
正则表达式
正则表达式
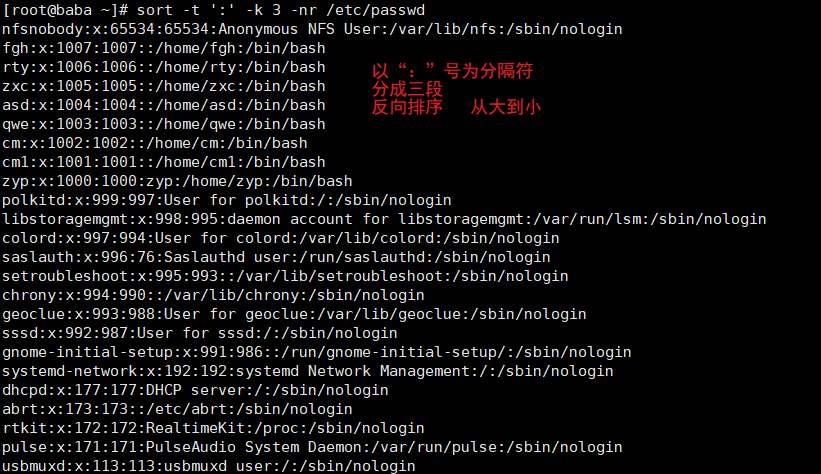
sort命令:
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
| sort [选项] 参数 |
常用选项:
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分离符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o | <输出文件>:将排序后的结果转存至指定文件 |

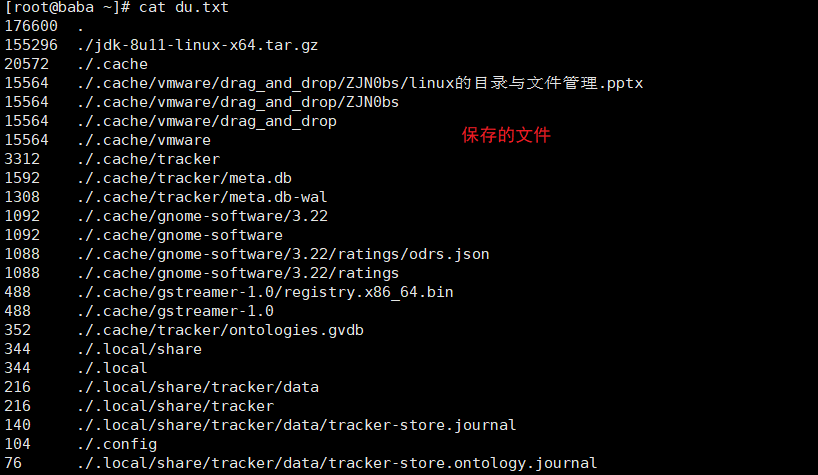
uniq命令:
用于报告或者忽略文件中连续的重复行,常与sort命令复合使用
语法格式
| uniq [选项] 参数 |
常用选项
| -c | 进行计数 |
| -d | 仅显示连续的重复行 |
|
-u |
仅显示出现一次的行 |




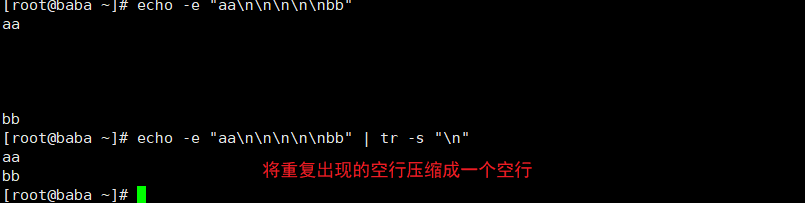
tr命令
| tr [选项] [参数] |
参数:
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”
字符集2:指定要转换成的目标字符集

常用选项
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串:用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1 ,不加选项同结果 |



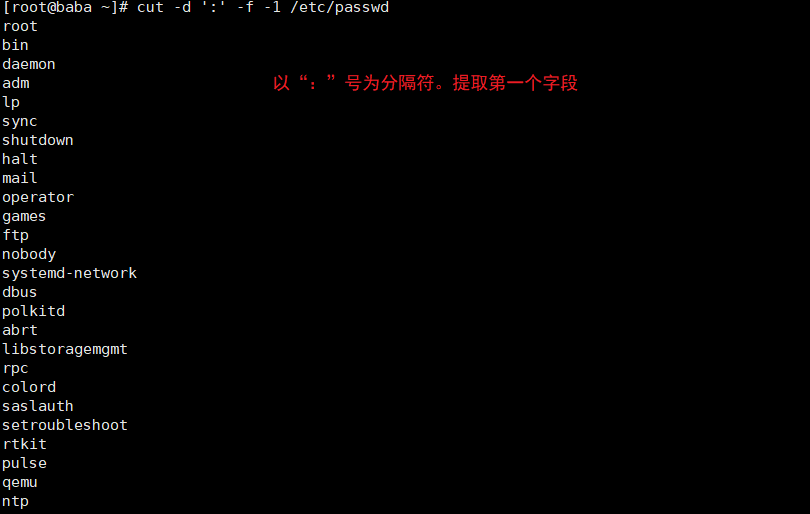
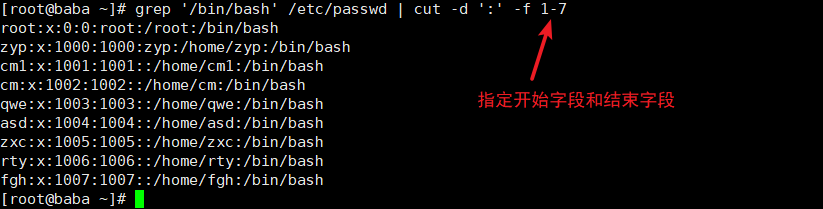
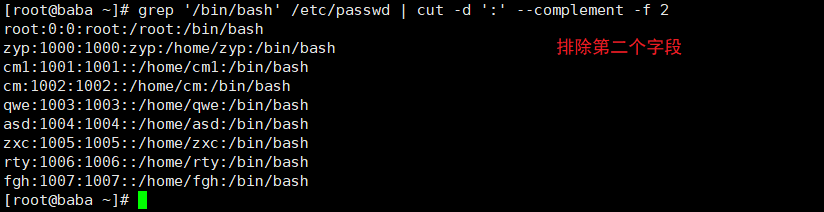
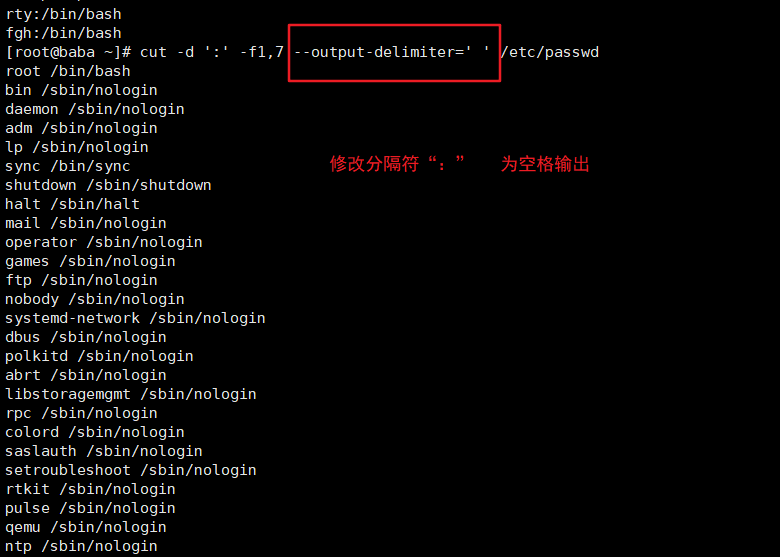
cut命令
显示行中的指定部分,删除文件中指定字段
|
cut [选项] 参数 |
常用选项
| -f | 通过指定哪一个字段进行提取。cut命令使用”TAB“作为默认的字段分隔符 |
| -d | “TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符 |
| --complement | 此选项用于排除所指定的字段 |
| --output-delimiter | 更改输出内容的分隔符 |

eval命令
前面加上eval时,shell就会在执行命令之前扫描它两次。eval 命令将首先扫描命令进行所有的置换,然后再执行该命令。
命令适用于哪些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描
示例一、

示例二、


示例三、


正则表达式
通常用于判断语句中,用来检查某一字符串是否满足某一格式
- 正则表达式是由普通字符与元字符组成
- 普通字符包括大小写字母、数字、标点符号以及一些其他符号
- 元字符是指正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现形式
基础正则表达式常见元字符:(支持的工具:grep、egrep、sed、awk)
注:egrep、awk使用 {n} 、{n,}、{n,m}匹配时“{ }”前不用加“\”
| \ | 转义字符,用于取消特殊符号的含义,例:\! 、 \n 、 \$等 |
| ^ | 匹配字符串开始的位置,例^9、^oh、^#、^[a-z] |
| $ | 匹配字符串结束的位置,例 h0u$ 、^$匹配空行 |
| . |
匹配除\n之外的任意一个字符,例: uj.h 、 uj..h |
| * | 匹配前面子表达式0次或者多次,例:uj*h 、 uj.*h |
| [list] | 匹配list列表中的一个字符,例uj[ssf]jk 、 [0-9]匹配任意一位字符 |
| [^list] | 匹配非 list 列表中的一个字符,例uj[^ssf]jk 、 [^a-z]匹配任意一位非小写字符 |
| \{n\} | 匹配前面的子表达式n次,例 go\{2\}d、'[0-9]\{2\}'匹配两位数字 |
| \{n,\} | 匹配前面的子表达式不少于n次,例 go\{2,\}d、'[0-9]\{2,\}'匹配两位及两位以上数字 |
| \{n,m\} | 匹配前面的子表达式n到m次,例 go\{2,3\}d、'[0-9]\{2,3\}'匹配两位到三位数字 |






扩展正则表达式元字符:(支持的工具:egrep、awk)
| + | 匹配前面子表达式1次以上 |
| ? | 匹配前面子表达式0次或者1次 |
| () | 将括号的字符串作为一个整体 |
| | | 以或的方式匹配字条串 |




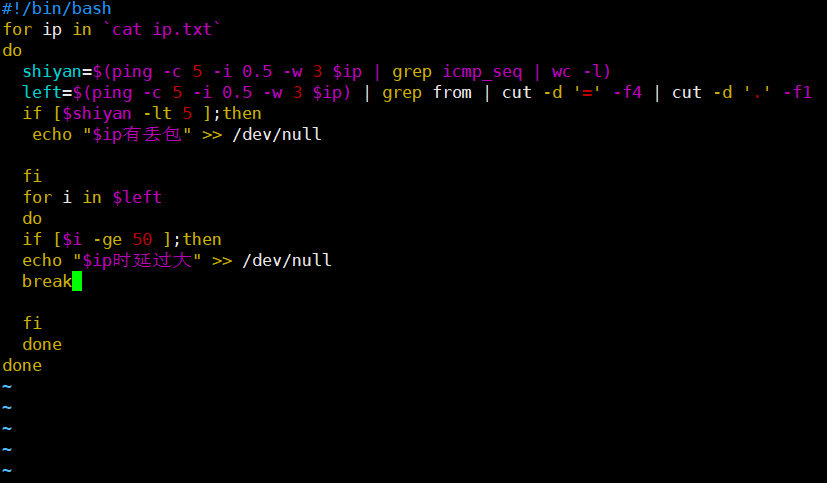
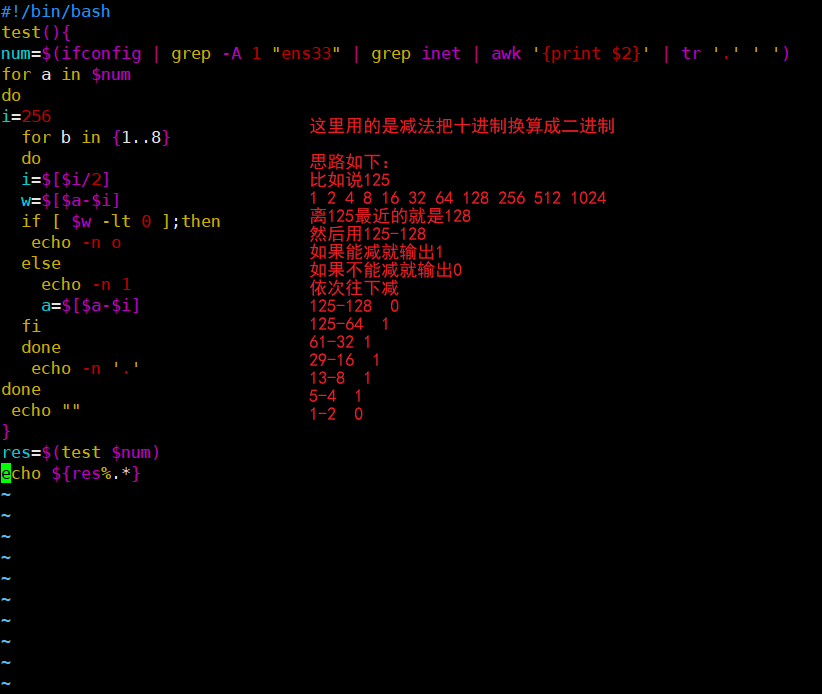
1、写个shell脚本,要求ping一批服务器,每台服务器ping5个包,取出时延>=50ms或丢包的服务器
2、写个shell脚本实现把点分十进制的IP地址,转换成点分二进制

Sed工具概述
sed编辑器:
- sed是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流
- sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要么存储在一个命令文本文件中
sed的工作流程
- 读取:sed从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)
- 执行:默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,否则sed命令将会在所有的行上一次执行
- 显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。在所有的文件内容都被处理完成之前,上述过程将重复执行,直到所有内容被处理完
注:默认情况下所有的sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出
sed基本语法:
命令语法:
sed -e ‘编辑指令’ 文件1 文件2....
sed -n -e ‘编辑指令’ 文件1 文件2....
sed -i -e ‘编辑指令’ 文件1 文件2....
编辑指令格式:【地址1】 【地址2】 操作 【参数】
常用选项:
| -e 或 --expression= | 指定要执行的命令,只有一个编辑命令时可以省略 |
| -n、--quiet 或 silent | 禁止sed编辑器输出,但可以与p命令一起使用完成输出 |
| -i | 直接修改目标文本文件 |
| -f 或 --file= | 表示用指定的脚本文件来处理输入的文本文件 |
| -h 或 --help | 显示帮助 |
常用操作
| 指令 | 作用 |
| p | 输出指定的行 |
| d | 删除指定的行 |
| s | 字串替换,格式:“行范围s/旧字符串/新字符串/g” |
| r | 读取指定文件 |
| w | 保存为文件 |
| i | 插入,在当前行前面插入一行或多行 |
| a | 增加,在当前行后面增加一行指定内容 |
| c | 替换,将选定行替换为指定内容 |
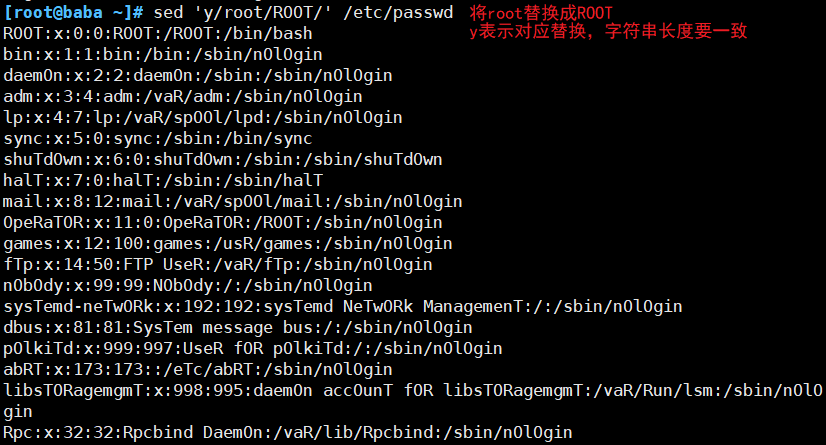
| y | 字符转换,转换前后的字符长度必须相同 |
| l | 打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t) |
| = | 打印行号 |
Sed用法示例:
(1)输出指定的行
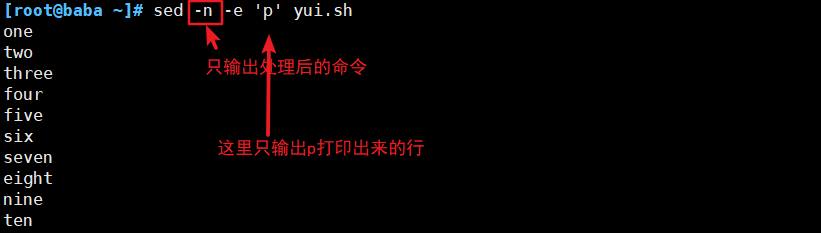

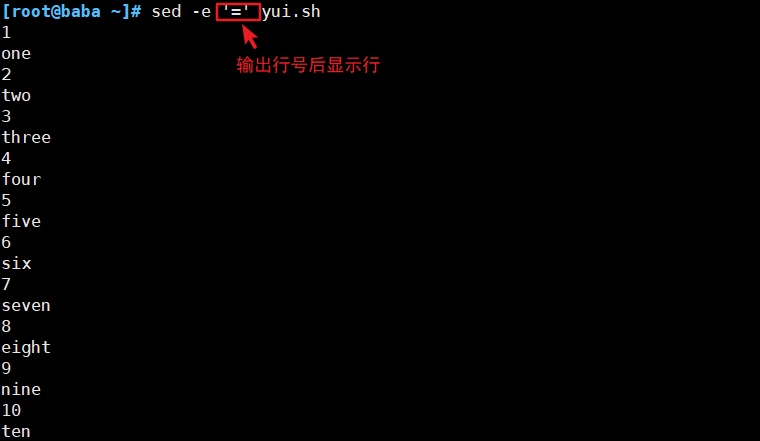

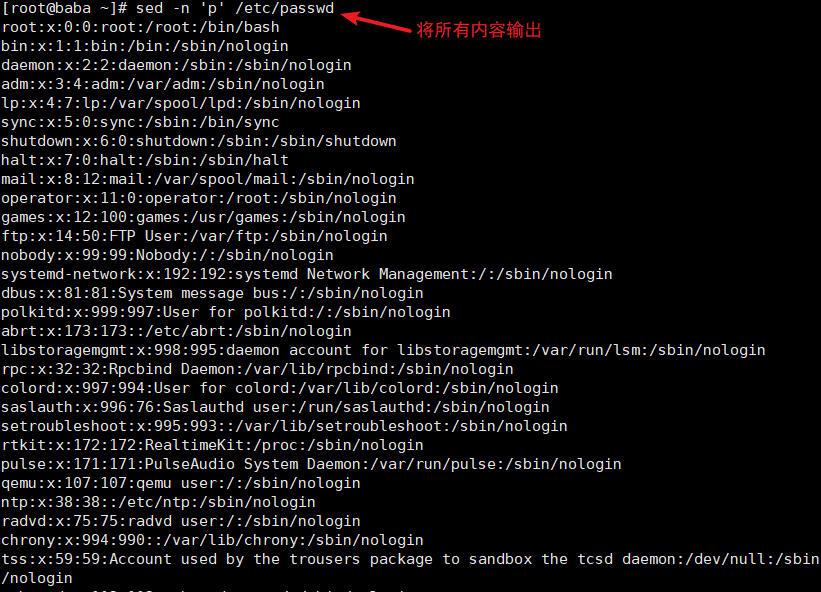
使用地址:
sed编辑器有2种寻址方式
- 以数字形式表示行区间
- 用文本模式来过滤出行









(2)插入符合条件的行
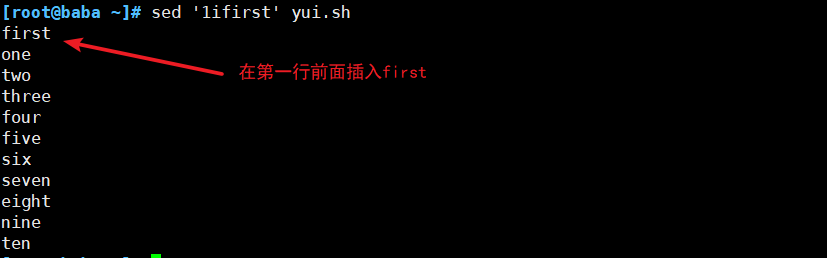
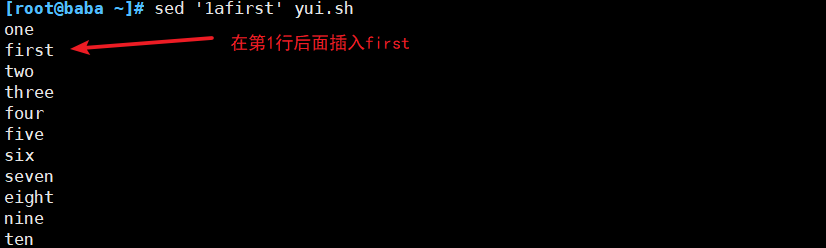
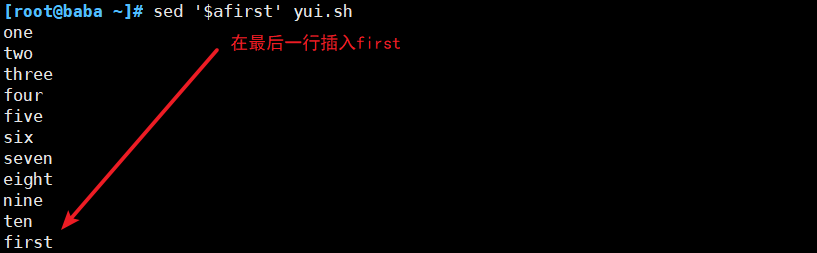
(3)删除符合要求的行
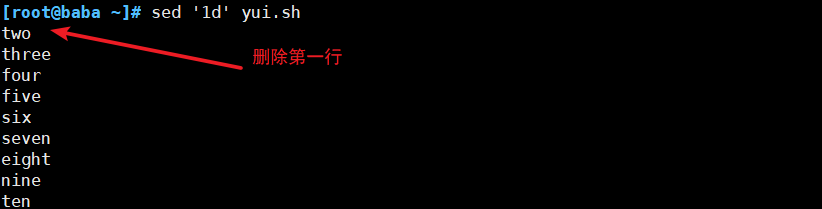
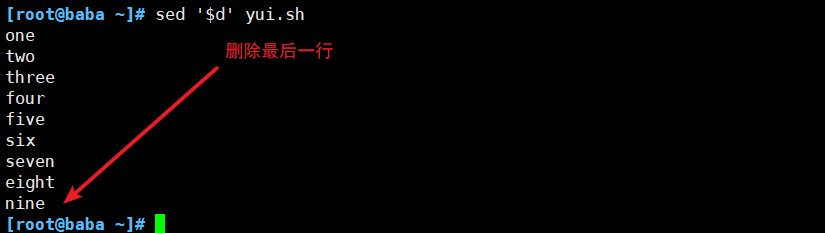
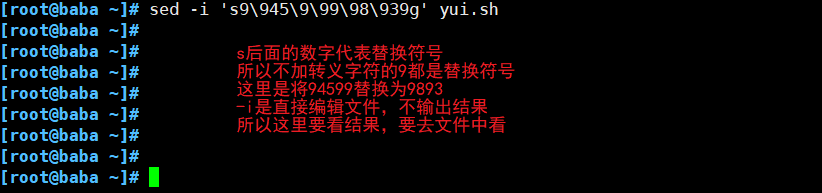
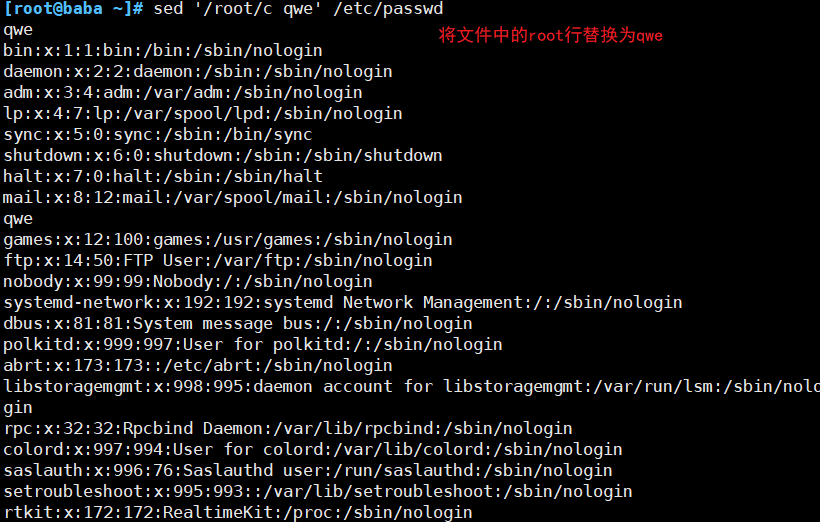
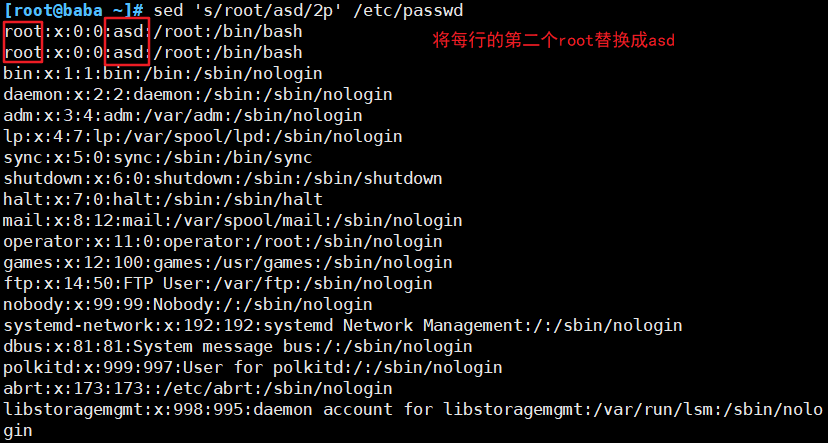
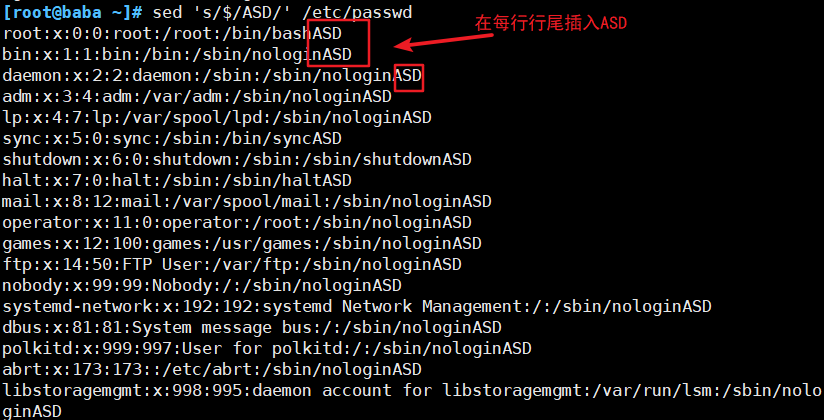
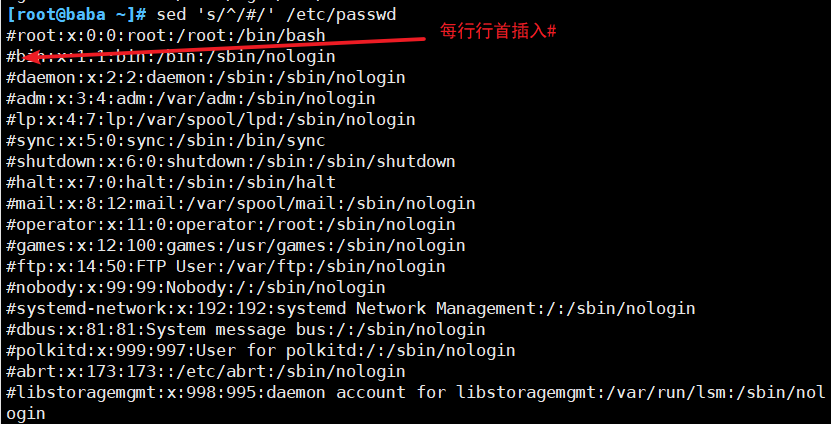
(4)替换符合条件的文本
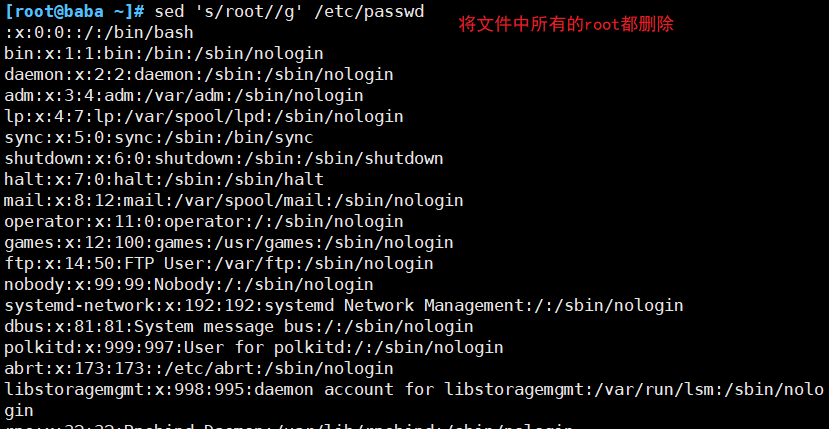
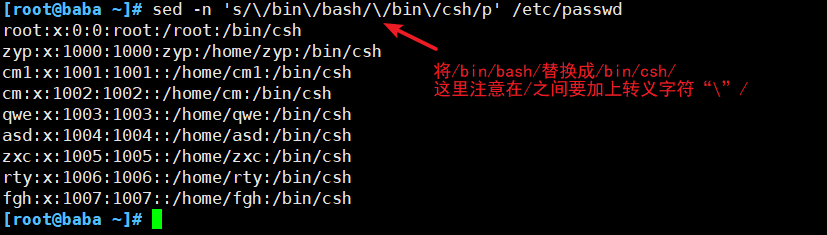
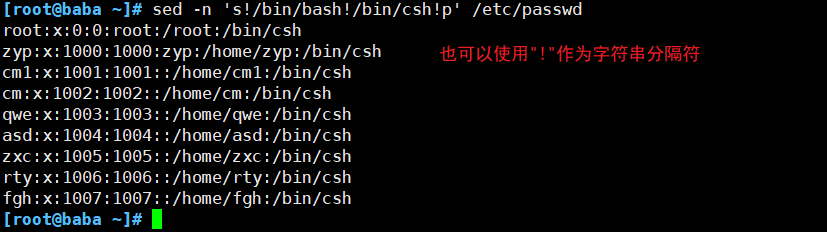

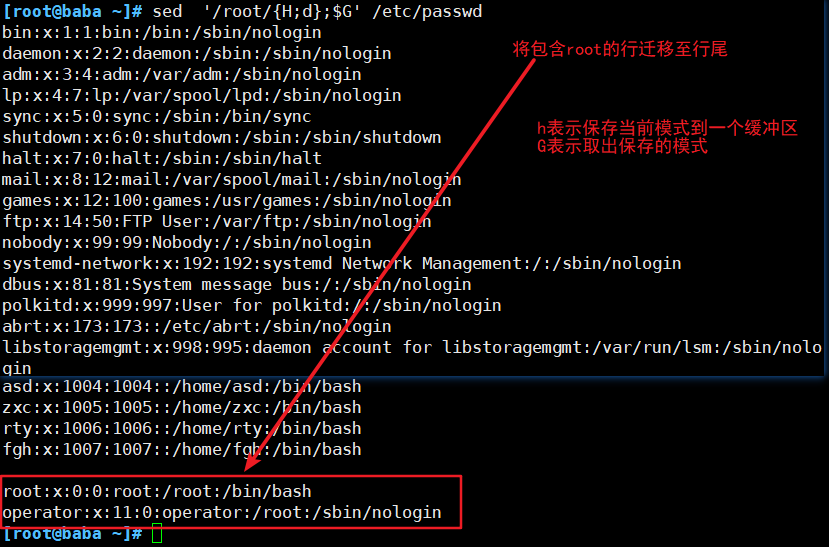
(5)迁移符合条件的文本


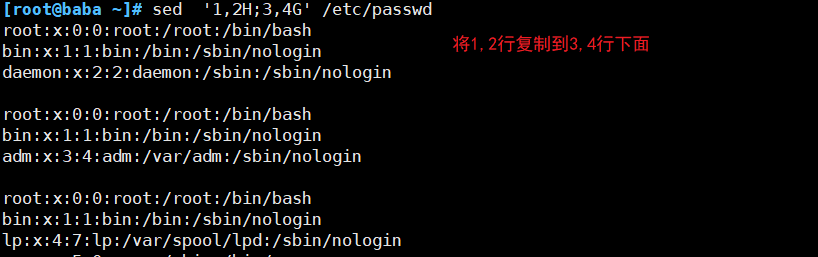


AWK:
工作原理:
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
对比sed:
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示或、“!”表示“非”:还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
awk的两种语法格式:
- awk 选项 '模式或条件 (操作)' 文件1 文件2 ...
- awk -f 脚本文件 文件1 文件2 ...
awk常见的内建变量
| FS | 列分割符,指定每行文本的字段分割符,默认为空格或制表符。与“-F”作用相同 |
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序数) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 行分割符,awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是‘\n’ |
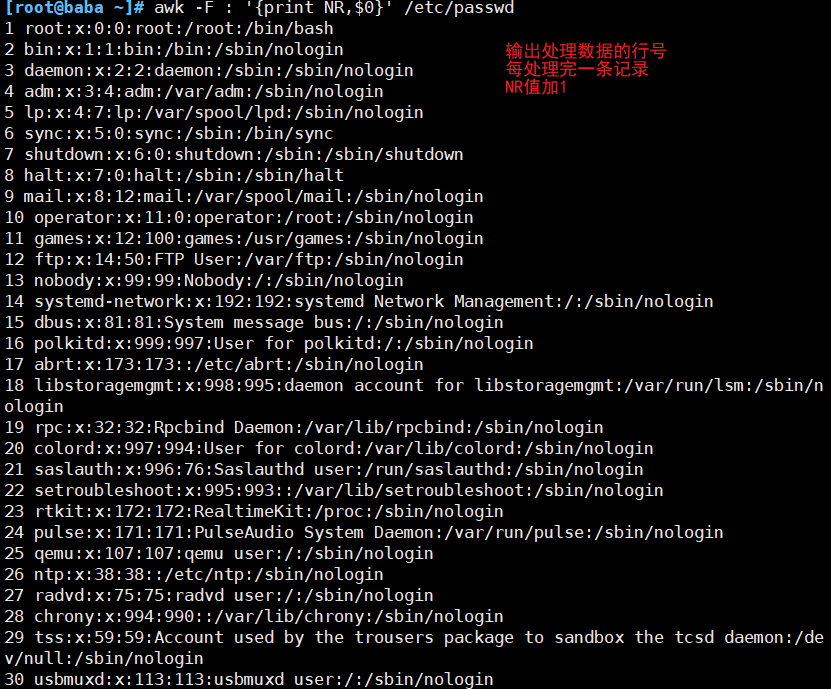
##按行输出文本

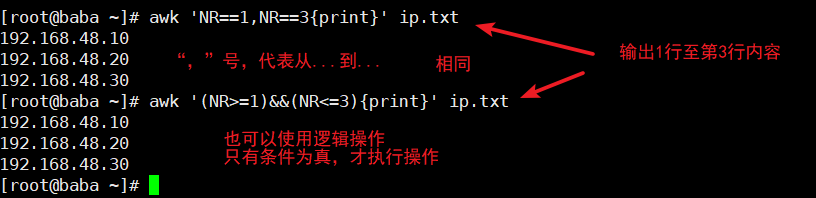



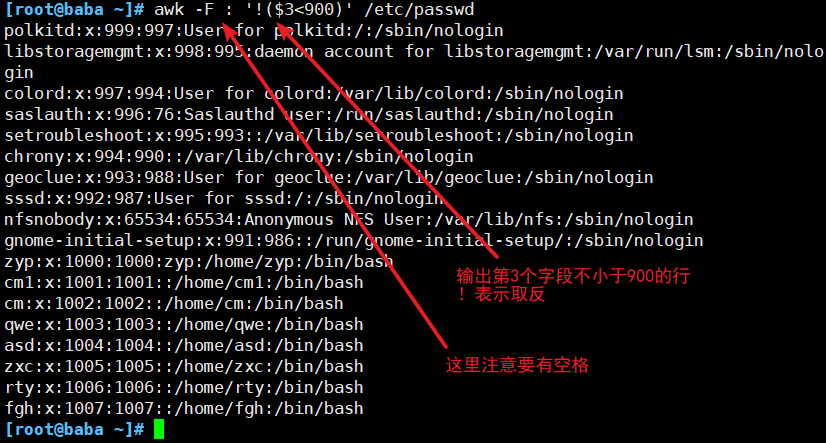
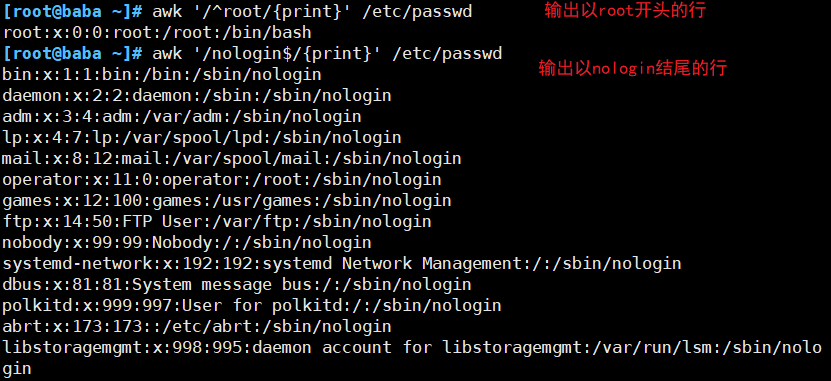
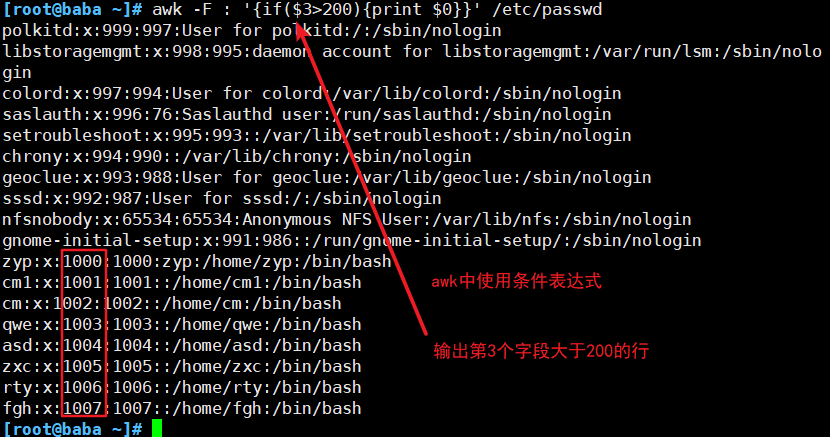
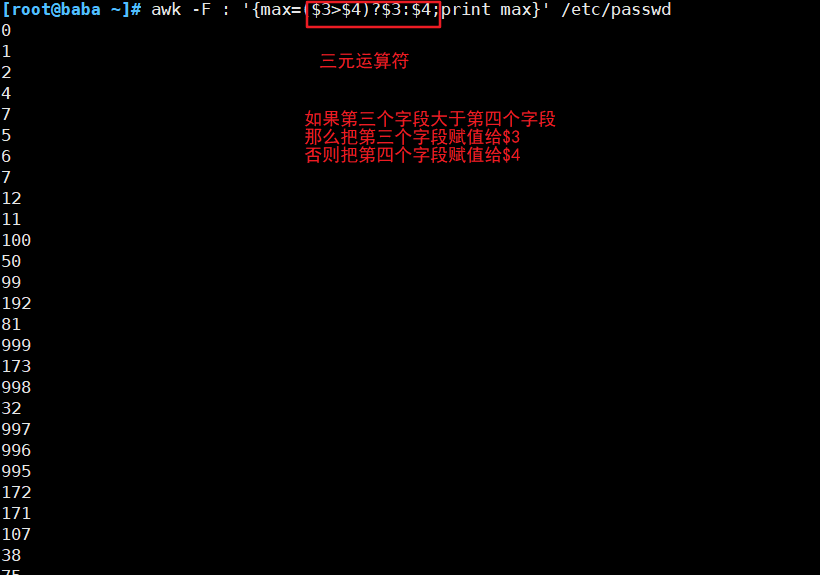
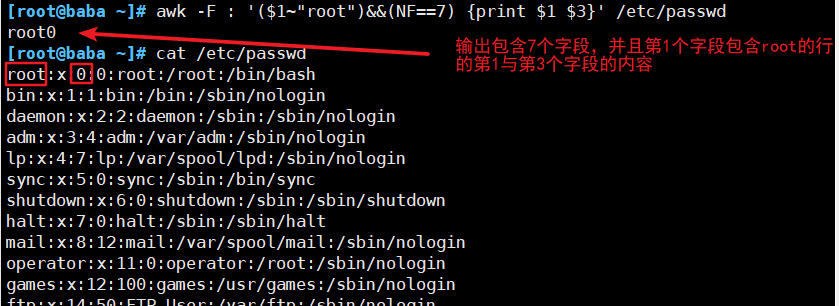
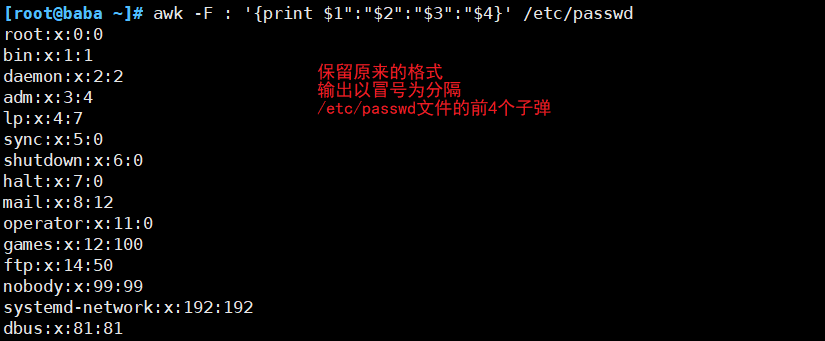
##按字段输出文本





 浙公网安备 33010602011771号
浙公网安备 33010602011771号