

1-4.表的创建、修改\数据类型\字段约束(制表三范式)
前面提到,在创建表之前,一定要先创建用来存储表的数据库。运行 CREATE DATABASE 语句就可以在 RDBMS 上创建数据库了。语法:CREATE DATABASE <数据库名称>; 例我们要创建一个名字为 shop 的数据库,语法:CREATE DATABASE shop;
此外,数据库名称、表名以及列名都要使用半角字符(英文字母、数 字、符号)
表的创建(CREATE TABLE语句)
CREATE TABLE <表名>
(<列名1> <数据类型> <该列所需约束>,
<列名2> <数据类型> <该列所需约束>,
<列名3> <数据类型> <该列所需约束>,
<列名4> <数据类型> <该列所需约束>,
.
.
.
<该表的约束1>, <该表的约束2>,……);
例如我们要创建下面这个图表
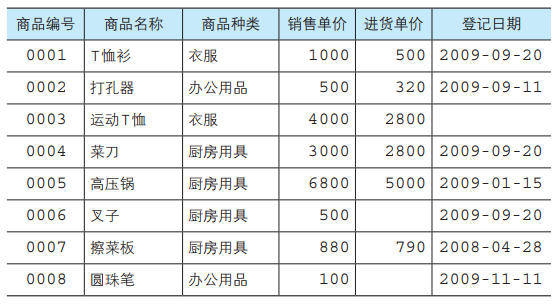
代码如下:

我们只能使用半角英文字母、数字、下划线(_)作为数据库、表和 列的名称 。例如,不能将 product_id 写成 product-id,因为标 准 SQL 并不允许使用连字符作为列名等名称。$、#、? 这样的符号同样 不能作为名称使用。
数据类型的指定
Product 表所包含的列,定义在 CREATE TABLE Product( ) 的括号中。列名右边的 INTEGER 或者 CHAR 等关键字,是用来声明该 列的数据类型的,所有的列都必须指定数据类型。
四种基本的数据类型:
INTEGER型
用来指定存储整数的列的数据类型(数字型),不能存储小数。
CHAR型
CHAR 是 CHARACTER(字符)的缩写,是用来指定存储字符串的列 的数据类型(字符型)。可以像 CHAR(10) 或者 CHAR(200) 这样,在 括号中指定该列可以存储的字符串的长度(最大长度)。字符串超出最大 长度的部分是无法输入到该列中的。
字符串以定长字符串 的形式存储在被指定为 CHAR 型的列中。所谓 定长字符串,就是当列中存储的字符串长度达不到最大长度的时候,使用半 角空格进行补足。例如,我们向 CHAR(8) 类型的列中输入 'abc'的时候, 会以 'abc '(abc 后面有 5 个半角空格)的形式保存起来。
VARCHAR型
同 CHAR 类型一样,VARCHAR 型也是用来指定存储字符串的列的 数据类型(字符串类型),也可以通过括号内的数字来指定字符串的长度(最 大长度)。但该类型的列是以可变长字符串 的形式来保存字符串的。定 长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串 不同,即使字符数未达到最大长度,也不会用半角空格补足。例如,我们 向 VARCHAR(8) 类型的列中输入字符串 'abc' 的时候,保存的就是字 符串 'abc'。
DATE型
用来指定存储日期(年月日)的列的数据类型(日期型)。
约束的设置
约束是除了数据类型之外,对列中存储的数据进行限制或者追加条件 的功能。Product 表中设置了两种约束。
数据类型的右侧设置了 NOT NULL 约束。NULL 是代表空白(无 记录)的关键字 。在 NULL 之前加上了表示否定的 NOT,就是给该列 设置了不能输入空白,也就是必须输入数据的约束(如果什么都不输入 就会出错)。
这样一来,Product 表的 product_id(商品编号)列、product_ name(商品名称)列和 product_type(商品种类)列就都成了必须 输入的项目。
另外,在创建 Product 表的 CREATE TABLE 语句的后面,还有 下面这样的记述。
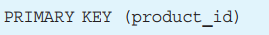
这是用来给 product_id 列设置主键约束的。所谓键,就是在指 定特定数据时使用的列的组合。键种类多样,主键(primary key)就是可 以特定一行数据的列 。也就是说,如果把 product_id 列指定为主键, 就可以通过该列取出特定的商品数据了。
反之,如果向 product_id 列中输入了重复数据,就无法取出唯一的特定数据了(因为无法确定唯一的一行数据)。这样就可以为某一列 设置主键约束了。
自增长策略(AUTO_INCREMENT)

有时候我们向表中插入数据时,可能表的记录很多(几万条),但是插入的时候有主键约束,如果与之前插入的主键约束重复,则会插入失败,为了避免这种情况,可以在创建表的时候在主键约束后面加一个AUTO_INCREMENT。
它可以在主键列自动生成数据,依次生成(如:1、2、3.....),而且插入主键列的时候可以直接输入“NULL”,这都是没有任何影响的。
唯一键(UNIQUE)

这个键可以控制值的唯一性,就说设置了这个约束后,插入这一列的数据的时候,插入的值是不可以重复的,但是插入NULL的时候是可以重复的。
外界约束(FOREIGN KEY (列名) REFERENCES (表名(列名)))

有时候我们向一个表中插入数据的时候,很有可能和另外一张表有联系,这样也就容易产生错误,为了是两张表建立对应性,避免输入错误数据,我们此时就需要对两个表之间有联系的列设置外键约束了。
但是需要注意的是,设置外界约束的两个列必须是各自表中的主键列。
关于MySQL当中字段的数据类型?以下只说常见的
int 整数型(java中的int)
bigint 长整型(java中的long)
float (或 decinal) 浮点型(java中的float double)
char 定长字符串(String)
varchar 可变长字符串(StringBuffer/StringBuilder)
date 日期类型 (对应Java中的java.sql.Date类型)
BLOB 二进制大对象(存储图片、视频等流媒体信息) Binary Large OBject (对应java中的Object)
CLOB 字符大对象(存储较大文本,比如,可以存储4G的字符串。) Character Large OBject(对应java中的Object)
字段备注
在创建表的时候每个字段末尾可以增加备注,以便日后清晰此列内容
语法:在约束后面添加 comment 备注内容
约束(constraint)
在创建表的时候,可以给表的字段添加相应的约束,添加约束的目的是为了保证表中数据的
合法性、有效性、完整性。
常见的约束有哪些呢?
非空约束(not null):约束的字段不能为NULL
唯一约束(unique):约束的字段不能重复
主键约束(primary key):约束的字段既不能为NULL,也不能重复(简称PK)
外键约束(foreign key):...(简称FK)
检查约束(check):注意Oracle数据库有check约束,但是mysql没有,目前mysql不支持该约束。
非空约束 not null
not null可以为多个列添加约束,创建表时加到字段类型后面。
not null虽然可以为多个列添加约束,但是不可以设置联合约束比如:not null(A列,B列),只能挨个列添加。
唯一性约束(unique)
唯一约束修饰的字段具有唯一性,不能重复。但可以为NULL。
unique可以单列添加,也可以设置多个列添加,更可以绑定2个或2个以上的列进行合并唯一约束(这样不推荐,表现形式在表的末尾添加约束:unique(A列,B列))
主键约束(primary key)
主键约束修饰的字段具有唯一性,不能重复而且不可以为NULL。
primary key可以单列添加,也可以绑定2个或2个以上的列进行合并主键约束(这样不推荐,表现形式在表的末尾添加约束:primary key(A列,B列))
主键有什么作用?
- 表的设计三范式中有要求,第一范式就要求任何一张表都应该有主键。
- 主键的作用:主键值是这行记录在这张表当中的唯一标识。(就像一个人的身份证号码一样。)
主键的分类?
根据主键字段的字段数量来划分:
单一主键(推荐的,常用的。)
复合主键(多个字段联合起来添加一个主键约束)(复合主键不建议使用,因为复合主键违背三范式。)
根据主键性质来划分:
自然主键:主键值最好就是一个和业务没有任何关系的自然数。(这种方式是推荐的)
业务主键:主键值和系统的业务挂钩,例如:拿着银行卡的卡号做主键,拿着身份证号码作为主键。(不推荐用)
最好不要拿着和业务挂钩的字段作为主键。因为以后的业务一旦发生改变的时候,主键值可能也需要
随着发生变化,但有的时候没有办法变化,因为变化可能会导致主键值重复。
一张表的主键约束只能有1个。(必须记住)
mysql提供主键值自增:(auto_increment)
Oracle当中也提供了一个自增机制,叫做:序列(sequence)对象。
外键约束(foreign key)
添加语句:foreign key(子表外键列) references 父表名(父表列)
顺序要求:
删除数据的时候,先删除子表,再删除父表。
添加数据的时候,先添加父表,在添加子表。
创建表的时候,先创建父表,再创建子表。
删除表的时候,先删除子表,在删除父表。
外键可以为NULL。
被引用的字段不一定是主键,但至少具有unique约束。
MySQL支持外键的存储引擎只有InnoDB , 在创建外键的时候, 要求父表必须有对应的索引 , 子表在创建外键的 时候, 也会自动的创建对应的索引。
下面两张表中 , country_innodb是父表 , country_id为主键索引,city_innodb表是子表,country_id字段为外 键,对应于country_innodb表的主键country_id 。
create table country_innodb(
country_id int NOT NULL AUTO_INCREMENT,
country_name varchar(100) NOT NULL,
primary key(country_id) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table city_innodb(
city_id int NOT NULL AUTO_INCREMENT,
city_name varchar(50) NOT NULL,
country_id int NOT NULL,
primary key(city_id),
key idx_fk_country_id(country_id),
CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_innodb(country_id)
ON DELETE RESTRICT ON UPDATE CASCADE )
ENGINE=InnoDB DEFAULT CHARSET=utf8;
在创建索引时, 可以指定在删除、更新父表时,对子表进行的相应操作,
包括 RESTRICT、CASCADE、SET NULL 和 NO ACTION。 RESTRICT和NO ACTION相同, 是指限制在子表有关联记录的情况下, 父表不能更新;
CASCADE表示父表在更新或者删除时,更新或者删除子表对应的记录;
SET NULL 则表示父表在更新或者删除的时候,子表的对应字段被SET NULL 。
针对上面创建的两个表, 子表的外键指定是ON DELETE RESTRICT ON UPDATE CASCADE 方式的, 那么在主表删 除记录的时候, 如果子表有对应记录, 则不允许删除, 主表在更新记录的时候, 如果子表有对应记录, 则子表 对应更新 。
MySQL On Delete和On Update
ON DELETE
restrict(约束):当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。
no action:意思同restrict.即如果存在从数据,不允许删除主数据。
cascade(级联):当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则也删除外键在子表(即包含外键的表)中的记录。
set null:当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)
ON UPDATE
restrict(约束):当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许更新。
no action:意思同restrict.
cascade(级联):当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则也更新外键在子表(即包含外键的表)中的记录。
set null:当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
注:NO ACTION和RESTRICT的区别:只有在及个别的情况下会导致区别,前者是在其他约束的动作之后执行,后者具有最高的优先权执行。
数据库设计三范式
什么是设计范式?
设计表的依据。按照这个三范式设计的表不会出现数据冗余。
三范式都是哪些?
第一范式:任何一张表都应该有主键,并且每一个字段原子性不可再分。
第二范式:建立在第一范式的基础之上,所有非主键字段完全依赖主键,不能产生部分依赖。
多对多?三张表,关系表两个外键。(换句话说就是表中不可以出现与主键无关的列(数据))
第三范式:建立在第二范式的基础之上,所有非主键字段直接依赖主键,不能产生传递依赖。
一对多?两张表,多的表加外键。(换句话说就是表中不可以出现与主键产生间接关系的列(数据))
提醒:在实际的开发中,以满足客户的需求为主,有的时候会拿冗余换执行速度。
一对一怎么设计?
一对一设计有两种方案:主键共享
相当于第二张表中的主键和第二张中的外键是同一列,并且他们都是第一张表的主键。
一对一设计有两种方案:外键唯一
相当于给第二张表添加一列外键,这列外键指向的是第一张表的主键,并且这列外键要设置唯一约束(uinque)
MySQL 字符串函数
|
函数 |
描述 |
实例 |
|
ASCII(s) |
返回字符串 s 的第一个字符的 ASCII 码。 |
返回 CustomerName 字段第一个字母的 ASCII 码: SELECT ASCII(CustomerName) AS NumCodeOfFirstChar FROM Customers; |
|
CHAR_LENGTH(s) |
返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 SELECT CHAR_LENGTH("RUNOOB") AS LengthOfString; |
|
CHARACTER_LENGTH(s) |
返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 SELECT CHARACTER_LENGTH("RUNOOB") AS LengthOfString; |
|
CONCAT(s1,s2...sn) |
字符串 s1,s2 等多个字符串合并为一个字符串 |
合并多个字符串 SELECT CONCAT("SQL ", "Runoob ", "Gooogle ", "Facebook") AS ConcatenatedString; |
|
CONCAT_WS(x, s1,s2...sn) |
同 CONCAT(s1,s2,...) 函数,但是每个字符串之间要加上 x,x 可以是分隔符 |
合并多个字符串,并添加分隔符: SELECT CONCAT_WS("-", "SQL", "Tutorial", "is", "fun!")AS ConcatenatedString; |
|
FIELD(s,s1,s2...) |
返回第一个字符串 s 在字符串列表(s1,s2...)中的位置 |
返回字符串 c 在列表值中的位置: SELECT FIELD("c", "a", "b", "c", "d", "e"); |
|
FIND_IN_SET(s1,s2) |
返回在字符串s2中与s1匹配的字符串的位置 |
返回字符串 c 在指定字符串中的位置: SELECT FIND_IN_SET("c", "a,b,c,d,e"); |
|
FORMAT(x,n) |
函数可以将数字 x 进行格式化 "#,###.##", 将 x 保留到小数点后 n 位,最后一位四舍五入。 |
格式化数字 "#,###.##" 形式: SELECT FORMAT(250500.5634, 2); -- 输出 250,500. |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号