会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
Loading
Zhbeii
博客园
首页
新随笔
联系
订阅
管理
上一页
1
2
3
4
5
6
7
8
9
···
21
下一页
2022年1月21日
重构RDD以及RDD的持久化
摘要: 第一,RDD架构重构与优化 尽量去复用RDD,差不多的RDD,可以抽取称为一个共同的RDD,供后面的RDD计算时,反复使用。 第二,公共RDD一定要实现持久化 北方吃饺子,现包现煮。你人来了,要点一盘饺子。馅料+饺子皮+水->包好的饺子,对包好的饺子去煮,煮开了以后,才有你需要的熟的,热腾腾的饺子。
阅读全文
posted @ 2022-01-21 14:12 Zhbeii
阅读(43)
评论(0)
推荐(0)
2022年1月20日
Kryo序列化
摘要: Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字
阅读全文
posted @ 2022-01-20 12:35 Zhbeii
阅读(381)
评论(0)
推荐(0)
Spark算子
摘要: Spark的transformation算子(不少于8个)(重点) 单Value (1)map:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换 (2)mapPartitions:将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤
阅读全文
posted @ 2022-01-20 12:05 Zhbeii
阅读(302)
评论(0)
推荐(0)
Spark的架构和作业提交流程
摘要: 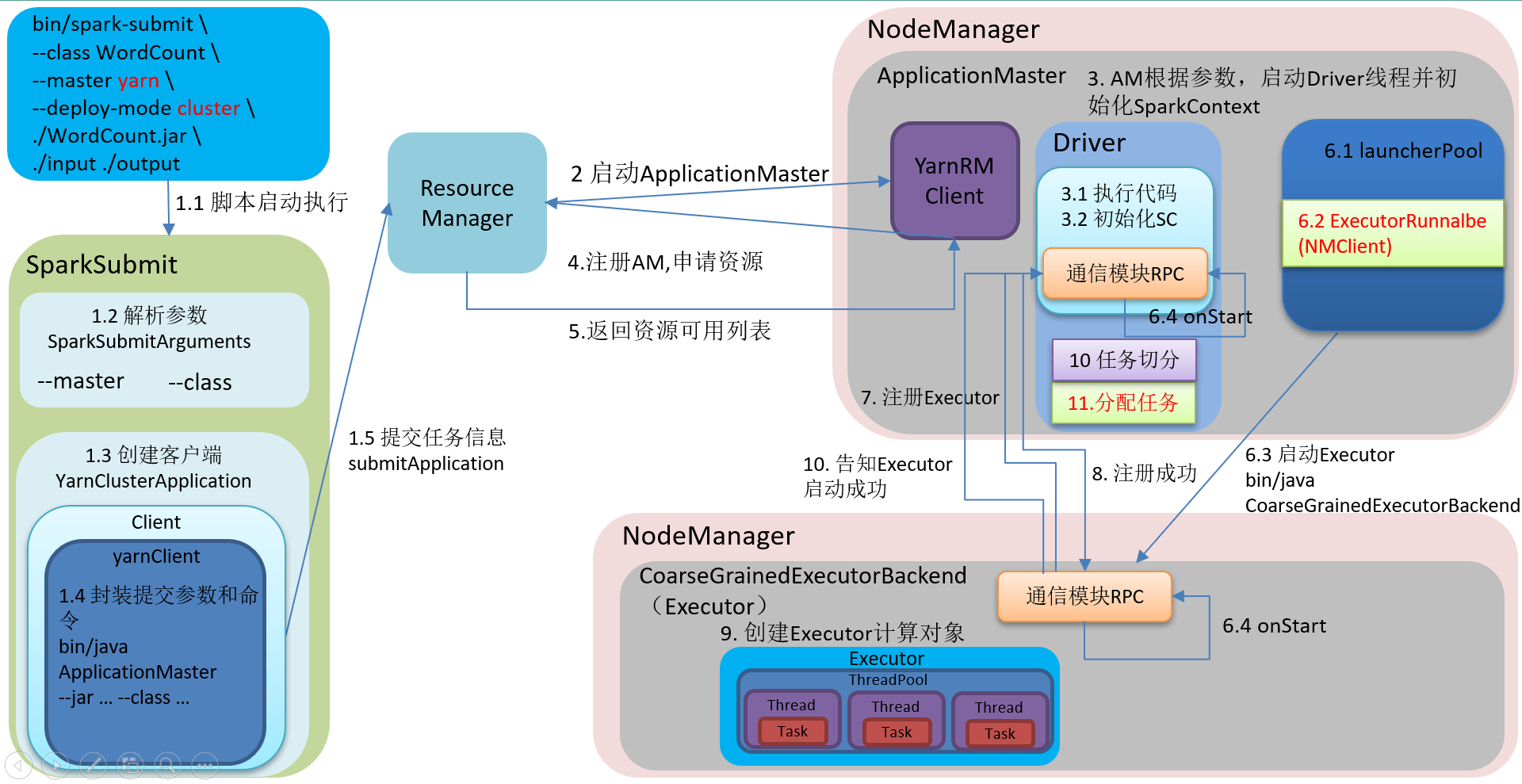
阅读全文
posted @ 2022-01-20 11:39 Zhbeii
阅读(45)
评论(0)
推荐(0)
Zookeeper
摘要: 第一次启动 非第一次启动
阅读全文
posted @ 2022-01-20 10:52 Zhbeii
阅读(22)
评论(0)
推荐(0)
2022年1月19日
Yarn工作机制
摘要: Yarn生产环境核心参数
阅读全文
posted @ 2022-01-19 19:24 Zhbeii
阅读(34)
评论(0)
推荐(0)
MapReduce
摘要: MapReduce MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 多个溢出文件会被合并成大的溢出文件 在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序 ReduceTask根据自己的分区
阅读全文
posted @ 2022-01-19 19:05 Zhbeii
阅读(47)
评论(0)
推荐(0)
HDFS小文件处理
摘要: 缺点: 存储层面:1个文件块,占用namenode多大内存150字节 128G能存储多少文件块? 128 g* 1024m1024kb1024byte/150字节 = 9.1亿文件块 每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenod
阅读全文
posted @ 2022-01-19 19:02 Zhbeii
阅读(297)
评论(0)
推荐(0)
HDFS
摘要: 简介 定义: HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。 HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关
阅读全文
posted @ 2022-01-19 16:51 Zhbeii
阅读(104)
评论(0)
推荐(0)
表的同步策略
摘要: 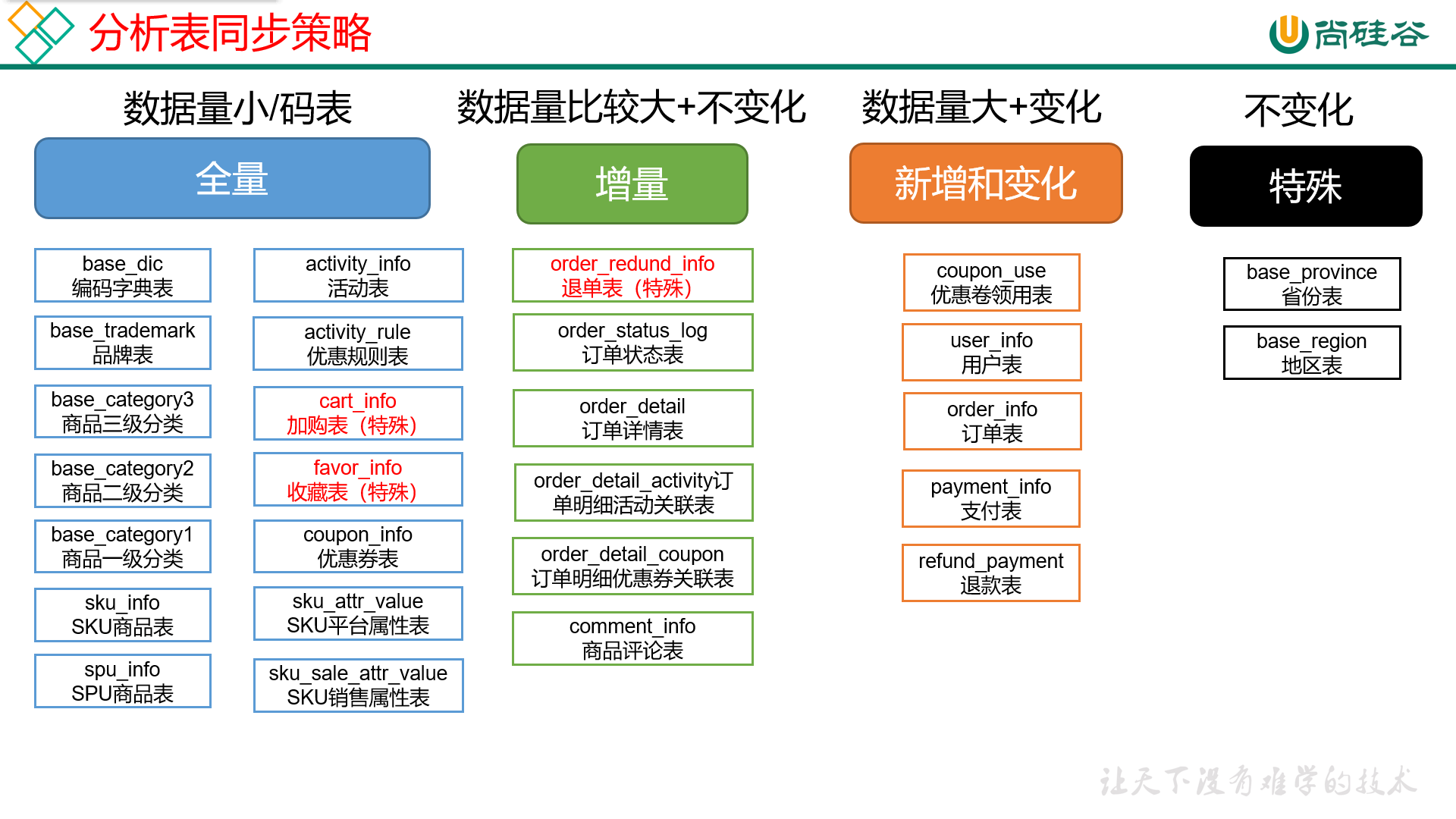
阅读全文
posted @ 2022-01-19 10:59 Zhbeii
阅读(20)
评论(0)
推荐(0)
上一页
1
2
3
4
5
6
7
8
9
···
21
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号