本文所有内容基于markdown,如果不能正常显示,建议卸载浏览器并安装最新版本。
原创内容,转载请注明来源https://www.cnblogs.com/zhber/p/10016909.html
-
设计PSP表格(见7)
-
解题思路描述
代码要实现的功能分两部分,一是计算给定数独局面的解,二是生成\(T\)个不重复的数独解,\(T\)的规模\(1e6\)。
-
对于第一部分,注意到给定局面的一些位置可以由同一行/列/块已确定的数字推出来,因此先暴力松弛,即枚举每个位置,遇到可以确定的位置就填上去,并重新开始一轮松弛。如果都没有可以确定的位置了,松弛环节结束。显然松弛操作不会超过\(81\)次。接下来的位置填法不唯一,没有太好做法,直接\(dfs\)爆搜所有可能情况。
- 另解:考虑问题转化为精确覆盖问题,即:给出一个二维的只包含\(01\)元素的矩阵,选出一些行的集合,使得集合中每一列有且恰好有一个\(1\),如可以一起选\(0101\)与\(1010\),但不能一起选\(0101\)与\(1110/0010\)。那么可以把这个问题转化一下变成\(729\)行\(364\)列的\(01\)矩阵的精确覆盖问题,然后套一个dancing link模板即可。因为精确覆盖问题是要每一列都有恰好\(1\)个\(1\),令前\(81\)列表示数独\(81\)个位置必须都填上,再\(81\)列表示数独\(9\)行的\(9\)个数字都要用上,再\(81\)列表示数独\(9\)列的\(9\)个数字都要用上,再\(81\)列表示数独\(9\)块的\(9\)个数字都要用上。对于每个位置的每一种填法建一行,把这个位置的这种填法对应的位置、对应行的数字、对应列的数字、对应块的数字的那\(4\)列填\(1\),其他位置填\(0\),跑一遍dancing link即可出解。
-
对于第二部分,要求生成的是很多不重复的数独解,输出很多个 不重复解是问题所在。
注意到对于一个合法的数独解,我们把任意一对数字的位置互换,比如把所有数字\(2\)和数字\(9\)的位置互换,就可以得到一个新的数独解。那么一个解实际上给出了一种分配数字的方案,打乱编号顺序能构造出的不重复解有\(9!=362880\)个。再考虑合法解旋转\(90°\)、\(180°\)、\(270°\)后同样是合法解(但不一定不重复),以及交换同一块内的两行或两列同样是合法解(也不一定不重复),能构造出的解有\(9!*4*(A_3^2)^6=67722117120\)种,远大于\(1e6\)。当然,这里面肯定有不少重复情况,但拿出\(1e6\)种不重复情况绰绰有余。因此问题只在于生成初始的合法数独解。可以考虑随机生成几个残局,然后用第一部分的算法跑几个合法解来使用,无解就多跑几次,直到有解。也可以考虑打表,预处理几个合法解放在配置文件里,运行时从里面读取。
-
-
设计实现过程
第一部分,套个DLX模板即可。DLX不是很方便,最好能将这部分封装好,然后直接调用接口。
第二部分,代码里预留一个写死了的合法数独解,通过调换把\(2\)翻到左上角,然后把\(13456789\)几个数字轮换,外面再套一个四到六行和四到六列的任意调换,就是\(8!*(A_3^2)^2=1451520\)已经够了。
详细的需求分析、设计可参阅仓库里的 设计文档.docx
此处列举一部分设计内容,仅供参考。
一、主模块:实现程序的基本功能。 1、 init()函数 介绍:为实现功能,程序需要一个初始化函数,用于处理和检测输入、判定操作类型等。 原型:int init(int argc,char** argv); 参数说明:把主函数的参数原样传入,以处理输入。 返回值说明:返回值为0,代表执行一个’-c’操作。返回值为1,代表执行一个’-s’操作。 2、 work_c()函数 介绍:处理’-c’操作的代码部分,用函数封装,而不用在主函数中堆砌。 原型:void work_c(int n); 参数说明:传入数据是一个数字n,表示要生成的数独个数。 返回值说明:无返回值(void)。 3、 work_s()函数 介绍:处理’-s’操作的代码部分,用函数封装,而不用在主函数中堆砌。 原型:void work_s(); 参数说明:无输入。由于输入输出改版,文件路径不需要再作为参数传入。 返回值说明:无返回值(void)。 4、 class Sudoku 数独类型 介绍:用于存储单个数独信息的结构体。 原型: class Sudoku{ public: int d[9][9]; Sudoku(){}; void init(); void out1(); void out2(); }; 成员说明: public int d[9][9]; 一个存储数独内数字的二维矩阵,取值范围为0~9。1~9表示已经填入对应数字,0表示未确定此处的数字 public Sudoku(){} 构造函数,数独创建时自动把一个已经填入数字的样例数独赋值给它 public void init(); 初始化函数(从文件中输入)。用于从文件中读取给定的数独局面。由于输入输出改版,文件路径不需要作为参数传入 public void out_s(); 输出函数,适用于’-s’操作的输出函数 public void out_c(); 输出函数,适用于‘-c’操作的输出函数 -
记录在改进程序性能上所花费的时间,描述你改进的思路,展示性能分析图,并展示你程序中消耗最大的函数。
在改进程序性能上花费了很多时间。
12.13:添加了fastIO来优化,同时代码大修,加了很多static/register以及某些常数优化来加速。
12.16:尝试学一下汇编+底层优化,失败了,怎么都过不了编译……
12.17:这几天陆陆续续改好了第二版fastIO,删除了几乎所有冗余的代码,感觉没有可以优化的了。
12.28:在最后审阅的时候发现原来都是用VS的Debug模式生成可执行文件,换成Release后发现快了很多……
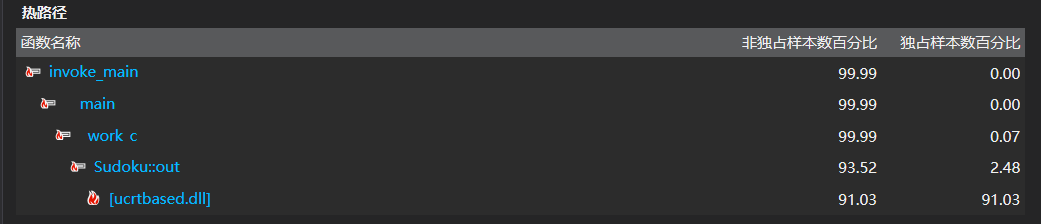
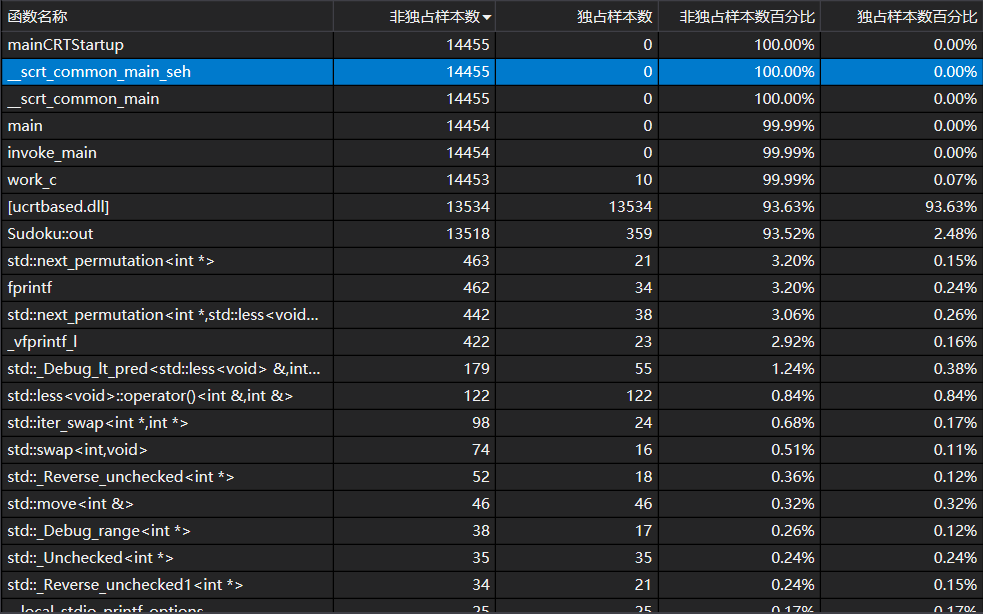
以下为第一版代码的性能分析图(函数视图,按采样样本数从大到小排序):
![性能分析0]()
![性能分析1]()
[ucrtbased.dll]不知是什么,应该是某个系统函数的动态链接库。但是可以看到Sudoku::out函数即输出函数的占用率极高,达到90%以上。这说明输出较慢时一个很重要的瓶颈。
因此考虑优化主要以加速I/O为主。
- 为了加速输入输出,可以考虑把fprintf的格式化输出数字替换成fputc输出单个单个的字符。
- 结果:有一点效果,但是还是比较慢。
- 考虑使用更底层的fwrite/fread实现I/O,那么要自己写一套缓冲区的输入输出。参考了鄙队的ACM模板写出第一版fastIO.hpp。
- 结果:果然快了很多。
- 然后陆陆续续加了一些常数优化,比如一些局部变量移出来变成全局变量再加static,不能移出来的加register,嵌套for里定义的变量移出来,把一些if用:?替换,一些加法尽量用位运算替换,等等。
- 结果:感觉不明显。
- 陆陆续续搞出第二版fastIO.hpp,删掉了很多没用的细节。
- 结果:快了大约30%,但是没有第一版一下快那么多那么舒服了。
- 令人窒息的操作:把Debug切换到Release
- 结果:握草快了好多啊!感觉时间只有原来的四分之一了
- 为了加速输入输出,可以考虑把fprintf的格式化输出数字替换成fputc输出单个单个的字符。
-
代码说明
此处选择一些有代表性的代码。
void Sudoku::init()//初始化 { register int i, j; for (i = 0; i < 9; i++) for (j = 0; j < 9; j++) { if (read(d[i][j]), IOerror) { if (!i && !j && ~IOerror) return; else { puts("Error : not valid input."); exit(23333); } } } }此代码用来从文件中读取一个完整的数独。
首先局部变量从for嵌套中提出来而且加register,不用解释。
函数调用了fastIO::read读取了81次数据,然后保存在二维数组Sudoku::d中。
逗号运算符的返回值为后者,如(a,b,c)的返回值为c。因此在if中判断的就是fastIO::IOerror。这里纯属装X写法。当出现读入错误时,根据fastIO的实现,会有两种情况:一是读到了非法字符,即\(\{0...9,'\ ','\backslash t','\backslash n'\}\)以外的字符。另外一种情况是读到了文件尾
EOF。第一种情况fastIO=-1,不进入后面的第二个if判断。唯一的合法情况只有读到文件尾时刚好读完,此时应该是恰好下一个数独的第一个位置读取就报错,即\(i=j=0\),并且fastIO=1.此时进入if判断,会直接退出函数。否则直接报错并且程序报异常退出。返回值23333意义请见设计文档的约定。inline void work_c(int n)//处理参数是-c的情况 { refreshOut("sudoku.txt"); if (n <= 0)return; Sudoku now; std::swap(a[1], a[now.d[0][0]]); std::swap(a[1], a[2]); register int i, j, k; for (i = 1; i <= 6; i++) { for (j = 1; j <= 6; j++) { for (k = 1; k <= 40320; k++) { now.out_c(); if(!(--n))return;else print('\n'); std::next_permutation(a + 2, a + 10); } std::next_permutation(col + 3, col + 6); } std::next_permutation(row + 3, row + 6); } }此代码用来执行-c操作,参数为\(n\)。
fastIO::refreshOut("sudoku.txt")用于将输出流重定向到一个相对路径sudoku.txt里。
if (n <= 0)return 这句意义不大,因为init()初始化已经判定不合法的n退出。
Sudoku now 初始化一个数独,构造函数将会把写死的一个模板复制上去。
初始\(a_i=i\),两个std::swap的作用是把学号对应的数字\(2\)换到数独左上角首位,同时保证剩下的\(8\)个数字恰好在\(a_2...a_9\)。
此后三个循环,
for i和row数组控制数独第4到第6行的轮换,for j和col数组控制数独第4到第6列的轮换,for k和a数组控制数独剩下8个可移动数字的轮换。std::next_permutation是得到下一个排列。在循环内部,每次执行n--和输出结果,变换结果可以根据a/row/col数组直接得到,即原来输出d[i][j]此时直接输出a[d[row[i]][col[j]]]。当n=0时直接退出。 -
完成PSP表格
PSP 2.1 Personal Software Process Stages 预估耗时(分钟) 实际耗时(分钟) Planning 计划 · Estimate · 估计这个任务需要多少时间 2 3 Development 开发 · Analysis · 需求分析(包括学习新技术) 60 45 · Design Spec · 生成设计文档 120 240 · Design Review · 设计复审(和同事审核设计文档) 60 10 · Coding Standard · 代码规范(为目前的开发制定合适的规范) 10 10 · Design · 具体设计 120 90 · Coding · 具体编码 720 1200 · Code Review · 代码复审 120 60 · Test · 测试(自我修改,修改代码,提交修改) 720 480 Reporting 报告 · Test Report · 测试报告 180 180 · Size Management · 计算工作量 20 10 · Postmortem & Process Improvement Plan · 事后总结,并提出过程改进计划 120 30 合计 2252 2358 一些感悟
- 软件工程确实是一门很难的学科啊……感觉写代码和优化很简单,但是写文档真是要了我的命,尤其是画图
- 我猜这是个敏捷开发过程,因为我的需求一直在变,想到啥加啥(逃
- 感受到设计文档的好处,虽然这是第一版出来之后补上的。确定了函数接口有助于检查代码安全性和防止溢出,但是之后不能随便乱改了,算是有利有弊吧
- 感到
Windows跑这种运行时间很长的代码不是很友善啊……大概是因为内核调度的原因每次跑出来时间都不一样,而且波动很大啊,我应该取一个平均数吗? - 造数据的时候,又来了——“这代码怎么会还有问题?”——“握草我又把自己代码X掉了”,感觉还是要学习一个
Visual Studio真辣鸡!Mingw大法好!
更新日志
2018.11.25
- 更新一个补全数独的demo,过了poj2676,正确性应该没问题了吧?
2018.11.26
- 发现并没有那么简单……原来要先做需求分析……心态爆炸
- 推倒重写
- 我真的好菜啊
- 补上psp表格,填了个看上去很合理的预期时间(应该算合理吧?)
- (设计文档怎么写啊?我不会啊?)
- 完成解题思路描述
- todo:
- 设计文档 不会写也要硬着头皮写
- 解题思路写得太长,要砍掉一点
2018.11.27~12.02(补)
- 忙着各种事,啥也没干
- 我真的好菜啊
2018.12.03
- 我真的好菜啊……时间真的来得及么
- 赶紧发挥人类智慧弄了一个看上去还行的技术文档
- 设计复审是什么啊?就是给别人看一眼吗?
- 把dancing links封装到dlx.hpp里面
- 然而被文件路径的判断制裁了……并没有拼出来一个能跑的.exe
- 感觉判断文件路径是否合法好难啊?不会啊
2018.12.04
- 试着用regex搞一发文件路径判断,感觉似乎很有道理
- 怼出来一个能跑的exe了……终于敢commit一下push了
- 测了下-c的极限数据,感觉读写实在太慢
- 我好菜啊
- todo:
- 太慢了 弄个fastIO上去
- 测一下-s的极限数据是不是很爆炸
2018.12.05~12.13
- 摸鱼,并且忘记写文档辣
- fastIO.hpp 断断续续弄好了,感觉跑得飞快 -c 1e6 只要6.5s
- 感觉dancing link还是慢啊……不知道该怎么办啊 -s的满数据还是170秒
- todo
- 用mmap再改一改fastIO(我要跑的比香港记者都快
- 试下IDA*爆搜或者其他什么解数独的算法,如果比dancing link 更快就换了吧
- 尝试着写一下各种文档
2018.12.14~12.30(补)
- 汇编优化失败
- 感觉剪枝爆搜并不会比dancing link更快,有点难受了
- 开发fastIO 2.0完成,感觉快了一小些
- 把Debug换成Release,发现怎么时间变成原来四分之一啊?
- 我好菜啊
- 改了改设计文档
- 构造测试用例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号