

机器学习之决策树
机器学习之决策树的构建与剪枝
最近在面试中被问到决策树的知识,当时一脸懵逼,内心OS:“什么?我明明找的是计算机视觉算法岗位,决策树什么的除了刚入学看过一点,现在也全忘了啊!”,于是面试毫无意外的挂掉了。不过一码归一码,我下决心再把机器学习的相关知识复习起来,增加自己相关能力的同时以备不时之需。好了,闲言少叙,直接进入正文。决策树是一种有监督的机器学习算法,下面我们将从决策树的构建,剪枝以及特殊值的处理三个方面来进行整体介绍。为了方便举例,我们创建如下数据集便于后续说明。
| 编号 | 天气 | 温度 | 湿度 | 有风 | 适合玩耍 |
|---|---|---|---|---|---|
| 1 | 晴朗 | 85 | 85 | 否 | 否 |
| 2 | 晴朗 | 80 | 90 | 是 | 否 |
| 3 | 阴天 | 82 | 86 | 否 | 是 |
| 4 | 下雨 | 70 | 96 | 否 | 是 |
| 5 | 下雨 | 68 | 80 | 否 | 是 |
| 6 | 下雨 | 65 | 70 | 是 | 否 |
| 7 | 阴天 | 64 | 65 | 是 | 是 |
| 8 | 晴朗 | 72 | 95 | 否 | 否 |
| 9 | 晴朗 | 69 | 70 | 否 | 是 |
| 10 | 下雨 | 75 | 80 | 否 | 是 |
| 11 | 晴朗 | 75 | 70 | 是 | 是 |
| 12 | 阴天 | 72 | 90 | 是 | 是 |
| 13 | 阴天 | 81 | 75 | 否 | 是 |
| 14 | 下雨 | 71 | 91 | 是 | 否 |
一、决策树的构建
在实际生活中,决策树的分类方式跟人的思考方式差不多,比如在找对象的时候,一个女生可以从各个方面对她的追求者进行判断,最终做出是否同意谈对象的决定,整个决策过程可以描述如下:
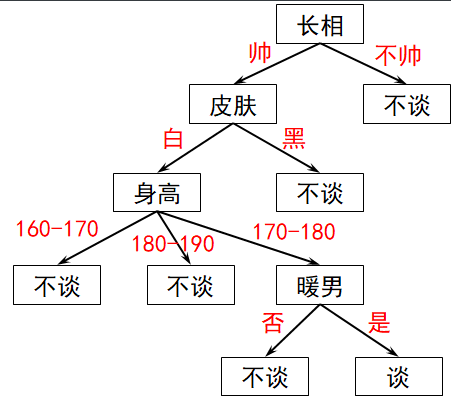
从上图可以看出,一颗决策树可以大致分为一个根节点,若干个内部节点和若干个叶子节点,其中叶子节点对应最终的决策结果,而每个根节点和内部节点对应一个属性测试。根节点包含样本全集,符合节点属性的样本被划分到该节点的下一级。具体如下图所示:

然后再对每个子集进行新一轮的划分,因此整个决策树的构建是一个递归过程,每个测试的结果或者是导出的最终结论,或者是进一步地判定问题都是在上一轮决策结果的限定范围之内。在决策树构建的过程中,最重要的步骤就是如何选择划分属性。比如在上一个例子中,为什么我首先选择天气因素作为第一轮的划分结果?为什么第二轮的结果中不同的子集 \(D_{1},D_{3}\) 考虑的划分属性不一样?因此在决策树划分属性的一个原则就是:使分支节点所包含的样本尽可能地属于同一类别,即节点的纯度越来越高。
1.1 ID3算法
要想同一个子集 \(D_{i}\) 中的样本纯度高,那么就意味着样本有序。而熵是衡量样本是否有序的一个重要指标,因此从直观上理解最优的划分标准就是:使划分后子集的信息熵最小。用数学语言描述如下:假设当前样本集合 \(D\) 中第 \(k\) 类样本所占的比例为 \(p_{k},(k=1,2,..,|\ell|)\),那么 \(D\) 的信息熵定义为:
因此,\(Ent(D)\) 的值越小,则样本 \(D\) 的纯度就越高。举个例子,在上述数据集 \(D = \{1,2,...,14\}\) 中,样本被分为 2 类,分别为 \(\{适合玩耍, 不适合玩耍\}\),所占的样本个数分别为 \(\{9,5\}\),因此信息熵为:
对于数据集 \(D\) 而言,属性有 5 个可能的取值 \(\{编号,天气,温度,湿度,有风\}\),假如选取 \(\{天气\}\) 属性来划分样本,则能划分出 \(\{晴朗,阴天,下雨\}\) 三个子集,每个子集下面有 \(\{5, 4, 5\}\) 个样本,因此选取 \(\{天气\}\) 属性来划分样本,划分后的样本信息熵为:
因此,划分样本后的信息增益为:
同理,我们依次计算按照其他剩余属性划分后的信息增益,然后选择信息增益最大的属性进行划分 \(a = argmax Gain(D,a)\)(即划分后子集的信息熵最小)。然后在每个子集中,按照同样的方式进行划分,最终得到整个决策树的模型。整个过程的数学语言描述为:
其中,\(D\) 代表待划分的子集,\(a\) 代表待划分的属性,\(v\) 代表划分属性 \(a\) 的类别,\(D^{v}\) 代表第 \(v\) 个分类子集中的样本个数,\(Ent(D^{v})\) 代表第 \(v\) 个分类子集的信息熵。
1.2 C4.5算法
在上述算法中,如果 \(编号\) 作为分类属性,那么分类后一共产生 14 个子集,每个子集中只包含一个样本,因此分类后的信息熵为 0,即子集的样本纯度最大, 信息增益为:
但是,这样的决策树显然不具有泛化能力,无法对新的样本进行有效地预测,产生过拟合的现象。因此,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,\(C4.5\) 算法对 \(ID3\) 算法进行改进,使用信息增益率来选择最优划分属性。信息增益率定义为:
直观上理解,属性 \(a\) 分类后的类别越多,则 \(IV(a)\) 越大,增益率越低。所以 \(C4.5\) 算法在一定的基础上提升了 \(ID3\) 算法的泛化性。
1.3 Gini 指数
\(CART\) 决策树使用基尼指数来选择划分属性,首先定义基尼值来衡量数据集 \(D\) 的纯度:
直观来说,\(Gini(D)\) 反映了从数据集 \(D\) 中随机抽取两个样本,其类别标记不一致的概率,因此 \(Gini(D)\) 越小,则数据集 \(D\) 的纯度越高。因此 \(Gini\) 指数定义为:
于是我们的目标就是在属性集合中选择划分后基尼指数最西奥德属性作为最优划分属性。
二、剪枝处理
剪枝是决策树学习算法中应对 “过拟合” 的主要手段,因为在决策树学习过程中,为了尽可能正确分类训练样本,节点划分过程不断重复,有时会造成决策树分支过多,这事就可能因为训练样本学习的过好以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合,因此剪枝就是通过主动去掉一些分支来降低过拟合的风险。剪枝的基本策略有预剪枝和后剪枝。
2.1 预剪枝
预剪枝是指在决策树生成的过程中,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升(即决策树在验证集上的准确率),则停止划分并将当前节点标记为叶节点。预剪枝使得决策树的很多分支都没有 “展开”,这不仅降低了过拟合的风险,还显著减少了决策树训练时间和测试时间的开销。但是, 有些分支的当前划分虽然不能提升泛化性能,其后续的划分却有可能导致性能提高。
2.2 后剪枝
后剪枝先从训练集生成一棵完整的决策树,然后自底向上地对决策树中的所有非叶节点进行考察,如果该节点没有提升泛化性,则更新为叶子节点。后剪枝决策树欠拟合的风险很小,泛化能力强,但是其训练时间开销比未剪枝和预剪枝的决策树大很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号