
2020未来网络SDN实验室纳新题:数据包异常检测
作业内容:数据中心的数据包异常检测
自我介绍:
-
郑林滢,032002342,计算机3班
-
性格
-
外向活泼,不怕生。常常主动开启话题,与人交流,icebreaker实锤
-
有点懒。比如做的ppt总是白底,比如其实这篇博客可以搞得更花里胡哨但我没有,还义正言辞这是极简主义;但是该做的事不会偷懒,必要的事情回去做,对自己有好处有收获的事情会额外去做
-
一点点完美主义,对自己要求有点高。有时做事情会更希望做到尽善尽美,周到而没有漏洞;但是这和我懒的本性是相违背的,这时候就会根据事情本身权衡
-
遇事急躁,但一直在努力改变。比如当遇到复杂事情的时候就把事情细分,知道要做什么事、怎么做,以降低焦虑
-
会思考,会规划,想得多,也想得细。比如就算是看网络上的口水小说也会思考文字之后的意义;比如这次作业布置伊始就开始规划每天的进度,然后准确踩在ddl上提交作业;比如如今十八岁就已经想好未来十年的规划,虽然未来变数极大,但未雨绸缪总是让人心安的
-
善于总结。看到大段材料总是想把它们简化,找共同点,或得出一个相对使用得结论,可能也只是因为懒,想找到规律性的东西来囊括一切
-
身上有一股狠劲。比如说今天给自己布置的任务没完成,就硬要求自己加班加点开夜车,写完才睡觉,但是当然也会结合自身情况调整任务,以继续明天高效学习
-
之前做事情总是三分热度,学琴也是,学刻橡皮章也是,也可能是因为对这些东西不是真正喜爱,看小说的兴趣倒是从来没有放下过
-
-
掌握的技术:暑假看翁恺老师网课学了C语言入门,之前会在csdn上写总结博客,其他课程跟着老师的进度学习,通过这次作业学会了github,如何查找资料,如何自主学习和一些网络方面的知识等等(后面会详细写到),收获良多
-
现在说研究方向个人感觉为时过早,因为我现今对于这个领域的了解有限,但随着学习的加深,应该会有自己的想法。通过这次作业,我对于所谓科研有了更深的了解,我想我能在实验室学到发现和解决问题的方法,创新、提出idea的能力以及自主学习的经验等等
作业链接
虚拟机 + ubuntu 安装过程
虚拟机+Ubuntu安装过程
(我的安装过程如同教程所示,就不再详细列出,私以为更重要的是该过程的收获(在下方列出))
- 心得/收获:
经过之前GitHub的学习,遇到新事物时更有方向地去搜索相应的资源(csdn/b站/百度)
看到难懂的步骤会静下心反复多看,而不是如之前一样看不懂就焦虑,一直无法成功的操作会去搜索博客寻找解决方法
通过Ubuntu的安装和之前GitHub的学习,对命令行的操作有了初步了解
虽然过程磕磕绊绊,但是安装成功后很有成就感
tcpdump抓包过程和数据清洗过程
-
心得/收获:
可以耐住性子看长篇的教程
对于命令行操作更加熟悉 -
不足:
在学TCPdump的时候意识到作业的核心应该是提出检测异常数据的方法,GitHub、虚拟机和tcpdump只是执行idea的手段,于是加快学习的速度,故tcpdump的实践偏少
检测异常数据的方法
异常数据:

类似二分法
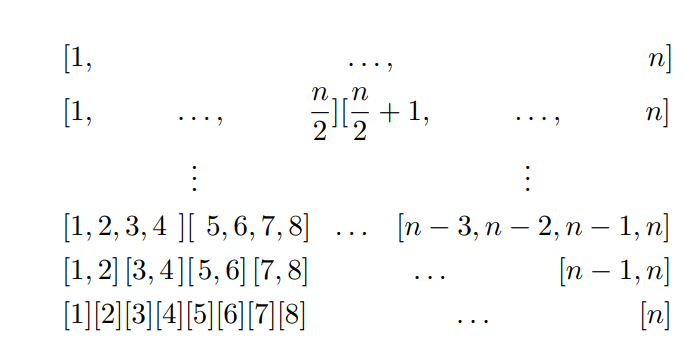
(灵感来源于论文Lecture 7: Heavy Hitters: the Count-Min Sketch中一个配图)
假设有1到n个数据包
先对半分,分别统计两个部分数据包的总字节数
取字节数大的一部分,再次对半分,再分别统计两部分数据包的字节数
重复以上步骤,直到只剩下最后一个数据包
此数据包即为heavy hitter
- 优点:相比于遍历,简化了一半的查找量
- 不足:
- 面对大量数据还是要花费大量时间
- 只能查询一个heavy hitter,而flow里可能不止一个heavy hitter,达不到检测top k的目的
- 检测精确度不够:
若8个数据包(1-8),大小分别为1,1,1,100,30,30,30,30
分组[1,1,1,100][30,30,30,30](A B)
假设包长大于60即为heavy hitter,则第4个数据包即为heavy hitter
但由于二分取总字节数大的部分,而A组(103)小于B组(120),取数值较大的B组,导致无法检测出真正的heavy hitter
- 总结:实用性低,需要改进
Sketch
对Sketch的了解:
CM-Sketch
MV-Sketch
-
为什么用sketch:
- 题目背景中要求检查高频率、大数据量的数据包,若是用数组一个一个储存数据不现实(单个数据数据量大,数据总数多,需要耗费大量存储空间),而用哈希则可以简化数据的纪录,符合内存限制
- 有实时性要求,若用数组遍历则容易超时,而哈希将多个相同数据投入一个桶中(合并),只需查询桶而不用查询单个数据
-
检测重流:数据总数m,找top k
- cm-sketch:遍历数组,找计数器值大于k/m的桶
- mv-sketch:遍历数组,找总计数器值vi,j大于k/m的桶,再对这些桶中的重流候选计数器进行查询,满足Ci,j>m/k的即为重流
-
cm-sketch与mv-sketch比较:
若有r个哈希函数,每个哈希函数中有w个桶- 时间上:cm遍历查询rw次,mv遍历查询r²w次
cm所花时间更少 - 内存上:cm每个桶中有一个计数器,mv用静态内存,每个桶中两个计数器,一个重流候选
- 特性上:mv可逆,即能得到重流的信息(五元组等),同时mv经历两遍查找,数据更准确
cm查询速度快,却不能保存重流数据
- 时间上:cm遍历查询rw次,mv遍历查询r²w次
-
综上,由于要找到top k个重流,故选用mv-sketch
学习了哪些新的技能/知识:
- 学会GitHub,装了虚拟机,TCPdump的安装和一些命令,命令行初体验
- 当接触陌生名词时,积累到一定的学习经验,归纳了查找/学习的顺序
- 查东西的时候先百度,知道这个东西是有什么作用 ,是干什么的(缩句成什么是什么,比如tcpdump是网络数据采集分析工具),具体是干什么的(定语)掠掉,在后续的深入了解中会知道的。(不然看到陌生的术语会头大然后不想读下去)
- 深入了解:先百度找博客,读不懂去b站找视频讲解(在博客和b站之间反复横跳)
- 接触英文论文,了解文章结构,对于某些公式的理解存在困难,但随着阅读过程有所缓解
- 习惯静下心来阅读长篇文章,遇到困难面向浏览器学习
-参考资料:
网页:
GitHub:https://www.cnblogs.com/jjlee/p/10305194.html
虚拟机安装:https://blog.csdn.net/zhaoxizxzx/article/details/109274858
tcpdump:https://blog.csdn.net/zhaoxizxzx/article/details/109275325
cm-sketch:
https://baike.baidu.com/item/哈希函数/9796422?fr=aladdin
https://blog.csdn.net/pipisorry/article/details/64126199
mv-sketch:https://www.sdnlab.com/23514.html
论文:
CS369G: Algorithmic Techniques for Big Data Spring 2015-2016
Lecture 7: Heavy Hitters: the Count-Min Sketch
Prof. Moses Charikar Scribes: Nicole Wein
MV-Sketch: A Fast and Compact Invertible Sketch
for Heavy Flow Detection in Network Data Streams
Lu Tang1, Qun Huang2, and Patrick P. C. Lee1
1Department of Computer Science and Engineering, The Chinese University of Hong Kong
2State Key Lab of Computer Architecture, Institute of Computing Technology, Chinese Academy of Sciences
问题
GitHub:
-
初始化用户名和邮箱的时候一直不成功,后来将我的命令一个字一个字对照教程发现--之前少了空格,从此再输入命令行特意关注空格
git config --global user.name "YOUR NAME" git config --global user.email "YOUR EMAIL" -
将本地仓库上传时,提示先是说缺少.git仓库,而我的文件夹里却有.git目录,搜索之后又出现更多错误提示信息
最后是重新创建了一个本地仓库才顺利上传,没弄明白之前不能上传的原因
虚拟机&Ubuntu
- 在官网下VMware的时候一直找不到windows版本,后来发现是因为浏览器自动将英文网页翻译成中文,windows被翻译成窗口浑然不觉
tcpdump
- 用apt-get命令安装时出现错误提示
E: Could not open lock file /var/lib/dpkg/lock-frontend - open (13: Permission denied) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), are you root?
搜索博客之后用rm -rf命令也无法解锁,后来模仿某些博客中sudo rm -rf命令,用sudo apt-get命令强制安装
一个专业问题
- 为什么静态内存会节约开销?
在看mv-sketch的时候提出的问题,网上找不到解释,故现在还没解决
在csdn上写过程总结时候的问题
-
学习一个新名词时,自己看懂了但没办法在博客上把事情讲明白:
当刚接触到一个新名词时,搜索博客学习总是看得云里雾里,但是当自己弄懂了,写博客的时候会发现,我会着重解释自己在学习过程中看不懂的部分,但如果是一位对这个知识完全陌生的学习者来看我的总结博客,也会看得云里雾里,也就是我没有把所有事情讲得通俗易懂,讲明白;等过一段时间之后自己再看,也会存在理解问题:“我当初是怎么理解的?” -
解决方法:不要偷懒,把博客写明白,现在以为容易理解的东西几个月之后或许会产生理解问题
总结:
-
这次作业在我看来不是特别满意,总的来说就是时间分配不恰当导致时间不够,同时思考也不够:
- 没有给出代码实现:留给代码的时间很少,本来想去GitHub上找个轮子跑一跑的,可是现在作业提交迫在眉睫,一会儿写完还有时间就去试一试
- idea部分还可以继续优化,但时间仓促,没有做到,对于所给的方法也没有给出误差分析
- 花了几天的时间看论文,刚开始不挑重点从头开始看,后来有所侧重但是看一点忘一点,没有及时总结,对论文所给出的方法的思考也不够
- 有了解计算机网络相关内容,但没有总结
-
但是从此次作业中我学到了很多:
- 从GitHub到虚拟机到tcpdump,越来越适应跟网上的经验贴学习,对于长篇文章也可以耐住性子细心阅读
- 首次接触到英文论文,认识到英语学习的重要性;从论文中学到了一些相关的术语,慢慢学会理解文章中的公式;了解文章的行文结构,知道哪里skim哪里scan哪里细读研究

