
01-AI大模型(一)--综述
1. NLP的发展脉络
1.1 文本表示方式的演进
要处理NLP问题,首先要解决文本的表示问题。虽然我们人去看文本,能够清楚明白文本中的符号表达什么含义,但是计算机只能做数学计算,需要将文本表示成计算机可以处理的形式。自然语言处理的核心是将“语言”转化为“模型可处理的向量”,其表示方式经历了如下演变:
| 阶段 | 方法 | 特点 |
| 第一代 | One-hot | 每个词表示为一个高维稀疏向量,维度等于词表大小,不能表达词之间的关系 |
| 第二代 | Word Embedding(如 Word2Vec, GloVe) | 将词映射为低维稠密向量,捕捉语义关系,如“king - man + woman ≈ queen” |
| 第三代 | 上下文动态表示(如ELMo、BERT) | 向量由上下文决定,解决词义多样问题 |
| 第四代 | 自回归表示(GPT 系列) | 强调从左到右的生成学习,更适合语言建模和对话任务 |
1.2 NLP常见任务及演化趋势
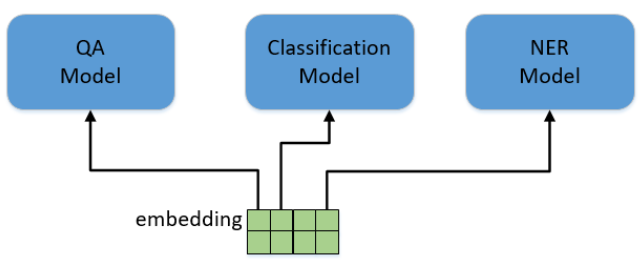
NLP中有各种各样的任务,比如分类(Classification)(如情感分析、新闻分类),问答(QA)(如阅读理解),实体命名识别(NER)(提取出人名、地名等实体)等。对于这些不同的任务,最早的做法是根据每类任务定制不同的模型,输入预训练好的embedding,然后利用特定任务的数据集对模型进行训练,如下图所示。这里存在的问题就是,不是每个特定任务都有大量的标签数据可供训练,对于那些数据集非常小的任务,恐怕就难以得到一个理想的模型。
1.3 借鉴CV领域的“预训练 + 微调”范式
我们看一下图像领域是如何解决这个问题的。图像分类是计算机视觉中最基本的任务,当我要解决一个小数据集的图像分类任务时,该怎么做?CV领域已经有了一套成熟的解决方案。我会用一个通用的网络模型,比如Vgg,ResNet或者GoogleNet,在ImageNet上做预训练(pre-training)。ImageNet有1400万张有标注的图片,包含1000个类别,这样的数据规模足以训练出一个规模庞大的模型。在训练过程中,模型会不断的学习如何提取特征,底层的CNN网络结构会提取边缘,角,点等通用特征,模型越往上走,提取的特征也越抽象,与特定的任务更加相关。当完成预训练之后,根据我自己的分类任务,调整最上层的网络结构,然后在小数据集里对模型进行训练。在训练时,可以固定住底层的模型参数只训练顶层的参数,也可以对整个模型进行训练,这个过程叫做微调(fine-tuning),最终得到一个可用的模型。总结一下,整个过程包括两步,拿一个通用模型在ImageNet上做预训练(pre-training),然后针对特定任务进行微调(fine-tuning),完美解决了特定任务数据不足的问题。还有一个好处是,对于各种各样的任务都不再需要从头开始训练网络,可以直接拿预训练好的结果进行微调,既减少了训练计算量的负担,也减少了人工标注数据的负担。
- BERT:通过 Masked Language Model(MLM)进行语言理解预训练;
- GPT:通过自回归语言模型进行生成式预训练。
2.BERT vs ChatGPT
2.1 它们与 Transformer 的关系
-
BERT 和 ChatGPT 都是 基于 Transformer 的改造模型
-
Transformer 是 通用架构,可用于编码(理解)或解码(生成)
-
它们各自基于 Transformer 的某一部分发展:
-
BERT:只用 Transformer 的 Encoder
-
ChatGPT:只用 Transformer 的 Decoder
-
2.2 BERT的发展路径:理解为主的“预训练+微调”典范
初代 BERT(2018, Google)
-
结构基础:基于 Transformer 的 Encoder-only 架构;
-
预训练目标:
-
Masked Language Modeling(MLM):随机遮盖输入中的部分词,预测被遮盖词;
-
Next Sentence Prediction(NSP):判断两个句子是否相邻;
-
-
创新之处:
-
双向上下文建模:相比传统左到右的语言模型,BERT能同时利用左右语境;
-
统一模型架构:一个模型可适配多种NLP任务,如分类、QA、NER等;
-
预训练-微调范式确立:先在大语料上训练,再在下游任务上微调。
-
后续改进版本
| 版本 | 核心改进 | 发布者 |
| RoBERTa | 移除NSP、更长训练时间、更大Batch、更大数据(更强) | |
| ALBERT | 参数共享+矩阵分解,降低参数量 | |
| DistilBERT | 蒸馏技术压缩模型,提升速度 | HuggingFace |
| SpanBERT | 预测连续span而非单词,适合抽取任务 | |
| BERT-wwm | Whole Word Masking,更自然的遮盖策略 | 哈工大+百度 |
影响与地位
-
BERT 奠定了“通用语言理解模型”的范式;
-
广泛用于问答系统、文本分类、命名实体识别、法律/医疗文本理解等;
-
是 Google 搜索、微软 Office 等系统的核心组件。
2.3 ChatGPT(GPT)的发展路径:从语言模型到对话智能体
2.3.1 GPT 初代(GPT-1, 2018, OpenAI)
-
结构基础:基于 Transformer 的 Decoder-only 架构;
-
训练目标:自回归语言建模(Auto-Regressive Language Modeling)
- 特点:
-
只能基于前文生成下一个词;
-
表现优于传统 RNN、LSTM 语言模型。
-
2.3.2 GPT-2(2019)
-
规模升级:从 GPT-1 的 1.17 亿参数 → GPT-2 的 15 亿参数;
-
性能突破:
-
能进行文本生成、翻译、摘要、对话等任务;
-
展现“少样本学习能力”:只需少量样例即可泛化新任务;
-
-
争议与影响:因“可能被滥用”一度未公开完整模型。
2.3.3 GPT-3(2020)
-
参数量爆炸性增长:1750 亿参数;
-
Few-shot / Zero-shot 能力增强:
-
利用“提示词工程(prompt engineering)”实现任务泛化;
-
不再需要微调,只通过提示就能解决多种任务;
-
-
缺点:缺乏人类价值对齐,容易生成虚假、毒性内容。
2.3.4 ChatGPT(2022)
-
基于GPT-3.5(InstructGPT)
-
引入**强化学习+人类反馈(RLHF)**机制,优化对话表现:
-
收集人类偏好评分,训练奖励模型;
-
使用 Proximal Policy Optimization(PPO)强化训练;
-
-
变成“能对话的语言模型”,具备以下特性:
-
多轮对话;
-
能回答指令、写代码、写文案;
-
更安全、更守规矩;
-
-
用户量爆发式增长,ChatGPT 成为AI走入大众的重要标志。
2.3.5 GPT-4 / GPT-4o(2023~2024)
| GPT-版本 | 关键特性 |
| GPT-4 | 更强推理、多模态输入(图像+文本) |
| GPT-4o(Omni) | 原生多模态(文本+图像+音频),速度更快,成本更低 |
2.4 BERT vs ChatGPT:对比总结与演化趋势
| 对比项 | BERT | ChatGPT(GPT系列) |
| 架构方向 | Transformer Encoder | Transformer Decoder |
| 任务偏向 | 语言理解(分类、QA) | 语言生成(对话、写作) |
| 训练目标 | MLM + NSP | 自回归预测 + RLHF |
| 输入处理 | 同时利用前后文 | 只使用前文预测 |
| 下游适配 | 微调为主 | Prompt + 少样本泛化 |
| 典型代表 | BERT、RoBERTa、ALBERT | GPT-2/3、InstructGPT、ChatGPT、GPT-4(o) |
| 用户接口 | API接入或任务式 | 对话式/问答式,ToC为主 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号