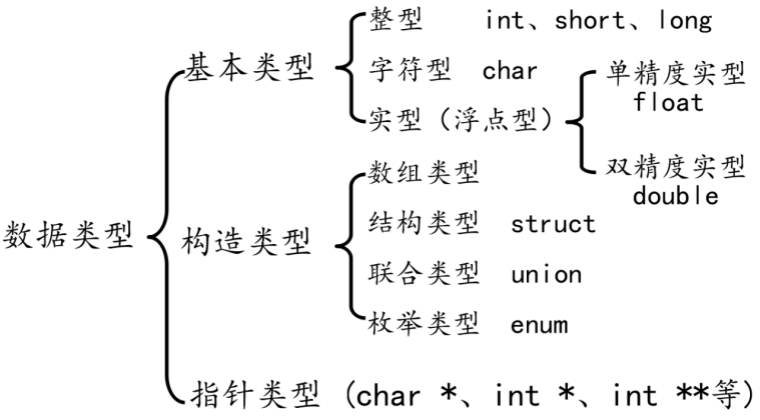
C++基础
1. c++概述
1.1 C++的特点
-
-
C++语言的数据结构多样
-
C++语言的控制语句形式多样
-
C++语言是一种面向对象的程序设计语言
-
C++语言与硬件结合紧密
-
C++语言具有很强的移植性
在C语言基础上新增的内容:
- 作用域运算符:两个冒号( :: )
- 成员选择运算符:一个点( . )
- 指针成员选择符:一个箭头( -> )
- 用new来分配内存
- 用delete来释放分配的内存
- <<:既表示左移运算符也表示插入运算符
-
整形常量
整形常量可以分为有符号整形常量和无符号整形常量。
-225代表一个负数。
+1024代表一个正整数,正整数前面的"+"符号可以省略
+1024和1024表示的意义相同。
由于基本的数据类型里除了整型外,还有长整型和短整型,所以整型常量也有长整型常量和短整型常量。长整型常用不是可以无限大的,它的最大值是有限定的,根据CPU寄存器位数的不同以及编译器的不同,最大的整型常量值也会不同。
整形常量在编写代码时不仅可以写成十进制整数形式,也可以写成十六进制或八进制
1)八进制形式整型常量必须以0开头,即以0作为八进制数的前缀。每位取值范围0~7。并且八进制数通常是无符号数。
以下各数是合法的八进制数:016、0101、0127.
以下各数不是合法的八进制数:
256无前缀0,代表十进制整型常量。
0396中数字9不是八进制应用的取值。
2)十六进制整型常量的前缀为0X或0x。其数码取值为0~9,A~F或a~f。
以下各数是合法的十六进制整常数:0X2A1、0XC5、0XFFFF。
以下各数不是合法的十六进制整常数:
5A 无前缀0X
0X3N中含有非十六进制数N
-
实型常量
实型常量也称为浮点数,只能采用十进制形式表示。它有两种表示形式:即小数表示法和指数表示法。
1)小数表示法
使用这种表示法,实型常量由整数部分和小数部分组成,整数部分和小数部分每位取值范围是0~9,中间用小数点分隔。例如:0.0、3.25、0.00596、5.0、536、-5.3、-0.002等均为合法的实型常量。
整数部分和小数部分有时可以不必同时出现。例如:.2、2.。
2)指数表示法
指数表示法也儿科学记数法,指数部分以符号"e"或"E"开始,但必须是整数,并且符号"e"或"E"两边都必须有一位数。例如:1.2e20、-3.4e-2。
以下不是合法的实型常量:
E5是E之前无数字。
3E3.5是E后面有小数。
-
字符常量
字符常量是用单引号括起来的一个字符。例如'a'和'?'都是合法字符常量。在对代码编译时,编译器会根据ASCII码表将字符常量转换成整形常量。字符'a'的ASCII码值是97,字符'A'的ASCII码值是41,字符'?'的ASCII码值是63。ASCII码表中还有很多通过键盘无法输入的字符,可以使用'\ddd'或'\xhh'来引用这些字符。可是使用'\ddd'或'\xhh'来引用所有ASCII码表中的字符。ddd是1~3位八进制数所代表的字符;'\xhh'是1~2位十六进制数所代表的字符。例如'\101'表示ASCII码'A','\XOA'表示换行等。
-
转义字符


#include <iostream> void main() { std:cout << "A" << std:endl; std:cout << "\101" << std:endl; std:cout << "\x41" << std:endl; std:cout << "\052,\x1E" << std:endl; }
| 转义字符 | 意义 | ASCII代码 |
|---|---|---|
| \0 | 空字符 | 0 |
| \n | 换行 | 10 |
| \t | 水平制表 | 9 |
| \b | 退格 | 8 |
| \r | 回车 | 13 |
| \f | 换页 | 12 |
| \\ | 反斜杠 | 93 |
| \' | 单引号字符 | 39 |
| \" | 双引号字符 | 34 |
-
字符串常量
字符串常量由一对双引号括起来的零个或是多个字符序列。例如 "welcome to out school" 、 "hello girl" 。""可以表示一个空字符串。
字符串常量实际是一个字符数组,可以将字符串分解成或干个字符,字符的数量是字符串的长度。字符串常量一般都是用来给字符数组变量赋值或是直接做为实参传递,为告知编译器字符串已经结束,一般在给字符数组赋初值时都在字符串的末尾加上字符'\0',表示字符结束,如果不加字符结束标志,有可能会出现意想不到的错误
字符常量'A'与字符串常量"A"是不同的,字符串常量"A"是由'A'和'\0'两个字符组成的,字符串的长度是2,字符常量'A'只是一个字符,没有长度。
-
其他常量
-
- 布尔(bool)常量:布尔常量只有两个,一个是true,表示真;一个是false,表示假。
- 枚举型常量:枚举型数据中定义的成员也都是常量,以后的章节还会讲到枚举这个类型。
- 宏定义常量:通过 #define 宏定义的一些值也是常量。
如下示例,其中PI就是常量。
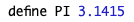
1.标识符
- 由字母、数字及下划线组成,且不能以数字开头
- 大写和小写字母代表不同意义
- 不能与关键字同名
- 尽量"见名知义",应该受一定规范的约束
2.变量
变量是指程序在运行时,其值可以改变的量。每个变量都由一个变量名标识,每个变量又具有一个特定的数据类型。
声明变量的形式如下:
[修饰符] 类型 变量名标识符
3.整型变量
整型变量可以分为短整型,整型和长整型,变量类型说明符分别是short、int、long。根据是否有符号还可分为以下六种
- 整型 [signed] int
- 无符号整型 unsigned int
- 有符号短整型 [signed] short [int]
- 无符号短整型 unsinged short [int]
- 有符号长整型 [signed] long [int]
- 无符号长整型 unsigned long [int]
4. 实型变量
实型变量又称为浮点型变量,变量可分为单精度(float)、双精度(double)和长双精度(long double) 三种。
- 单精度
- 双精度
- 长双精度
5.变量赋值
变量值是动态改变的,每次改变都需要进行赋值运算。变量赋值的形式如下:
变量名标识符 = 表达式
例如: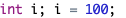
6.字符变量
字符变量的类型说明符为char,一个字符变量占用1字节内存单元
例如

1.4 数据类型
| 类型 | 位 | 范围 |
|---|---|---|
| char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 |
| signed char | 1 个字节 | -128 到 127 |
| int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 |
| signed int | 4 个字节 | -2147483648 到 2147483647 |
| short int | 2 个字节 | -32768 到 32767 |
| unsigned short int | 2 个字节 | 0 到 65,535 |
| signed short int | 2 个字节 | -32768 到 32767 |
| long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| signed long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| unsigned long int | 8 个字节 | 0 to 18,446,744,073,709,551,615 |
| float | 4 个字节 | +/- 3.4e +/- 38 (~7 个数字) |
| double | 8 个字节 | +/- 1.7e +/- 308 (~15 个数字) |
| long double | 16 个字节 | +/- 1.7e +/- 308 (~15 个数字) |
| wchar_t | 2 或 4 个字节 | 1 个宽字符 |
1.5 类型转换
1)隐式转换
隐式转换发生在不同数据类型的量混合运算时,由编译系统自动完成。
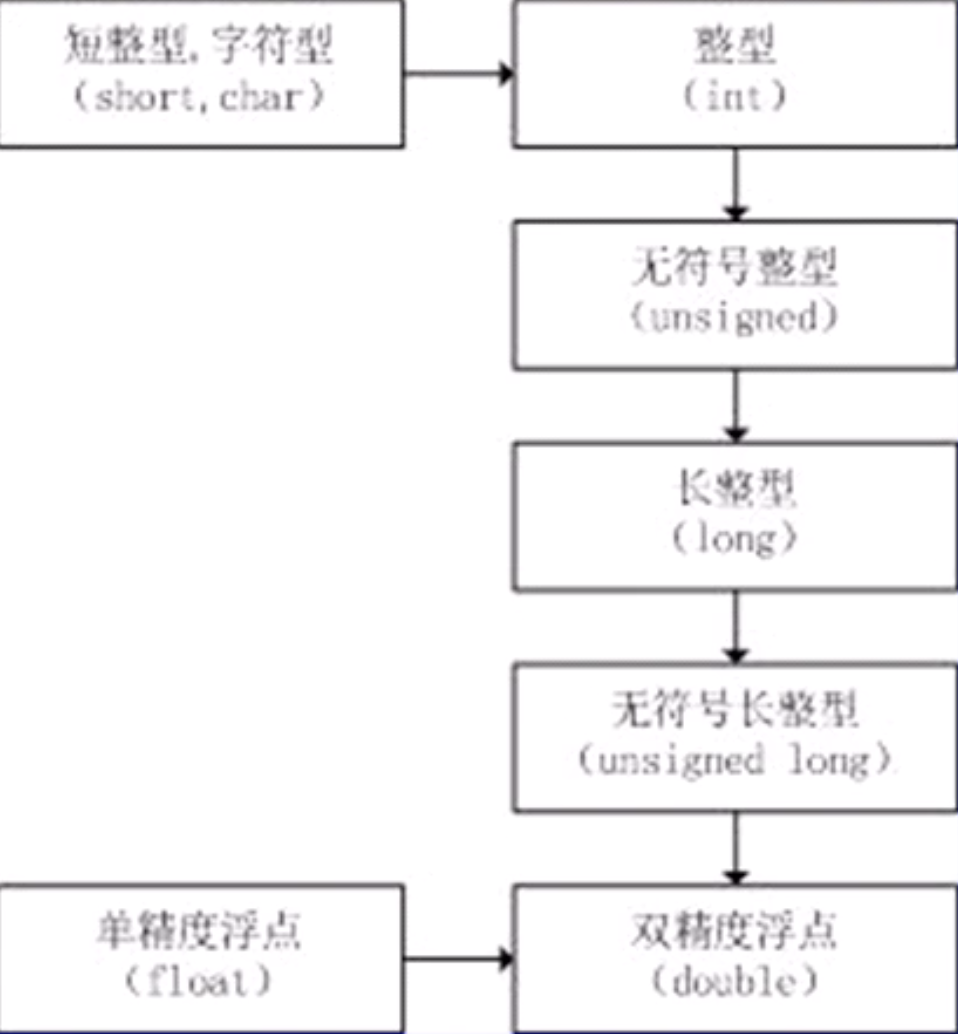
隐式转换遵循以下规则:
- 若参与运算量的类型不同,则先转换成同一类型,然后进行运算。赋值时会反赋值类型和被赋值类型转换成同一类型,一般赋值号右边量的类型将转换成左边量的类型。如果右边量的数据类型长度比左边长时,将丢失一部分数据,这样会降低精度,丢失的部分按四舍五入向前舍入。
- 转换按数据由低到高顺序执行,以保证精度不降低。
int型和long型运算时,先把int型转成long型后再进行运算。
所有的浮点运算都是以双精度进行的,即使仅含float单精度量运算的表达式,也要先转换成double型,再作运算。
char型和short型参与运算时,必须先转换成int型
#include <iostream> using namespace std; void main() { double result; char a = 'k'; int b = 10; float e = 1.515; result = (a+b)-e; printf("%f\n",result); //115.485000 }
2)强制类型转换
强制类型转换是通过类型转换运算来实现。其一般形式为:
类型说明符(表达式) 或 (类型说明符)表达式
#include <iostream> using namespace std; void main() { float i,j; int k; i = 60.25; j = 20.5; k = (int)i + (int)j; cout << k << endl; //80 }
1.6 数据的输入与输出
在用户与计算机进行交互的过程中,数据输入和数据输出是必不可少的操作过程,计算机需要通过输入来获取用户的输入的操作指令,并通过输出来显示操作结果。
1. C++语言中的流
在C++语言中,数据的输入和输出包括标准输入输出设置(键盘、显示器),外部存储介质(磁盘)上的文件和内存的存储空间三个方面的输入/输出。对标准输入设备和标准输出设备的输入/输出简称为标准的I/O,对在外存磁盘上文件的输入/输出简称文件I/O,对内存中指定的字符串存储空间的输入/输出简称为串I/O。
C++中把数据之间的传输操作称为流。在C++中流既可以表示数据从内存传送到某个载体或设备中,即输出流;也可以表示数据从某个载体或设备传送到内存缓冲区变量中,即输入流。C++中所有流都是相同的,但文件可以不同。使用流以后,程序用流统一对各种计算机设备和文件进行操作,使程序与设备、程序与文件无关,从而提高了程序设计的通用性和灵活性。
C++定义了I/O类库供用户使用,标准I/O操作有4个类对象,它们分别是cin,cout,cerr和clog。其中cin为代表标准输入设备键盘,也称为cin流或标准输入流。cout代表标准输出显示器,也称为cout流或标准输出流,当进行键盘输入操作时使用cin流,当进行显示器输出操作时使用cout流,当进行错误信息输出操作时使用cerr或clog。
C++的流通过重载运算符“<<” 和 “>>” 执行输入和输出操作。输出操作是向流中插入一个字符序列,因此,在流操作中,将左移运算符“<<” 称为插入运算符。输入操作是从流中提取一个字符序列,因此,将右移运算符“>>” 称为提取运算符。
(1)cout语句的一般格式
cout << 表达式1 << 表达式2 << ... << 表达式n;
cout代表着显示器,执行 cout << x 操作就相当于把x的值输出到显示器。
先把x的值输出到显示器屏幕上,在当前屏幕光标位置显示出来,然后cout流恢复到等待输出的状态,以便继续通过插入操作符输出下一个值。当使用插入操作符向一个流输出一个值后,再输出下一个值时将被紧接着放在上一个值的后面,所以为了让流中前后两个值分开,可以在输出一个值后接着输出一个空格,或一个换行符,或是其他所需要的字符或字符串。
一个cout语句可以分写成若干行。例如: cout << "Hello World!" << endl;
可以写成

也可以写成多个 cout 语句。

实例 输出简单字符
#include <iostream.h> void main() { int i = 0; cout << i << endl; cout << "Hello world" << endl; }
(2)cin语句的一般格式
cin >> 变量1 >> 变量2 >> ...... >> 变量n;
cin 代表键盘,执行 cin >> x 就相当于把键盘输入的数据赋值给变量。
当从键盘上输入数据时,只有当输入完数据并按下回车键后,系统才把该行数据存入到键盘缓冲区,供cin流顺序读取给变量。另外,从键盘上输入的每个数据之间必须用空格或回车符分开,因为cin为一个变量诗入数据时是以空格或回车符作为其结束标志的。
当 cin >> x 操作中的x为字符指针类型时,则要求从键盘的输入中读取一个字符串,并把它赋值给x所指向的存储空间,若x没有事先指向一个允许写入信息的存储空间,则无法完成输入操作。另外从键盘上输入的客符串,其两边不能带有双引号定界符,若有则只作为双引号字符看待。对于输入的字符也是如此,不能带有单引号定界符。
实例 在屏幕上输出用户的输入
#include <iostream.h> void main() { int iInput; cout << "please input a number;" << endl; cin >> iInput; cout << "the number is :" << iInput << endl; }
2. 流操作的控制
在头文件 iomanip.h 中定义了一些控制流输出格式的函数,默认情况下整型数按十进制形式输出,可以通过 hex 将其设置为十六进制输出。流操作的控制具体函数如下:
(1)long setf(long f);
根据参数f设置相应的格式标志,返回此前的设置。该参数f所对应的实参为无名枚举类型中的枚举常量(又称格式化常量),可以同时使用一个或多个常量,每两个常量之间要用按位或操作符连接。如需要在左对齐输出,并使数值中的字母大写时,则调用该函数的实参为ios::left|ios::uppercase。
#include <iostream.h> #include <iomanip.h> void main() { cout << setw(10) << "abc" << endl; // abc a前面有9个空格 cout.setf(ios::left); cout << setw(10) << "abc" << endl; // abc setw是设置所需内容的宽度 cout << hex << 10 << endl; // A cout.setf(ios::uppercase); cout << hex << 10 << endl; // a }
(2)long unsetf(long f);
根据参数 f 清除相应的格式化标志,返回此前的设置。如果要清除此前的左对齐输出设置,恢复默认的右对齐输出设置,则调用该函数的实参为 ios::left。
(3)int width();
返回当前的输出宽度。若返回数值为0则表明没为刚才输出的数据设置输出域宽。输出域宽是指输出的值在流中所占有的字节数。
(4)int width(int w);
设置下一个数据值的输出域宽为w,返回为输出上一个数据值所规定的域宽,若无规定则返回0。注意,此设置不是一直有效,而只是对下一个输出数据有效。
(5)setiosflags(long f);
设置 f 所对应的格式标志,功能为 setf(long f) 成员函数相同,当然输出该操作符后返回的是一个输出流。如果采用标准输出流 cout 输出它时,则返回 cout。对于输出每个操作符后也都是如此,即返回输出它的流,以便向流中继续插入下一个数据。
(6)resetiosflags(long f);
清除 f 所对应的格式化标志,功能与 unsetf(long f) 成员函数相同。输出后返回一个流。
(7)setfill(int c);
设置填充字符为 ASCII 码为 c 的字符。例: cout << setfill('?') << setw(4) << "abc" << endl; // ?abc
(8)setprecision(int n);
设置浮点数的输出精度为n。例: cout << setprecision(3) << 3.14159 << endl; // 3.14
(9)setw(int w);
设置下一个数据的输出域宽为w。
C++除了使用函数来控制流输出以外,还提供了简单的控制字符。这些字符结合输出运算符 "<<" 可以更加方便的对输出格式进行控制。
- dec:转换为按十进制输出整数,是默认的输出格式。
- oct:转换为按八进制输出整数。
- hex:转换为按十六进制输出整数。
- ws:从输出流中读取空白字符。
- endl:输出换行符 \n 并刷新流。刷新流是指把流缓冲区的内容立即写入到对应的物理设备上。
- ends:输出一个空字符 \0。
- flush:只刷新一个输出流。
3. prinf
prinf("[控制格式]…[控制格式]…",数值列表);
控制格式的形式如下: %[*][域宽][长度]类型
-
D 以十进制形式输出带符号整数(正数不输出符号)
-
O 以八进制形式输出无符号整数(不输出前缀O)
-
X 以十六进制形式输出无符号整数(不输出前缀OX)
-
U 以十进制形式输出无符号整数
-
C 输出单个字符
-
S 输出字符串
-
f 以小数形式输出单、双精度实数
-
E 以指数形式输出单、双精度实数
-
G 以%f%e中较短的输出宽度输出单、双精度实数
2. 运算符与表达式
2.1 运算符
算术运算符
算术运算是主要指常用的加(+)、减(-)、乘(*)、除(/)四则运算,算术运算符中既有单目运算符还有双目运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 30 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -10 |
| * | 把两个操作数相乘 | A * B 将得到 200 |
| / | 分子除以分母 | B / A 将得到 2 |
| % | 取模运算符,整除后的余数 | B % A 将得到 0 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 11 |
| -- | 自减运算符,整数值减少 1 | A-- 将得到 9 |
#include <iostream> using namespace std; int main() { int a = 21; int b = 10; int c; c = a + b; cout << "Line 1 - c 的值是 " << c << endl ; c = a - b; cout << "Line 2 - c 的值是 " << c << endl ; c = a * b; cout << "Line 3 - c 的值是 " << c << endl ; c = a / b; cout << "Line 4 - c 的值是 " << c << endl ; c = a % b; cout << "Line 5 - c 的值是 " << c << endl ; int d = 10; // 测试自增、自减 c = d++; cout << "Line 6 - c 的值是 " << c << endl ; d = 10; // 重新赋值 c = d--; cout << "Line 7 - c 的值是 " << c << endl ; return 0; } /* Line 1 - c 的值是 31 Line 2 - c 的值是 11 Line 3 - c 的值是 210 Line 4 - c 的值是 2 Line 5 - c 的值是 1 Line 6 - c 的值是 10 Line 7 - c 的值是 10 */
关系运算符
关系运算主要是对两个对象进行比较,运算结果是逻辑常量真或假。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (A == B) 不为真。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (A > B) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 | (A >= B) 不为真。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 | (A <= B) 为真。 |
#include <iostream> using namespace std; int main() { int a = 21; int b = 10; int c ; if( a == b ) { cout << "Line 1 - a 等于 b" << endl ; } else { cout << "Line 1 - a 不等于 b" << endl ; } if ( a < b ) { cout << "Line 2 - a 小于 b" << endl ; } else { cout << "Line 2 - a 不小于 b" << endl ; } if ( a > b ) { cout << "Line 3 - a 大于 b" << endl ; } else { cout << "Line 3 - a 不大于 b" << endl ; } /* 改变 a 和 b 的值 */ a = 5; b = 20; if ( a <= b ) { cout << "Line 4 - a 小于或等于 b" << endl ; } if ( b >= a ) { cout << "Line 5 - b 大于或等于 a" << endl ; } return 0; } /* Line 1 - a 不等于 b Line 2 - a 不小于 b Line 3 - a 大于 b Line 4 - a 小于或等于 b Line 5 - b 大于或等于 a */
逻辑运算符
逻辑运算符是对真和假这两种逻辑值进行运算,运算后的结果仍是一个逻辑值。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
#include <iostream> using namespace std; int main() { int a = 5; int b = 20; int c ; if ( a && b ) { cout << "Line 1 - 条件为真"<< endl ; } if ( a || b ) { cout << "Line 2 - 条件为真"<< endl ; } /* 改变 a 和 b 的值 */ a = 0; b = 10; if ( a && b ) // a = 0, 此判断永远为假 { cout << "Line 3 - 条件为真"<< endl ; } else { cout << "Line 4 - 条件不为真"<< endl ; } if ( !(a && b) ) { cout << "Line 5 - 条件为真"<< endl ; } return 0; }
赋值运算符
赋值运算符分为简单赋值运算符和复合赋值运算符,复合赋值运算符又称为带有运算的赋值运算符。简单赋值运算符就是直接给变量赋值的运算符。例如:
变量 = 表达式
等号 = 就为简单赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 | C = A + B 将把 A + B 的值赋给 C |
| += | 加且赋值运算符,把右边操作数加上左边操作数的结果赋值给左边操作数 | C += A 相当于 C = C + A |
| -= | 减且赋值运算符,把左边操作数减去右边操作数的结果赋值给左边操作数 | C -= A 相当于 C = C - A |
| *= | 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋值给左边操作数 | C *= A 相当于 C = C * A |
| /= | 除且赋值运算符,把左边操作数除以右边操作数的结果赋值给左边操作数 | C /= A 相当于 C = C / A |
| %= | 求模且赋值运算符,求两个操作数的模赋值给左边操作数 | C %= A 相当于 C = C % A |
| <<= | 左移且赋值运算符 | C <<= 2 等同于 C = C << 2 |
| >>= | 右移且赋值运算符 | C >>= 2 等同于 C = C >> 2 |
| &= | 按位与且赋值运算符 | C &= 2 等同于 C = C & 2 |
| ^= | 按位异或且赋值运算符 | C ^= 2 等同于 C = C ^ 2 |
| |= | 按位或且赋值运算符 | C |= 2 等同于 C = C | 2 |
#include <iostream> using namespace std; int main() { int a = 21; int c ; c = a; cout << "Line 1 - = 运算符实例,c 的值 = : " <<c<< endl ; c += a; cout << "Line 2 - += 运算符实例,c 的值 = : " <<c<< endl ; c -= a; cout << "Line 3 - -= 运算符实例,c 的值 = : " <<c<< endl ; c *= a; cout << "Line 4 - *= 运算符实例,c 的值 = : " <<c<< endl ; c /= a; cout << "Line 5 - /= 运算符实例,c 的值 = : " <<c<< endl ; c = 200; c %= a; cout << "Line 6 - %= 运算符实例,c 的值 = : " <<c<< endl ; c <<= 2; cout << "Line 7 - <<= 运算符实例,c 的值 = : " <<c<< endl ; c >>= 2; cout << "Line 8 - >>= 运算符实例,c 的值 = : " <<c<< endl ; c &= 2; cout << "Line 9 - &= 运算符实例,c 的值 = : " <<c<< endl ; c ^= 2; cout << "Line 10 - ^= 运算符实例,c 的值 = : " <<c<< endl ; c |= 2; cout << "Line 11 - |= 运算符实例,c 的值 = : " <<c<< endl ; return 0; } /* * Line 1 - = 运算符实例,c 的值 = : 21 Line 2 - += 运算符实例,c 的值 = : 42 Line 3 - -= 运算符实例,c 的值 = : 21 Line 4 - *= 运算符实例,c 的值 = : 441 Line 5 - /= 运算符实例,c 的值 = : 21 Line 6 - %= 运算符实例,c 的值 = : 11 Line 7 - <<= 运算符实例,c 的值 = : 44 Line 8 - >>= 运算符实例,c 的值 = : 11 Line 9 - &= 运算符实例,c 的值 = : 2 Line 10 - ^= 运算符实例,c 的值 = : 0 Line 11 - |= 运算符实例,c 的值 = : 2 */
位运算符
位运算有位逻辑与、位逻辑或、位逻辑异或和取反运算符,其中位逻辑与位逻辑或、位逻辑异或为双目运算符。取反运算符为单目运算符。
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
移位运算符
移位运算有两个,分别是左移 << 和右移 >> ,这两个运算符都是双目的
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 | (A & B) 将得到 12,即为 0000 1100 |
| | | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 | (A | B) 将得到 61,即为 0011 1101 |
| ^ | 如果存在于其中一个操作数中但不同时存在于两个操作数中,二进制异或运算符复制一位到结果中。 | (A ^ B) 将得到 49,即为 0011 0001 |
| ~ | 二进制补码运算符是一元运算符,具有"翻转"位效果,即0变成1,1变成0。 | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 | A >> 2 将得到 15,即为 0000 1111 |
#include <iostream> using namespace std; int main() { unsigned int a = 60; // 60 = 0011 1100 unsigned int b = 13; // 13 = 0000 1101 int c = 0; c = a & b; // 12 = 0000 1100 cout << "Line 1 - c 的值是 " << c << endl ; c = a | b; // 61 = 0011 1101 cout << "Line 2 - c 的值是 " << c << endl ; c = a ^ b; // 49 = 0011 0001 cout << "Line 3 - c 的值是 " << c << endl ; c = ~a; // -61 = 1100 0011 cout << "Line 4 - c 的值是 " << c << endl ; c = a << 2; // 240 = 1111 0000 cout << "Line 5 - c 的值是 " << c << endl ; c = a >> 2; // 15 = 0000 1111 cout << "Line 6 - c 的值是 " << c << endl ; return 0; } /* * Line 1 - c 的值是 12 Line 2 - c 的值是 61 Line 3 - c 的值是 49 Line 4 - c 的值是 -61 Line 5 - c 的值是 240 Line 6 - c 的值是 15 */
sizeof 运算符
是一个很像函数的运算符,也是唯一一个用到字母的运算符。该运算符有两种形式:
sizeof(类型说明符)
sizeof(表达式)
功能是返回指定的数据类型或表达式的值的数据类型在内存中占用的字节数。
条件运算符
条件运算符是C++仅有的一个三目运算符,该运算符需要3个运算数对象,形式如下
<表达式1>? <表达式2> : <表达式3>
表达式1是一个逻辑值,可以为真或假;若表达式1为真,则运算结果是表达式2,如果表达式1为伟 ,则运算结果是表达式3.这个运算相当于一个if语句。
逗号运算符
C++语言中逗号 “ , ”也是一种运算符,称为逗号运算符。其优先级别最低,结合方向自左至右。其功能是把两个表达式连接起来组成一个表达式,逗号运算符是一个多目运算符,并且操作数的个数不限定,可以将任意多个表达式组成一个表达式。例如。
x,y,z a = 1, b = 2
| 运算符 | 描述 |
|---|---|
| sizeof | sizeof 运算符返回变量的大小。例如,sizeof(a) 将返回 4,其中 a 是整数。 |
| Condition ? X : Y | 条件运算符。如果 Condition 为真 ? 则值为 X : 否则值为 Y。 |
| , | 逗号运算符会顺序执行一系列运算。整个逗号表达式的值是以逗号分隔的列表中的最后一个表达式的值。 |
| .(点)和 ->(箭头) | 成员运算符用于引用类、结构和共用体的成员。 |
| Cast | 强制转换运算符把一种数据类型转换为另一种数据类型。例如,int(2.2000) 将返回 2。 |
| & | 指针运算符 & 返回变量的地址。例如 &a; 将给出变量的实际地址。 |
| * | 指针运算符 * 指向一个变量。例如,*var; 将指向变量 var。 |
2.2 结合性和优先级
运算符优先级决定了在表达式中各个运算符执行的先后顺序。高优先级运算符要先于低优先级运算符进行运算。例如根据先乘除后加减的原则,表达式“a+b*c”会先计算 b*c ,得到结果在与 a 相加。在优先级相同的情况下,则按从左到右的顺序进行计算。
运算符的结合方式有两种,左结合和右结合。
- 左结合表过运算符优先与其左边的标识符结合进行运算。例如加减法运算 +,-
- 右结合表示运算符优先与其右边的标识符结合进行去处。例如赋值运算 =。
同一优先级的优先级别相同,运算次序由结合方向决定。例如 1*2/3,*和/的优先级别相同,其结合方向自左向右,则等价于(1*2)/3。
下面的表格是按优先级从高到低排列
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ - - | 从左到右 |
| 一元 | + - ! ~ ++ - - (type)* & sizeof | 从右到左 |
| 乘除 | * / % | 从左到右 |
| 加减 | + - | 从左到右 |
| 移位 | << >> | 从左到右 |
| 关系 | < <= > >= | 从左到右 |
| 相等 | == != | 从左到右 |
| 位与 AND | & | 从左到右 |
| 位异或 XOR | ^ | 从左到右 |
| 位或 OR | | | 从左到右 |
| 逻辑与 AND | && | 从左到右 |
| 逻辑或 OR | || | 从左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号 | , | 从左到右 |
2.3 表达式
表达式由运算符、括号、数值对象或变量等几个元素构成,一个数值对象是最简单的表达式;一个表达式可以看作一个数学函数,带有运算符的表达式通过计算将返回一个数值。
算术表达式
算术表达式的一般形式是: 表达式 算术运算符 表达式
算术表达式由算术运算符把表达式连接而成,其值的计算很简单,其值的数据类型按下述规定确定:若所有的运算符数量类型相同,则表达式运算结果的数据类型和操作数的数据类型相同;若操作数的数据类型不同,就需要转换,表达式运算结果的数据类型取最高的数据类型。
关系表达式
关系表达式的一般形式是:表达式 关系运算符 表达式
关系表达式一般只出现在三目运算符、if语句和循环语句的判断条件中。关系表达式的运算结果都是逻辑型,只能取true或false。数值0表示false,非0代表true。
条件表达式
条件表达式的一般形式是:关系表达式 ? 表达式 :表达式
条件表达式的值和数据类型取决于 ?号前表达式的真假,若为真,则整个表达式的运算结果和数据类型和冒号前的操作数相同;若为假,则整个表达式的值和数据类型和冒号后的操作数相同
赋值表达式
赋值表达式的一般形式是:表达式 赋值运算符 表达式
赋值运算符的值和数据类型的第一个操作数对象值完毕后的值和数据类型相同。
由于赋值运算符的结合性是从右至左,因此可以出现连接赋值的表达式。
逻辑表达式
逻辑表达式的一般形式是:表达式 逻辑运算符 表达式
逻辑表达式是用逻辑运算符将关系表达式连接起来。逻辑表达式的值也是逻辑型,只能取真值true或假值 False。
其中的表达式可以又是逻辑表达式,从而组成了嵌套的形。例如: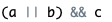
根据逻辑运算符的左结合性,上式也可写为:a || b && c 逻辑表达式的值是式中各种逻辑运算的最后值,以1 和 0 分别代表 “真” 和 “假”
逻辑表达式注意事项:
(1)逻辑运算符两侧的操作数,除可以是0和非0的整数外,也可以是其它任何类型的数据,如实型、字符型等。
(2)在计算逻辑表达式时,只有在必须执行下一个表达式才能求解时,才求解该表达式也就是说并不是所有的表达式都被求解。
逗号表达式
逗号表达式一般形式为:表达式1,表达式2
其求值过程是先求解表达式1,再求解表达式2,并以表达式2的值作为整个逗号表达式的值。
逗号表达式的注意事项:
1. 逗号表达式可嵌套。
表达式1,(表达式2,表达式3)
嵌套的逗号表达式可以转换成扩展形式,扩展形式如下。
表达式1,表达式2,... 表达式n
整个逗号表达式的值等于表达式n的值。
2. 程序中使用逗号表达式,通常是要分别求逗号表达式内各表达式的值,并不一定要求整个逗号表达式的值。
3. 并不是在所有出现逗号的地方都组成逗号表达式,如在变量说明中,函数参数表中逗号只是用作各变量之间的间隔符。
2.4 语句
在C++程序中,语句是最小的可执行单元,一条语句由一个分号结束。
C++程序语句按其功能可以划分为两类,一类是用于描述计算机执行操作运算的,称为操作运算语句; 另一类是用于控制操作运算执行顺序的,称为流程控制语句。任何程序设计语句都具备流程控制的功能。基本的控制结构有3种:顺序结构、选择结构、循环结构。
顺序结构指按照语句在程序中的先后次序一条一条顺序执行。顺序结构是自然形成的,不需要控制,按默认的顺序执行,顺序控制语句就是一条简单的语句。
1. 表达式语句
表达式语句是由表达式后面加上一个分号组成。表达式有很多种,关系表达式、逻辑表达式、算术表达式,但关系表达式、逻辑表达式多用于循环或选择结构中,只有赋值表达式多用于赋值语句。赋值语句是赋值表达式后面加上一个分号可以形式赋值语句,将右边的表达式(算术表达式)的结果赋值给左边的变量。一个赋值语句中可以包含多个赋值表达式。
2. 空语句
空语句只有一个分号,表示什么也不做。空语句经常出现在选择或循环语句中,表示某个分支或循环体不执行具体的操作。也用于编制程序的初始阶段,在搭建程序的模块框架中,先用空语句占位,接下来在逐步细化和补充。例如: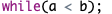
上面是一个循环语句,表示当变量a小于变量b时,在花括号中的循环体中要进行什么操作,但不确定循环体应该实现什么功能,所以需要使用空语句占位,空语句语法上是正确的。
3. 复合语句
复合语句是若干条语句的一个集合,它在语法上是一个整体,相当于一个语句。语法形式上是由一对花括号将若干条语句括起来。复合语句经常出现在选择或循环结构中,选择语句的分支和循环语句的循环体由多条语句组成的,用花括号括起来形式一条的复合语句,起到层次划分的作用。一个花括号形成了一个范围,这个范围也是变量的作用范围,也可以将花括号内的代码称之为程序段。在能使用简单语句的地方,都能够使用复合语句。在一个复合语句中可以包含另外一个或多个复合语句。

一个复合语句的大括号外面不能再写分号。
4. 函数调用语句
函数是由函数名、带实际参数表的圆括号组成,函数调用语句就是在函数后加上一个分号。调用主要指,程序执行到函数调用语句时,程序会跳转到相应的函数体中去执行,执行该函数体中的内容,执行完所有内容后返回到函数调用语句处,执行调用语句下面的语句。可以调用的函数主要有用系统库函数和自定义函数。
3. 条件控制
3.1 判断语句
3.2 决策分支
3.3 使用条件运算符进行判断
3.4 switch语句
3.5 while语句
3.6 for循环语句
3.7 循环控制
3.8 循环嵌套
3.9 循环应用实例
#
循环是程序开发常用结构,在程序开发过程中会大量使用循环语句。
阿姆斯壮数
在三位的整数中,形如 153=13+53+33 这样的数称为阿姆斯壮数。求阿姆斯壮数需要分别计算三位整数的百位、十位和个位,然后对三个数分别求立方,最后进行判断是否为阿姆斯壮数
#include <iostream> using namespace std; int main() { int a, b, c; int input; for (input = 100; input <= 999; input++) { a = input / 100; // 求百位 b = (input % 100) / 10; // 求十位 c = input % 10; //求个位 if (a * a * a + b * b * b + c * c * c == input) { cout << input << endl; } } return 0; } /* 153 370 371 407 */
巴斯卡三角形
巴斯卡三角形是两个边全输出1,三角形的内部用上行相邻两个数之和,各相加后的和数等分的放在三角形的各行内。

#include <iostream> #include <iomanip> using namespace std; long combi(int n, int r) { int i; long p = 1; for (i = 1; i <= r; i++) { p = p * (n - i + 1) / i; } return p; } int main() { int n, r, t; for (n = 0; n <= 12; n++) { // 控制行数 for (r = 0; r <= n; r++) { int i; if (r == 0) { for (i = 0; i <= (12 - n); i++) { cout << " "; } } else cout << " "; cout << setw(3) << combi(n, r); } cout << endl; } return 0; }
对输入的分数进行排名
通过输入不同的分数,然后计算不同分数之间的排名
#include <iostream> using namespace std; int main() { int score[101] = {0}; int juni[102] = {0}; int count = 0; do { cout << "input score: "; cin >> score[count++]; } while (score[count - 1] != -1); count--; for (int i = 0; i < count; i++) { juni[score[i]]++; } juni[101] = 1; for (int j = 100; j >= 0; j--) { juni[j] = juni[j] + juni[j + 1]; } cout << "Result:" << endl; for (int k = 0; k < count; k++) { cout << score[k] << " is "; cout << juni[score[k] + 1] << endl; } return 0; }
4. 函数
4.1 函数概述
函数就是能够实现特定功能的程序模块,函数可以是只有一条语句的简单函数,也可以是包含许多子函数的复杂函数。函数有别人写好的存放在库里的库函数,也有开发人员自己写的自定义函数。函数根据功能可以分为字符函数、日期函数、数学函数、图形函数、内存函数等。一个程序可以只有一个主函数,但不可以没有函数。
函数定义的一般形式如下。
类型标识符 函数名(形式参数列表)
{
变量的声明
语句
}
类型标识符:用来标识函数的返回值类型,可以根据函数的返回值判断函数的执行情况,通过返回值也可以获取想要的数据。类型标识符可以是整形、字符型、指针型、对象的数据类型。
形式参数列表:由各种类型变量组成的列表,各参数之间用逗号间隔,在进行函数调用时,主调函数对变量进行赋值。
函数的声明
调用一个函数前必须先声明函数的返回值类型和参数类型。例如:
函数声明被称为函数原型,函数声明时可以省略变量名。例如:
4.2 函数参数及返回值
返回值
函数的返回值是指函数被调用之后,执行函数体中的程序段所取得的并返回给主调函数的值,函数的返回值通过 return 语句返回给主调函数。return 语句一般形式如下。
return(表达式);
语句将表达式的值返回给主调函数。
空函数
没有参数和返回值,也没有函数的作用域为空的函数就是空函数。
void setWorkSpace(){}
调用此函数,什么工作也不做,没有任何实际意义。
形参与实参
函数定义时如果参数列表为空,说明函数是无参函数;
如果参数列表不为空,就称为带参数函数,带参数函数中的参数如果在函数声明和定义时被称为“形式参数”简称形参,在函数被调用时被赋予具体值,具体的值被称为“实际参数”简称实参

默认参数
在调用有参函数时,如果经常需要传递同一个值到调用函数,在定义函数时,可以为参数设置一个默认值,这样,在调用函数时,可以省略一些参数,此时程序将采用默认值作为函数的实际参数。下面的代码定义了一个具有默认值参数的函数。

可变参数
省略号参数代表的含义是函数的参数是不固定的,可以传递一个或多个参数。对于printf函数来说,可以输出一项信息,也可以同时输出多项信息。
声明可变参数的函数和声明普通函数一样,只是参数列表中有一个“...”省略号。
例如:
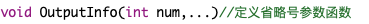
对于可变参数的函数,在定义函数时需要一一读取用户传递的实际参数。可以使用va_list类型和va_start、va_arg、va_end 3个宏读取传递到函数中的参数值。使用可变参数需要 引用STDARG.H头文件。
#include <iostream> #include <STDARG.H> //需要包含该头文件 using namespace std; void OutputInfo(int num,...) { va_list arguments; va_start(arguments,num); while(num--) { char* pchData = va_arg(arguments,char*); int iData = va_arg(arguments,int); cout << iData << endl; } va_end(arguments); } void main() { OutputInfo(2,"Beijing",2008,"Olympic Games",2008); //调用OutputInfo函数 }
4.3 函数调用
声明完函数后就需要在源代码中调用该函数。整个函数的调用过程被称为函数调用。
- 传值调用
- 嵌套调用
- 递归调用
传值调用
主调函数和被调用函数之间有数据传递关系,换句话说,主调函数将实参数值复制给被用函数的形参处,这种调用方式称为传值调用,如果传递的实参是结构体对象,值传递方式的效率是低下的,可以通过传指针或使用变量的引用来替换传值调用。传值调用是函数调用的基本方式。
#include <iostream> void swap(int a, int b) { int tmp; tmp = a; a = b; b = tmp; } void main() { int x,y; cout << "输入两个数" << endl; cin >> x; cin >> y; if( x < y) swap(x,y); cout << "x=" << x << endl; cout << "y=" << y << endl; }
嵌套调用
在自定义函数中调用其他自定义函数,这种调用方式称为嵌套调用。
#include <iostream> using namespace std; void ShowMessage() { cout << "The ShowMessage function" << endl; } void Display() { ShowMessage(); } void main() { Display(); }
递归调用
直接或间接调用自己的函数被称为递归函数。
#include <iostream> using namespace std; long Fac(int n) { if(n == 0) return 1; else return n * Fac(n-1); } void main() { int n; long f; cout << "please input a number" << endl; cin >> n; f = Fac(n); cout << "Result:" << f << endl; }
实例 递归实现汉诺塔
有3个立柱垂直树立在地面,给这3个立柱分别命名为“A”、“B”、“C”。开始的时候立柱A上有64个圆盘,这64个圆盘在大小不一,并且按从小到大的顺序依次摆放在立柱A上。如果要将c也移动到C上,就要暂时将c移动到B,然后再移动a和b。移动顺序是c->B,a->A,b->B,a->B,d->C。
最后是完成4个圆盘的移动,移动顺序是a->C,b->A,a->A,a->C,a->B,b->C,a->C。
#include <iostream> using namespace std; long lCount; void move(int n,char x, char y, char z)//将n个盘子从x针借助y针移动到z针上。 { if(n == 1) cout << "Times:" << ++lCount << x << "->" << z << endl; else { move(n - 1, x, y, z ); cout << "Times:" << ++lCount << x << "->" << z << endl; move(n - 1, y, x, z ); } } void main() { int n; lCount = 0; cout << "please input a number" << endl; cin >> n; move(n, 'a','b','c'); }
4.4 重载函数
定义同名的变量,程序会编译出错,如果定义同名的函数也带来冲突的问题,但C++中使用了名字重组的技术,通过函数的参数类型来识别函数。所谓重载函数就是指多个函数具有桢的函数标识名,而参数类型或参数个数不同。函数调用时,编译器以参数的类型及个数来区分调用哪个函数。
#include <iostream> int add(int a, int b) { return a + b; } int add(int a, int b,int c) { return a + b + c; } double add(double a, double b) { return a + b; } void main() { cout << add(1,2) << endl; //调用 Int add(a,b) cout << add(1,2,3) << endl; //调用 Int add(a,b,c) cout << add(1.5,2.5) << endl; //调用 double add(a,b) return ; }
4.5 变量作用域
根据变量的声明的位置可以将变量分为局部变量及全局变量:
在函数体内即花括号{}内定义的变量称之为局部变量。
在函数体外即花括号{}外定义的变量称之为全局变量。
4.6 变量的存储类别
存储类别是变量的属性之一,C++语言中定义了4种变量的存储类别,分别是auto变量、static变量、register变量、extern变量。
auto存储变量
变量的默认存储方式,使用关键字auto。例如:
static 变量
在声明变量前加关键字static,可以将变量声明成静态变量。静态存储变量通常是在变量定义时就分配固定的存储单元,并一直保持不变,直至整个程序结束,静态全局变量只能在本源文件中使用。
例如:

register 变量
通常变量的值是存放在内存中,当对一个变量频繁读写时,则需要反复访问内存储器,从而花费大量的存取时间。为了提高效率,C++语言可以将变量声明为寄存器变量。这种变量将局部变量的值存放在CPU中的寄存器中,使用时,不需要访问内存,而直接从寄存器中读写。寄存器变量的说明符是register。
对寄存器变量的说明:
- 寄存器变量属于动态存储方式。凡需要采用静态存储方式的量不能定义为寄存器变量。
- 编译程序会自动决定那个变量使用寄存器存储,register起到程序优化的作用。
extern变量
在一个源文件中定义 的变量和函数只能被本文件中的函数调用,当一个C++程序中有多个源文件时,使用extern关键字来引用其它源文件中全局变量。
4.7 命名空间
使用命名空间
在一个应用程序的多个文件中可能会存在同名的全局对象,这样会导致应用程序的链接错误。使用命名空间是消除命名冲突的最佳方式。
定义命名空间
命名空间的定义格式为:
namespace 名称 { 常量、变量、函数等对象的定义 }
定义命名空间要使用关键字 namespace ,例如:
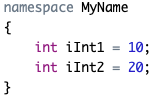
引用空间成员的一般形式是:
命名空间名称::成员
例如引用MyName命名空间中的成员:
MyName::iInt1 = 30;
在多个文件中定义命名空间
在定义命名空间时,通常在头文件中声明命名空间中的函数,在源文件中定义命名空间中的函数。将程序的声明与实现分开。例如,在头文件中声明命名空间函数。

在源文件中定义函数

在源文件中定义函数时,注意要使用命名空间名作为前缀,表明实现的是命名空间中定义的函数。否则将是定义一个全局函数。
#include <iostream> namespace myname { int myint = 10; }; //方式一 void main() { int myint = 30; cout << myname::myint << endl; // 10 cout << myint << endl; // 30 } // 方式二 using namespace myname; void main() { cout << myint << endl; // 10 }
定义嵌套的命名空间
命名空间可以定义在其他的命名空间中。在这种情况下,仅仅通过使用外部的命名空间作为前缀,程序便可以引用在命名空间之外定义的其他标识符。然而,在命名空间内不定的标识符需要作为外部命名空间和内部命名空间名称的前缀出现。
定义未命名的命名空间
尽管为命名空间指定名称是有益的,但是C++中也允许在定义中省略命名空间的名称来简单的定义未命名的命名空间。
例如定义一个包含两个整形变量的未命名的命名空间。
namespace { int iValue1 = 10; int iValue2 = 20; }
事实上在无命名空间中定义的标识符被设置为全局命名空间,不过这样就违背了命名空间的设置原则。所以,未命名的命名空间没有被广泛应用。
5. 指针
5.1 指针
专门用来存放另一个变量地址的变量,就是指针变量。在C++语言中将存放内存单元地址的数据类型,称为指针类型。
指针变量和变量的指针,指针也是一种数据类型,通常所说的指针就是指针变量,它是一个专门用来存放地址的变量;而变量的指针主要指变量在内存中的地址,变量的址在编写代码时无法获取,只有在程序运行期间才可以得到。

指针指向的就是房间号,它要把房间内的内容取出来,需要取值符号*
- 指针的声明
声明指针的一般形式如下:
数据类型标识符 *指针变量名
例如
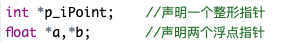
- 指针的赋值
指针可以在声明的时候赋值,也可以后期赋值。
在初始化时赋值:

在后期赋值:

关于指针使用的说明
- 指针变量名是p,而不是*p。
- 指针变量不可以直接赋值。
- 如果强行赋值,使用指针运算符*提取指针所指变量时会出错。
- 不能将*p当变量使用。
#include <iostreaam> using namespace std; void main() { int *p; int i = 100; p = &i; printf("%d\n",p); // 获取的是地址值 130923 printf("%d\n",*p); // 获取的是值 100 // 强行给指针赋值,会出错。 int *a; *a = 100; printf("%d\n",a); }
指针运算符和取地址运算符
* 和 & 是两个运算符
*是指针运算符,&是取值运算符。
*p取得的是指针的值,&p取得的是指针的地址
&*p和*&a的区别
& 和 * 的运算符优先级别相同,按自右而左的方向结合。因此&*p先进行*运算,*p相当于变量a;再进行&运算,&*p就相当于取变量a的地址。
*&a 先计算& 运算符,&a就是取变量a的地址,然后计算*运算,*&a就相当于取变量a所在地址的值,实际就是变量a。
指针运算
指针变量存储的是地址值,对指针做运算就等于对地址做运算。
5.2 指向函数的指针
指针变量也可以指向一个函数。一个函数在编译时被分配给一个入口地址。这个函数入口地址就称为函数的指针。可以用一个指针变量指向函数,然后通过该指针变量调用此函数。
一个函数可以带回一个整形值、字符值、实型值等,也可以带回指针型的数据,即地址。其概念与以前类似,只是带回的值的类型是指针类型而已。返回指针值的函数简称为指针函数。
定义指针函数的一般形式为:
类型名 *函数名(参数列表);
例如定义一个具有两个参数和一个返回值的函数的指针。
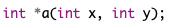
#include <iostream> #include <iomanip> using namespace std; int avg(int a, int b); void main() { int width,length,result; width = 10; length = 30; int (*pFun)(int,int); //定义函数指针 pFun = avg; // 把函数赋值给指针 result = (*pFun)(width,length); // 直接调用指针函数 cout << result << endl; } int avg(int a, int b) { return (a * b) / 2; }
5.3 引用
引用
引用实际上是一种隐匿指针,它为对象建立一个别名,引用通过操作符&来实现。&是取地址操作符,通过它可以获得地址。
引用的形式如下:
数据类型 & 表达式;
例如:

定义了一个引用变量ia,它是变量a的别名,对ia的操作与对a的操作完全一样。ia=2把2赋给a,&ia返回a的地址。执行ia=2和执行a=2等价。
#include <iostream> using namespace std; void main() { int a; int & ref_a = a; a = 100; cout << "a=" << a << endl; // 100 cout << "ref_a" << ref_a << endl; // 100 a = 2; cout << "a=" << a << endl; // 2 cout << "ref_a" << ref_a << endl; // 2 int b = 20; ref_a = b; cout << "a=" << a << endl; // 20 cout << "ref_a" << ref_a << endl; // 20 ref_a--; cout << "a=" << a << endl; // 19 cout << "ref_a" << ref_a << endl; // 19 }
使用引用的说明:
- 一个C++引用被初始化后,无法使用它再去引用另一个对象,它不能被重新约束。
- 引用变量只是其他对象的别名,对它的操作与原来对象的操作具有相同作用。
- 指针变量与引用有两点主要区别:一是指针是一种数据类型,而引用不是一个数据类型。指针可以转换为它指向变量的数据类型,以便赋值运算符两边的类型相匹配;而在使用引用时,系统要求引用和变量的数据类型必须相同,不能进行数据类型转换。二是指针变量和引用变量都用来指向其他变量,但指针变量使用的语法要复杂一些;而在定义了引用变量后,其使用方法与普通变量相同。
使用引用传递参数
在C++语言中,函数参数的传递方式主要有两种,分别为值传递和引用传递。所谓值传递,是指将在函数调用时,将实际参数的值赋值一份传递到调用函数中。这样,如果在调用函数中修改了参数的值,其改变不会影响到实际参数的值。而引用传递则恰恰相反,如果函数按引用方式传递,在调用函数中修改了参数的值,其改变会影响到实际参数。
#include <iostream> using namespace std; // 交换,引用传递参数 void swap(int & a, int & b) { int tmp; tmp = a; a = b; b = tmp; } void main() { int x,y; cout << "input two number " << endl; cin >> x; cin >> y; // 如果x < y,两个值交换 if (x < y) swap(x, y); //3,6 cout << "x=" << x << endl; //6 cout << "y=" << y << endl; //3 }
#include <iostream> using namespace std; // 交换 void swap(int *a, int *b) { int tmp; tmp = *a; *a = *b; *b = tmp; } void main() { int x,y; int *p_x,*p_y; cout << "input two number " << endl; cin >> x; cin >> y; p_x = &x;p_y = &y; // 如果x < y,两个值交换 if (x < y) swap(p_x, p_y); //3,6 cout << "x=" << x << endl; //6 cout << "y=" << y << endl; //3 }
使用引用 传递参数比较简单,使用指针传递参数比较灵活
指针传递参数
指针变量可以作为函数参数。使用指针变量传递参数和使用引用传递方式的执行效果相同。
通过指针传递参数和使用引用方式传递参数一样,都可以减少传递带来的开销。在开发程序时是使用指针还是使用引用类型作为函数参数呢?实际上,使用指针和引用类型作为函数参数各有优缺点,视具体环境而定。对于引用类型,引用必须被初始化为一个对象,并且不能使它再指向其他对象,因为对应用赋值实际上是对目标对象赋值。这是引用类型的缺点,但也是引用类型的优点,因为在函数中不用验证引用参数的合法性。
数组做函数参数
在函数调用过程中,有时需要传递多个参数,如果传递的参数都是同一类型则可以通过数组的方式来传递参数,作为参数的数组可以是一维数组,也可以是多维数组。
#include <iostream> using namespace std; void main(int argc,char *argv[]) { cout << "the list of parameter:" << endl; while(argc > 1) { ++argv; cout << *argv << endl; --argc; } } //在控制台执行 项目名/a /b /c,会把/a,/b,/c分别输出出来
6. 数组
6.1 一维数组
一维数组的声明
在程序设计中,将同一数组类型的数组按一定形式有序的组织起来,这些有序数据的集合就称为数组。一个数组有一个统一的数组名,可以通过数组名和下标来唯一确定数组中的元素。
一维数组的声明形式如下:
数据类型 数据名[常量表达式]
例如

使用数组的说明:
(1)数组名的定名规则和变量名相同。
(2)数组名后面的括号是方括号,方括号内是常量表达式。
(3)常量表达式表示元素的个数,即数组的长度。
(4)定义数组的常量表达式不能是变量,因为数组的大小不能动态定义。
一维数组的引用
数组引用的一般形式如下
数组名[下标]
例如
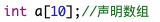
a[0]、a[1]、a[2]、a[3]、a[4]、a[5]、a[6]、a[7]、a[8]、a[9]是对数组a中的十个元素的引用。
一维数组引用的说明
(1)数组元素的下标起始值为0而不是1。
(2)a[10]是不存在的数组元素,引用a[10]非法。
#include <iostream> using namespace std; void main() { int a[10]; for(int i = 0;i < 10;i++) a[i] = i; for(i = 0;i < 10;i++) { cout << a[i] << endl; } }
一维数组的初始化
数组元素初始化的方式有两种,一种是对单个元素逐一的赋值,另一种是使用聚合方式赋值。
(1)单一数组元素赋值
a[0] = 0 就是对单一数组元素赋值,也可以通过变量控制下标的方式进行赋值。
(2)聚合方法赋值
数组不仅可以是一个数组元素一个数组元素的赋值,还可以通过大括号进行多个元素的赋值。
例如

或
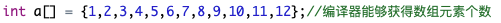
或

6.2 二维数组
二维数组的声明
二维数据声明的一般形式为:
数据类型 数组名[常量表达式1] [常量表达式2]
例如

一个一维数组描述的是一个线性序列,二维数组则描述的是一个矩阵。常量表达式1代表行的数量,常量表达式2代表列的数量。
二维数组可以看作是一种特殊的一维数组,如图所示,虚线左侧为三个一维数组的首元素,二维数组是由a[0],a[1],a[2]这三个一维数组组成。每个一维数组都包含4个元素。
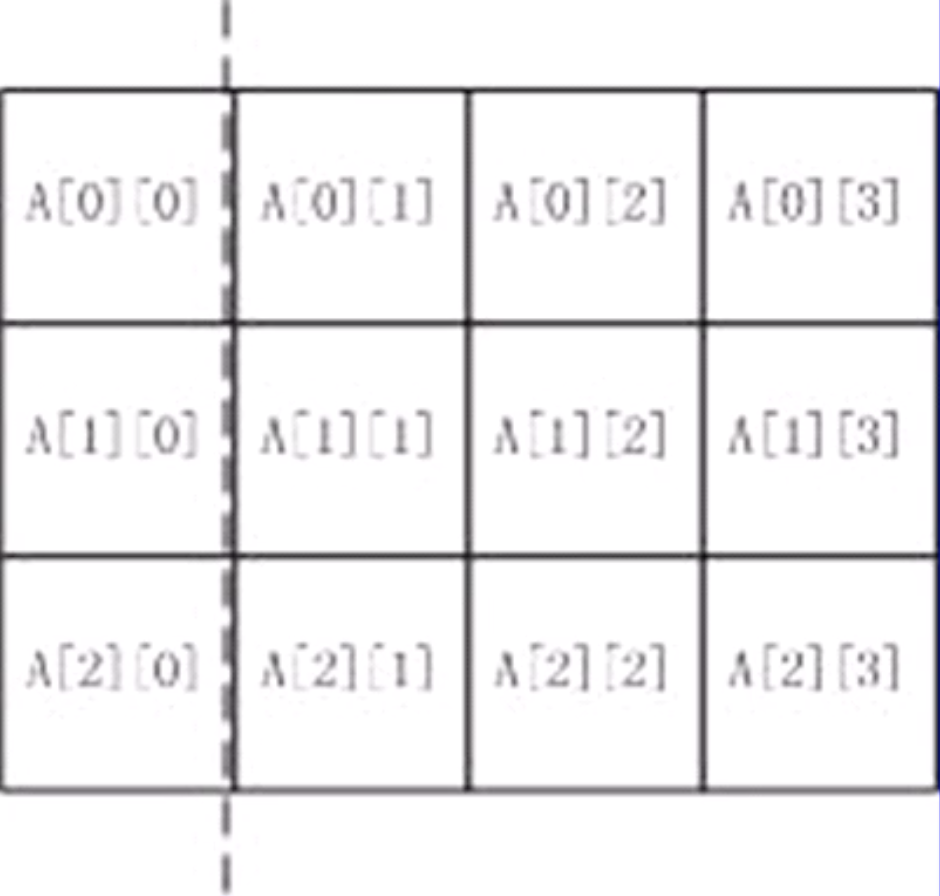
使用数组的说明
(1)数组名的定名规则和变量名相同。
(2)二维数组有两个下标,所以要有两个中括号。

(3)下标运算符中的整数表达式代表数组每一个维的长度,它们必须是正整数。它们的乘权确定了整个数组的长度。例如
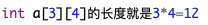
(4)定义数组的常量表达式不能是变量,因为数组的大小不能动态定义。
二维数组元素的引用
二维数组的元素的引用形式为
数组名[下标][下标]
二维数组元素引用和一维数组基本相同。例如

二维数组的初始化
二维数组元素初始化的方式和一维数组的相同,也分为单个元素逐一的赋值和使用聚合方式赋值。
例如:
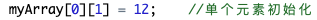
使用聚合方式给数组赋值等同于分别对数组中的每个元素赋值。
例如
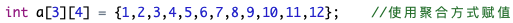
等同于执行如下语句:

二维数组中元素排列的顺序是按行存放,即在内存中先顺序存放第一行的元素,再存放第二行的元素。
例如 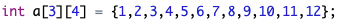
的赋值顺序是
先给第一行元素赋值: a[0][0] -> a[0][1] -> a[0][2] -> a[0][3]
再给第二行元素赋值: a[1][0] -> a[1][1] -> a[1][2] -> a[1][3]
最后给第三行元素赋值: a[2][0] -> a[2][1] -> a[2][2] -> a[2][3]
数组元素的位置以及对应数值
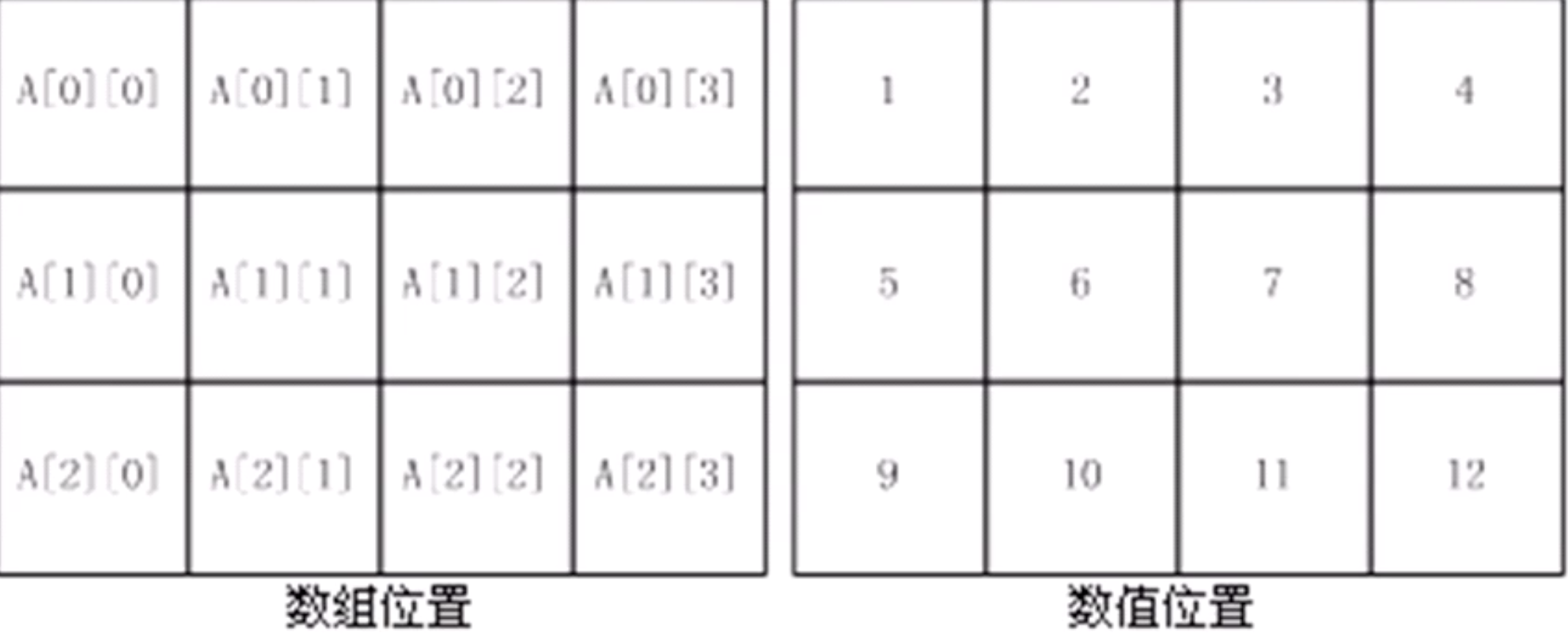
使用聚合方式赋值,还可以按行进行赋值。例如 
二维数组可以只对前几个元素赋值。例如 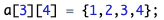
数组元素是左值,可以出现在表达式中,也可以对数组元素进行计算。例如 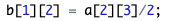
#include <iostream> using namespace std; void main() { int a[3][4]; for(int i = 0;i < 3;i++) for(int j = 0;j < 4;j++) a[i][j] = i + j; cout << (sizeof(a) / sizeof(int)) << endl; // 12 int *p; p = a[0]; for(int m = 0;m < 3;m++) for(int n = 0;n < 4;n++) cout << a[m][n] << endl; // 0 1 2 3 // 1 2 3 4 // 2 3 4 5 for(int k = 0;k < sizeof(a) / sizeof(int);k++) { cout << *p++ << endl; // 0 1 2 3 // 1 2 3 4 // 2 3 4 5 } }
6.3 字符数组
字符数组
用来存放字符数据的数组是字符数组,字符数组中的一个元素存放一个字符。字符数组具有数组的共同属性。由于字符串应用广泛,C和C++专门为它提供了许多方便的用法和函数。
(1)声明一个字符数组

(2)字符数组赋值方式
数组元素逐一赋值:

使用聚合方式赋值:
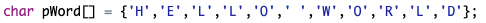
如果花括号中提供的初值个数大于数组长度,则按语法错误处理。如果初值个数小于数组长度,则只将这些字符赋给数组中前面的那些元素,其余的元素自动定义为空字符。
如果提供的初值个数与预定的数组长度相同,在定义时可以省略数组长度,系统会自动根据初值个数确定数组长度。
(3)字符数组的一些说明
聚合方式只能在数组声明的时候使用。
例如
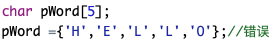
字符数组不能给字符数组赋值。

(4)字符串和字符串结束标志
字符数组作字符串使用,作为字符串要有字符串结束符'\0'。
可以使用字符串字符数组赋值。例如

语句等同与

字符串结束符'\0' 主要用告知字符串处理函数字符串已经结束了,不需要再输出了。
(5)字符串处理函数
- strcat函数
字符串连接函数strcat格式如下:
strcat(字符数组名1, 字符数组名2)
把字符数组2中的字符串连接到字符数组1中字符串的后面,并删去字符串1后的串结束标志“\0”。
#include <iostream> #include <string.h> using namespace std; void main() { char a[20] = {'a','b'}; //空间要够大 char b[] = "Hello"; strcat(a,b); //把b拼接到a后面 cout << a << endl; //abHello }
2. strcpy函数
字符串拷贝函数 strcpy 格式:
strcpy(字符数组名1, 字符数组名2)
把字符数组2中的字符串拷贝到字符串数组1中。串结束标志“\0”也一同拷贝。
#include <iostream> #include <string.h> using namespace std; void main() { char a[20] = {'a','b'}; //空间要够大 char b[] = "Hello"; strcpy(a,b); //把b拼接到a后面 cout << a << endl; //Hello }
3. strcmp函数
字符串比较函数 strcmp 格式如下:
strcmp(字符数组名1, 字符数组名2)
按照ASCII码顺序比较两个数组中的字符串,并由函数返回值返回比较结果。
字符串1 = 字符串2,返回值为0。
字符串1 > 字符串2,返回值为一正数。
字符串1 < 字符串2,返回值为一负数。
#include <iostream> #include <string.h> using namespace std; void main() { char a[] = "Hello"; char b[] = "Hello"; int i = strcmp(a,b); cout << i << endl; //0 char a2[] = "Helloworld"; char b2[] = "Hello"; int i2 = strcmp(a2,b2); cout << i2 << endl; //1 char a3[] = "Hell"; char b3[] = "Hello"; int i3 = strcmp(a3,b3); cout << i3 << endl; //-1 }
6.4 指针与数组
- 指针与一维数组
- 指针与二维数组
- 指针与字符数组
数组的存储
数组,作为同名、同类型元素的有序集合,被顺序存放在一块连接的内存中,而且每个元素存储空间的大小相同。数组第一元素的存储地址就是整个数组的存储首地址,该地址放在数组名中。
对于一维数组而言,其结构是线性的,所以数组元素按下标值由小到大的顺序依次存放在一块连接的内存中。在内存中存储一维数组。
对于二维数组而言,用矩阵方式存储元素,在内存中仍然是线性结构
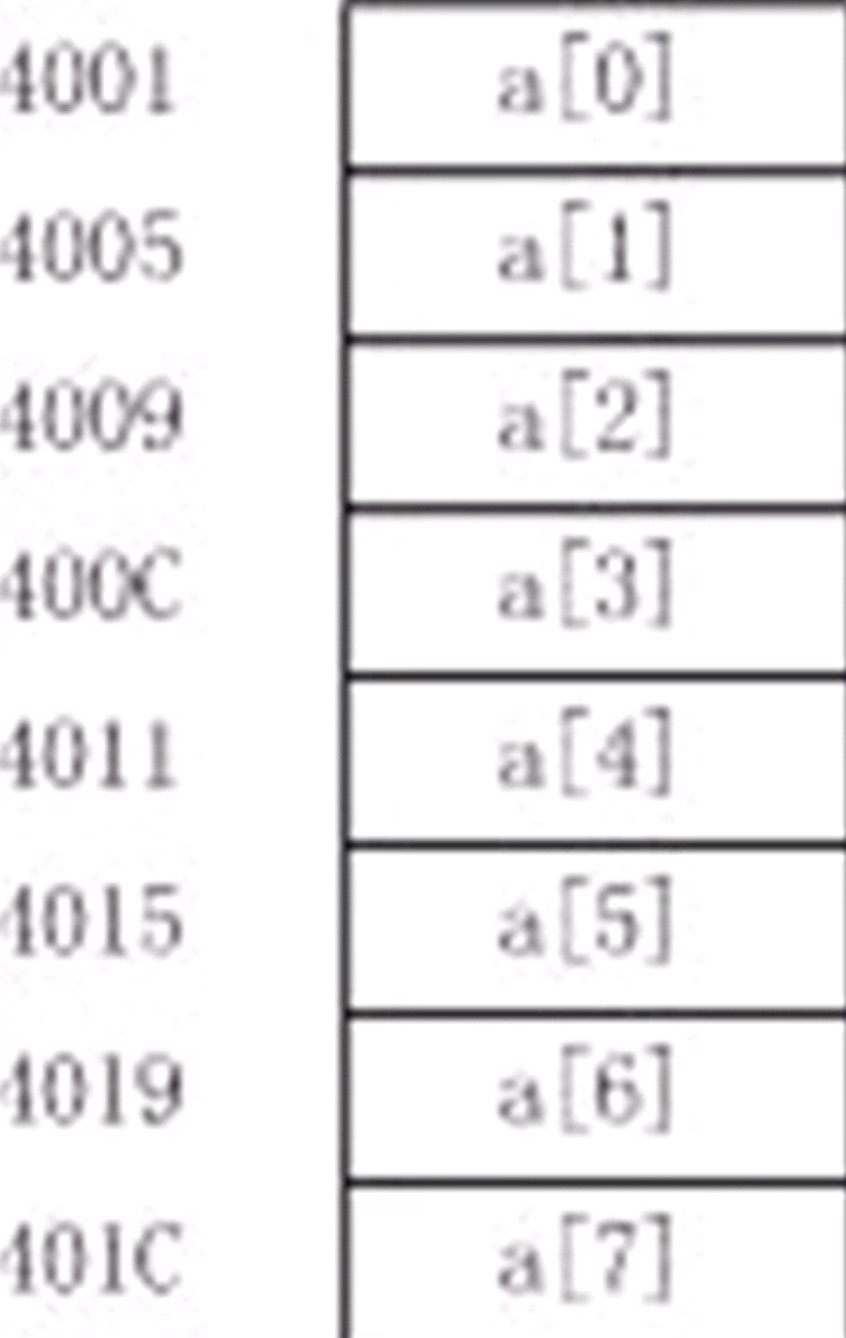
指针与一维数组
系统需要提供一定量连接的内存来存储数组中的各元素,内存都有地址,指针变量就是存放地址的变量,如果把数组的地址赋给指针变量,就可以通过指针变量来引用数组。到此引用数组元素有两种方法:下标法和指针法。
通过指针引用数组,就要先声明一个数组,再声明一个指针。

然后通过 & 运算符获取数组中元素的地址,然后将地址值赋给指针变量。
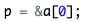
把a[0]元素的地址赋给指针变量p。也就是说,p指向a数组的第0号元素。
#include <iostream> using namespace std; void main() { int i,a[10]; int *p; for(int i = 0;i < 10;i++) a[i] = i; p = &a[0]; //p = a for(int i =0;i < 10,i++,p++) cout << *p << endl; // 0-9 //cout << *(a+i) <, endl; }
指针操作数组的一些说明。
*(p--)相当于a[i--],先对p进行*运算,再使p自减
*(++p)相当于a[++i],先使p自加,再作*运算。
*(--p)相当于a[--i],先使p自减,再作*运算。
指针与二维数组
可以将一维数组的地址赋给指针变量,同样也可以将二维数组的地址赋给指针变量,因为一维数组的内存地址是连续的,二维数组的内存地址也是连接的,可以将二维数组看成是一个一维数组。二维数组各元素的地址

a代表二维数组的地址,通过指针运算符也可以获取数组中的元素。
(1)a+n表示第n行的首地址。
(2)&a[0][0]既可以看作数组0行0列的首地址,同样还可以看作是二维数组的首地址。&a[m][n]就是第m行n列元素的地址。
(3)&a[0]是第0行的首地址,当然&a[n]就是第n行的首地址。
(4)a[0]+n,表示第0行第n个元素地址。
(5)*(*(a+n)+m)表示第n行第m列元素。
(6)*(a[n]+m)表示第n行第m列元素。
#include <iostream> using namespace std; void main() { int i,j; int a[4][3] = {{1,2,3},{4,5,6},{7,8,9},{10,11,12}}; cout << "the array is :" << endl; for(i = 0;i < 4;i++) //行 { for(j = 0;j < 3;j++) //列 cout << *(*(a+i)+j) << endl; } }
指针与字符数组
字符数组是一个一维数组,使用指针同样也可以引用字符数组,引用字符数组的指针为字符指针,字符指针就是指向字符内存空间的指针变量,其一般的定义语句如下:

字符数组就是一个字符串,通过字符指针可以指向一个字符串。
语句:

等价于下面两个语句:

#include <iostream> using namespace std; void main() { char str1[50],str2[30],*p1,*p2; p1 = str1; p2 = str2; cout << "please input string1:" << endl; //hello gets(str1); cout << "please input string2:" << endl; //world gets(str2); while(*p1 != '\0') p1++ while(*p2 != '\0') *p1++ = *p2++; *p1 = '\0'; cout << "the new string is :" << endl; //helloworld puts(str1); }
6.5 指针数组
数组中的元素均为指针变量的数组称为指针数组,一维指针数组的定义形式为
类型名 *数组名[数组长度];
例如: int *p[4];
指针数组中的数组名也是一个指针变量,该指针变量为指向指针的指针。
例如

p是一个指针数组,它的每一个元素是一个指针型数据(其值为地址),指针数组p的第一个值是变量a的地址。
指针数组中的元素可以使用指向指针的指针来引用。
例如 int *(*p);
*运算符表示p是一个指针变量,*(*p)表示指向指针的指针,*运算符的结合性是从右到左,因此 int *(*p); 可写成 int **p;
利用指针变量访问另一个变量就是“间接访问”。如果在一个指针变量中存放一个目标变量的地址,这就是“单级间址”。指向指针的指针用的是“二级间址”方法。还有“三级间址”和四级间址,但二级间址应用最为普遍。
#include <iostream> using namespace std; //对字符串进行排序 void sort(char *name[],int n) { char *temp; int i ,j, k; for(i = 0;i < n - 1;i++) { k = i; for(j = i + 1;j < n ;j++) if(strcmp(name[k],name[j]) > 0) k = j; if(k != i) { temp = name[i]; name[i] = name[k]; name[k] = temp; } } } //输出字符串数组中的元素 void print(char *name[],int n) { int i = 0; char *p; p = name[0]; while(i < n) { p = *(name+i++); cout << p << endl; } } void main() { char *name[] = {"mingri","soft","c++","mr"}; //定义指针数组 int n = 4; sort(name,n); print(name,n); return 0; }
7. 面向对象
7.1 面向对象与面向过程编程
过程编程
过程编程的主要思想是先做什么后做什么,在一个过程中实现特定功能,一个大模块实现过程还可以分成各个模块,各个模块可以按功能进行划分,然后组合在一起实现特定功能。在过程编程中,程序模块可以是一个函数,也可以是整个源文件。
过程编程主要以数据为中心,传统的面向过程的功能分解法属于结构化分析方法。分析者将对象系统的现实世界看做为一个大的处理系统,然后将其分解为若干个子处理过程,解决系统的总体控制问题。在分析过程中,用数据描述各子处理过程之间的联系,整个各个子处理过程的执行顺序。
面过程编程一般流程如下:
现实世界 -> 面向过程建模(流程图,变量,函数)-> 面向过程语言 -> 执行求解
过程编程其稳定性、可修改性和可重用性都比较差。
- 软件重用性差
- 软件可维护性差
- 开发出的软件不能满足用户的需求
面向对象
面向对象程序设计者的任务包括两个方面:一是设计所需的各种类和对象,即决定把哪些数据和操作封装在一起;二是考虑怎样向有关对象发送消息,以完成所需的任务。这时它如同一个总调度,不断地向各个对象发出消息,让这些对象活动起来(或者说激活这些对象),完成自己职责范围内的工作。
面向对象开发的程序可以描述成对象加消息。面向对象编程一般流程如下:
现实世界 -> 面向对象建模(类图,对象,方法)-> 面向对象语言 -> 执行求解
面向对象的特点
面向对象编程主要体现在代码容易修改、代码复用性高、满足用户需求三个特点。
- 代码容易修改
- 代码复用性高
- 满足用户需求
7.2 面向对象概述
面向对象(Object Oriented)的英文缩写是OO,它是一种设计思想,现在这种思想已经不简简单单的应用在软件设计上,数据库设计、计算机辅助设计(CAD)、网络结构设计、人工智能算法设计等领域都开始应用这种思想。
针对面向对象思想应用不同的领域面向对象又可以分为
- 面向对象分析(Object Oriented Analysis,OOA)
- 面向对象设计(Object Oriented Design,OOD)
- 面向对象编程(Object Oriented Programming,OOP)
- 面向对象测试(Object Oriented Test,OOT)
- 面向对象维护(Ojbect Oriented Soft Maintenance,OOSM)
面向对象有三大特点:
- 封装
- 继承
- 多态
7.3 C++类
面向对象中的对象需要通过定义类来声明,对象一词是一种形象的说法,在编写代码过程中则是通过定义一个类来实现。
类是一个新的数据类型,它和结构体有些相似,它也是由不同的数据类型组成的集合体,但类要比结构体增加了操作数据的行为,这个行为就是函数。
类的声明和定义
类的声明格式如下:
class 类名标识符 { [public:] [数据成员的声明] [成员函数的声明] [private:] [数据成员的声明] [成员函数的声明] [protected:] [数据成员的声明] [成员函数的声明] };
类的实现
第一种方法是将类的成员函数都定义在类体内
第二种方法,也可以将类体内的成员函数的实现放在类体外,但如果类成员定义在类体外,需要用到域运算符" :: ",放在类体内和类体外效果是等效的。
关于类的实现有两点说明:
1. 类的数据成员需要初始化,成员函数还要添加实现代码。类的数据成员是不可以在类的声明中初始化。
2. 空类是C++中最简单的类,其声明方式如下所示: class CPerson{};
空类和空函数的功能差不多,只是起到点位的作用,需要的时候再定义类成员及实现。
对象的声明
定义一个新类后,就可以通过类名来声明一个对象。声明的形式如下:
类名 对象名表
类名是定义好的新类的标识符,对象名表中是一个或多个对象的名称,如果声明的是多个对象就用逗号运算符分隔。
例如声明一个对象如下: CPerson p;
声明多个对象如下: CPerson p1,p2,p3;
类引用
声明完对象就是对象的引用了,对象的引用有两种方式,一种是成员引用方式,一种是指针方式。
(1)成员引用方式
成员变量引用的表示如下
对象名.成员名
这里“ . ”是一个运算符,该运算符的功能是表示对象的成员。
成员函数引用的表示如下
对象名. 成员名(参数表)
例如:

(2)对象指针方式
对象声明形式中的对象名表,除了是用逗号运算符分隔的多个对象名外,还可以是对象名数组,对象名指针,引用形式的对象名。
声明一个对象指针: CPerson *p;
但要想使用对象的成员,需要->运算符,它是表示成员的运算符,它与.运算符的意义相同,->用来表示对象指针所指的成员,对象指针就是指向对象的指针。
例如 CPerson *p; p->m_iIndex;
下面的对象数据成员的两种表示形式是等价的:
对象指针名->数据成员 与 (*对象指针名).数据成员
#include <iostream> using namespace std; class CPerson { public: int i; // 方式一 // 类体内实现 // void setValue(int a) // { // i = a; // } // void show() // { // cout << i << endl; // } // 方式二 //类体外实现 void setValue(int a); void show(); } void CPerson::setValue(int a) { i = a; } void CPerson::show() { cout << i << endl; } void main() { // 成员引用方式 CPerson p; p.setValue(2); cout << p.i << endl; // 2 p.show(); // 2 //对象指针方式 CPerson *p1; p1 = new CPerson(); p1->setValue(2); p1->show(); // 2 }
7.4 类成员
访问类成员
类的三大特点之一就是具有封装性,封装在类里面的数据可以设置成对外可见或不可见,通过关键字public、private、protected可以设置类中数据成员对外是否可见,也就是其他类是否可以访问该数据成员。
关键字public、private、protected说明类成员是共有的、私有的、还是保护的。这三个关键字将类划分为三个区域,在public区域的类成员可以在类作用域外被访问,而private区域和protected区域只能在类作用域内被访问。
- public属性的成员对外可见,对内可见。
- private属性的成员对外不可见,对内可见。
- protected属性的成员对外不可见,对内可见,且对派生类是可见的。
内联成员函数
在定义类的成员函数时,可以使用 inline 关键字将成员函数定义为内联成员函数。
静态类成员
静态类成员是在类成员定义前使用 static 关键字标识
对于静态数据成员,还需要注意以下几点:
- 静态数据成员可以是当前类的类型,而其他数据成员只能是当前类的指针或应用类型
- 在定义类成员时,对于静态数据成员,其类型可以是当前类的类型,而非静态数据成员则不可以,除非数据成员的类型为当前类的指针或引用类型。
- 静态数据成员可以作为成员函数的默认参数
- 类的静态成员函数只能访问类的静态数据成员,而不能访问普通的数据成员
隐藏的this指针
用户可以使用this指针访问数据成员
嵌套类
C++语言允许在一个类中定义另一个类,这被称之为嵌套类
对于内部的嵌套类来说,只允许其在外围的类域中使用,在其他类域或者作用域中是不可见的
因为既然定义了嵌套类,通常都不会允许在外界访问,这违背了使用嵌套类的原则。其次,在定义嵌套类时,如果将其定义为私有的或受保护的,即使使用外围类域作用限定符,外界也无法访问嵌套类。
局部类
类的定义可以放在头文件中,可以放在源文件中。还有一种情况,类的定义也可以放置在函数中,这样的类被称之为局部类。
7.5 构造函数
构造函数概述
在类的实例进入其作用域时,也就是建立一个对象,构造函数就会被调用,那么构造函数的作用是什么呢?当建立一个对象时,常常需要做某些初始化的工作,类如对数据成员进行赋值设置类的属性,而这些操作刚好放在构造函数中完成。
#include <iostream> using namespace std; class CPerson { public: // 构造函数 CPerson() { i = 0; } CPerson(int b) { i = b; } int i; void setValue(int a); void show(); } void CPerson::setValue(int a) { i = a; } void CPerson::show() { cout << i << endl; } void main() { CPerson p(4); p.show(); // 4 }
复制构造函数
如何用一个已经初始化的对象来新生成一个一模一样的对象,因为在开发程序时可能需要保存对象的副本,好在后面执行的过程中恢复对象的状态。答案是使用复制构造函数来实现,复制构造函数就是函数的参数是一个已经初始化的类对象。
#include <iostream> using namespace std; class CPerson { public: // 构造函数 CPerson() { i = 0; } //复制构造函数 CPerson(CPerson & b) { i = b.i; } int i; void setValue(int a); void show(); } void CPerson::setValue(int a) { i = a; } void CPerson::show() { cout << i << endl; } void main() { CPerson p(4); p.show(); // 4 Cperson p1(p); p1.show(); }
7.6 析构函数
构造函数和析构函数是类体定义中比较特殊的两个成员函数,因为它们两个都没有返回值,而且构造函数名标识符和类名标识符相同,析构函数名表示符就是在类名标识符前面加“ ~ ” 符号。
构造函数主要是用来在对象创建时,给对象中的一些数据成员赋值,主要目的就是来初始化对象。析构函数的功能是用来释放一个对象的,在对象删除前,用它来做一些清理工作,它与构造函数的功能正好相反。
析构函数注意事项:
- 一个类中只可能定义一个析构函数,析构函数不能重载。
- 构造函数和析构函数不能使用 return 语句返回值,不用加上关键字 void
何时调用构造函数和析构函数
- 自动变量的作用域是某个模块,当此模块被激活时,自动变量调用构造函数,当退出此模块时,会调用析构函数。
- 全局变量在进入main()函数之前会调用构造函数,在程序终止时会调用析构函数。
- 动态分配的对象当使用new时为对象分配内存时会调用构造函数;使用delete删除对象时会调用析构函数。
- 临时变量是为支持计算,由编译器自动产生的。临时变量的生存期的开始和结束会调用构造函数和析构函数。
8. 面向对象三大特性
8.1 继承
继承(inheritance)是面向对象的主要特征(此外还有封装和多态)之一,它使得一个类可以从现有类中派生,而不必重新定义一个新类。继承的实质就是用已有的数据类型创建新的数据类型,并保留已有数据类型的特点,以旧类为基础创建新类,新类包含了旧类的数据成员和成员函数,并且可以在新类中添加新的数据成员和成员函数。旧类被称为基类或父类,新类被称为派生类或子类。
类的继承
类继承的形式如下:
class 派生类名标识符: [继承方式] 基类名标识符 { [访问控制修饰符] [成员声明列表] };
继承方式有3种派生类型,分别为共有型(public)、保护型(protected)和私有型(private)。访问控制修饰符也是public、protected、private三种类型,成员声明列表中包含类的成员变量及成员函数,是派生类新增的成员。:是一个运算符,表示基类和派生类之间的继承关系。
继承后可访问性
继承方式有public、private、protected这三种,三种继承方式的说明如下:
- 共有型派生
共有型派生表示对于基类中的public数据成员和成员函数,在派生类中仍然是public,对于基类中的private数据成员和成员函数,在派生类中仍然是private。
- 私有型派生
私有型派生表示对于基类中的public、protected数据成员和成员函数,在派生类中可以访问。基类中private数据成员,派生类不可以访问。
- 保护型派生
保护型派生表示对于基类中的public、protected数据成员和成员函数,在派生类中均为protected。protected类型在派生类的定义时可以访问,用派生类声明的对象不可以访问,也就是说在类体外不可以访问。protected成员可以被基类的所有派生类使用。这一性质可以沿继承树无限向下传播。
#include <iostream> using namespace std; class CPerson { public: int i; CPerson() { i = 11; j = 12; k = 13; } private: int j; protected: int k; }; class CPeople : public CPerson { public: void show() { cout << i << endl; // cout << j << endl; // 私有变量不可以被访问 cout << k << endl; } }; int main() { CPeople p; p.show(); cout << p.i << endl; }
构造函数访问顺序
由于父类和子类中都有构造函数和析构函数,那么子类对象在创建时是父类先进行构造,还是子类先进行构造,同样在子类对象释放时,是父类先进行释放,还是子类先进行释放,这里有个先后顺序问题。。答案是当从父类派生一个子类并声明一个子类的对象时,它将先调用父类的构造函数,然后调用当前类的构造函数来创建对象;在释放子类对象时,先调用的是当前类的析构函数,然后是父类的析构函数。
#include <iostream> using namespace std; class CPerson { public: int i; CPerson() { cout << "CPerson" << endl; } ~CPerson() { cout << "~CPerson" << endl; } }; class CPeople : private CPerson { public: CPeople() { cout << "CPeople" << endl; } ~CPeople() { cout << "~CPeople" << endl; } }; int main() { CPeople p; } /* 输出结果 CPerson CPeople ~CPeople ~CPerson * */
子类隐藏父类的成员函数
当子类中定义了一个和父类一样的成员函数时,会调用子类中的成员函数。
#include <iostream> using namespace std; class Employee { public: int id; char name[128]; char depart[128]; Employee() { cout << "Employee类构造函数被调用" << endl; } ~Employee() { cout << "~Employee类析构函数被调用" << endl; } }; class Operator:public Employee { public: char password[128]; void outputName() { cout << "操作员姓名:" << name << endl; } bool login() { if (strcmp(name,"MR") == 0 && strcmp(password,"KJ") == 0) { cout << "登录成功" << endl; return true; }else{ cout << "登录失败" << endl; return false; } } }; int main(int argc, char* argv[]) { Operator optr; strcmp(optr.name,"MR"); optr.outputName(); return 0; }
8.2 多重继承
前面所介绍的继承方式属于单继承,即子类只从一个父类继承共有的和受保护的成员。与其他面向对象语言不同,C++语言允许了类从多个父类继承共有的和受保护的成员,这被称之为多继承。
多重继承定义
多重继承就是指有多个基类名标识符,多重继承的声明形式如下:
class 派生类名标识符:[继承方式] 基类名标识符1,...,访问控制修饰符 基类名标识符n { [访问控制修饰符] [成员声明列表] }
声明形式中有“ : ” 运算符,基类名标识符之间用逗号运算符分开。
二义性
派生类在调用成员函数时,先在自身的作用域内寻找,如果找不到,会到基类中寻找。但当派生类继承的基类中有同名成员时,派生类中就会出现来自不同基类的同名成员。
#include <iostream> using namespace std; class BaseA { public: void function() { cout << "basea" << endl; } }; class BaseB { public: void function() { cout << "baseB" << endl; } }; class DeviceC:public BaseA,public BaseB { public: void function(){ cout << "device C" << endl; } }; int main() { DeviceC p; p.function(); return 0; };
多重继承的构造顺序
单一继承是先调用基类的构造函数,然后调用派生类的构造函数,但多重继承将如何调用构造函数呢?
多重继承中的基类构造函数被调用的顺序以类派生表中声明的顺序为准。派生表就是多重继承定义中继承方式后面的内容,调用顺序就是按照基类名标识符的前后顺序进行的。
#include <iostream> using namespace std; class Bicycle { public: Bicycle() { cout << "Bicycle Construct" << endl; } Bicycle(int weight) { weight = weight; } void run() { cout << "Bicycle run" << endl; } protected: int weight; }; class Airplane { public: Airplane() { cout << "Airplane Construct" << endl; } Airplane(int weight) { weight = weight; } void fly() { cout << "airplane fly" << endl; } protected: int weight; }; class AirBicycle: public Bicycle,public Airplane { public: AirBicycle() { cout << "AirBicycle Construct" << endl; } void runFly() { cout << "run and fly" << endl; } }; int main() { AirBicycle ab; ab.runFly(); // 按继承的前后顺序来调用构造函数 //Bicycle Construct //Airplane Construct //AirBicycle Construct //run and fly }
8.3 多态
多态性(polymorphism)是面向对象程序设计的一个重要特征。利用多态性可以设计和实现一个易于扩展的系统。在C++语言中,多态性是指具有不同功能的函数可以用同一个函数名,这样就可以用一个函数名调用不同内容的函数。发出同样的消息被不同类型的对象接收时,导致完全不同的行为。这里所说的消息主要指类的成员函数的调用,而不同的行为是指不同的实现。
多态性通过联编实现。联编是指一个计算机程序自身彼此关联的过程。按照联编所进行的阶段不同,可分为两种不同的联编方法:静态联编和动态联编。在C++中,根据联编的时刻不同,存在两种类型多态性:函数重载和虚函数。
虚函数概述
在类的继承层次结构中,在不同的层次中可以出现名字相同、参数个数和类型都相同而功能不同的函数。编译器按照先自己后父类的顺序进行查找覆盖。如果子类有父类相同原型的成员函数时,要想调用父类的成员函数,需要对父类重新引用调用。虚函数则可以解决子类和父类相同原型成员函数的函数调用问题。虚函数允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类中的同名函数。
在基类用 virtual 声明成员函数为虚函数,在派生类中重新定义此函数,改变该函数的功能。在C++语言中虚函数可以继承,当一个成员函数被声明为虚函数后,其派生类中的同名函数都自动成为虚函数,但如果派生类没有覆盖基类的虚函数,则调用时调用基类的函数定义。
利用虚函数实现动态绑定
多态主要体现在虚函数上,只要有虚函数存在,对象类型就会在程序运行时动态绑定。动态绑定的实现方法是定义一个指向基类对象的指针变量,并使它指向同一类族中需要调用该函数的对象。通过该指针变量调用此虚函数。
虚函数有以下几方面限制:
- 只有类的成员函数才能说明为虚函数。
- 静态成员函数不能是虚函数,因为静态成员函数不受限于某个对象。
- 内联函数不能是虚函数,因为内联函数是不能在运行中动态确定其位置的。
- 构造函数不能是虚函数,对象只有构造函数才能被实例化,析构函数通常是虚函数。
虚继承
从CBird类和CFish类派生子类CWaterBird时,在CWaterBird类中将存在两个CAnimal类的拷贝。问题是如何在派生CWaterBird类时,使其只存在一个CAnimal基类,C++语言提供的虚继承的机制,就是为了解决这个问题。
#include <iostream> using namespace std; /** * 虚继承 */ class CAnimal { public: CAnimal() { cout << "动物类被构造" << endl; } void move() { cout << "动物能够移动" << endl; } }; class CBird: virtual public CAnimal { public: CBird() { cout << "鸟类被构造" << endl; } void FlyInSky() { cout << "鸟能够在天空飞翔" << endl; } void breath() { cout << "鸟能够呼吸" << endl; } }; class CFish: virtual public CAnimal { public: CFish() { cout << "鱼类被构造" << endl; } void swimInWater() { cout << "鱼能够在水里游" << endl; } void breath() { cout << "鱼能够呼吸" << endl; } }; class CWaterBird:public CBird,public CFish { public: CWaterBird() { cout << "水鸟类被构造" << endl; } void action() { cout << "水鸟即能飞又能游" << endl; } }; int main(int argc, char* argv[]) { CWaterBird waterBird; return 0; } // 虚继承的结果,只调用一次父类的构造函数 //动物类被构造 //鸟类被构造 //鱼类被构造 //水鸟类被构造 // 不使用 virtual 的结果,每个父类都会调用一次父类的构造函数 //动物类被构造 //鸟类被构造 //动物类被构造 //鱼类被构造 //水鸟类被构造
8.4 重载运算符
运算符重载实际是一个函数,所以运算符的重载实际上是函数的重载。编译程序对运算符重载的选择,遵循着函数重载的选择原则。当遇到不很明显的运算时,编译程序将去寻找与参数相匹配的运算符函数。
重载运算符的形式与规则
重载运算符的声明形式如下:
operator类型名();
operator是需要重载的运算符,整个语句没有返回类型,因为类型名就代表了它的返回类型,重载运算符将对象转换成类型名规定的类型。转换时的形式就像强制转换一样。如果没有重载运算答定义,直接用强制转换编译器无法通过编译。
重载的运算符不可以是新创建的运算符,可以重载运算符是在C++语言中已有的运算符,可以重载的运算符如下:
- 算术运算符:+、-、*、/、%、++、--
- 位操作运算符:&、|、~、^、>>、<<
- 逻辑运算符:!、&&、||
- 比较运算符:<、>、>=、<=、==、!=
- 赋值运算符:=、+=、-=、*=、/=、%=、&=、|=、^=、<<=、>>=
- 其他运算符:[]、()、->、逗号、new、delete、new[]、delete[]、->*
并不是所有的C++语言中已有的运算符都可以重载,不允许重载的运算符有:“ . ”,“ * ”,“ :: ”,“ ? ”,“ : ”
/** * 重载运算符 * 通过 operator 来定义 */ #include <iostream> using namespace std; class CBook { public: CBook(int iPage) { m_iPage = iPage; } CBook operator+ ( CBook b) { return CBook(m_iPage + b.m_iPage); } void display() { cout << m_iPage << endl; } protected: int m_iPage; }; int main() { CBook bk1(10); CBook bk2(20); CBook tmp(0); tmp = bk1 + bk2; tmp.display(); return 0; }
转换运算符
C++语言中普通的数据类型可以进行强制类型转换,例如:

程序中将整形数 i 强制转换成双精度。
语句 d = (double) i;
等同于 d = double(i);
double() 在 C++ 语言中被称为转换运算符。通过重载转换运算符可以将类对象转换成想要的数据。例如。
#include <iostream> using namespace std; /** * 强制类型转换 */ class CBook { public: CBook(double iPage = 0); operator double() { return m_iPage; } protected: int m_iPage; }; CBook::CBook(double iPage) { m_iPage = iPage; } int main() { CBook bk1(10.0); CBook bk2(20.0); cout << "bk1+bk2=" << double(bk1) + double(bk2) << endl; // bk1+bk2=30 return 0; }
8.5 抽象类
包含有纯虚数的类称为抽象类,一个抽象类至少具有一个纯虚函数。抽象类只能作为基类派生出新的子类,而不能在程序中被实例化(即不能说明抽象类的对象),但是可以使用指向抽象类的指针。在开发程序过程中并不是所有代码都是自己写的,有时候需要调用库函数,有时候分给别人写,一名软件构造师可以通过纯虚函数建立接口,然后让程序员填写代码实现接口,软件构造师主要负责建立抽象类。
纯虚函数
所谓纯虚函数(pure virtual function)是指被标明为不具体实现的虚成员函数,纯虚函数不具备函数的功能。许多情况下,在基类中不能为虚函数给出一个有意义的定义。这时可以在基类中将它说明为纯虚函数。它的实现留给派生类去做。纯虚函数不能被直接调用,仅起提供一个与派生类相一致的接口作用。声明纯虚函数的形式为:
virtual 类型 函数名 (参数列表) = 0;
纯虚函数不可以被继承。当基类是抽象类时,在派生类中必须给出基类中纯虚函数的定义,或在该类中再声明其为纯虚函数。只有在派生类中给出了基类中所有纯虚函数的实现时,该派生类就不再成为抽象类。
#include <iostream> using namespace std; /** * 基类,只有一个线虚函数,让子类实现 */ class CFigure { public: virtual double getArea() = 0; }; // 用 const 定义一个常量 const double PI = 3.14; /** * 圆形 */ class CCircle : public CFigure { private: double m_dRadius; public: CCircle(double dR){ m_dRadius = dR; } double getArea() { return m_dRadius * m_dRadius * PI; } }; /** * 矩形 */ class CRectangle:public CFigure { protected: double m_dHeight,m_dWidth; public: CRectangle(double dHeight, double dWidth) { m_dHeight = dHeight; m_dWidth = dWidth; } double getArea() { return m_dHeight * m_dWidth; } }; int main() { CFigure *fg1; fg1 = new CRectangle(4.0,5.0); cout << fg1->getArea() << endl; // 20 delete fg1; CFigure *fg2; fg2 = new CCircle(4.0); cout << fg2->getArea() << endl; // 50.24 delete fg2; return 0; } /////////////////////////////////////////////////////////////////////////// // 类似java的写法 class Shape { public: virtual double getArea() = 0; }; class Circle:public Shape { private: double radius; public: Circle(double radius) : radius(radius) {} double getArea() override { return radius * radius * PI; } }; class Rectange:public Shape { protected: double height,width; public: Rectange(double height, double width) : height(height), width(width) {} double getArea() override { return height * width; } }; int main() { Shape *s1; s1 = new Circle(4.0); cout << s1->getArea() << endl; // 20 delete s1; Shape *s2; s2 = new Rectange(4.0,5.0); cout << s2->getArea() << endl; // 50.24 delete s2; }
实现抽象类中的成员函数
抽象类通常用于作为其他类的父类,从抽象类派生的子类如果是抽象类,则子类必须实现父类中的所有纯虚函数。
#include <iostream> using namespace std; // 定义基类员工,是一个抽象类 class CEmployee { public: int m_ID; char m_Name[128]; char m_Depar[128]; virtual void outputName() = 0; }; // 操作员 class COperator:public CEmployee { public: char m_Password[128]; void outputName() { cout << "操作员姓名:" << m_Name << endl; } COperator() { strcpy(m_Name,"MR"); // 把 MR 复制到 m_Name 中 } }; // 系统管理员 class CSystemManager :public CEmployee { public: char m_Password[128]; void outputName() { cout << "系统管理员姓名:" << m_Name << endl; } CSystemManager() { strcpy(m_Name, "SK"); } }; int main(int argc, char* argv[]) { CEmployee * pWorker; pWorker = new COperator(); pWorker->outputName(); // 操作员姓名:MR delete pWorker; // delete:释放内存 pWorker = NULL; pWorker = new CSystemManager(); pWorker->outputName(); // 系统管理员姓名:SK delete pWorker; pWorker = NULL; return 0; }
8.6 友元
友元概述
使用 friend 关键字可以让特定的函数或者别的类的所有成员函数对私有数据成员进行读写。这个技术既可以保持数据的私有性,又能够是特定的类或函数直接访问私有数据。
#include <iostream> using namespace std; class CRectangle { protected: int m_iHeight; int m_iWidth; public: CRectangle() { m_iHeight = 0; m_iWidth = 0; } CRectangle(int iLeftTop_x, int iLeftTop_y, int iRightBottom_x, int iRightBottom_y) { m_iHeight = iRightBottom_y - iLeftTop_y; m_iWidth = iRightBottom_x - iLeftTop_x; } int getHeight() { return m_iHeight; } int getWidth() { return m_iWidth; } // 如果把这一句注释掉,编译就会报错,因为它调用了Rectangle的私有成员 m_iHeight 和 m_iWidth friend int ComputerRectArea(CRectangle & myRect); // 声明为友元函数 }; int ComputerRectArea(CRectangle & myRect) // 友元函数的定义 { return myRect.m_iHeight * myRect.m_iWidth; } int main() { CRectangle rg(0,0,100,100); cout << "Result of ComputerRectArea is:" << ComputerRectArea(rg) << endl; // Result of ComputerRectArea is:10000 return 0; }
友元类
对于类的私有方法,只有在该类中允许访问,其他类是不能访问的。但在开发程序时,如果两个类的耦合度比较紧密,能够在一个类中访问另一个类的私有成员会带来很大的方便。C++语言提供了友元类和友元方法(或者称为友元函数)来实现访问其他类的私有成员。当用户希望另一个类能够访问当前类的私有成员时,可以在当前类中将另一个类作为自己的友元类,这样,在另一类中就可以访问当前类的私有成员了。
#include <iostream> using namespace std; class CItem { private: char name[128]; void outputName() { printf("%s\n", name); } public: friend class CList; void setItemName(const char *pchData) { if (pchData != NULL) { strcpy(name, pchData); } } CItem() { memset(name, 0, 128); } }; class CList{ private: CItem item; public: void outputName(); }; void CList::outputName() { item.setItemName("BeiJing"); item.outputName(); }
友元方法
在开发程序时,有时需要控制另一个类对当前类的私有成员的方法。例如,假设需要实现只允许 CList 类的某个成员访问 CItem 类的私有成员,而不允许其他成员函数访问 CItem 类的私有数据。这可以通过定义友元函数来实现。在定义 CItem 类时,可以将 CList 类的某个方法定义为友元方法,这样就限制了只有该方法允许访问 CItem 类的私有成员。
9. 模板
9.1 函数模板
函数模板定义不是一个实在的函数,编译器不能为其生成可执行代码。定义函数模板只是一个对函数功能框架的描述,当它具体执行时,将根据传递的实际参数决定其功能。
函数模板的定义
函数模板定义的一般形式如下:
template <类型形式参数表> 返回类型 函数名(形式参数表)
{
...... //函数体
}
template 为关键字,表示定义一个模板,尖括号 <> 表示模板参数,模板参数主要有两种,一种是模板类型参数,另一种是模板非类型参数。上述代码中定义的模板使用的模板类型参数,模板类型参数使用关键字 class 或 typedef 开始,其后是一个用户定义的合法的标识符。模板非类型参数与普通参数定义相同,它通常为一个常数。
可以将声明函数模板分成 template 部分和函数名部分。例如:
template<class T>
void fun(T t)
{
...... // 函数实现
}
函数模板的作用
能涌通过一个 max 函数来完成既求整型数之间最大者又求实型数之间最大者,答案是使用函数模板以及#define 宏定义
#include <iostream> using namespace std; // 传统的方法,使用重载实现比较两个数的大小 //int maxMethod(int a, int b) //{ // return (a > b)? a : b; //} // //double maxMethod(double a, double b) //{ // return (a > b) ? a : b; //} // 使用 #define 宏定义的方法实现 // 宏定义属于是替换,在编译时,把 maxMethod(a,b) 替换为后面的表达式,如果是++b,结果就不对了。所以不满足需求,并且宏定义不能调试 #define maxMethod(a,b) (a > b ? a : b) // 使用模板实现 //template <class type> //type maxMethod(type a, type b){ // return ((a > b) ? a : b); //} int main() { double a, b; cin >> a >> b; cout << maxMethod(a,b) << endl; }
重载函数模板
整形数和实型数编译器可以直接进行比较,所以使用函数模板后也可以直接进行比较,但如果是字符指针指向的字符串该如何比较呢?答案是通过重载函数模板来实现。通常字符串需要库函数来进行比较,通过重载函数模板实现字符串的比较。
#include <iostream> #include <string.h> using namespace std; template <class type> type maxMethod(type a,type b) { return a > b ? a : b; } /** * 重载模板函数,字符串比较 */ char* maxMethod(char * a, char * b) { if (strcpy(a,b)) return a; else return b; } int main() { cout << maxMethod("mr","soft") << endl; return 0; }
#include <iostream> using namespace std; template <class type, int len> // 定义一个模板类型 type getMax(type array[len]) // 定义函数模板 { type ret = array[0]; // 定义一个变量 for (int i = 1; i < len; i++) { ret = ret > array[i] ? ret : array[i]; //比较数组元素大小 } return ret; // 返回最大值 } int main() { int array[5] = {1, 2, 3, 4, 5}; // 定义一个整形数组 int ret = getMax<int,5>(array); // 调用函数模板getMax double dset[3] = {10.5, 11.2, 9.8}; // 定义实数数组 auto dret = getMax<double,3>(dset); // 调用函数模板getMax // 这里用auto 或是double都可以,IDE推荐使用auto cout << ret << endl; cout << dret << endl; return 0; }
9.2 类模板
使用 template 关键字不但可以定义函数模板,也可以定义类模板,类模板代表一族类,是用来描述通用数据类型或处理方法的机制,它使类中的一些数据成员和成员函数的实数或返回值可以取任意的数据类型。类模板可以说是用类生成类,减少了类的定义数量
类模板的定义与声明
类模板的一般定义形式是:
template <类型形式参数表> class 类模板名
{
..... // 类模板体
}
类模板成员函数定义形式为:
template <类型形式参数表>
返回类型 类模板名 <类型名表>::成员函数名(形式参数列表)
{
..... // 函数体
}
template 是关键字,类型形式参数表与函数模板定义相同。类模板的成员函数定义时的类模板名与类模板定义时要一致,类模板不是一个真实的类,需要重新生成类,生成类的形式如下:
类模板名<类型实在参数表>
用新生成的类定义对象的形式如下:
类模板名<类型实在参数表> 对象名
其中类型实在参数表应与该类模板中的类型形式参数表匹配。用类模板生成的类称为模板类。类模板和模板类不是同一个概念,类模板是模板的定义,不是真实的类,定义中要用到类型参数,模板类本质上与普通类相同,它是模板的类型参数实例化之后得到的类。
简单类模板
类模板中的类型形式参数表可以在执行时指定,也可以在定义类模板时指定。
#include <iostream> using namespace std; template <class T1,class T2> class MyTemplate { T1 t1; T2 t2; public: MyTemplate(T1 t1, T2 t2) : t1(t1), t2(t2) {} void display(){ cout << t1 << ' ' << t2 << endl; } }; int main() { int a = 123; double b = 3.1415; MyTemplate<int,double> mt(a,b); mt.display(); }
默认模板参数
默认模板参数就是在类模板定义时设置类型形式参数表中一个类型参数的默认值,该默认值是一个数据类型,有默认的数据类型参数后,在定义模板新类时就可以不进行指定。
#include <iostream> using namespace std; template <class T1,class T2 = int> class MyTemplate { T1 t1; T2 t2; public: MyTemplate(T1 t1, T2 t2) : t1(t1), t2(t2) {} void display(){ cout << t1 << ' ' << t2 << endl; } }; int main() { int a = 123; double b = 3.1415; MyTemplate<int,double> mt(a,b); // 123 3.1415 MyTemplate<int> mt2(a,b); // 123 3 mt.display(); mt2.display(); }
为具体类型的参数提供默认值
默认模板参数是类模板中有默认的数据类型做参数,在模板定义时还可以为默认的数据类型声明变量,并且为变量赋值。
#include <iostream> using namespace std; template <class T1,class T2, int num = 10> class MyTemplate { T1 t1; T2 t2; public: MyTemplate(T1 tt1, T2 tt2){ t1 = tt1 + num, t2 = tt2 + num; } void display(){ cout << t1 << ' ' << t2 << endl; } }; int main() { int a = 123; double b = 3.1415; MyTemplate<int,double> mt(a,b); // 133 13.1415 MyTemplate<int,double, 100> mt2(a,b); // 223 103.141 mt.display(); mt2.display(); return 0; }
#include <iostream> using namespace std; class Date { int month,day,year; char format[128]; public: Date(int month = 0, int day = 0, int year = 0) : month(month), day(day), year(year) {} friend ostream& operator<<(ostream & os, const Date t) { cout << "month:" << t.month << ' '; cout << "day:" << t.day << ' '; cout << "year:" << t.year << ' '; return os; } void display() { cout << "month:" << month; cout << "day:" << day; cout << "year:" << year; } }; template <class T,int b> class Array { T elem[b]; public: Array() {} T& operator[](int sub) { assert(sub >= 0 && sub < b); return elem[sub]; } }; int main() { Array<Date,3> dateArray; Date dt1(1,2,3); Date dt2(4,5,6); Date dt3(7,8,9); dateArray[0] = dt1; dateArray[1] = dt2; dateArray[2] = dt3; for (int i = 0; i < 3; i++) { cout << dateArray[i] << endl; } // 下标越界,弹出警告 Date dt4(10,11,13); dateArray[3] = dt4; cout << dateArray[3] << endl; return 0; }
9.3 链表类模板
链表是一种常用的数据结构,创建链表类模板就是创建一个对象的容器,在容器内可以对不同类型的对象进行插入、删除和排序等操作。
设计 CList 让它能够适应各种类型的节点。一个最简单的方法就是将普通的链表类 CList 类改为类模板。
#include <iostream> using namespace std; template <class Type> //定义类模板 class CList //定义CList类 { private: Type *m_pHeader; //定义头节点 int m_NodeSum; //节点数量 public: CList() //定义构造函数 { m_pHeader = NULL; //将m_pHeader置为空 m_NodeSum = 0; //将m_NodeSum置为0 } Type* MoveTrail() //获取尾节点 { Type *pTmp = m_pHeader; //定义一个临时节点,将其指向头节点 for (int i=1;i<m_NodeSum;i++) //遍历链表 { pTmp = pTmp->m_pNext; //将下一个节点指向当前节点 } return pTmp; //返回尾节点 } void AddNode(Type *pNode) //添加节点 { if (m_NodeSum == 0) //判断链表是否为空 { m_pHeader = pNode; //在头节点处添加节点 } else //链表不为空 { Type* pTrail = MoveTrail(); //获取尾节点 pTrail->m_pNext = pNode; //在尾节点处添加节点 } m_NodeSum++; //使节点数量加1 } void PassList() //遍历链表 { if (m_NodeSum > 0) //判断链表是否为空 { Type* pTmp = m_pHeader; //定义一个临时节点,将其指向头节点 printf("%4d",pTmp->m_Data); //输出头节点数据 for (int i=1;i<m_NodeSum;i++) //利用循环访问节点 { pTmp = pTmp->m_pNext; //获取下一个节点 printf("%4d",pTmp->m_Data); //输出节点数据 } } } ~CList() //定义析构函数 { if (m_NodeSum > 0) //判断链表是否为空 { Type *pDelete = m_pHeader; //定义一个临时节点,将其指向头节点 Type *pTmp = NULL; //定义一个临时节点 for(int i=0; i< m_NodeSum; i++) //利用循环遍历所有节点 { pTmp = pDelete->m_pNext; //将下一个节点指向当前节点 delete pDelete; //释放当前节点 pDelete = pTmp; //将当前节点指向下一个节点 } m_NodeSum = 0; //设置节点数量为0 pDelete = NULL; //将pDelete置为空 pTmp = NULL; //将pTmp置为空 } m_pHeader = NULL; //将m_pHeader置为空 } }; class CNet //定义一个节点类 { public: CNet *m_pNext; //定义一个节点类指针 char m_Data; //定义节点类的数据成员 CNet() //定义构造函数 { m_pNext = NULL; //将m_pNext置为空 } }; class CNode //定义一个节点类 { public: CNode *m_pNext; //定义一个节点指针,指向下一个节点 int m_Data; //定义节点的数据 CNode() //定义节点类的构造函数 { m_pNext = NULL; //将m_pNext设置为空 } }; int main(int argc, char* argv[]) { CList<CNode> nodelist; //构造一个类模板实例 for(int n=0; n<5; n++) //利用循环向链表中添加节点 { CNode *pNode = new CNode(); //创建节点对象 pNode->m_Data = n; //设置节点数据 nodelist.AddNode(pNode); //向链表中添加节点 } nodelist.PassList(); //遍历链表 cout <<endl; //输出换行 CList<CNet> netlist; //构造一个类模板实例 for(int i=0; i<5; i++) //利用循环向链表中添加节点 { CNet *pNode = new CNet(); //创建节点对象 pNode->m_Data = 97+i; //设置节点数据 netlist.AddNode(pNode); //向链表中添加节点 } netlist.PassList(); //遍历链表 cout << endl; //输出换行 return 0; }
类模板的静态数据成员
在类模板中用户也可以定义静态的数据成员,只是类模板中的每个实例都有自己的静态数据成员,而不是所有的类模板实例共享静态数据成员。我们对模板类 CList 进行简化,向其中添加一个静态数据成员,并初始化静态数据成员。
#include <iostream> using namespace std; template<class Type> class CList //定义CList类 { private: Type *m_pHeader; int m_NodeSum; public: static int m_ListValue; //定义静态数据成员 CList() { m_pHeader = NULL; m_NodeSum = 0; } }; class CNode //定义CNode类 { public: CNode *m_pNext; int m_Data; CNode() { m_pNext = NULL; } }; class CNet //定义CNet类 { public: CNet *m_pNext; char m_Data; CNet() { m_pNext = NULL; } }; template<class Type> int CList<Type>::m_ListValue = 10; //初始化静态数据成员 int main(int argc, char *argv[]) { CList<CNode> nodelist; nodelist.m_ListValue = 2008; CList<CNet> netlist; netlist.m_ListValue = 88; cout << nodelist.m_ListValue << endl; cout << netlist.m_ListValue << endl; return 0; }
9.4 模板的使用
定义完模板类后如果想扩展模板新类的功能,需要对类模板进行覆盖,使模板类能够完成特殊功能。覆盖操作可以针对整个类模板、部分类模板以及类模板的成员函数。把这种覆盖操作称之为定制。
定制类模板
定义一个类模板,然后覆盖类模板中所定义的所有成员
#include <iostream> using namespace std; class Date { int iMonth,iDay,iYear; char Format[128]; public: Date(int m=0,int d=0,int y=0) { iMonth=m; iDay=d; iYear=y; } friend ostream& operator<<(ostream& os,const Date t) { cout << "Month: " << t.iMonth << ' ' ; cout << "Day: " << t.iDay<< ' '; cout << "Year: " << t.iYear<< ' ' ; return os; } void Display() { cout << "Month: " << iMonth; cout << "Day: " << iDay; cout << "Year: " << iYear; cout << endl; } }; template <class T> class Set { T t; public: Set(T st) : t(st) {} void Display() { cout << t << endl; } }; template<> class Set<Date> { Date t; public: Set(Date st): t(st){} void Display() { cout << "Date :" << t << endl; } }; int main() { Set<int> intset(123); Set<Date> dt =Date(1,2,3); intset.Display(); dt.Display(); return 0; }
定制类模板成员函数
定义一个类模板,然后覆盖类模板中指定的成员
#include <iostream> using namespace std; class Date { int iMonth,iDay,iYear; char Format[128]; public: Date(int m=0,int d=0,int y=0) { iMonth=m; iDay=d; iYear=y; } friend ostream& operator<<(ostream& os,const Date t) { cout << "Month: " << t.iMonth << ' ' ; cout << "Day: " << t.iDay<< ' '; cout << "Year: " << t.iYear<< ' ' ; return os; } void Display() { cout << "Month: " << iMonth; cout << "Day: " << iDay; cout << "Year: " << iYear; cout << std::endl; } }; template <class T> class Set { T t; public: Set(T st) : t(st) { } void Display(); }; template <class T> void Set<T>::Display() { cout << t << endl; } void Set<Date>::Display() // 在 Clion 中报错,运行不下去,template specialization requires 'template<>' { cout << "Date: " << t << endl; } int main() { Set<int> intset(123); Set<Date> dt =Date(1,2,3); intset.Display(); dt.Display(); return 0; }
模板部分定制
定义一个类模板,然后覆盖模板类型形式参数表中的一个参数。
#include <iostream> using namespace std; template <class T1,class T2> class MyTemplate { T1 obj1; T2 obj2; public: MyTemplate(T1 o1,T2 o2) : obj1(o1) ,obj2(o2){} void display() { cout << "Object Display" << endl; cout << "Object 1:" << obj1 << endl; cout << "Object 2:" << obj2 <<endl; cout << endl; } }; template <class T> class MyTemplate<T, char> { T obj1,obj2; public: MyTemplate(T o1,char c) : obj1(o1) ,obj2(o1) {obj2+=(int)c;} void display() { cout << "Object Display" << endl; cout << "Object 1:" << obj1 << endl; cout << "Object 2:" << obj2 <<endl; cout << endl; } }; int main() { MyTemplate<int,int>mt1(10,20); MyTemplate<int,int>mt2(10,'b'); mt1.display(); mt2.display(); return 1; }
10. 宏、异常处理
10.1 不带参数的宏定义
宏定义指令 #define 用来定义一个标识符和一个字符串,以这个标识符来代表这个字符串,在程序中每次遇到该标识符时就用所定义的字符串替换它。它的作用相当于给指定的字符串起一个别名。
不带参数的宏定义一般形式如下:
#define 宏名 字符串
例如: #define PI 3.1415926
它的作用是在程序中用PI替代3.1425926,在编译预处理时,每当在源程序中遇到 PI 就自动用 3.1415926代替。
使用 #define 进行宏定义的好处是需要改变一个常量的时候只需要改变 #define 命令行,整个程序的常量都会改变,大大的提高了程序的灵活性。
宏名要简单且意义明确,一般习惯用大写字母表示以便与变量名相区别。
注意:
宏定义不是C语句,不需要在行末加分号。
#include <stdio.h> #define PRICE 390.5 int main() { printf("衣服原价为:%.1f\n", PRICE); printf("八折原价为:%.1f\n", 0.8 * PRICE); printf("六折原价为:%.1f\n", 0.6 * PRICE); }
说明:
(1)如果在字符串中含有宏名,则不进行替换。
(2)如果字符串长于一行,可以在该行末尾用一反斜杠“\”续行。
(3)#define命令出现在程序中函数的外面,宏名的有效范围为定义命令之后到此源文件结束。
(4)可以用#define命令终止宏定义的作用域。
(5)宏定义用于预处理命令,它不同于定义的变量,只作字符替换,不分配内存空间。
10.2 带参数的宏定义
带参数的宏定义不是简单的字符串替换,还要进行参数替换。一般形式如下:
#define 宏名(参数名) 字符串
#include <stdio.h> #define MIX(a,b) ((a) * (b) + (b)) // 宏定义求两个数的混合运算 int main() { int x = 5, y = 9; printf("x,y:\n"); printf("%d,%d\n",x,y); printf("the results is :%d\n",MIX(x,y)); //宏定义调用 }
对于带参数的宏定义有以下几点需要强调:
(1)宏定义时参数要加括号,如不加括号,有时结果是正确的,有时结果便是错误的,那么什么时候是正确的,什么时候是错误的,下面具体说明:
当参数 x = 10,y = 9时,在参数不加括号的情况下调用MIX(x,y),可以正确的输出结果;当x=10,y=3+4时,在参数不加括号的情况下调用MIX(x,y),则输出的结果是错误的,因为此时调用的MIX(x,y)执行情况如下:
(10 * 3 + 4 + 3 + 4);
此时计算出的结果是41,而实际上希望得出的结果是77,所以为了避免出现上面这种情况,在进行宏定义时要在参数外面要加上括号。
(2)宏定义必须使用括号,来保护表达式中低优先级的操作符,以便确保调用时达到想要的结果。
如之前的示例,宏扩展外没有加括号,则调用: 5*MIX(x,y)
则会被扩展为: 5*(a)*(b)+(b)
而本意是希望得到: 5*((a) * (b) + (b) )
解决的办法就是上面说的宏扩展时加上括号就能避免这种错误发生。
(3)对带参数的宏的展开只是将语句中的宏名后面括号内的实参字符串代替 #define 命令行中的形参。
(4)在宏定义时,在宏名与带参数的括号之间不可以加空格,否则将空格以后的字符都作为替代字符串的一部分。
(5)在带参宏定义中,形式参数不分配内存单元,因此不必作类型定义。
10.3 #undef命令
使用#undef命令用来删除事先定义了的宏定义。
#undef命令的一般形式如下:
#undef 宏替换名
例如:

在上面代码中,首先使用 #define 定义标识符MAX_SIZE,直到遇到 #undef 语句之前,MAX_SIZE 的定义都是有效的。
10.4 异常处理
异常处理是程序设计中除调试之外的另一错误处理方法。
异常处理与真正的错误片是其实是有一定的区别的,异常处理不但可以对系统错误做出反应,还可以对人为制造的错误做出反应并处理。
抛出异常
当程序执行到某一函数或方法内部时,程序本身出现了一些异常,但这些异常并不能由系统所捕获,这时就可以创建一个错误信息,再由系统捕获该错误信息并处理。创建错误信息并发送这一过程称之为抛出异常。
在 C++ 中异常的抛出就是使用 throw 关键字来实现的,在这个关键字的后面可以跟随任何类型的值。
异常捕获
异常捕获是指当一个异常被抛出时,不一定就在异常抛出的位置来处理这个异常,而是可以在别的地方通过捕获这个异常信息后再进行处理。这样增加了程序结构的灵活性,也提高了异常处理的的方便性。
如果在函数内抛出一个异常(或在函数调用时抛出一个异常),将在异常抛出时退出函数。如果不想在异常抛出时退出函数,可在函数内创建一个特殊块用于解决实际程序中的问题。这个特殊的块由try关键字组成。
try{ } catch(type obj){ }
异常处理部分必须直接放在测试块之后。如果一个异常信号被抛出,异常处理器中第一个参数与异常抛出对象相匹配的函数将捕获该异常信息,然后进入相应的 catch 语句,执行异常处理程序。 catch语句与 switch语句不同,它不需要在每个 case语句后加入 break 用以中断后面程序的执行。
异常匹配
当在程序中有异常抛出时,异常处理系统会根据异常处理器的顺序找到最近的异常处理块,并不会搜索更多的异常处理块。
异常匹配并不要求异常与异常处理器进行完美匹配,一个对象或一个派生类对象的引用将与基类处理器进行匹配。若抛出的是类对象的指针,则指针将会匹配相应的对象类型,但不会自动转换成其他对象的类型。
#include <iostream> #include <string> using namespace std; class CCustomError //异常类 { private: int m_ErrorID; // 异常id char m_Error[255]; // 异常信息 public: CCustomError(int ErrorID,char *Error) //构造函数 { m_ErrorID = ErrorID; strcpy(m_Error,Error); } int getM_ErrorID() const { // 获取异常id return m_ErrorID; } const char *getM_Error() const { // 获取异常信息 return m_Error; } }; int main() { try { throw (new CCustomError(1,"出现异常!")); //抛出异常 } catch (CCustomError *error) { // 输出异常信息 cout << "异常id:" << error->getM_ErrorID() << endl; cout << "异常信息:" << error->getM_Error() << endl; } return 0; }
11. STL
11.1 序列容器
STL 提供了很多容器,每种容器都提供一组操作行为,序列容器(sequence容器)只提供插入功能,序列容器中的元素都是有序的,但并未排序,序列容器包括 vector 向量、deque 双端队列和 list 双向串行。
向量类模板
向量(vector)是一种随机访问的数组类型,提供了对数组元素的快速、随机访问,以及在序列尾部快速、随机的插入和删除操作。它在需要时可以改变其大小,是大小可变的向量。
#include <iostream> #include <vector> using namespace std; void outVal(char val) { cout << val << ' '; } int main() { vector<char> charVector; // 创建字符型向量 charVector.push_back('Z'); // 在向量中插入数据 charVector.push_back('D'); charVector.push_back('S'); charVector.push_back('A'); charVector.push_back('E'); charVector.push_back('C'); charVector.push_back('U'); charVector.push_back('V'); cout << "Contents of vector:"; for_each(charVector.begin(),charVector.end(),outVal); //循环并显示向量中的元素 sort(charVector.begin(),charVector.end()); // 对向量中的元素进行排序 cout << endl << "Contents of vector:"; for_each(charVector.begin(),charVector.end(),outVal); //循环并显示向量中的元素 cout << endl; return 0; }
双端队列类模板
双端队列(deque)是一种随机访问的数据类型,提供了在序列两端快速插入和删除操作的功能,它可以在需要的时候修改其自身的大小,双端队列主要完成标准C++数据结构中队列的功能。
#include <iostream> #include <deque> using namespace std; int main() { deque<int> intdeque; intdeque.push_back(2); intdeque.push_back(3); intdeque.push_back(4); intdeque.push_back(7); intdeque.push_back(9); cout << "Deque:old " << endl; for (int i = 0; i < intdeque.size(); i++) { cout << "intdeque[" << i << "]:"; cout << intdeque[i] << endl; } cout << endl; intdeque.pop_front(); // 删除队列中的元素 intdeque.pop_front(); intdeque[1] = 33; cout << "Deque: new" << endl; for (int j = 0; j < intdeque.size(); j++) { cout << "intdeque[" << j << "]:"; cout << intdeque[j] << endl; } cout << endl; return 0; }
链表类模板
链表(list)双向链表容器,它不支持随机访问,访问链表元素要指针从链表的某个端点开始,插入和删除操作所花费的时候是固定的,和该元素在链表中的位置无关。在任何位置插入和删除动作都很快,不像 vector 只在末尾进行操作。
#include <iostream> #include <list> using namespace std; int main() { char cTemp; list<char> charlist; // 声明list对象 for (int i = 0; i < 5; i += 3) { cTemp = 'a' + i; charlist.push_front(cTemp); // 将数据保存到链表中 } cout << "list old:" << endl; list<char>::iterator it; // 声明一个链表的迭代器 for (it = charlist.begin(); it != charlist.end(); it++) { cout << *it << endl; // 通过迭代器将数据读取出来 } list<char>::iterator itstart = charlist.begin(); // 指向链表的首部 charlist.insert(++itstart, 2, 'A'); // 通过迭代器在链表的首部插入数据,2 是插入几个数据,'A'是插入的结果 cout << "list new:" << endl; for (it = charlist.begin(); it != charlist.end(); it++) { cout << *it << endl; } return 0; }
11.2 迭代器
迭代器是相当于指向容器元素的指针,迭代器在容器内中以向前移动,可以向前向后双向移动,有专为输入元素准入的迭代器,有专为输出元素准备的迭代器,还有可以进行随机操作迭代器,迭代器为访问容器提供了通用方法。
输出迭代器
输出迭代器:只用于写一个序列,这种类型的迭代器可以进行递增和提取操作。
#include <iostream> #include <vector> using namespace std; int main() { vector<int> v; for (int i = 0; i < 10; i+=2) { v.push_back(i); } cout << "Vector: " << endl; vector<int>::iterator it = v.begin(); while (it != v.end()) cout << *it++ << endl; // 0 2 4 6 8 return 0; }
输入迭代器
输入迭代器:只用于读一个序列,这种类型的迭代器可以进行递增、提取和比较操作。
#include <iostream> #include <vector> using namespace std; int main() { vector<int> intVect(5); vector<int>::iterator out = intVect.begin(); // auto out = intVect.begin(); // ide推荐使用 auto *out++ = 1; *out++ = 3; *out++ = 5; *out++ = 7; *out = 9; cout << "Vect:"; auto it = intVect.begin(); while (it !=intVect.end()) cout << *it++ << ' '; cout << endl; return 0; }
前向迭代器
前向迭代器:即可用于读,也可用于写。这种类型的迭代器不仅具有输入和输出迭代器的功能,还具有保存其值的功能,从而能够从迭代器原来的位置开始重新遍历序列。
#include <iostream> #include <vector> using namespace std; int main() { vector<int> intVect(5); vector<int>::iterator it = intVect.begin(); vector<int>::iterator saveIt = it; *it++ = 12; *it++ = 21; *it++ = 31; *it++ = 41; *it = 9; cout << "Vect:"; while (saveIt !=intVect.end()) cout << *saveIt++ << ' '; cout << endl; return 0; }
双向迭代器
双向迭代器:既可用于读,也可用于写。这种类型的迭代器与前向迭代器类似,只是双向迭代器可做递增和递减操作。
#include <iostream> #include <vector> using namespace std; int main() { vector<int> intVect(5); vector<int>::iterator it = intVect.begin(); vector<int>::iterator saveIt = it; *it++ = 1; *it++ = 3; *it++ = 5; *it++ = 7; *it = 9; cout << "Vect:"; while (saveIt !=intVect.end()) cout << *saveIt++ << ' '; cout << endl; do cout << *--saveIt << endl; while (saveIt != intVect.begin()); cout << endl; return 0; }
随机访问迭代器
随机访问迭代器:最强大的迭代器类型,不仅具有双向迭代器的所有功能,还能使用指针的算术运算和所有比较运算。
#include <iostream> #include <vector> using namespace std; int main() { vector<int> intVect(5); vector<int>::iterator it = intVect.begin(); *it++ = 1; *it++ = 3; *it++ = 5; *it++ = 7; *it = 9; cout << "Vect Old:"; for (it = intVect.begin(); it != intVect.end(); it++) { cout << *it << ' '; } it = intVect.begin(); // 定位到迭代器的开头 *(it + 2) = 100; cout << endl; cout << "Vect:"; for (it = intVect.begin(); it != intVect.end(); it++) { cout << *it << ' '; } cout << endl; return 0; }
11.3 算法
算法(algorithm)是STL的中枢,STL 中提供了算法库,算法库中都是模板函数,迭代器主要负责从容器那获取一个对象,算法不关系具体对象在容器什么位置等细节。每个算法都是参数化一个或多个迭代器类型的函数模板。
标准算法分4个类别:非修正序列算法、修正序列算法、排序算法和数值算法。
非修正序列算法
非修正算法不修改它们所作用的容器,例如计算元素个数或查找元素的函数。
#include <iostream> #include <list> #include <set> using namespace std; int main() { multiset<int, less<int>> intSet; intSet.insert(7); intSet.insert(5); intSet.insert(1); intSet.insert(5); intSet.insert(7); cout << "Set: " << " "; multiset<int, less<int>>::iterator it = intSet.begin(); for (int i = 0; i < intSet.size(); ++i) { cout << *it++ << ' '; } cout << endl; cout << "第一次匹配: "; it = adjacent_find(intSet.begin(),intSet.end()); cout << *it++ << ' '; cout << *it << endl; cout << "第二次匹配: "; it = adjacent_find(it,intSet.end()); cout << *it++ << ' '; cout << *it << endl; return 0; }
#include <iostream> #include <set> using namespace std; int main() { multiset<int, less<int>> intSet; intSet.insert(7); intSet.insert(5); intSet.insert(1); intSet.insert(5); intSet.insert(7); cout << "Set:"; multiset<int, less<int>>::iterator it = intSet.begin(); for (int i = 0; i < intSet.size(); i++) { cout << *it++ << ' '; } cout << endl; int cnt = count(intSet.begin(), intSet.end(), 5); // 容器中有几个5 cout << "相同元素数量:" << cnt << endl; return 0; }
#include <iostream> #include <set> using namespace std; void Output(int val) { cout << val << ' '; } int main() { multiset<int, less<int>> intSet; intSet.insert(7); intSet.insert(5); intSet.insert(3); cout << "Set:"; for_each(intSet.begin(), intSet.end(), Output); // 对窗口中的每个元素调用 Output 函数 cout << endl; return 0; }
修正序列算法
修正序列算法有些操作会改变容器的内容。例如,把一个容器的部分内容拷贝到同一个容器的另一部分,或者用指定值填充容器。STL的变异算法提供了这类操作。
#include <iostream> #include <vector> using namespace std; void Output(int val) { cout << val << ' '; } int main() { vector<int> intVector; for (int i = 0; i < 10; i++) { intVector.push_back(i); // 为整形向量输入10个数 } cout << "Vect:"; for_each(intVector.begin(), intVector.end(), Output); fill(intVector.begin(), intVector.begin() + 5, 0); // 填充数值,如果原来有值,就修改 此处修改前5个元素的值为0 cout << endl; cout << "Vect:"; for_each(intVector.begin(), intVector.end(), Output); cout << endl; return 0; } //Vect:0 1 2 3 4 5 6 7 8 9 //Vect:0 0 0 0 0 5 6 7 8 9
#include <iostream> #include <vector> using namespace std; void Output(int val) { cout << val << ' '; } int main() { vector<char> charVector; charVector.push_back('B'); charVector.push_back('A'); charVector.push_back(' '); charVector.push_back('M'); charVector.push_back('R'); charVector.push_back(' '); charVector.push_back('K'); cout << "Vect:"; for_each(charVector.begin(), charVector.end(), Output); // 将容器内的元素进行旋转,把第1个元素和向后移动6个位置的元素倒转 rotate(charVector.begin(), charVector.begin() + 6, charVector.end()); cout << endl; cout << "Vect:"; for_each(charVector.begin(), charVector.end(), Output); cout << endl; return 0; }
排序算法
排序算法,该算法的特点是对容器的内容进行不同方式的排序
#include <iostream> #include <vector> using namespace std; void Output(int val) { cout << val << ' '; } int main() { vector<char> charVector; charVector.push_back('M'); charVector.push_back('R'); charVector.push_back('K'); charVector.push_back('J'); charVector.push_back('H'); charVector.push_back('I'); cout << "Vect:"; for_each(charVector.begin(), charVector.end(), Output); sort(charVector.begin(), charVector.end()); cout << endl; cout << "Vect:"; for_each(charVector.begin(), charVector.end(), Output); cout << endl; return 0; }
数值算法
数值算法,该算法是对容器的内容进行数值计算。
-
accumulate(first, last, init) 元素累加
-
inner_product(first, last, first2, init) 内积
-
partial_sum(first, last, result) 局部总和
-
adjacent_difference(first, last, result) 相邻元素的差额
#include <iostream> #include <vector> #include <numeric> using namespace std; void Output(int val) { cout << val << ' '; } int main() { vector<int> intVect; for (int i = 0; i < 5; i++) { intVect.push_back(i); } cout << "Vect:"; for_each(intVect.begin(), intVect.end(), Output); // 把vector中的所有元素累加 int result = accumulate(intVect.begin(), intVect.end(), 5); cout << endl; cout << "Result:" << result << endl; return 0; } //Vect:0 1 2 3 4 //Result:15
11.4 set类模板
set 类模板又称为集合类模板,一个集合对象像链表一样顺序的存储一组值。在一个集合中,集合元素既充当存储的数据,又充当数据的关键码。
#include <iostream> #include <set> using namespace std; void Output(int val) { cout << val << ' '; } int main() { set<int> iSet; // 创建整型集合 iSet.insert(1); // 插入数据 iSet.insert(3); iSet.insert(5); iSet.insert(7); iSet.insert(9); cout << "set:" << endl; set<int>::iterator it; //循环并输出集合中的数据 for (it = iSet.begin(); it != iSet.end(); it++) { cout << *it << endl; } return 0; }
#include <iostream> #include <set> using namespace std; int main() { set<int> iSet; // 创建整型集合 iSet.insert(1); // 插入数据 iSet.insert(3); iSet.insert(5); iSet.insert(7); iSet.insert(9); cout << "old set:" << endl; set<int>::iterator it; //循环并输出集合中的数据 for (it = iSet.begin(); it != iSet.end(); it++) { cout << *it << endl; } it = iSet.begin(); iSet.erase(++it); // 删除集合中的元素 cout << "new set:" << endl; for (it = iSet.begin(); it != iSet.end(); it++) { // 循环集合,显示元素删除后的集合 cout << *it << endl; } return 0; } /* old set: 1 3 5 7 9 new set: 1 5 7 9 */
#include <iostream> #include <set> using namespace std; int main() { set<char> cSet; // 利用 set 对象创建字符类型的集合 cSet.insert('B'); // 插入元素 cSet.insert('C'); cSet.insert('D'); cSet.insert('A'); cSet.insert('F'); cout << "old set:" << endl; set<char>::iterator it; // 循环显示集合中的元素 for (it = cSet.begin(); it != cSet.end();it++){ cout << *it << endl; } char cTemp; cTemp = 'D'; it = cSet.find(cTemp); // 在集合中查找指定的元素 cout << "start find: " << cTemp << endl; if (it == cSet.end()) // 没找到元素 cout << "not found" << endl; else // 找到元素 cout << "found" << endl; cTemp = 'G'; it = cSet.find(cTemp); // 在集合中查找指定的元素 cout << "start find: " << cTemp << endl; if (it == cSet.end()) // 没找到元素 cout << "not found" << endl; else // 找到元素 cout << "found" << endl; return 0; }
#include <iostream> #include <set> using namespace std; int main() { set<char> cSet1; // 利用 set 对象创建字符类型的集合 cSet1.insert('C'); cSet1.insert('D'); cSet1.insert('A'); cSet1.insert('F'); cout << "set1:" << endl; set<char>::iterator it; // 循环显示集合中的元素 for (it = cSet1.begin(); it != cSet1.end(); it++) { cout << *it << endl; } set<char> cSet2; // 利用 set 对象创建字符类型的集合 cSet2.insert('B'); cSet2.insert('C'); cSet2.insert('D'); cSet2.insert('A'); cSet2.insert('F'); cout << "set2:" << endl; for (it = cSet2.begin(); it != cSet2.end(); it++) { cout << *it << endl; } if (cSet1 == cSet2) { cout << "set1 == set2"; } else if (cSet1 < cSet2) { cout << "set1 < set2"; } else if (cSet1 > cSet2) { cout << "set1 > set2"; } cout << endl; return 0; } /* set1: A C D F set2: A B C D F set1 > set2 */
12. IO
12.1 文件流
类库的使用
C++系统中的 I/O 标准库,都定义在 iostream.h、fstream.h和strstream.h 这3个头文件中,各头文件包含的类如下。
- 进行标准 I/O 操作时使用 iostream.h 头文件,它包含有 ios,iostream,istream,ostream等类。
- 进行文件 I/O 操作时使用 fstream.h 头文件,它包含有 fstream.h,ifstream,ofstream,fstreambase 等类。
- 进行串 I/O 操作时使用 strstream.h 头文件,它包含有 strstream,istrstream,ostrstream,strstreambase,iostream等类。
ios 类中的枚举常量
在根基类 ios 中定义了用户需要使用的枚举类型,由于它们是在公用成员部分定义的,所以其中的每个枚举类型常量在加上 ios:: 前缀后都可以被本类成员函数和所有外部函数访问。
- skipws:利用它设置对应标志后,从流中输入数据时跳过当前位置及后面的所有连续的空白字符,从第一个非空白字符起读数,否则不跳过空白字符。空格、制表符\t、回车符\r和换行符\n统称为空白符。默认为设置。
- left:靠左对齐输出的数据。
- right:靠右对齐输出的数据。
- insternal:显示占满整个域宽,用填充字符在符号和数值之间填充。
- dec:用十进制输出数据。
- hex:用十六进制输出数据。
- showbase:在数据前显示基数符,八进制基数是0,十六进制基数符是0x。
- showpoint:强制输出的浮点数中带有小数点和小数尾部的无效数字0。
- uppercase:用大写输出数据。
- showpos:在数值前显示符号。
- scientific:用科学记数法显示浮点数。
- fixed:用固定小数点位数显示浮点数。
#include <iostream> #include <strstream> using namespace std; int main() { char buf[] = "12345678"; int i ,j; istrstream s1(buf); // 输入的字符串流 s1 >> i; // >> 提取字符,将字符串转换为数字 12345678 istrstream s2(buf, 3); // 只截取3位 s2 >> j; // 123 cout << i + j << endl; //两个数字相加 // 12345678 + 123 = 123456801 }
12.2 文件打开
打开模式
只有当使用文件流跟磁盘上面的文件进行了连接后才能对磁盘上文件进行操作,这个连接过程称为打开该报。
打开文件的方式有两种。
(1)在创建文件流时利用构造函数打开文件,即在创建流时加入参数,语法结构是
<文件流类> <文件流对象名> (<文件名>,<打开方式>)
其中文件流类可以是 fstream、ifstream和ofstream 中的一种。文件名指的是磁盘文件的名称,包括磁盘文件的路径名。打开方式在 ios 类中定义,有输入方港式、输出方港式、追加方式等。
(2)另一种打开文件的方式是利用 open 函数打开磁盘文件,语法结构是
<文件流对象名>.open (<文件名>,<打开方式>);
文件流对象名是一个已经定义了的文件流对象。
ifstream infile;
infile.open("test.txt",ios::out);
(3)打开失败的解决
使用这两种方式中的任意一种打开文件后,如果打开成功,文件流对象为非0值,如果打开失败,则文件流对象为0值。检测一个文件是否打开成功可以用以下语句:
void open(const char * filename, int mode, int prot = filebuf::openprot)
默认打开模式
如果没有指定打开方式参数,编译器会使用默认值。
std::ofstream std::ios::out | std::ios::trunk
std::ifstream std::ios::in
std::fstream 无默认值 文件的输入输出流没有默认的打开方式,必须手动指定
#include <iostream> #include <fstream> using namespace std; int main() { ofstream ofile; // 输出流,输出到文件上 cout << "create file1" << endl; ofile.open("test.txt"); if (!ofile.fail()) { ofile << "name1" << " "; ofile << "sex1" << " "; ofile << "age1" << " "; ofile.close(); cout << "create file2" << endl; ofile.open("test2.txt"); if (!ofile.fail()) { ofile << "name2" << " "; ofile << "sex2" << " "; ofile << "age2" << " "; ofile.close(); } } return 0; }
在对文件进行操作时,必须离不开读写文件。在使用程序查看文件内容时,首先要读取文件,而要修改文件内容时,则需要向文件中写入数据,本节就主要介绍通过程序对文件的读写操作。
文件流
(1)流可以分为3类,输入流,输出流及输入/输出流,相应的必须将流说明为ifstream、ofstream以及fstream类的对象。
-
ifstream ifile; //声明一个输入流
-
ofstream ofile; //声明一个输出流
-
fstream iofile; //声明一个输入/输出流
说明了流对象之后,可以使用函数open()打开文件。文件的打开即是在流与文件之间建立一个连接。
文件流成员函数
-
ofstream和ifstream类有很多用于磁盘文件管理的函数。
-
-
close:刷新未保存的数据后关闭文件。
-
flush:刷新流。
-
open:打开一个文件并把它与流关联。
-
put:把一个字节写入流中。
-
rdbuf:返回与流关联的filebuf对象。
-
seekp:设置流文件指针位置。
-
setmode:设置流为二进制或文件模式。
-
tellp:获取流文件指针位置。
-
write:把一组字节写入流中。
-
get(c):从文件读取一个字符
-
getline(str,n,'\n'):从文件读取字符存入字符串str中,直到读取n-1个字符,或遇到'\n'时结束。
-
peek():查找下一个字符,但不从文件中取出
-
put(c):将一个字符写入文件
-
putback(c):对输入流放回一个字符,但不保存
-
eof:如果读取超过EOF,返回True
-
#include <iostream> #include <fstream> using namespace std; int main() { char buf[128]; ofstream ofile("test.txt"); // 对文件执行写操作 for (int i = 0; i < 5; i++) { memset(buf,0,128); cin >> buf; // 用户输入 ofile << buf; // 将用户输入的字符存入文件中 } ofile.close(); ifstream ifile("test.txt"); // 输入文件流是将文件中的内容显示到屏幕上,对文件执行读操作 while (!ifile.eof()){ char ch; ifile.get(ch); if (!ifile.eof()){ cout << ch; } } cout << endl; ifile.close(); return 0; }
写文件文件
文本文件是程序开发经常用到的文件,使用记事本程序就可以打开文本文件,文本文件以txt作为扩展名,其实上一节已经使用 ifstream和ofstream 类创建并写入了文本文件,这一节主要应用fstream来写入文本文件。
#include <iostream> #include <fstream> using namespace std; int main() { fstream file("test.txt", ios::out); if (!file.fail()) { cout << "start write " << endl; file << "name" << " "; file << "sex" << " "; file << "age" << " "; } else { cout << "can not open " << endl; } file.close(); return 0; }
读文本文件
#include <iostream> #include <fstream> using namespace std; int main() { fstream file("test.txt", ios::in); if (!file.fail()) // 文件是否读取失败 { while (!file.eof()) // 不失败就循环读取文件中的内容 { char buf[128]; // 定义一个字符数组 file.getline(buf, 128); // 使用 getline 方法读取 128个字符 cout << buf; cout << endl; } } else { cout << "can not open " << endl; } file.close(); return 0; }
二进制文件的读写
文本文件中的数据都是ASCII码,如果要读取图片的内容,就不能使用读取文件文件的方法了,以二进制的方式读写文件,需要使用 ios::binary 模式 。
#include <iostream> #include <fstream> using namespace std; int main() { char buf[50]; fstream file; file.open("test.dat", ios::binary | ios::out); for (int i = 0; i < 2; i++) { memset(buf, 0, 50); // void *memset(void *str, int c, size_t n) 复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。 cin >> buf; file.write(buf, 50); file << endl; } file.close(); file.open("test.dat", ios::binary | ios::in); while (!file.eof()) { memset(buf, 0, 50); file.read(buf, 50); if (file.tellg() > 0) cout << buf; } cout << endl; file.close(); return 0; }
实现文件复制
用户在进行程序开发时,有时候需要复制等操作,下面就介绍用于复制文件的方法
#include <iostream> #include <fstream> using namespace std; int main() { ifstream infile; ofstream outfile; char name[20]; char c; cout << "请输入文件:" << "\n"; cin >> name; infile.open(name); if (!infile){ cout << "文件打开失败!"; exit(1); } strcat(name,"复本"); cout << "start copy" << endl; outfile.open(name); if (!outfile){ cout << "无法复制"; exit(1); } while (infile.get(c)) { outfile << c; } cout << "start end" << endl; infile.close(); outfile.close(); return 0; }
12.4 文件指针移动操作
在读写文件的过程中,有时候用户可能不需要对整个文件进行读写,而是对指定位置的一段数据进行读写操作,这时,就需要通过移动文件指针来完成。
文件错误与状态
在 I/O 流的操作过程中可能出现各种错误,每个流都有一个状态标志字,以指示是否发生了错误及出现了那种类型的错误,这种处理技术与格式控制标志字是相同的。ios类定义了以下枚举类型
enum io_state { goodbit = 0x00, // 不设置任何位,一切正常 eofbit = 0x01, // 输入流已经结束,无字符可读入 failbit = 0x02, // 上次读/写操作失败,但流仍可使用 badbit = 0x04, // 视图进行无效的读/写操作,流不可再用 bardfail = 0x80 // 不可恢复的严重错误 };
对应于标志字各状态位,ios类还提供了以下成员函数来检测或设置流的状态。
int rdstate(); int eof(); int fail(); int bad(); int good(); int clear(int flag = 0);
文件的追加
在写入文件时,有时候用户根据需要不会一次性写入全部数据,而是在写入一部分数据以后,再根据条件不断的向文件中追加写入。
#include <iostream> #include <fstream> using namespace std; int main() { ofstream ofile("test.txt",ios::app); // 文件的打开方式设置为app,表示追加 if (!ofile.fail()) { cout << "start write" << endl; ofile << "Mary"; ofile << "girl"; ofile << "20"; } else{ cout << "can not open"; } return 0; }
文件结尾的判断
在操作文件时,经常需要判断文件是否结束,使用 eof() 可以判断文件是否已经到达文件末尾,另外也可以通过其他方法来判断是否到达文件的末尾。例如使用流的 get() 方法。
#include <iostream> #include <fstream> using namespace std; int main() { ifstream ifile("test.txt"); if (!ifile) { cerr << "open fail" << endl; } char ch; // 使用 get() 判断 while (ifile.get(ch)) { cout << ch; } cout << endl; ifile.close(); // 使用 eof() 判断 ifstream file("test.txt"); if (!file.fail()) { while (!file.eof()) { char ch; file.get(ch); if (!file.eof()) cout << ch; } file.close(); } return 0; }
在指定位置读写文件
要实现在指定位置读写文件的功能,首先要了解文件指针操作的相关函数。
- seekg:位移字节数,相对位置用于输入文件中指针的移动。
- seekp:位移字节数,相对位置用于输出文件中指针的移动。
- tellg:用于查找输入文件中的文件指针位置。
- tellp:用于查找输出文件中的文件指针位置。
位移字节数是移动指针的位移量
- ios::beg:文件头部
- ios::end:文件尾部
- ios::cur:文件指针的当前位置
#include <iostream> #include <fstream> using namespace std; // 输出空格在文件中的位置 int main() { // name1 sex1 age1 Marygirl20Marygirl20 ifstream ifile("test.txt"); if (!ifile.fail()) { while (!ifile.eof()) { char ch; streampos sp = ifile.tellg(); // 查找输入文件中的文件指针位置 ifile.get(ch); if (ch == ' ') { cout << "position:" << sp; cout << " is blank" << endl; } } } return 0; }
#include <iostream> #include <fstream> using namespace std; int main() { ifstream ifile; char cFileSelect[20]; cout << "input filename"; // 需要用户输入一个文件名 cin >> cFileSelect; ifile.open(cFileSelect); // 打开相应的文件 if (!ifile) { cout << cFileSelect << "can not open" << endl; return 0; } ifile.seekg(0, ios::end); // 将指针移动到文件的末尾 int maxpos = ifile.tellg(); // 获取文件的长度 int pos; cout << "Position: "; // 需要用户输入一个位置 cin >> pos; if (pos > maxpos) // 判断用户输入的位置是否超过了文件长度 { cout << "is over file length" << endl; // 如果超过文件长度就不进行操作 } else { char ch; // 如果没有超过文件长度,就将指针移动到用户输入的位置 ifile.seekg(pos); ifile.get(ch); // 获得位置下的字符,并输出出来 cout << ch << endl; // test.txt www.mingrisoft.com 第5个字符:i } ifile.close(); return 0; }
12.5 文件和流的关联和分离
一个流对象可以在不同时间表示不同文件。在构造一个流对象时,不用将流和文件绑定。使用流对象的 Open 成员函数动态与文件关联,如果要关联其它文件就调用 close 成员函数关闭当前文件与流的连接,再通过 open 成员函数建立与其它文件的连接。
#include <iostream> #include <fstream> using namespace std; int main() { const char *filename = "test.txt"; fstream iofile; iofile.open(filename, ios::in); if (iofile.fail()) { iofile.clear(); iofile.open(filename, ios::in | ios::out | ios::trunc); // ios::trunc 如果文件存在就覆盖掉 } else{ iofile.close(); iofile.open(filename, ios::in | ios::out | ios::ate); // ios::ate 如果文件不存在则创建 } if (!iofile.fail()) { iofile << "我是新加入的"; iofile.seekg(0); while (!iofile.eof()) { char ch; iofile.get(ch); if (!iofile.eof()) cout << ch; } cout << endl; } return 0; }
12.6 删除文件
#include <iostream> #include <fstream> using namespace std; int main() { char file[50]; cout << "input file name: " << endl; cin >> file; if (!remove(file)) { cout << "The file:" << file << "已删除" << endl; } else { cout << "The file:" << file << "删除失败" << endl; } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号