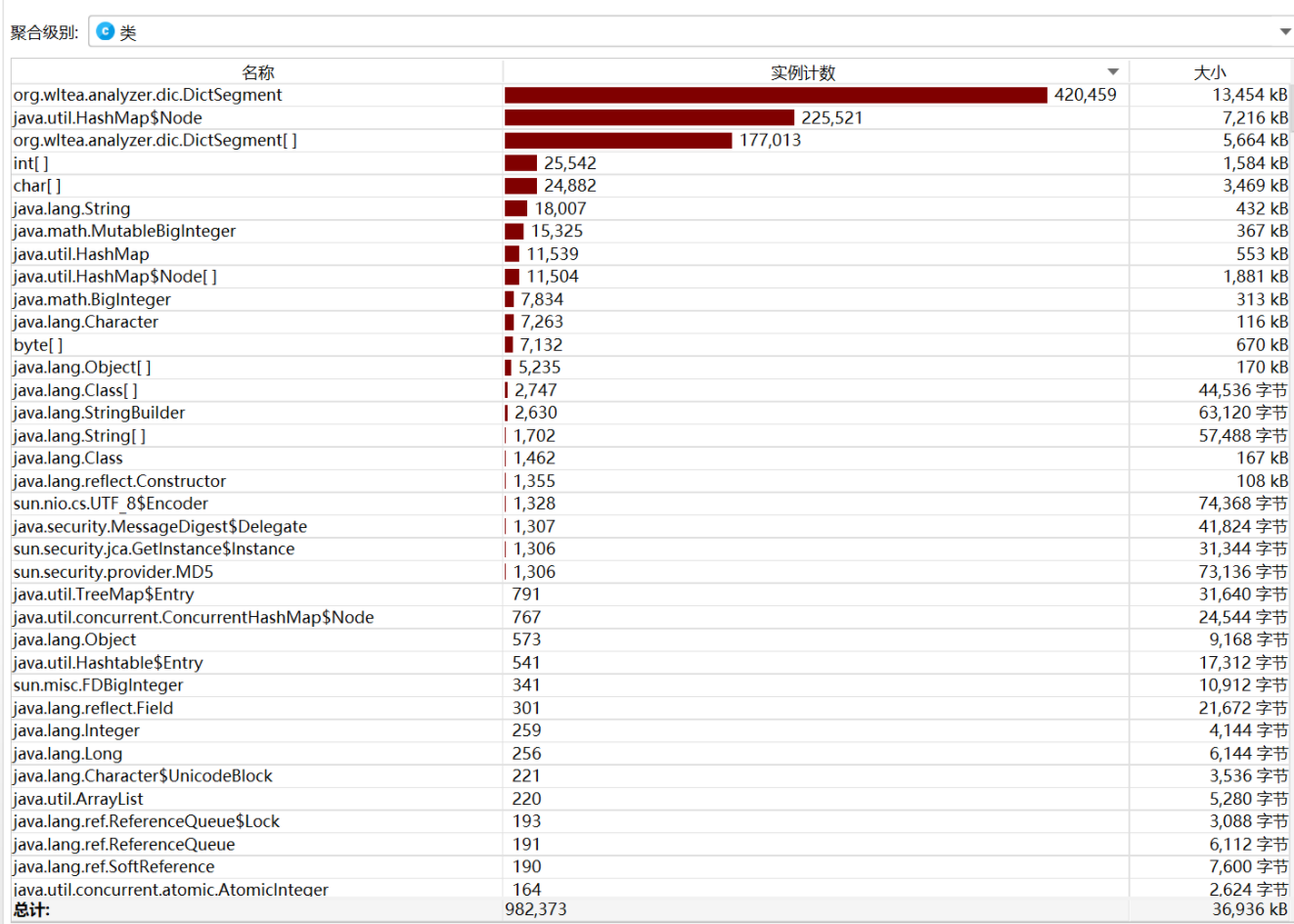
从图中可以看出 程序运行的时候IKAnalyzer消耗大部分的内存,目前还没有更好的方法去改善内存的消耗问题。
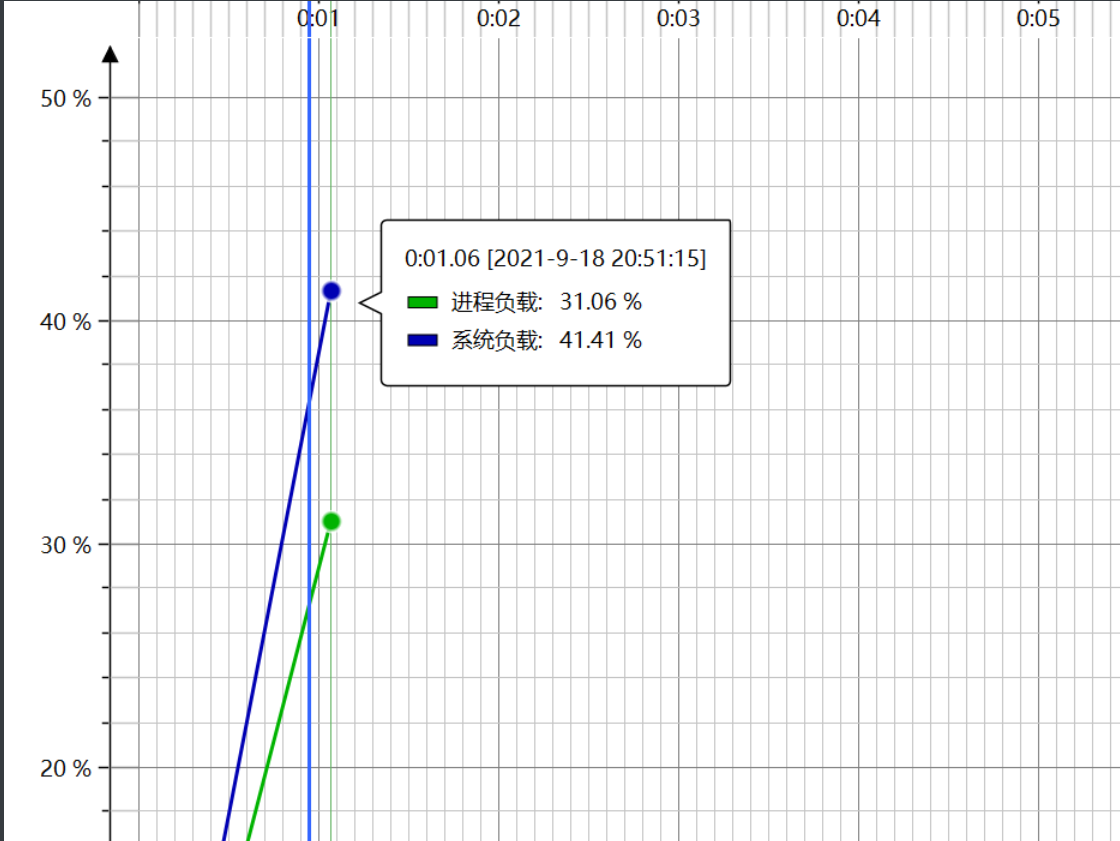
4.2 CPU负载
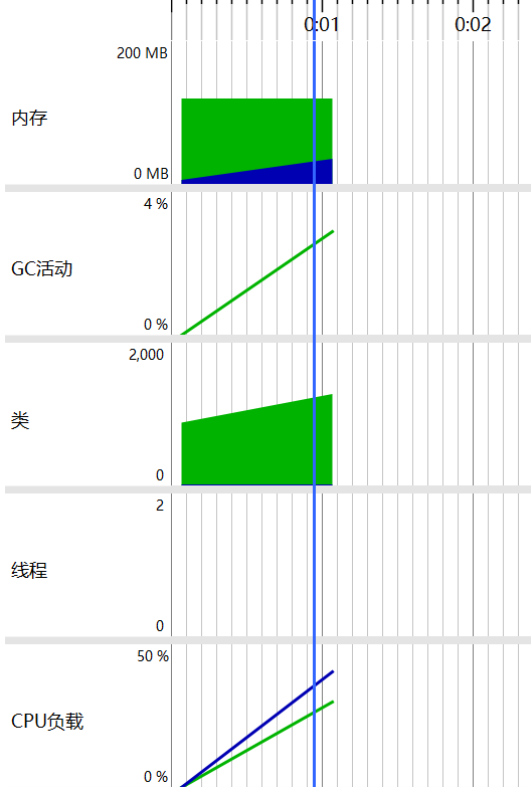
4.3 遥测概况
5. 计算模块单元测试展示
5.1 测试代码
import org.junit.Test;
import utils.ProcessUtils;
import java.io.IOException;
/**
*
* @author zbr
*/
public class TestPaperCheck {
/**
* 1.测试不存在的文件testFile/test.txt
*/
@Test
public void testNotExistPath(){
try {
ProcessUtils.applicationProcess("testfile/test.txt",
"testfile/orig.txt", "testfile/result.txt");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
/**
* 2.测试空文件testFile/1.txt
*/
@Test
public void testEmptyFile() {
try {
ProcessUtils.applicationProcess("testfile/orig.txt", "testfile/1.txt","testFile/result.txt" );
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
/**
* 3.测试orig.txt和orig_0.8_add.txt
*/
@Test
public void testAddFile(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_add.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 4.测试orig.txt和orig_0.8_del.txt
*/
@Test
public void testDelFile(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_del.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 5.测试orig.txt和orig_0.8_dis_1.txt
*/
@Test
public void testDis1File(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_dis_1.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 6.测试orig.txt和orig_0.8_dis_10.txt
*/
@Test
public void testDis10File(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_dis_10.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 7.测试orig.txt和orig_0.8_dis_15.txt
*/
@Test
public void testDis15File(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_dis_15.txt", "testFile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 8.测试orig.txt和orig.txt相同的文件
*/
@Test
public void testSameFile(){
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 9.传入的文件格式不是txt
*/
@Test
public void testWrongFormatFile() {
try {
ProcessUtils.applicationProcess("testFile/orig.txt",
"testfile/testWordfile.doc", "testFile/result.txt");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
/**
* 10. 测试orig.txt和orig_0.8_dis_20.txt
*/
@Test
public void testDis20File() {
try {
ProcessUtils.applicationProcess("testfile/orig.txt",
"testfile/orig_0.8_dis_20.txt", "testfile/result.txt");
} catch (Exception e) {
e.printStackTrace();
}
}
}
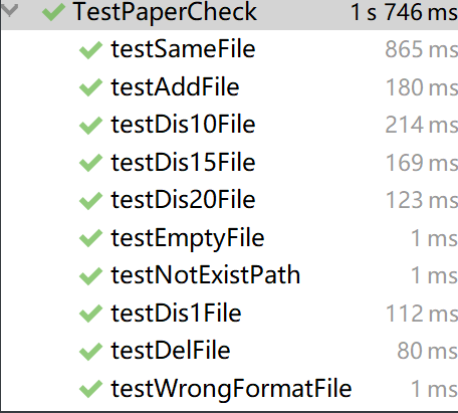
5.2 测试结果
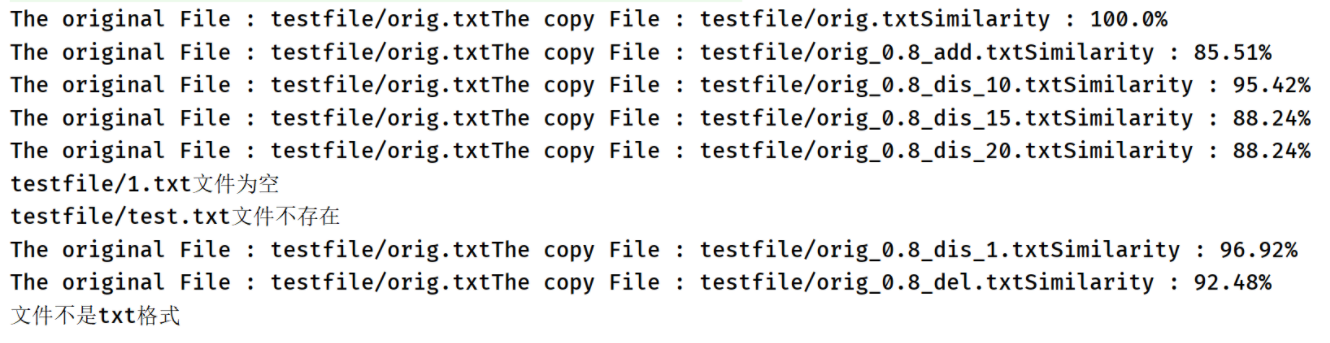
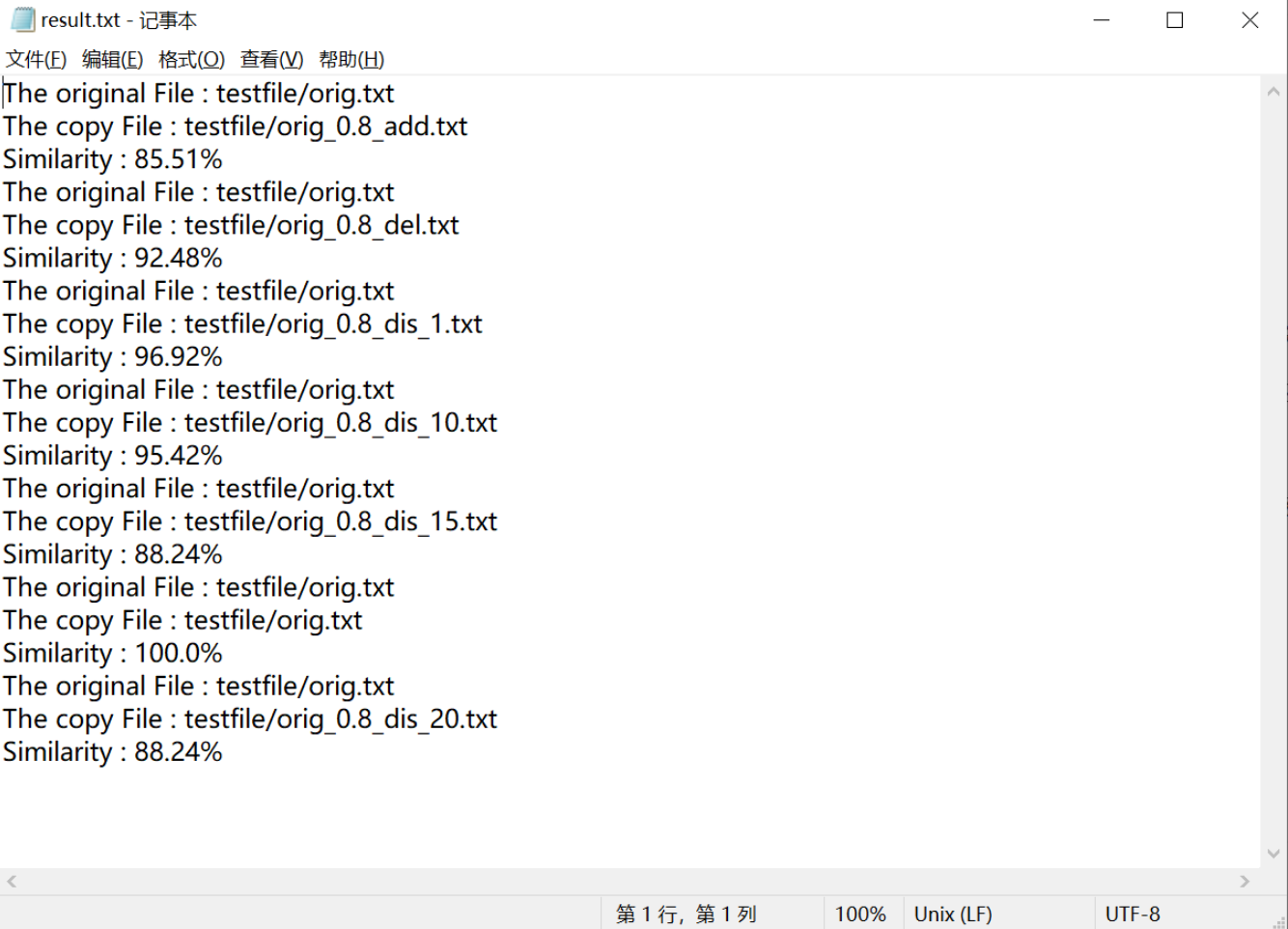
5.3 代码覆盖率

6. 计算模块异常处理
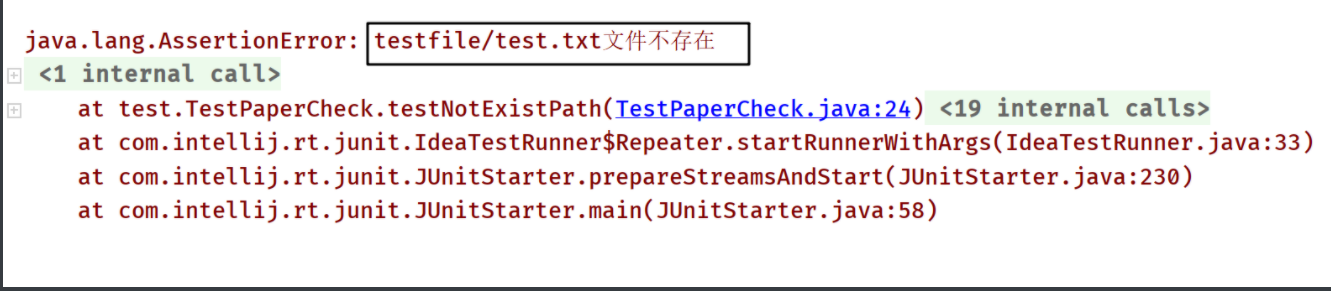
6.1 原文件或抄袭文件不存在
/**
* 1.测试不存在的文件testFile/test.txt
*/
@Test
public void testNotExistPath(){
try {
ProcessUtils.applicationProcess("testFile/test.txt",
"testFile/orig.txt", "testFile/result.txt");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
测试结果:
6.2 原文件或抄袭文件为空
/**
* 2.测试空文件testFile/1.txt
*/
@Test
public void testEmptyFile() {
try {
ProcessUtils.applicationProcess("testFile/orig.txt", "testFile/1.txt","testFile/result.txt" );
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
测试结果:

6.3 文件不是txt格式
/**
* 9.传入的文件格式不是txt
*/
@Test
public void testWrongFormatFile() {
try {
ProcessUtils.applicationProcess("testFile/orig.txt",
"testfile/testWordfile.doc", "testFile/result.txt");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
测试结果:

7. 代码质量检查
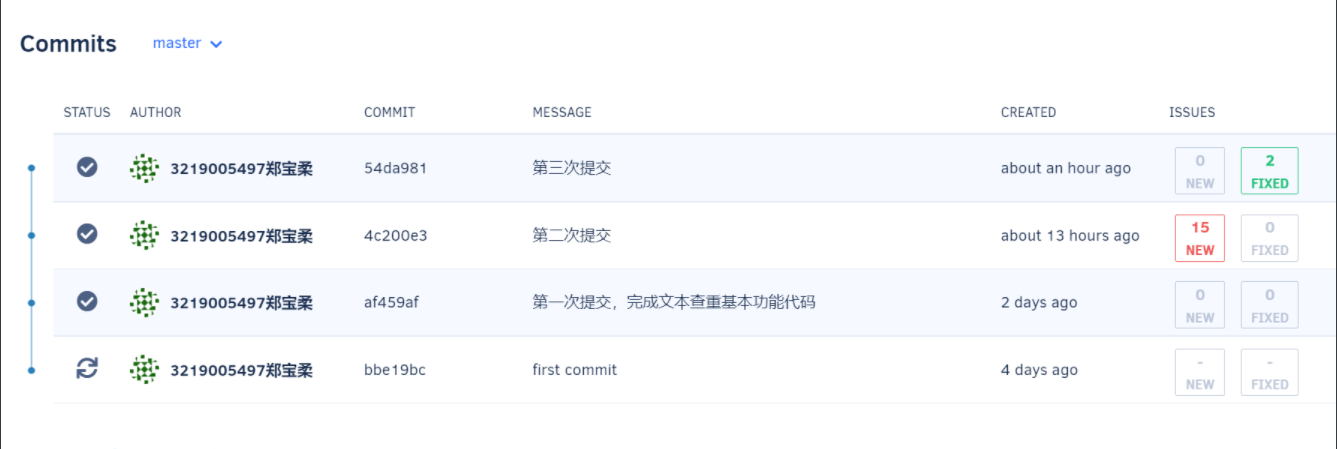
第二次提交上去的时候还是有一些代码规范问题的,比如不用的包没有及时去掉,修改之后通过了代码质量检查。
8. 总结
这次的项目一开始会比较迷茫,不知道从何下手,但填写了PSP表格计划时间之后,按部就班地完成对应的模块,计划也就越来越清晰。主要遇到的瓶颈是理解SimHash算法,一些与代码无关的路径配置问题。但只要是理解了算法核心部分,开发起来就变得容易许多。总的来说,这次个人项目作业我也收获了许多,虽然遇到了一些瓶颈,但也陆陆续续解决了,提高了解决问题的能力,发现了更多解决问题的渠道。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号