

推荐系统---深度兴趣网络DIN&DIEN
深度学习在推荐系统、CTR预估领域已经有了广泛应用,如wide&deep、deepFM模型等,今天介绍一下由阿里算法团队提出的深度兴趣网络DIN和DIEN两种模型
paper
DIN:https://arxiv.org/abs/1706.06978
DIEN:https://arxiv.org/abs/1809.03672
code
DIN:https://github.com/zhougr1993/DeepInterestNetwork
DIEN:https://github.com/mouna99/dien
DIN
常见的深度学习网络用于推荐或者CTR预估的模式如下:
Sparse Features -> Embedding Vector -> MLPs -> Sigmoid -> Output.
这种方法主要通过DNN网络抽取特征的高阶特征,减少人工特征组合,如wide&deep、deepFM的DNN部分均是采用这种模式,然而阿里的小组经过研究认为还有以下两种特性在线上数据中十分重要的,而当前的模型无法去挖掘
Diversity:用户在浏览电商网站的兴趣多样性。
Local activation: 由于用户兴趣的多样性,只有部分历史数据会影响到当次推荐的物品是否被点击,而不是所有的历史记录。
为了充分挖掘这些特性,联系到attention机制在nlp等领域的大获成功,阿里团队将attention机制引入推荐系统,在向量进入MLP之前先通过attention机制计算用户行为权重,让每个用户预测关注的兴趣点(行为向量)不同。
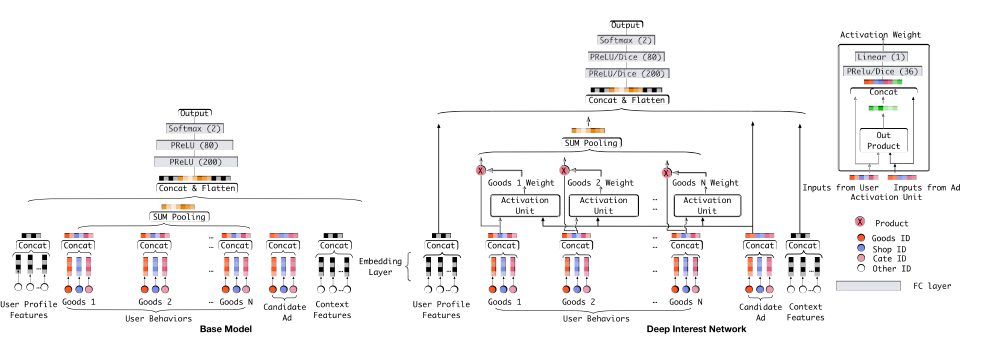
网络基本结构如上图,Base Model有一个很大的问题,它对用户的历史行为是同等对待的,没有做任何处理,这显然是不合理的。一个很显然的例子,离现在越近的行为,越能反映你当前的兴趣。因此,DIN模型对用户历史行为基于Attention机制进行一个加权
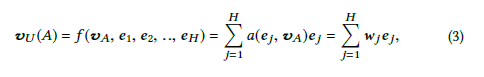

···
def din_fcn_attention(query, facts, attention_size, mask, stag='null', mode='SUM', softmax_stag=1, time_major=False, return_alphas=False, forCnn=False):
if isinstance(facts, tuple):
# In case of Bi-RNN, concatenate the forward and the backward RNN outputs.
facts = tf.concat(facts, 2)
if len(facts.get_shape().as_list()) == 2:
facts = tf.expand_dims(facts, 1)
if time_major:
# (T,B,D) => (B,T,D)
facts = tf.array_ops.transpose(facts, [1, 0, 2])
mask = tf.equal(mask,tf.ones_like(mask))
facts_size = facts.get_shape().as_list()[-1] # Hidden size for rnn layer
query = tf.layers.dense(query,facts_size,activation=None,name='f1'+stag)
query = prelu(query)
queries = tf.tile(query,[1,tf.shape(facts)[1]]) # Batch * Time * Hidden size
queries = tf.reshape(queries,tf.shape(facts))
din_all = tf.concat([queries,facts,queries-facts,queries*facts],axis=-1) # Batch * Time * (4 * Hidden size)
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att' + stag)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att' + stag)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att' + stag) # Batch * Time * 1
d_layer_3_all = tf.reshape(d_layer_3_all,[-1,1,tf.shape(facts)[1]]) # Batch * 1 * time
scores = d_layer_3_all
key_masks = tf.expand_dims(mask,1) # Batch * 1 * Time
paddings = tf.ones_like(scores) * (-2 ** 32 + 1)
if not forCnn:
scores = tf.where(key_masks, scores, paddings) # [B, 1, T] ,没有的地方用paddings填充
# Activation
if softmax_stag:
scores = tf.nn.softmax(scores) # [B, 1, T]
# Weighted sum
if mode == 'SUM':
output = tf.matmul(scores,facts) # Batch * 1 * Hidden Size
else:
scores = tf.reshape(scores,[-1,tf.shape(facts)[1]]) # Batch * Time
output = facts * tf.expand_dims(scores,-1) # Batch * Time * Hidden Size
output = tf.reshape(output,tf.shape(facts))
if return_alphas:
return output,scores
else:
return output
···
以上是其中attention的核心代码
DIEN
在用DIN解决了用户的兴趣不同的问题后,模型还存在以下问题
1)用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性
2)通过用户的显式的行为来表达用户隐含的兴趣,这一准确性无法得到保证。
为了解决以上两个问题,阿里算法又提出了DIEN模型
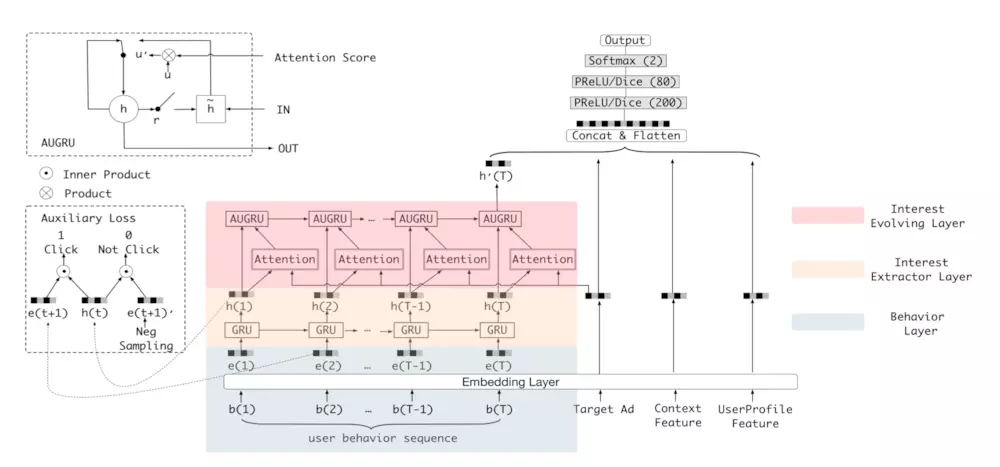
对比DIN的结构,主要区别在于增加了兴趣抽取层和兴趣进化层(RNN)
作者将用户行为表示为序列,利用GRU来抽取兴趣状态

在此之后,为了进一步保证兴趣抽取的准确,作者设计了一个二分类网络,用下一刻的真实行为加GRU的状态拼接作为正例,抽取的假行为拼接GRU状态作为负例,输入二分类网络
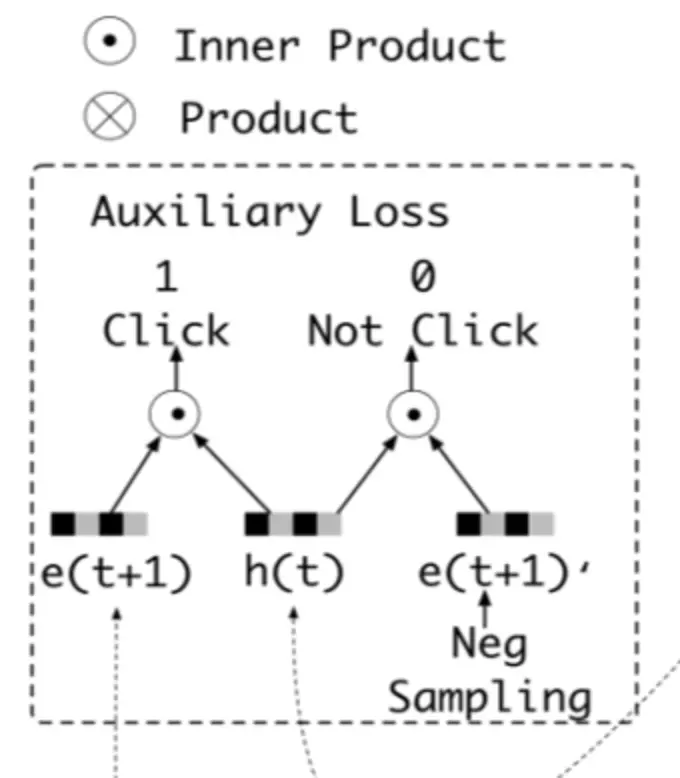
同时设计损失函数
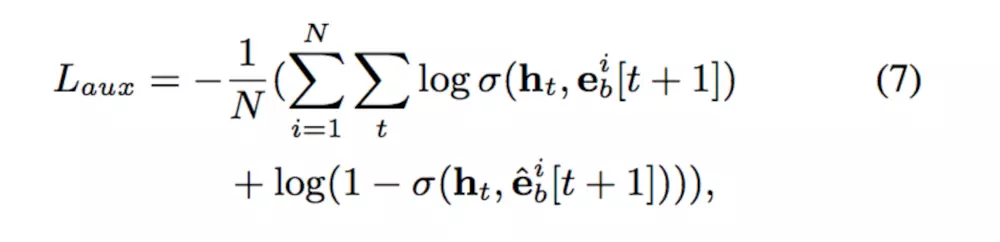
然后,抽取完兴趣的状态送入兴趣进化网络,为了让用户兴趣也能追着时间变化,采用RNN设计,同时继承与DIN的attention机制,结合后采用了GRU with attentional update gate (AUGRU)的方法,修改了GRU的结构
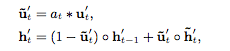
此处有多种GRU结合attention的方法。
最终DIEN的实验结果表现很好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号