


一文详解机器学习的判别指标(精准率,召回率)
其实大部分的评价指标比如误识率,拒识率等都是根据TP,FP,FN,TN计算出来的,为了方便起见,把他们的关系表示为下表:
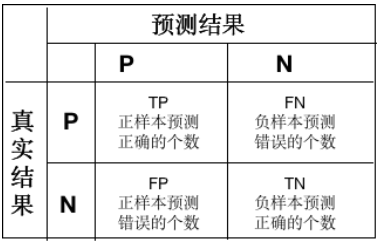
为了更好地理解,我把正负样本记做好人和坏人,那么:
- TP表示预测为正类的样本中实际也为正样本的个数(本来是好人,预测也是好人)
- FP表示预测为正类的样本中实际为负样本的个数(把坏人当成了好人)
- FN表示预测为负类的样本中实际为正样本的个数(把好人当成了坏人)
- TN表示预测为负类的样本中实际也为负样本的个数(本来是坏人,预测也是坏人)
那么我们可以得到两个全局的评价指标:
由于在不同的任务中,对指标的侧重点不一样,所以仅使用全局的评价指标并不能完全代表考虑优先级。比如在抓小偷时,没有百分百把握不能轻易动手,因此就要FP尽可能的小。然而在疾病筛查过程中,即使有很小的概率,也不能忽略,因此FN也要尽可能小。所以在不同场景下判断指标出现了偏向,所以又多出两个衍生的评价指标用来适应不同场景的需求:
其中,\(TAR\) 表示预测的正类样本占总的正类样本的比例,也叫 \(TPR\) ,查全率,召回率;\(FAR\) 表示把坏人当成好人的样本占总坏人的比例,也叫误识率,\(FRR\),\(FMR\) 等。
值得注意的是,\(TAR\) 与 \(FAR\) 两者之间没有明确的定量关系,通过 \(ROC\),\(DET\) 等曲线来描述。与其他曲线不同的是,\(ROC\) 和\(DET\) 曲线的横纵坐标之间并不是因变量与自变量的关系,他们都是阈值 threshold 的因变量。要想理解这个事情,首先要明白threshold是什么。
以声纹识别为例,将 \(M\) 个待检测的声纹信息与 \(N\) 个声纹库的声纹信息分别编码后进行匹配,计算余弦相似度,我们肯定希望相同的声源之间的相似度更高,而不同的声源之间的相似度很低。那么这个相似度就可以理解为threshold。比如:设置的阈值为0,那么所有相似度大于0的都可以看成是相同的声源,所以 \(TP\) 和 \(FP\) 都接近1;同理,设置的阈值为1,那么所有相似度大于1的都可以看成是相同的声源,所以 \(TP\) 和 $ FP$ 都接近0. 当阈值变大时:
- \(TP\) 减少:因为要求变高了,容易把好人当成坏人(游走在道德边缘的这些)
- \(FN\) 增加:因为要求变高了,所以好人被当成坏人的概率变大了
- \(TN\) 增加:因为要求变高了,能筛除更多冒充好人的人
- \(FP\) 减少:因为要求变高了,预测错的概率就变低了,把坏人当做好人的概率变少了
所以 \(TAR\) 与 \(FAR\) 同向变动。根据这个原理以threshold为自变量,将 \(FAR\) 与 \(TAR\) 作为横纵坐标,绘制出了 \(ROC\) 曲线。在 \(ROC\)曲线中,横轴代表 \(FAR\),纵轴代表 \(TAR\),\(ROC\) 曲线下方的面积代表一个判别器的优劣,面积越大,判别器越好反之越差。当 \(ROC\) 曲线是下图中的虚线时,相当于判别器没有效果,因为在虚线上的任何点,无论在任何threshold下,\(FAR\) 与 \(TAR\) 都是相同的,也就是说猜对与猜错各一半,模型没有预测价值。在 \(ROC\) 曲线上,等错误率(ERR)是 \(FAR\) 和 \(TAR\) 的一个平衡点,等错误率的值越低,表示算法的性能越好。
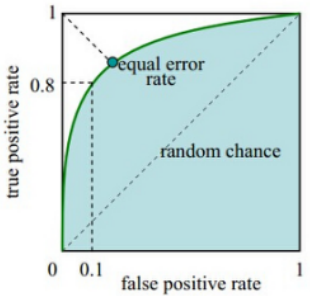
除了 \(FAR\) 与 \(TAR\) 外,还有一些其他衍生出来的判别指标,比如:
- \(FRR=1-TAR\):这个没什么好说的,TAR的逆版本,主要用来绘制DET曲线
- \(PRE=TP/(TP+FP)\):这个也叫精确率,表示预测正确的正样本在预测为正类的样本中占的比例。
因为 \(FAR\) 与 \(TAR\) 的变化同向,所以通过 \(FAR\) 与 \(FRR\) 来绘制 \(DET\) 曲线,能够看出此消彼长的关系:
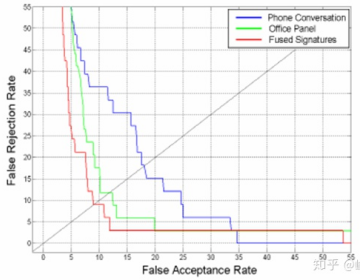
\(ERR\) 就是 \(y=x\) 与 \(DET\) 曲线的交点处。与 \(ROC\) 曲线中的描述一致。因为在 \(ROC\) 中,\(ERR\) 就是 \(FAR+TAR=1\) 的交点处。而在 \(DET\) 中,\(ERR\) 同样是 \(FAR=FRR\) 处,因此 \(FAR=1-TAR\) 。习惯上,\(FAR\) 与 \(FRR\) 的关系也可以表示为下图所示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号