
OO第一次博客
2018-04-03 23:15 ankifrog 阅读(156) 评论(0) 收藏 举报首先生成三次作业的类图并对代码进行度量分析。
第一次作业
1.类图

完全没有OO的感觉……更像是一个功能很多的方法集合
优点:无
缺点:类过于单一(就一个),功能臃肿
2.度量分析
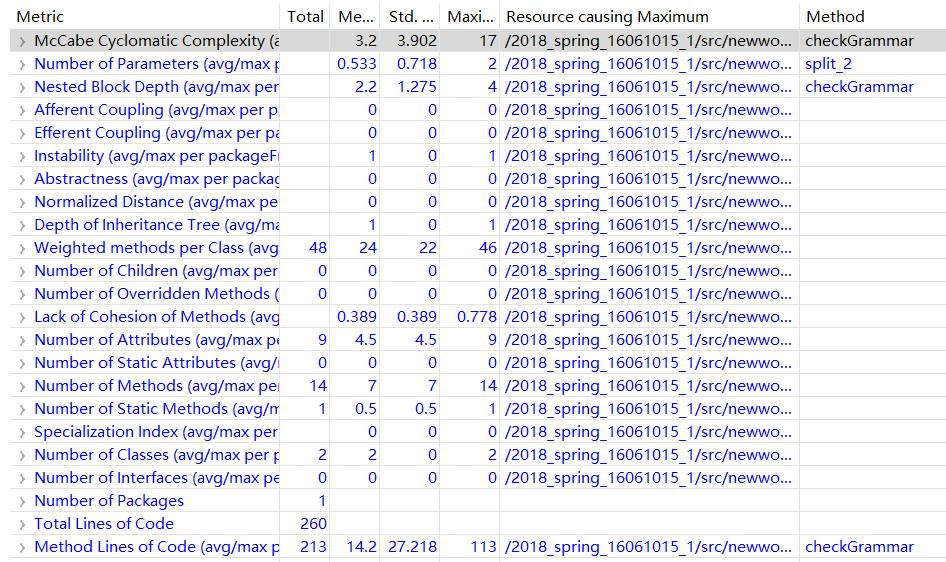
逻辑比较简单,出现问题不大。
3.自身BUG分析
由于对正则表达式不够熟悉,我采取使用split分割原字符串,之后存到数组中的方法。由于我一开始考虑的时候,认为至少存在一个(a,b),故先后对}和,进行split,结果在面对不完整输入的时候,便会出现给数组赋值空值,并进行计算的错误。
其次,由于对指导书的硬性要求不是非常了解,我把部分硬性要求当做可在readme中规定,比如对于输入多项式个数的规定(我以为测试者也不能输入超过50个,结果对方使用大数据使我的数组越界),被对方抓住了把柄。
这些BUG产生的主要原因还是在于我并没有充分理解指导书的要求,并且程序缺乏鲁棒性,对错误输入没有全面的处理,以至于出现了crash的问题。
4.对方BUG分析
我从对方的正则表达式中发现了对方并没有处理“错误输入中含有正确子串”的场合,同时通过阅读其代码逻辑发现其他不足。
在这个过程中,我采取的主要方法是阅读其代码,重点看对方有没有和自己犯相同的错误。
5.总结
由于是第一次使用面向对象编程,所以我刚接触这个任务的时候,还有些不适应。特别是我们这门课的特色互评制度,还有指导书的存在,使得我有些手足无措。
由于第一次互测,我没有准备足够多的测试样例,无论是对自己代码的检查和对对方代码的纠错,都不够效率。
第二次作业
1.类图

优点:某种程度上做到了各司其职
缺点:仍然存在臃肿的现象,部分类虚有其表
2.度量分析

如同纪一鹏老师所说,程序中嵌套不宜太深,应当最多不超过4,5层。这个主要是由于我频繁使用其他类中的属性进行比较导致的。
修改措施:将该属性比较写成方法,需要进行逻辑判断的时候,直接调用类中的方法,以减少块嵌套深度。
3.自身BUG分析
全部为readme中没有说明的模糊问题:前置0个数以及超过100条指令的处理。
另外一条关于整数超标的BUG,来自我对前置0的处理。我设置程序可以读取(正则表达式匹配)1到10位的整数(包含前置0),但是并没有考虑到10位的整数有可能超过int范围,只需减少允许前置0的个数即可解决这一问题。
4.对方BUG分析
对方的BUG实在太多。
首先通过简单阅读对方代码的核心部分——正则表达式,逻辑部分,以及错误处理部分,发现了对方对于某些场合只能发现存在错误,但是 压 !根 !没 ! 有 !输出ERROR。关于这个错误,理论上可以把对方的树挂满,但是出于人道主义精神,我把所有此类的错误全部归在一个点,并在备注里向对方说明了这一情况。
越过了阅读代码的流程,下面进入了轰炸阶段(测试样例):
①边界测试。之前我注意到对方使用了大数组结构,且并没有对超过100条指令进行处理,所以构建了一个超过10000条指令的无耻测试样例(对方数组大小为10000)。在这个阶段,还有诸如空指令,无输入,不完全输入等测试样例。
②复杂测试。通过又臭又长的测试样例(100条以内),测试对方是否存在BUG。
③集中测试。如果②中发现了问题,则找出发现问题的地方,构建测试样例挂掉对方。
④补刀测试。构建很巧的数据,对指导书中提到的临界情形进行测试。
5.总结
总体上,我这次的程序本身没有BUG……
但是!我遇到了天灾人祸……
由于临近周三晚上7点的时候我还在热火朝天地DEBUG,而我习惯在最后才提交作业的最终版本,所以当评测姬崩溃的时候,我慌了……
评测姬对于部分测试样例,不输出结果,导致我以为我在debug的过程中增加了大量的新bug,于是我到gitlab网站上找到了之前的代码重新提交,这才发现并不是我的代码的问题,而是评测姬的问题。然而,这时我已经浪费很长时间在之前de“新BUG”的过程中了,离7点已经不远了。
在最后的提交中(18:58!!!!),我虽然将代码和readme都上传到gitlab了,但在评测网站上只拉取了代码部分,毕竟当时只想着测试样例是否正确,而readme还保持着周二的版本……
所以,下次一定要注意这方面的问题。
第三次作业
1.类图
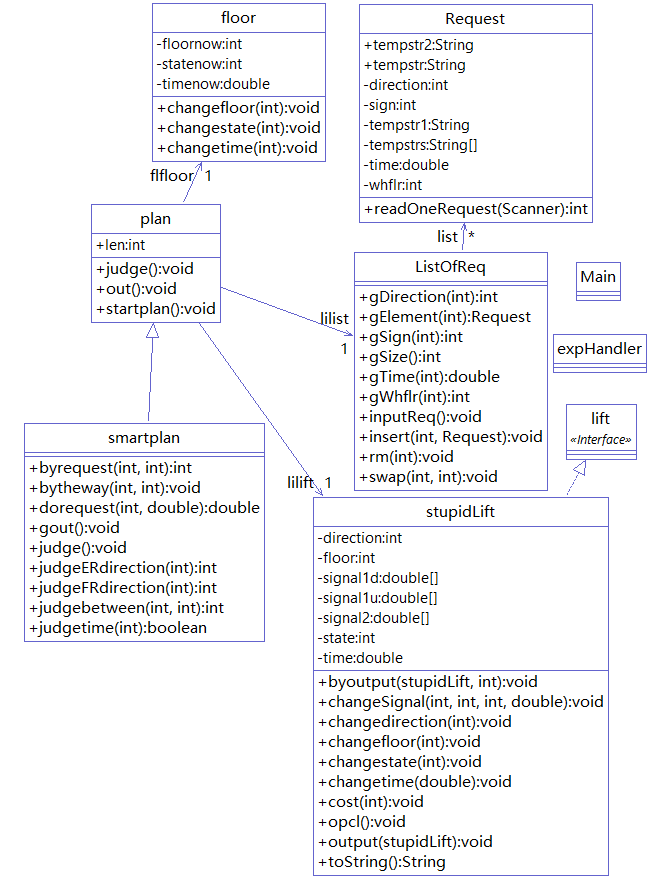
优点:类的方法充足
缺点:缺少条件判定的方法,频繁调用get方法导致程序复杂。仍然存在类的功能分配不均的问题。
2.度量分析

第三次作业中除了第二次中已经出现的问题,还有着复杂度较高的问题,这个主要是由于使用了过量的判定条件。
修改措施:一方面和块嵌套过深的解决方案一样,增加类中的判定方法;另一方面也要理清逻辑,减少多余的判定。
3.自身BUG分析
直到最后一刻,也没能解决对于同时刻的相同请求,按照时间顺序输出的问题。
我的程序中,对捎带的解决是通过构建捎带列表,依次执行列表中的指令,最后再处理主指令。这使得当捎带列表中存在和主指令同时刻的请求时,便会出现输出顺序乱序的的问题,导致了众多问题的出现。公测中的问题和互测中被发现的问题,均和此条有关。
4.对方BUG分析
不是我军无能,而是敌军太狡猾……
5.总结
惨痛痛痛痛痛痛痛痛痛痛痛痛痛痛痛痛痛痛定思痛。
对于大工程,真的需要多留些时间来解决。这次没有投入充分的时间来解决本次作业是我的错误,在第五周的多线程作业中,我一定会留出足够多的时间。
总体心得体会
和课上给出的推荐类图一比较,我便发现了自己的设计存在明显的不合理之处。
我的主要类普遍比较臃肿,而其他类则显得功能较单一。出现这个现象的根本原因在于我还是停留在面向过程编程的思维范式中,不能很好地进入面向对象编程的思维模式。对于各类之间的划分,我没有做到很明确,典型的体现便是第二次和第三次作业中存在的块嵌套深度过深的问题。
此外, 对于三次作业中出现的crash错误,我应当予以反省,毕竟很早老师便讲授了try—catch的写法,在原则上是不会产生crash错误的,顶多程序无法继续运行下去。
面向对象的编程,不能像以前写c程序一样,把方法和类像堆砌函数一样,只为了实现功能而不考虑简洁性、可读性、健壮性和鲁棒性。在开始动手写程序之前,一定要理清逻辑,最好是在纸上画出自己功能流程图——其实也就是类图。在这个阶段,也要尽可能地考虑到可能存在的边界数据和BUG,否则一旦程序中功能实现与逻辑方法产生冲突,便会出现我第三次作业中出现的难以debug的现象.
经历了三次愉快的互评,我们相比都认识到了死抠指导书和完善Readme的重要性。在指导书的最终版本出来之前,我们最好不要立刻动手完成程序的主体逻辑部分,虽然有的错误可以简单改正,但是有些诸如顺序、数据类型的改动修正起来就很麻烦。在这段时间内,我们可以完成上述所说的理清逻辑的工作。对于Readme,我认为应当先写一份草稿,之后在完成程序的过程中,对Readme进行完善,最终检查一次,便可以大功告成。
在下次的作业中,我打算带着我得到的心得体会将程序重写一份,尽可能地使程序变得简洁高效,增加程序的鲁棒性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号