
000670 elasticSearch、kibana安装 集群配置(centos7+jdk8下)
一条要遵守的纪律: 在elasticSearch的配置中,冒号后面的一定要带一个空格,等号后面一定不要有空格
1.上传、解压、创建目录
mkdir -p /opt/es
上传下面三个文件到 /opt/es

然后 chmod 777 * 获取这三个文件的权限
解压
tar -zxvf elasticsearch-6.3.1.tar.gz chmod 777 -R elasticsearch-6.3.1
=============================
[配置]
es 使用最大线程数 最大内存数 访问的最大文件数 (在centos7下,只需要配置“访问的最大文件数”)
先改一下centos7系统的配置: 修改线程内存和文件数
vi /etc/security/limits.conf
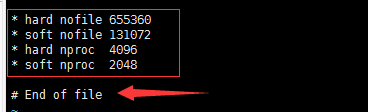
在文件末尾,注意一定在要 # End of file之前,添加如下配置
* hard nofile 655360 * soft nofile 131072 * hard nproc 4096 * soft nproc 2048
wq!保存 source /etc/security/limits.conf
然后是 修改系统允许的软件运行内存
vi /etc/sysctl.conf
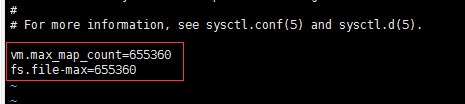
在文件最后写入以下配置
vm.max_map_count=655360 fs.file-max=655360
然后使用以下命令, 保存,并使其生效
wq! sysctl -p
来到elasticsearch-6.3.1/config下, 需要改两个配置文件 elasticsearch.yml(es的集群配置文件) 和 jvm.options (es的jvm配置文件)
vi jvm.options
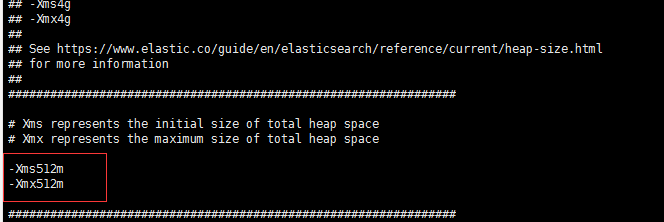
wq!退出
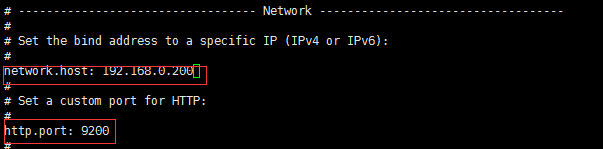
然后 vi elasticsearch.yml
找到path.data
es6.0出于安全方面的考虑,不允许使用root用户来启动es6.0,所以需要为es单独创建用户,并切换到新用户es下然后授权,这样之后的操作,很多文件的访问权限使用用户es的权限就可以了
adduser es su es
启动es
cd /opt/es/elasticsearch-6.3.1/bin/
./elasticsearch
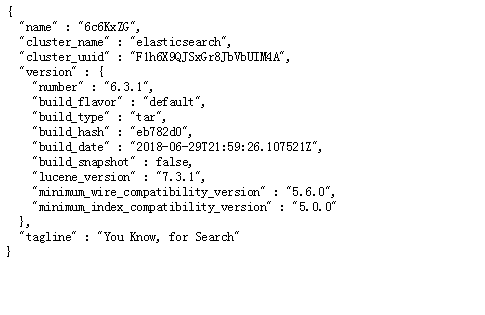
然后访问 http://192.168.0.200:9200/
结果如下图
=========================
切换到root用户下,在/opt/es目录下,执行
tar -zxvf kibana-6.3.1-linux-x86_64.tar.gz
kibana解压后,进入 解压上下 的config目录,然后
vi kibana.yml
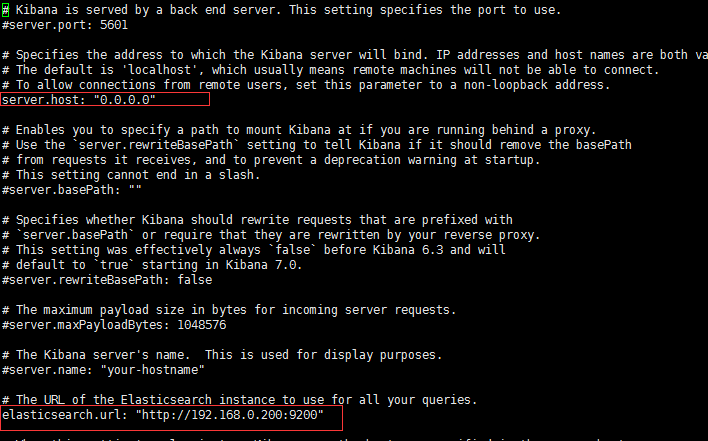
切换到bin目录,执行
nohup ./kibana &
再回车
会在当前目录下产生nohup.out文件
查看进程很独特 ps -ef | grep node | grep -v grep 用的是node,而不是什么kibana
访问 192.168.0.200:5601
发现需要登录,而且无法输入用户名和密码,这里,我们需要开启x-pack(es6.0自带)
启用trial license(30天试用)
curl -H "Content-Type:application/json" -XPOST http://192.168.0.200:9200/_xpack/license/start_trial?acknowledge=true
配置elasitcsearch.yml,末尾加上下面这个
xpack.security.enabled: true
启动elasticsearch
./bin/elasticsearch
设置三个密码共6次,每个密码都要确认一次
li@li-ok:~/elasticsearch-6.3.0$ ./bin/elasticsearch-setup-passwords interactive Picked up _JAVA_OPTIONS: -Dawt.useSystemAAFontSettings=gasp Picked up _JAVA_OPTIONS: -Dawt.useSystemAAFontSettings=gasp Initiating the setup of passwords for reserved users elastic,kibana,logstash_system,beats_system. You will be prompted to enter passwords as the process progresses. Please confirm that you would like to continue [y/N]y Enter password for [elastic]: Reenter password for [elastic]: Enter password for [kibana]: Reenter password for [kibana]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]:
我使用了如下的密码
elasticpwd kibanapwd logsyspwd bsyspwd
在kibana中配置elasticsearch的用户信息
在kibana.yml中配置,找到如下位置并修改
elasticsearch.username: "elastic" elasticsearch.password: "elasticpwd"
重新启动elasticsearch、kibana
启动完成之后访问kibana,使用
用户名 elastic
密码 elasticpwd
登录
========================================
安装中文分词插件
上传analysis-ik到elasticSearch的plugins目录下
重启elasticSearch
=======================================
集群配置
克隆一个centos服务器,然后修改一下新服务器的ip,以及众多已安装软件的的配置中的ip
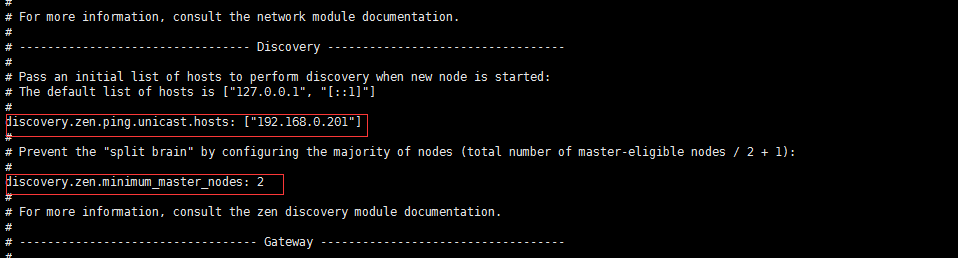
cluster.name: liqunes #必须相同 # 集群名称(不能重复) node.name: lqes1 #(必须不同) # 节点名称,仅仅是描述名称,用于在日志中区分(自定义) #指定了该节点可能成为 master 节点,还可以是数据节点 node.master: true node.data: true path.data: /opt/data #没有这个目录就要手动创建 # 数据的默认存放路径(自定义) path.logs: /opt/logs #没有这个目录就要手动创建 # 日志的默认存放路径 network.host: 192.168.0.200 # 当前节点的IP地址 http.port: 9200 # 对外提供服务的端口 transport.tcp.port: 9300 #9300为集群服务的端口 discovery.zen.ping.unicast.hosts: ["192.168.0.201"] # 集群个节点IP地址,也可以使用域名,需要各节点能够解析 discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1 注意:清空data和logs数据 192.168.14.12:9200/_cat/nodes?v
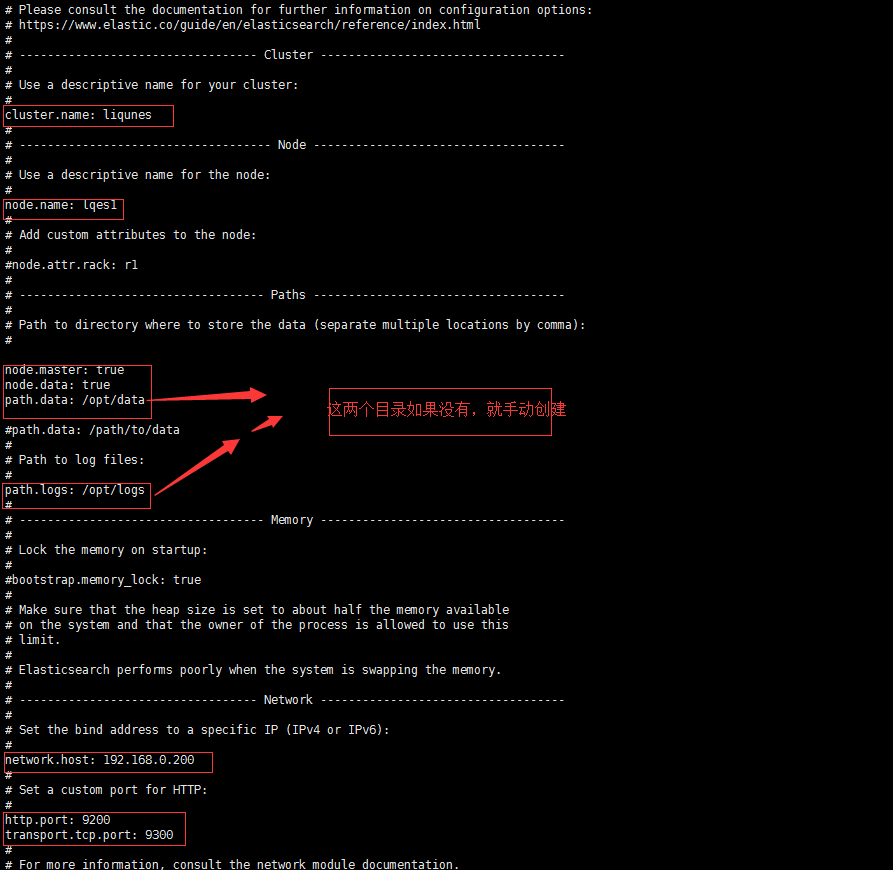
然后按相关项配置另外一台服务器 192.168.0.201
两个服务器上,都 cd /opt 再执行 chmod 777 data 和 chmod 777 logs
然后切换有es用户下,用nohup启动elasticsearch
[注: 你在两个xshell上,把两个服务器的es都打开,然后再去用http访问,不然会报错说集群中的master节点数量不够]
su es 来到es的bin目录下 rm -rf nohup.out nohup ./elasticsearch &
我们使用cerebro-0.8.3来管理es的集群
方法:解压cerebro-0.8.3,放到d盘,在bin目录下,右键单击cerebro.bat,以管理员运行,初始化出两条 信息后,我们用浏览器访问 http://localhost:9000/
然后在界面中央的框内写入任意一个es的地址,比如 http://192.168.0.200:9200 (必须带http://), 点击connect
===========================================
一般数据量不大的公司,es的数据就存储在es的服务器上,如果是数据量大的,就得需要专门的存储服务器来存储es需要的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号