

大数据作业附加
面我们以词频统计算法为例,来介绍怎么在具体应用中使用Hive。词频统计算法又是最能体现MapReduce思想的算法之一,这里我们可以对比它在MapReduce中的实现,来说明使用Hive后的优势。
MapReduce实现词频统计的代码可以通过下载Hadoop源码后,在 $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar 包中找到(wordcount类),wordcount类由63行Java代码编写而成。下面首先简单介绍一下怎么使用MapReduce中wordcount类来统计单词出现的次数,具体步骤如下:
1)创建input目录,output目录会自动生成。其中input为输入目录,output目录为输出目录。命令如下:
- cd /usr/local/hadoop
- mkdir input
2)然后,在input文件夹中创建两个测试文件file1.txt和file2.txt,命令如下:
- cd /usr/local/hadoop/input
- echo "hello world" > file1.txt
- echo "hello hadoop" > file2.txt
3)执行如下hadoop命令:
- cd ..
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount input output
4)我们可以到output文件夹中查看结果,结果如下:

下面我们通过HiveQL实现词频统计功能,此时只要编写下面7行代码,而且不需要进行编译生成jar来执行。HiveQL实现命令如下:
- create table docs(line string);
- load data inpath 'file:///usr/local/hadoop/input' overwrite into table docs;
- create table word_count as
- select word, count(1) as count from
- (select explode(split(line,' '))as word from docs) w
- group by word
- order by word;
执行后,用select语句查看,结果如下:
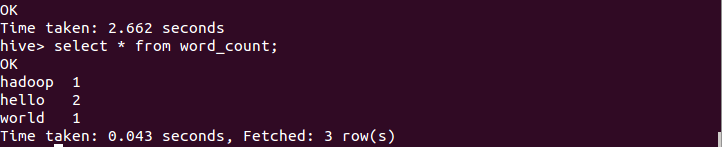
由上可知,采用Hive实现最大的优势是,对于非程序员,不用学习编写Java MapReduce代码了,只需要用户学习使用HiveQL就可以了,而这对于有SQL基础的用户而言是非常容易的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号