

MySQL操作(二)
启动: mysql -u账号 -p密码
退出: exit;
创建数据库: CREATE DATABASE 库名;
显示所有数据库: show DATABASES;
进入数据库: use 库名;
查看当前数据库: select database();
创建表:
CREATE TABLE test_one(one_id INT NOT NULL AUTO_INCREMENT,one_name VARCHAR(100) NOT NULL,desc_s VARCHAR(10) NOT NULL,submission_date DATE,PRIMARY KEY ( one_id ))ENGINE=InnoDB DEFAULT CHARSET=utf8;
注:INT,DATE表示这个字段类型,NOT NULL表示不可为空,VARCHAR(100)字数限制,ENGINE使用的引擎,CHARSET设置编码
显示表: show TABLES;
删除表: DROP TABLE 表名; (前提是进入到了这个库)
插入数据:
INSERT INTO 表名 (runoob_title, runoob_author, submission_date) VALUES ("学习 PHP", "菜鸟教程", NOW());
读取数据表: select * from 表名;
整句查询:
SELECT * FROM 表名;
注:*表示所有,还可以使用字段名,来限制返回的字段
更新:
UPDATE 表名 SET runoob_title='学习 C++' WHERE runoob_id=1;
注:WHERE 后面是子句,都表示为条件,是紧随FROM子句后面的
删除数据: DELETE FROM 表名 WHERE runoob_id=3;
显示表结构: DESCRIBE 表名
排序:(ORDER BY[ASC, DESC],通常在SELECT语句的结尾),可以设置多个字段参与排序:
SELECT * from 表名 ORDER BY 字段1 字段2 ASC; (会先排序字段1 然后在排序字段2)
分组: GROUP BY ,分组也可以使用多key。
正则 REGEXP 可以进行正则匹配,跟在匹配的字段名后使用。
子查询:例句:secelt * from A where name = (select job_name from B where last_name="HA");
单一子查询就是让某个条件等于另一个查询出来的结果
多行子查询,通常使用IN,ANY,ALL,进行连接
并且子查询可以返回F/T,还可以使用比较等符号进行条件补充。
函数:
Mysql支持的四大操作:
数据定义语句:DDL,作用对象是库、表、列,创建、删除、修改、库或表结构,对数据库或表的结构操作
数据操作语句:DML,作用对象是数据库记录(数据),增、删、改,对表记录进行更新(增、删、改)
数据控制语句:DCL,作用对象是数据库,用来定义访问的权限和安全级别,对用户的创建,及授权
数据库查询语句:DQL,作用查询的对象,select 语句
事务控制语句:TCL,作用对象是数据操作,用来维护数据的一致性(COMMIT,ROLLBACK,SAVEPOINT(事务保存点))
事务:
事务常识:
BEGIN 或 START TRANSACTION 显式地开启一个事务;
COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK 回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier 把事务回滚到标记点;
SET TRANSACTION 用来设置事务的隔离级别。
事务的五个隔离:
Read Uncommitted(读取未提交内容)在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用
因为它的性能也不比其他级别好多少。
Read Committed(读取提交内容)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事
务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在
该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不
过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务
又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控
制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个
读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
实际操作:
1,场景,两个服务器同时对一个数据库进行操作,A服务器手动提交事务,B服务器默认的自动提交事务。
a:A在开启事务的情况下,插入一条数据,B则查不到这数据,A可以查到。因为A事务虽然没有提交,但是数据已经保存到内存或者磁盘中去,
这是因为事务的隔离性,并且数据会有个锁
b:B提交新数据之后,A还是查不到,这是因为A执行DML操作,对其都是不可见的,只有等事务结束之后才可见
c:A执行新增加数据,B查不到,但是A新建一张表之后(注意是在事务没有提交的新建一张表),B就可以查到,这是因为A执行了DDL操作触发了 隐式提交
其中 DROP 在事务中执行的时候,事务不结束DROP就会被阻塞
注意事项以及经验:
1,SQL语言大小写不敏感,并且可以写在一行或者多行,各子句一般要分行写
2,日期和字符只能在单引号中出现
3,关于mysql的隐式转换,举例:查询的时候两种情况分别是要被查询的字段的类型是int的时候和要被查询的字段是str的时候,输入的字段类型是int
这样也会出现两种情况,在查询之前,sql会先做比较,如果被查询的字段是int,输入的字段是int和str,就会只用索引,因为输入的str被转化为了
int,如果被查询的字段是str,输入的是int,那么就不会使用索引,因为这时候输入的int并不符合类型的要求,仅仅是被查询的字段被隐式转换了,
这时候又会出现很有意思的情况,例如被查询的字段是“0abc”,“abc”,“0+2”,当我们输入的条件是0的时候,这三条数据,都会返回,因为
“0abc”转化成int后分成了两部分,前面一部分就是0,“abc”转换成int后也是0,“0+2”转换成int后,因为中间有一个字符,所以就会变成三部
分,前面一部分也是0,所以在使用的时候,类型一定要准确
4,量级数据插入的时候,需要进行分批存储,不然会造成IO读写压力过大
5,所有的多表查询都是两张表进行join进行查询之后,拿到新的数据集之后和下一个表再次进行相同的操作
6,两张表查询的时候,会进行笛卡尔积操作,就是将两张表的数据,分别的条数进行相乘,引弦内部会进行去重,下方有笛卡尔积的计算
索引问题:
1,最左查询
数据库表设计准则:
1,字段的原子性,见字识意。
2,主健设计不要与业务逻辑有所关联。
3,动静分离。
4,外部关联最好用ID(自增的来说)。
运算符:
比较运算: =(等于),>(大于),<(小于),>=(大于且等于),<=(小于且等于),<>(不等于,等同于 != ),:=(赋值使用)
比较运算符(子句,跟在WHERE后面): BETWEEN ...AND... 在两个值之间(包含边界),
IN(set) 等于值列表中的一个,
LIKE 模糊查询
IS NULL 空值
逻辑运算: AND (逻辑并),OR(逻辑或), NOT (逻辑非)
连接方式:
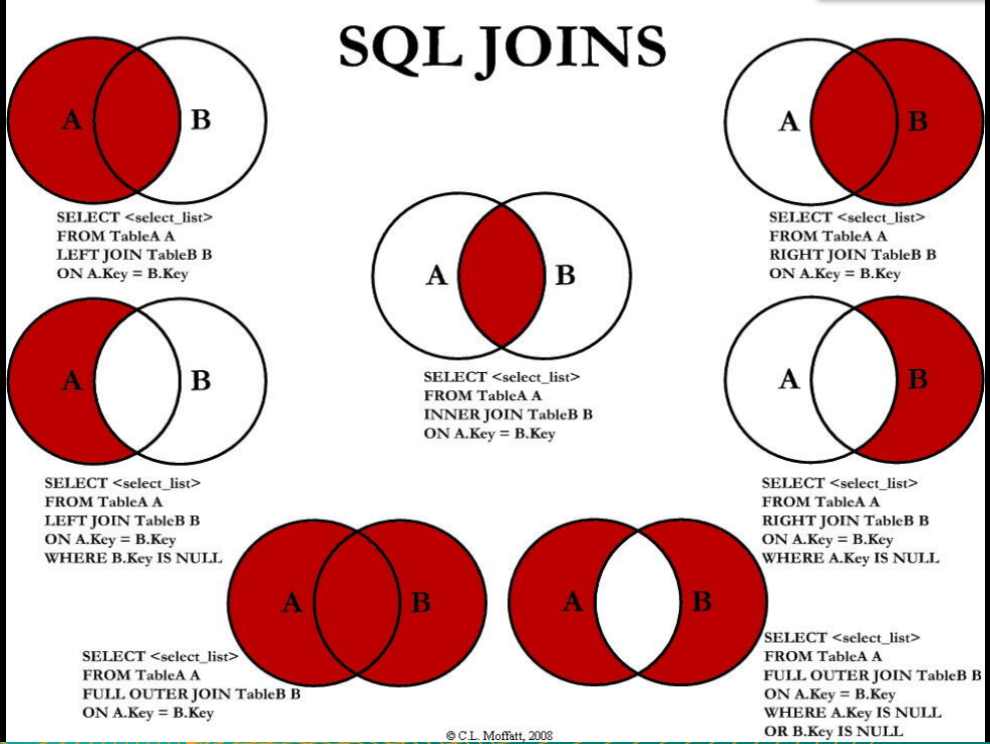
连接:左连接,右连接,内连接,左外连接,右外连接,满连接(全连接),交叉连接(去除公共部分)
约束:NOT NULL(非空约束,规定某个字段不能为空),UNIQUE (唯一约束规定某个字段在整个表中是唯一),PRIMARY KEY (主键,非空且唯一),FOREIGE KEY (外键),CHECK (检查约束),DEFAULT (默认值)
注 :可以根据需求,设置约束的范围,(单列,多列,表级)

笛卡尔集:
假设t1 = 5个数据,t2 = 7个数据,两个数据集合没有关系,那么select * from t1,t2会查出来多少个数据?
答案就是5*7=35个数据集,在没有关系的两张表中,为了不查漏数据,底层会做笛卡尔积运算,这就是数据冗余
更多高级后续更新......
